Pengantar
Di SQL Server 2012, agregasi yang dikelompokkan (vektor) dapat menggunakan eksekusi mode batch paralel, tetapi hanya untuk agregat parsial (per-utas). Agregat global terkait selalu berjalan dalam mode baris, setelah Aliran Partisi Ulang pertukaran.
SQL Server 2014 menambahkan kemampuan untuk melakukan agregasi grup mode batch paralel dalam satu Hash Match Aggregate operator. Ini menghilangkan pemrosesan mode baris yang tidak perlu, dan menghilangkan kebutuhan akan pertukaran.
SQL Server 2016 memperkenalkan pemrosesan mode batch serial dan tekan turun agregat . Saat pushdown berhasil, agregasi dilakukan dalam Pemindaian Columnstore operator itu sendiri, mungkin beroperasi langsung pada data terkompresi, dan memanfaatkan instruksi CPU SIMD.
Peningkatan kinerja yang mungkin dilakukan dengan agregat pushdown bisa sangat substansial. Dokumentasi mencantumkan beberapa kondisi yang diperlukan untuk mencapai pushdown, tetapi ada kasus di mana kurangnya 'baris yang dikumpulkan secara lokal' tidak dapat sepenuhnya dijelaskan dari detail tersebut saja.
Artikel ini membahas faktor tambahan yang memengaruhi pushdown agregat untuk GROUP BY hanya kueri . Penekanan agregat skalar (agregasi tanpa GROUP BY klausa), filter pushdown, dan ekspresi pushdown mungkin dibahas di postingan mendatang.
Penyimpanan toko kolom
Hal pertama yang harus dikatakan adalah bahwa agregat pushdown hanya berlaku untuk data terkompresi, jadi baris di delta store tidak memenuhi syarat. Di luar itu, pushdown dapat bergantung pada jenis kompresi yang digunakan. Untuk memahami hal ini, pertama-tama perlu meninjau cara kerja penyimpanan columnstore pada tingkat tinggi:
grup baris terkompresi berisi segmen kolom untuk setiap kolom. Nilai kolom mentah dikodekan dalam bilangan bulat 4-byte atau 8-byte menggunakan nilai atau kamus pengkodean.
Pengodean nilai dapat mengurangi jumlah bit yang diperlukan untuk penyimpanan dengan menerjemahkan nilai mentah menggunakan offset dasar dan pengubah magnitudo. Misalnya, nilai {1100, 1200, 1300} dapat disimpan sebagai (0, 1, 2) dengan terlebih dahulu menskalakan dengan faktor 0,01 untuk menghasilkan {11, 12, 13}, kemudian rebasing pada 11 untuk menghasilkan {0, 1, 2}.
Encoding kamus digunakan ketika ada nilai duplikat. Ini dapat digunakan dengan data non-numerik. Setiap nilai unik disimpan dalam kamus dan diberi id integer. Data segmen kemudian merujuk nomor id dalam kamus alih-alih nilai aslinya.
Setelah encoding, data segmen dapat dikompresi lebih lanjut menggunakan run-length encoding (RLE) dan bit-packing:
RLE mengganti elemen berulang dengan data dan jumlah pengulangan, misalnya {1, 1, 1, 1, 1, 2, 2, 2} dapat diganti dengan {5×1, 3×2}. Penghematan ruang RLE meningkat seiring dengan lamanya pengulangan. Lari pendek bisa menjadi kontraproduktif.
Pengemasan kecil menyimpan bentuk biner dari data dalam jendela umum yang sempit mungkin. Misalnya, angka {7, 9, 15} disimpan dalam bilangan bulat biner (byte tunggal untuk spasi) sebagai {00000111, 00001001, 00001111}. Pengepakan bit-bit ini ke dalam jendela empat-bit tetap memberikan aliran {011110011111}. Mengetahui ada ukuran jendela yang tetap berarti tidak perlu ada pembatas.
Encoding dan kompresi adalah langkah yang terpisah, jadi RLE dan bit-packing diterapkan pada hasil pengkodean nilai atau pengkodean kamus data mentah. Selanjutnya, data dalam segmen kolom yang sama dapat memiliki campuran kompresi RLE dan bit-packing. Data terkompresi RLE disebut murni , dan data terkompresi yang dikemas sedikit disebut tidak murni . Segmen kolom dapat berisi data murni dan tidak murni.
Penghematan ruang yang dapat dicapai melalui pengkodean dan kompresi mungkin bergantung pada pemesanan. Semua segmen kolom dalam grup baris harus diurutkan secara implisit dengan cara yang sama sehingga SQL Server dapat merekonstruksi baris lengkap dari segmen kolom secara efisien. Mengetahui bahwa baris 123 disimpan pada posisi yang sama (123) di setiap segmen kolom berarti nomor baris tidak harus disimpan.
Satu kelemahan dari pengaturan ini adalah urutan sortir yang umum harus dipilih untuk semua segmen kolom dalam grup baris. Urutan tertentu mungkin sangat cocok untuk satu kolom, tetapi kehilangan peluang signifikan di kolom lain. Ini paling jelas terjadi dengan kompresi RLE. SQL Server menggunakan teknologi Vertipaq untuk menentukan cara yang baik untuk menyortir kolom di setiap grup baris untuk memberikan hasil kompresi yang baik secara keseluruhan.
SQL Server saat ini hanya menggunakan RLE dalam segmen kolom bila ada minimum 64 nilai berulang yang berurutan. Nilai-nilai yang tersisa di segmen itu sedikit dikemas. Sebagaimana dicatat, apakah nilai berulang muncul sebagai bersebelahan dalam segmen kolom bergantung pada urutan yang dipilih untuk grup baris.
SQL Server mendukung SIMD specialized khusus bit membongkar untuk lebar bit dari 1 sampai 10 inklusif, 12, dan 21 bit. SQL Server juga dapat menggunakan ukuran integer standar mis. 16, 32, dan 64 bit dengan pengepakan bit. Angka-angka ini dipilih karena cocok dengan baik dalam unit 64-bit. Misalnya, satu unit dapat menampung tiga subunit 21-bit, atau 5 subunit 12-bit. SQL Server tidak melewati batas 64-bit saat mengemas bit.
SIMD menggunakan register 256-bit saat prosesor mendukung instruksi AVX2, dan register 128-bit saat instruksi SSE4.2 tersedia. Jika tidak, pembongkaran non-SIMD dapat digunakan.
Kondisi pushdown agregat yang dikelompokkan
Sebagian besar paket dengan Hash Match Aggregate operator tepat di atas Pemindaian Toko Kolom operator berpotensi memenuhi syarat untuk pushdown agregat yang dikelompokkan, sesuai dengan ketentuan umum yang tercantum dalam dokumentasi.
Filter dan ekspresi ekstra terkadang juga dapat ditambahkan tanpa mencegah pushdown agregat yang dikelompokkan. Aturan umumnya adalah bahwa filter atau ekspresi juga harus mampu menekan (meskipun ekspresi yang kompatibel mungkin masih muncul di Compute Scalar yang terpisah. ). Seperti disebutkan dalam pendahuluan, aspek-aspek ini dapat dibahas secara rinci dalam artikel terpisah.
Saat ini tidak ada rencana eksekusi yang menunjukkan apakah agregat tertentu dianggap kompatibel secara umum dengan pushdown agregat berkelompok atau tidak. Namun, ketika rencana umumnya memenuhi syarat untuk pushdown agregat yang dikelompokkan, tersedia jalur kode pushdown (cepat) dan non-pushdown (lambat).
Setiap batch keluaran pemindaian (hingga 900 baris) membuat keputusan runtime antara jalur kode cepat dan lambat. Fleksibilitas ini memungkinkan batch sebanyak mungkin untuk mendapatkan manfaat dari pushdown. Dalam kasus terburuk, tidak ada batch yang akan menggunakan jalur cepat saat runtime, meskipun ada paket yang 'umumnya kompatibel'.
Rencana eksekusi menunjukkan hasil pemrosesan pushdown jalur cepat sebagai 'baris yang dikumpulkan secara lokal' tanpa output baris yang sesuai dari pemindaian. Kumpulan jalur lambat muncul sebagai baris keluaran dari pemindaian penyimpanan kolom seperti biasa, dengan agregasi dilakukan oleh operator terpisah, bukan pada pemindaian.
Agregat tunggal dan kombinasi pemindaian yang dikelompokkan dapat mengirim beberapa kumpulan ke jalur cepat dan beberapa ke jalur lambat, jadi sangat mungkin untuk melihat beberapa, tetapi tidak semua, baris yang diagregasi secara lokal. Saat pushdown agregat yang dikelompokkan berhasil, setiap batch keluaran dari pemindaian berisi kunci pengelompokan dan agregat parsial yang mewakili baris yang berkontribusi.
Cek detail
Ada sejumlah pemeriksaan runtime untuk menentukan apakah pemrosesan pushdown dapat digunakan. Di antara pemeriksaan ringan yang didokumentasikan adalah:
- Tidak boleh ada kemungkinan agregat meluap .
- Semua tidak murni (bit-packed) kunci pengelompokan harus tidak lebih lebar dari 10 bit . Kunci pengelompokan murni (dikodekan RLE) diperlakukan sebagai memiliki lebar tidak murni nol, jadi ini biasanya menghadirkan sedikit hambatan.
- Pemrosesan pushdown harus terus dianggap bermanfaat , menggunakan 'ukuran manfaat' yang diperbarui di akhir setiap batch keluaran.
Kemungkinan kelimpahan agregat dinilai secara konservatif untuk setiap batch berdasarkan jenis agregat, tipe data hasil, nilai agregasi parsial saat ini, dan informasi tentang data input. Misalnya, SQL Server mengetahui nilai minimum dan maksimum dari metadata segmen seperti yang diekspos dalam sys.column_store_segments DMV . Di mana ada risiko overflow, batch akan menggunakan pemrosesan jalur lambat. Ini sebagian besar merupakan risiko untuk SUM agregat.
Pembatasan pada lebar kunci pengelompokan tidak murni layak untuk ditekankan. Ini hanya berlaku untuk kolom di GROUP BY klausa yang benar-benar digunakan dalam rencana pelaksanaan sebagai dasar pengelompokan. Kumpulan ini tidak selalu persis sama karena pengoptimal memiliki kebebasan untuk menghapus kolom pengelompokan yang berlebihan, atau untuk menulis ulang agregat, selama hasil kueri akhir dijamin cocok dengan spesifikasi kueri asli. Di mana ada perbedaan, itu adalah kolom pengelompokan yang ditunjukkan dalam rencana eksekusi yang penting.
Kesulitan yang lebih besar adalah mengetahui apakah salah satu kolom pengelompokan disimpan menggunakan bit-packing, dan jika demikian, berapa lebar yang digunakan. Ini juga akan berguna untuk mengetahui berapa banyak nilai yang dikodekan menggunakan RLE. Informasi ini dapat berada di column_store_segments DMV, tapi itu tidak terjadi hari ini. Sejauh yang saya tahu, tidak ada cara yang terdokumentasi saat ini untuk mendapatkan informasi bit-packing dan RLE dari metadata. Itu membuat kami mencari alternatif yang tidak terdokumentasi.
Menemukan informasi RLE dan bit-packing
DBCC CSINDEX yang tidak berdokumen dapat memberikan informasi yang kami butuhkan. Bendera pelacakan 3604 harus diaktifkan agar perintah ini menghasilkan keluaran di tab pesan SSMS. Mengingat informasi tentang segmen kolom yang kita minati, perintah ini mengembalikan:
- Atribut segmen (mirip dengan
column_store_segments) - Informasi RLE
- Bookmark ke data RLE
- Informasi Bitpack
Karena tidak berdokumen, ada beberapa keanehan (seperti harus menambahkan satu ke id kolom untuk clustered columnstore, tetapi bukan columnstore nonclustered), dan bahkan beberapa kesalahan kecil. Anda tidak boleh menggunakannya pada apa pun kecuali sistem pengujian pribadi. Semoga, suatu hari nanti, metode yang didukung untuk mengakses data ini akan tersedia.
Contoh
Cara terbaik untuk menampilkan DBCC CSINDEX dan menunjukkan poin yang dibuat sejauh ini dalam teks ini adalah dengan bekerja melalui beberapa contoh. Script berikut mengasumsikan ada tabel bernama dbo.Numbers dalam database saat ini yang berisi bilangan bulat dari 1 hingga setidaknya 16.384. Berikut adalah skrip untuk membuat versi standar saya dari tabel ini dengan sepuluh juta bilangan bulat:
JIKA OBJECT_ID(N'dbo.Numbers', N'U') BUKAN NULLBEGIN DROP TABLE dbo.Numbers;END;GOWITH Ten(N) AS ( SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1) SELECT n =IDENTITY(int, 1, 1)INTO dbo.NumbersFROM Ten AS T10CROSS JOIN Sepuluh AS T100CROSS JOIN Sepuluh AS T1000CROSS GABUNG Sepuluh SEBAGAI T10000CROSS GABUNG Sepuluh SEBAGAI T100000CROSS GABUNG Sepuluh SEBAGAI T1000000CROSS GABUNG Sepuluh SEBAGAI T10000000ORDER OLEH n OFFSET 0 BARIS FETCH PERTAMA 10 * 1000 * 1000 BARIS HANYAOPSI (MAXDOP 1);GOALTER TABLE dbo.NumbPRIersADD CONSTRA KEY CLUSTERED (n)DENGAN( SORT_IN_TEMPDB =ON, MAXDOP =1, FILLFACTOR =100);
Semua contoh menggunakan tabel pengujian dasar yang sama:Kolom pertama c1 berisi nomor unik untuk setiap baris. Kolom kedua c2 diisi dengan sejumlah duplikat untuk masing-masing sejumlah kecil nilai yang berbeda.
Indeks penyimpanan kolom berkerumun dibuat setelah populasi data sehingga semua data uji berakhir dalam satu grup baris terkompresi (tidak ada penyimpanan delta). Itu dibangun menggantikan indeks berkerumun b-tree pada kolom c2 untuk mendorong algoritma VertiPaq untuk mempertimbangkan kegunaan penyortiran pada kolom tersebut sejak dini. Ini adalah pengaturan pengujian dasar:
GUNAKAN Sandpit;GODROP TABLE JIKA ADA dbo.Test;GOCREATE TABLE dbo.Test( c1 integer NOT NULL, c2 integer NOT NULL);GODECLARE @values integer =512, @dupes integer =63; INSERT dbo.Test (c1, c2)SELECT N.n, N.n % @valuesFROM dbo.Numbers AS NWHERE N.n ANTARA 1 DAN @values * @dupes;GO-- Dorong VertiPaqCREATE CLUSTERED INDEX CCSI PADA dbo.Test (c2);GOCREATE CLUSTERED CLUSTERED INDEKS CCSI PADA dbo.TestWITH (MAXDOP =1, DROP_EXISTING =ON);
Kedua variabel tersebut untuk jumlah nilai yang berbeda untuk dimasukkan ke dalam kolom c2 , dan jumlah duplikat untuk setiap nilai tersebut.
Kueri pengujian adalah COUNT_BIG yang dikelompokkan sangat sederhana agregasi menggunakan kolom c2 sebagai kuncinya:
-- Tes querySELECT T.c2, numrows =COUNT_BIG(*)FROM dbo.Test AS TGROUP BY T.c2;
Informasi indeks Columnstore akan ditampilkan menggunakan DBCC CSINDEX setelah setiap eksekusi kueri pengujian:
DECLARE @dbname sysname =DB_NAME(), @objectid integer =OBJECT_ID(N'dbo.Test', N'U'); MENYATAKAN @rowsetid bigint =( PILIH P.hobt_id FROM sys.partitions AS P WHERE P.[object_id] =@objectid AND P.index_id =1 AND P.partition_number =1 ), @rowgroupid integer =0, @columnid integer =COLUMNPROPERTY (@objectid, N'c2', 'ColumnId') + 1; DBCC CSINDEX( @dbname, @rowsetid, @columnid, @rowgroupid, 1, -- tampilkan data segmen 2, -- print option 0, -- start bitpack unit (inclusive) 2 -- end bitpack unit (exclusive));Pengujian dijalankan pada versi terbaru dari SQL Server yang tersedia pada saat penulisan:Microsoft SQL Server 2017 RTM-CU13-OD bangun 14.0.3049 Edisi Pengembang (64-bit) di Windows 10 Pro. Segalanya akan berfungsi dengan baik pada versi terbaru SQL Server 2016 juga.
Tes 1:Pushdown, Kunci Tidak Murni 9-bit
Pengujian ini menggunakan skrip populasi data pengujian persis seperti yang tertulis di atas, menghasilkan tabel dengan 32.256 baris. Kolom
c1berisi angka dari 1 hingga 32.256.Kolom
c2berisi 512 nilai berbeda dari 0 hingga 511 inklusif. Setiap nilai dalamc2digandakan 63 kali , tetapi mereka tidak muncul sebagai blok yang berdekatan saat dilihat dic1memesan; mereka berputar 63 kali melalui nilai 0 hingga 511.Mengingat diskusi sebelumnya, kami mengharapkan SQL Server untuk menyimpan
c2data kolom menggunakan:
- Encoding kamus karena ada sejumlah besar nilai duplikat.
- Tidak ada RLE . Jumlah duplikat (63) per nilai tidak mencapai ambang 64 yang diperlukan untuk RLE.
- Ukuran kemasan bit 9 . 512 entri kamus yang berbeda akan benar-benar muat dalam 9 bit (2^9 =512). Setiap unit 64-bit akan berisi hingga tujuh subunit 9-bit.
Ini semua dikonfirmasi sebagai benar menggunakan DBCC CSINDEX permintaan:
Atribut Segmen bagian keluaran menunjukkan pengkodean kamus (ketik 2; nilai untuk encodingType seperti yang didokumentasikan di sys.column_store_segments ).
Versi =1 encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1.000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =511
NullValue =-1 OnDiskSize =37944 Jumlah Baris =32256
Bagian RLE menunjukkan tidak ada data RLE , hanya penunjuk ke wilayah yang sedikit penuh, dan entri kosong untuk nilai nol:
Judul RLE:
Jenis Lob =3 Jumlah Array RLE (Dalam hal Unit Asli) =2
Ukuran Entri Array RLE =8
Data RLE:
Indeks =0 Bitpack Array Index =0 Hitungan =32256
Indeks =1 Nilai =0 Hitungan =0
Header Data Bitpack bagian menunjukkan ukuran bitpack 9 dan 4.608 unit bitpack yang digunakan:
Judul Data Bitpack:
Ukuran Entri Bitpack =9 Jumlah Unit Bitpack =4608 Bitpack MinId =3
Bitpack DataSize =36864
Data Bitpack bagian menunjukkan nilai yang disimpan dalam dua unit bitpack pertama seperti yang diminta oleh dua parameter terakhir ke DBCC CSINDEX memerintah. Ingatlah bahwa setiap unit 64-bit dapat menampung 7 subunit (bernomor 0 hingga 6) dari masing-masing 9 bit (7 x 9 =63 bit). 4.608 unit secara keseluruhan menampung 4.608 * 7 =32.256 baris:
Unit 0 SubUnit 0 =383
Unit 0 SubUnit 1 =255
Unit 0 SubUnit 2 =127
Unit 0 SubUnit 3 =510
Unit 0 SubUnit 4 =381
Unit 0 SubUnit 5 =253
Unit 0 SubUnit 6 =125
Unit 1 SubUnit 0 =508
Unit 1 SubUnit 1 =379
Unit 1 SubUnit 2 =251
Unit 1 SubUnit 3 =123
Unit 1 SubUnit 4 =506
Unit 1 SubUnit 5 =377
Unit 1 SubUnit 6 =249
Karena kunci pengelompokan menggunakan bit-packing dengan ukuran kurang dari atau sama dengan 10 , kami mengharapkan penurunan agregat yang dikelompokkan untuk bekerja di sini. Memang, rencana eksekusi menunjukkan semua baris dikumpulkan secara lokal di Pemindaian Indeks Columnstore operator:

Paket xml berisi ActualLocallyAggregatedRows="32256" dalam informasi runtime untuk pemindaian indeks.
Tes 2:Tanpa pushdown, Kunci Tidak Murni 12-bit
Tes ini mengubah @values parameter ke 1025, menjaga @dupes di 63. Ini memberikan tabel 64.575 baris, dengan 1.025 nilai berbeda di kolom c2 berjalan dari 0 hingga 1024 inklusif. Setiap nilai dalam c2 digandakan 63 kali .
SQL Server menyimpan c2 data kolom menggunakan:
- Encoding kamus karena ada sejumlah besar nilai duplikat.
- Tidak ada RLE . Jumlah duplikat (63) per nilai tidak mencapai ambang 64 yang diperlukan untuk RLE.
- Sedikit dikemas dengan ukuran 12 . 1.025 entri kamus yang berbeda tidak akan muat dalam 10 bit (2^10 =1.024). Mereka akan muat dalam 11 bit tetapi SQL Server tidak mendukung ukuran pengepakan bit itu seperti yang disebutkan sebelumnya. Ukuran terkecil berikutnya adalah 12 bit. Menggunakan unit 64-bit dengan batas keras untuk pengepakan bit, tidak ada lagi subunit 11-bit yang dapat ditampung dalam 64 bit dibandingkan dengan subunit 12-bit. Either way, 5 subunit akan muat dalam unit 64-bit.
DBCC CSINDEX output mengkonfirmasi analisis di atas:
Versi =1 encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1.000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =1024
NullValue =-1 OnDiskSize =104400 Jumlah Baris =64575
Judul RLE:
Jenis Lob =3 Jumlah Array RLE (Dalam hal Unit Asli) =2
Ukuran Entri Array RLE =8
Data RLE:
Indeks =0 Bitpack Array Indeks =0 Hitungan =64575
Indeks =1 Nilai =0 Hitungan =0
Judul Data Bitpack:
Ukuran Entri Bitpack =12 Jumlah Unit Bitpack =12915 Bitpack MinId =3
Bitpack DataSize =103320
Data Bitpack:
Unit 0 SubUnit 0 =767
Unit 0 SubUnit 1 =510
Unit 0 SubUnit 2 =254
Unit 0 SubUnit 3 =1021
Unit 0 SubUnit 4 =765
Unit 1 SubUnit 0 =507
Unit 1 SubUnit 1 =250
Unit 1 SubUnit 2 =1019
Unit 1 SubUnit 3 =761
Unit 1 SubUnit 4 =505
Sejak tidak murni kunci pengelompokan memiliki ukuran lebih dari 10 , kami mengharapkan penurunan agregat yang dikelompokkan tidak bekerja di sini. Ini dikonfirmasi oleh rencana eksekusi yang menunjukkan nol baris yang dikumpulkan secara lokal di Pemindaian Indeks Toko Kolom operator:
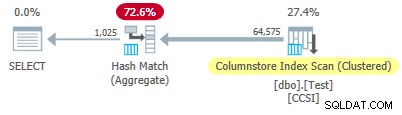
Semua 64.575 baris dipancarkan (dalam batch) oleh Columnstore Index Scan dan dikumpulkan dalam mode batch oleh Hash Match Aggregate operator. ActualLocallyAggregatedRows atribut hilang dari informasi runtime paket xml untuk pemindaian indeks.
Tes 3:Pushdown, Kunci Murni
Tes ini mengubah @dupes parameter 63-64 untuk memungkinkan RLE. @values parameter diubah menjadi 16.384 (maksimum untuk jumlah total baris yang masih muat dalam satu grup baris). Nomor tepat yang dipilih untuk @values tidak penting — intinya adalah menghasilkan 64 duplikat dari setiap nilai unik sehingga RLE dapat digunakan.
SQL Server menyimpan c2 data kolom menggunakan:
- Encoding kamus karena nilai duplikat.
- RLE. Digunakan untuk setiap nilai yang berbeda karena masing-masing memenuhi ambang 64.
- Tidak ada data yang dikemas sedikit . Jika ada, akan menggunakan ukuran 16. Ukuran 12 tidak cukup besar (2^12 =4.096 nilai yang berbeda) dan ukuran 21 akan boros. 16.384 nilai yang berbeda akan muat dalam 14 bit tetapi, seperti sebelumnya, tidak ada lagi yang dapat ditampung dalam unit 64-bit selain subunit 16-bit.
DBCC CSINDEX output mengkonfirmasi hal di atas (hanya beberapa entri RLE dan bookmark yang ditampilkan karena alasan ruang):
Versi =1 encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1.000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =16383
NullValue =-1 OnDiskSize =131648 Jumlah Baris =1048576
Judul RLE:
Jenis Lob =3 Jumlah Array RLE (Dalam hal Unit Asli) =16385
Ukuran Entri Array RLE =8
Data RLE:
Indeks =0 Nilai =3 Hitung =64
Indeks =1 Nilai =1538 Hitung =64
Indeks =2 Nilai =3072 Hitung =64
Indeks =3 Nilai =4608 Hitung =64
Indeks =4 Nilai =6142 Hitungan =64
…
Indeks =16381 Nilai =8954 Hitungan =64
Indeks =16382 Nilai =10489 Hitungan =64
Indeks =16383 Nilai =12025 Hitungan =64
Indeks =16384 Nilai =0 Hitungan =0
Tajuk Bookmark:
Jumlah Bookmark =65 Jarak Bookmark =16384 Ukuran Bookmark =520
Data Penanda:
Posisi =0 Indeks =64
Posisi =512 Indeks =16448
Posisi =1024 Indeks =32832
…
Posisi =31744 Indeks =1015872
Posisi =32256 Indeks =1032256
Posisi =32768 Indeks =1048577
Judul Data Bitpack:
Ukuran Entri Bitpack =16 Jumlah Unit Bitpack =0 Bitpack MinId =3
Bitpack DataSize =0
Karena kunci pengelompokan murni (RLE digunakan), penurunan agregat yang dikelompokkan diharapkan di sini. Rencana eksekusi mengonfirmasi hal ini dengan menampilkan semua baris yang diagregasi secara lokal di Pemindaian Indeks Toko Kolom operator:
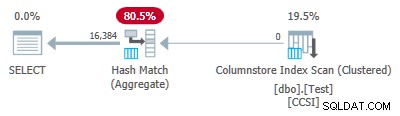
Paket xml berisi ActualLocallyAggregatedRows="1048576" dalam informasi runtime untuk pemindaian indeks.
Uji 4:Kunci Tidak Murni 10-bit
Tes ini menetapkan @values ke 1024 dan @dupes hingga 63, memberikan tabel 64.512 baris, dengan 1.024 nilai berbeda di kolom c2 dengan nilai dari 0 hingga 1.023 inklusif. Setiap nilai dalam c2 digandakan 63 kali .
Yang terpenting , indeks cluster b-tree sekarang dibuat pada kolom c1 bukannya kolom c2 . Penyimpanan kolom berkerumun masih menggantikan indeks berkerumun b-tree. Ini adalah bagian skrip yang diubah:
-- Perhatikan kolom c1 sekarang!BUAT CCSI CLUSTERED INDEX PADA dbo.Test (c1);GOCREATE CLUSTERED COLUMNSTORE INDEX CCSI PADA dbo.TestWITH (MAXDOP =1, DROP_EXISTING =ON);
SQL Server menyimpan c2 data kolom menggunakan:
- Encoding kamus karena duplikat.
- Tidak ada RLE . Jumlah duplikat (63) per nilai tidak mencapai ambang 64 yang diperlukan untuk RLE.
- Pengemasan kecil dengan ukuran 10 . 1.024 entri kamus yang berbeda benar-benar muat dalam 10 bit (2^10 =1.024). Enam subunit masing-masing 10 bit dapat disimpan di setiap unit 64-bit.
DBCC CSINDEX keluarannya adalah:
Versi =1 encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1.000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =1023
NullValue =-1 OnDiskSize =87096 Jumlah Baris =64512
Judul RLE:
Jenis Lob =3 Jumlah Array RLE (Dalam hal Unit Asli) =2
Ukuran Entri Array RLE =8
Data RLE:
Indeks =0 Bitpack Array Index =0 Hitungan =64512
Indeks =1 Nilai =0 Hitungan =0
Judul Data Bitpack:
Ukuran Entri Bitpack =10 Jumlah Unit Bitpack =10752 Bitpack MinId =3
Bitpack DataSize =86016
Data Bitpack:
Unit 0 SubUnit 0 =766
Unit 0 SubUnit 1 =509
Unit 0 SubUnit 2 =254
Unit 0 SubUnit 3 =1020
Unit 0 SubUnit 4 =764
Unit 0 SubUnit 5 =506
Unit 1 SubUnit 0 =250
Unit 1 SubUnit 1 =1018
Unit 1 SubUnit 2 =760
Unit 1 SubUnit 3 =504
Unit 1 SubUnit 4 =247
Unit 1 SubUnit 5 =1014
Sejak tidak murni kunci pengelompokan menggunakan ukuran kurang dari atau sama dengan 10, kami mengharapkan tekan bawah agregat yang dikelompokkan untuk bekerja di sini. Tapi itu bukan itu yang terjadi . Rencana eksekusi menunjukkan 54.612 dari 64.512 baris digabungkan di Hash Match Aggregate operator:
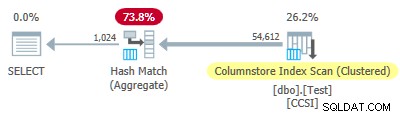
Paket xml berisi ActualLocallyAggregatedRows="9900" dalam informasi runtime untuk pemindaian indeks. Ini berarti penurunan agregat yang dikelompokkan digunakan untuk 9.900 baris, tetapi tidak digunakan untuk 54.612 lainnya!
Mekanisme umpan balik
SQL Server dimulai menggunakan penurunan agregat yang dikelompokkan untuk eksekusi ini karena kunci pengelompokan tidak murni memenuhi kriteria 10-bit-atau-kurang. Ini berlangsung dengan total 11 batch (masing-masing 900 baris =total 9.900 baris). Pada saat itu, mekanisme umpan balik yang mengukur efektivitas penurunan agregat yang dikelompokkan memutuskan itu tidak berhasil, dan mematikannya . Batch yang tersisa semuanya diproses dengan pushdown dinonaktifkan.
Umpan balik pada dasarnya membandingkan jumlah baris yang dikumpulkan dengan jumlah kelompok yang dihasilkan. Ini dimulai dengan nilai 100 dan disesuaikan pada akhir setiap batch keluaran pushdown. Jika nilainya turun ke 10 atau lebih rendah, tekan ke bawah dinonaktifkan untuk operasi pengelompokan saat ini.
'Ukuran manfaat push-down' berkurang kurang lebih tergantung pada seberapa buruk upaya agregasi push-down berjalan. Jika rata-rata ada kurang dari 8 baris per kunci pengelompokan dalam kumpulan keluaran, nilai manfaat saat ini berkurang sebesar 22%. Jika ada lebih dari 8 tetapi kurang dari 16, metrik dikurangi 11%.
Di sisi lain, jika keadaan membaik, dan 16 baris atau lebih per kunci pengelompokan selanjutnya ditemukan untuk kumpulan keluaran, metrik diatur ulang ke 100, dan terus disesuaikan karena kumpulan agregat parsial dihasilkan oleh pemindaian.
Data dalam pengujian ini disajikan dalam urutan yang sangat tidak membantu untuk pushdown karena indeks berkerumun b-tree asli pada kolom c1 . Saat disajikan dengan cara ini, nilai di kolom c2 mulai dari 0 dan bertambah 1 hingga mencapai 1.023, lalu mereka memulai siklus lagi. 1.023 nilai yang berbeda lebih dari cukup untuk memastikan setiap batch keluaran 900 baris hanya berisi satu baris gabungan sebagian untuk setiap kunci. Ini bukan keadaan bahagia.
Jika ada 64 duplikat per nilai, bukan 63, SQL Server akan mempertimbangkan pengurutan berdasarkan c2 sambil membangun indeks columnstore, dan dengan demikian menghasilkan kompresi RLE. Karena itu, penalti 22% berlaku setelah setiap batch. Mulai dari 100 dan menggunakan aritmatika bilangan bulat pembulatan yang sama, urutan nilai metriknya adalah:
-- @metric :=LANTAI(@metrik * 0.78 + 0.5);-- 100, 78, 61, 48, 37, 29, 23, 18, 14, 11, *9*
Batch kesebelas mengurangi metrik menjadi 10 atau lebih rendah, dan pushdown dinonaktifkan. 11 kumpulan dari 900 baris memperhitungkan 9.900 baris agregat lokal yang ditampilkan dalam rencana eksekusi.
Variasi dengan 900 nilai berbeda
Perilaku yang sama dapat dilihat pada pengujian 4 dengan sedikitnya 901 nilai yang berbeda, dengan asumsi baris-baris tersebut disajikan dalam urutan yang tidak membantu.
Mengubah @values parameter ke 900 sambil menjaga semuanya tetap sama memiliki efek dramatis pada rencana eksekusi:
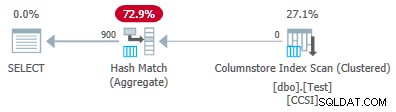
Sekarang semua 900 grup dikumpulkan saat pemindaian! Properti paket xml menampilkan ActualLocallyAggregatedRows="56700" . Ini karena pushdown agregat yang dikelompokkan mempertahankan 900 kunci pengelompokan dan agregat parsial dalam satu kumpulan. Itu tidak pernah menemukan nilai kunci baru tidak dalam kumpulan, jadi tidak ada alasan untuk memulai kumpulan keluaran baru.
Only ever producing one batch means the feedback mechanism never gets chance to reduce the “pushdown benefit measure” to the point where grouped aggregate pushdown is disabled. It never would anyway, since the pushdown is very successful — 56,700 rows for 900 grouping keys is 63 per key, well above the threshold for benefit measure reduction.
Extended Event
There is very little information available in execution plans to help determine why grouped aggregation pushdown was either not tried, or was not successful. There is, however, an Extended Event named query_execution_dynamic_push_down_statistics in the execution category of the Analytic channel.
It provides the following Event Fields:
rows_not_pushed_down_due_to_encoding
Description:Number of rows not pushed to scan because of the the total encoded key length.
This identifies impure data over the 10-bit limit as shown in test 2.
rows_not_pushed_down_due_to_possible_overflow
Description:Number of rows not pushed to scan because of a possible overflow
rows_not_pushed_down_due_to_pushdown_disabled
Description:Number of rows not pushed to scan (only) because dynamic pushdown was disabled
This occurs when the pushdown benefit measure drops below 10 as described in test 4.
rows_pushed_down_in_thread
Description:Number of locally aggregated rows in thread
This corresponds with the value for ‘locally aggregated rows’ shown in execution plans.
Catatan: No event is recorded if grouped aggregation pushdown is specifically disabled using trace flag 9373. All types of pushdown to a nonclustered columnstore index can be specifically disabled with trace flag 9386. All types of pushdown activity can be disabled with trace flag 9354.