Saya menulis sebelumnya tentang properti Baca Baris Aktual. Ini memberi tahu Anda berapa banyak baris yang benar-benar dibaca oleh Pencarian Indeks, sehingga Anda dapat melihat seberapa selektif Predikat Seek, dibandingkan dengan selektifitas gabungan Predikat Seek plus Predikat Residual.
Tapi mari kita lihat apa yang sebenarnya terjadi di dalam operator Seek. Karena saya tidak yakin bahwa "Bacaan Baris yang Sebenarnya" merupakan deskripsi yang akurat tentang apa yang sedang terjadi.
Saya ingin melihat contoh bahwa kueri alamat jenis alamat tertentu untuk pelanggan, tetapi prinsip di sini akan dengan mudah diterapkan ke banyak situasi lain jika bentuk kueri Anda cocok, seperti mencari atribut dalam tabel Pasangan Nilai Kunci, misalnya.
SELECT AddressTypeID, FullAddress FROM dbo.Addresses WHERE CustomerID = 783 AND AddressTypeID IN (2,4,5);
Saya tahu saya belum menunjukkan apa pun tentang metadata – saya akan kembali ke sana sebentar lagi. Mari kita pikirkan tentang kueri ini dan jenis indeks apa yang ingin kita miliki untuknya.
Pertama, kita tahu CustomerID dengan tepat. Pencocokan kesetaraan seperti ini umumnya menjadikannya kandidat yang sangat baik untuk kolom pertama dalam indeks. Jika kami memiliki indeks di kolom ini, kami dapat langsung masuk ke alamat untuk pelanggan itu – jadi menurut saya itu asumsi yang aman.
Hal berikutnya yang perlu diperhatikan adalah filter pada AddressTypeID. Menambahkan kolom kedua ke kunci indeks kami sangat masuk akal, jadi mari kita lakukan itu. Indeks kami sekarang aktif (ID Pelanggan, AddressTypeID). Dan mari TERMASUK FullAddress juga, sehingga kita tidak perlu melakukan pencarian untuk melengkapi gambar.
Dan saya pikir kita sudah selesai. Kita harus dapat mengasumsikan dengan aman bahwa indeks ideal untuk kueri ini adalah:
CREATE INDEX ixIdealIndex ON dbo.Addresses (CustomerID, AddressTypeID) INCLUDE (FullAddress);
Kami berpotensi mendeklarasikannya sebagai indeks unik – kami akan melihat dampaknya nanti.
Jadi mari kita buat tabel (saya menggunakan tempdb, karena saya tidak membutuhkannya untuk bertahan di luar posting blog ini) dan mengujinya.
CREATE TABLE dbo.Addresses ( AddressID INT IDENTITY(1,1) PRIMARY KEY, CustomerID INT NOT NULL, AddressTypeID INT NOT NULL, FullAddress NVARCHAR(MAX) NOT NULL, SomeOtherColumn DATE NULL );
Saya tidak tertarik dengan batasan kunci asing, atau kolom lain yang mungkin ada. Saya hanya tertarik dengan Indeks Ideal saya. Jadi buat itu juga, jika Anda belum melakukannya.
Rencana saya tampaknya cukup sempurna.
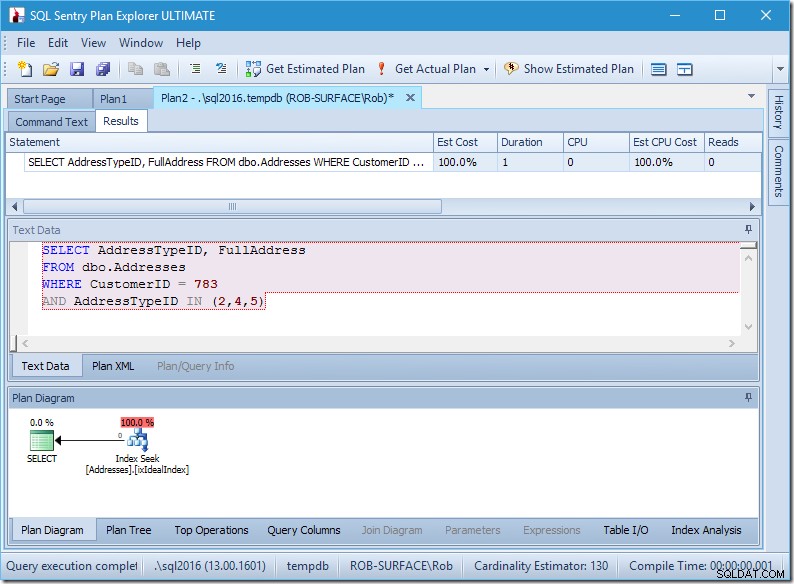
Saya memiliki pencarian indeks, dan hanya itu.
Memang, tidak ada data, jadi tidak ada pembacaan, tidak ada CPU, dan itu berjalan cukup cepat juga. Andai saja semua pertanyaan dapat disetel sebaik ini.
Mari kita lihat apa yang terjadi sedikit lebih dekat, dengan melihat properti Seek.
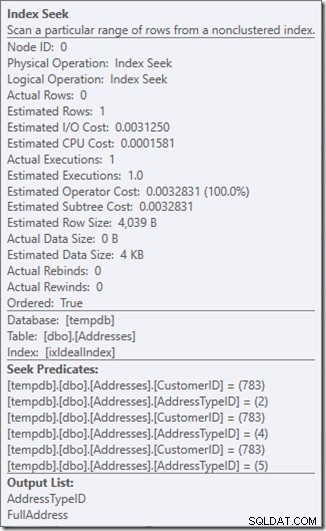
Kita bisa melihat Predikat Seek. Ada enam. Tiga tentang CustomerID, dan tiga tentang AddressTypeID. Apa yang sebenarnya kita miliki di sini adalah tiga set predikat pencarian, yang menunjukkan tiga operasi pencarian dalam operator Seek tunggal. Pencarian pertama mencari Pelanggan 783 dan Tipe Alamat 2. Pencarian kedua mencari 783 dan 4, dan pencarian terakhir 783 dan 5. Operator Pencarian kami muncul sekali, tetapi ada tiga pencarian yang terjadi di dalamnya.
Kami bahkan tidak memiliki data, tetapi kami dapat melihat bagaimana indeks kami akan digunakan.
Mari kita masukkan beberapa data dummy, sehingga kita dapat melihat beberapa dampaknya. Saya akan memasukkan alamat untuk tipe 1 sampai 6. Setiap pelanggan (lebih dari 2000, berdasarkan ukuran master..spt_values ) akan memiliki alamat tipe 1. Mungkin itu Alamat Utama. Saya membiarkan 80% memiliki alamat tipe 2, 60% tipe 3, dan seterusnya, hingga 20% untuk tipe 5. Baris 783 akan mendapatkan alamat tipe 1, 2, 3, dan 4, tetapi tidak 5. Saya lebih suka menggunakan nilai acak, tetapi saya ingin memastikan bahwa kita berada di halaman yang sama untuk contoh.
WITH nums AS (
SELECT row_number() OVER (ORDER BY (SELECT 1)) AS num
FROM master..spt_values
)
INSERT dbo.Addresses (CustomerID, AddressTypeID, FullAddress)
SELECT num AS CustomerID, 1 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
UNION ALL
SELECT num AS CustomerID, 2 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 8
UNION ALL
SELECT num AS CustomerID, 3 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 6
UNION ALL
SELECT num AS CustomerID, 4 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 4
UNION ALL
SELECT num AS CustomerID, 5 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 2
; Sekarang mari kita lihat kueri kita dengan data. Dua baris keluar. Ini seperti sebelumnya, tetapi sekarang kita melihat dua baris keluar dari operator Seek, dan kita melihat enam bacaan (di kanan atas).
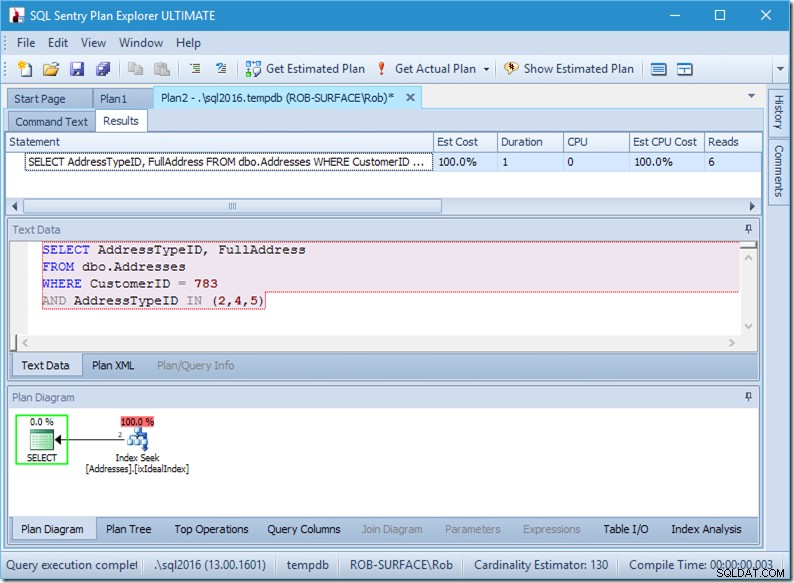
Enam bacaan masuk akal bagi saya. Kami memiliki meja kecil, dan indeks hanya cocok di dua tingkat. Kami melakukan tiga pencarian (dalam satu operator kami), jadi mesin membaca halaman root, mencari tahu halaman mana yang harus dibuka dan membacanya, dan melakukannya tiga kali.
Jika kita hanya mencari dua AddressTypeIDs, kita hanya akan melihat 4 pembacaan (dan dalam hal ini, satu baris dikeluarkan). Luar biasa.
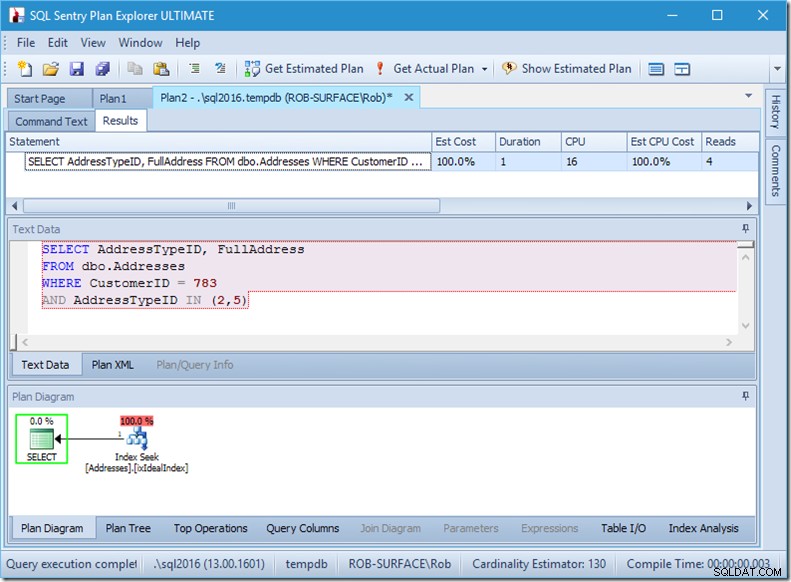
Dan jika kita mencari 8 jenis alamat, maka kita akan melihat 16.
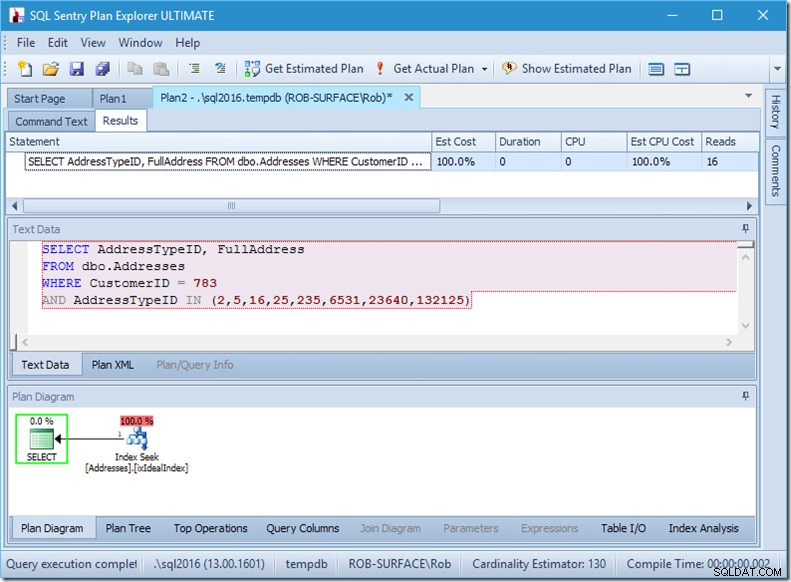
Namun masing-masing menunjukkan bahwa Baris Aktual yang Dibaca sama persis dengan Baris Aktual. Tidak ada inefisiensi sama sekali!
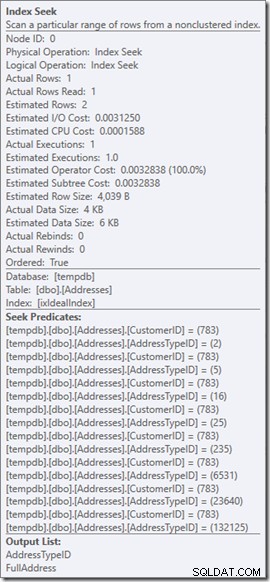
Mari kembali ke kueri awal kita, mencari tipe alamat 2, 4, dan 5, (yang mengembalikan 2 baris) dan memikirkan apa yang terjadi di dalam pencarian.
Saya akan berasumsi bahwa Mesin Kueri telah melakukan pekerjaan untuk mengetahui bahwa Pencarian Indeks adalah operasi yang tepat, dan memiliki nomor halaman akar indeks yang berguna.
Pada titik ini, itu memuat halaman itu ke dalam memori, jika belum ada di sana. Itu adalah pembacaan pertama yang dihitung dalam eksekusi seek. Kemudian ia menemukan nomor halaman untuk baris yang dicarinya, dan membaca halaman itu di dalamnya. Itu adalah pembacaan kedua.
Tapi kita sering mengabaikan bit 'menemukan nomor halaman'.
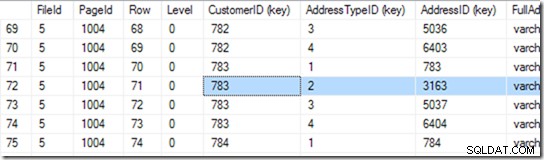
Dengan menggunakan DBCC IND(2, N'dbo.Address', 2); (2 pertama adalah id database karena saya menggunakan tempdb; 2 kedua adalah id indeks dari ixIdealIndex ), saya dapat menemukan bahwa 712 dalam file 1 adalah halaman dengan IndexLevel tertinggi. Pada tangkapan layar di bawah, saya dapat melihat bahwa halaman 668 adalah IndexLevel 0, yang merupakan halaman root.

Jadi sekarang saya bisa menggunakan DBCC TRACEON(3604); DBCC PAGE (2,1,712,3); untuk melihat isi halaman 712. Pada mesin saya, saya mendapatkan 84 baris kembali, dan saya dapat memberitahu bahwa CustomerID 783 akan berada di halaman 1004 dari file 5.
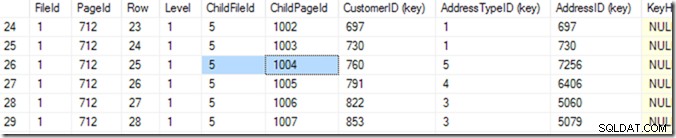
Tapi saya tahu ini dengan menggulir daftar saya sampai saya melihat yang saya inginkan. Saya mulai dengan menggulir sedikit ke bawah, dan kemudian kembali ke atas, sampai saya menemukan baris yang saya inginkan. Komputer menyebutnya pencarian biner, dan ini sedikit lebih tepat daripada saya. Ini mencari baris di mana kombinasi (CustomerID, AddressTypeID) lebih kecil dari yang saya cari, dengan halaman berikutnya lebih besar atau sama dengan itu. Saya katakan "sama" karena mungkin ada dua yang cocok, tersebar di dua halaman. Ia tahu ada 84 baris (0 hingga 83) data di halaman itu (terbaca di header halaman), jadi itu akan mulai dengan memeriksa baris 41. Dari sana, ia tahu bagian mana yang harus dicari, dan (di contoh ini), ia akan membaca baris 20. Beberapa bacaan lagi (total menjadi 6 atau 7)* dan ia mengetahui bahwa baris 25 (silakan lihat kolom yang disebut 'Baris' untuk nilai ini, bukan nomor baris yang disediakan oleh SSMS ) terlalu kecil, tetapi baris 26 terlalu besar – jadi 25 adalah jawabannya!
*Dalam pencarian biner, pencarian bisa sedikit lebih cepat jika beruntung ketika membagi blok menjadi dua jika tidak ada slot tengah, dan tergantung pada apakah slot tengah dapat dihilangkan atau tidak.
Sekarang sudah bisa masuk ke halaman 1004 di file 5. Mari kita gunakan DBCC PAGE yang satu itu.
Yang ini memberi saya 94 baris. Itu melakukan pencarian biner lain untuk menemukan awal dari rentang yang dicarinya. Itu harus melihat melalui 6 atau 7 baris untuk menemukannya.
"Mulai dari jangkauan?" Saya bisa mendengar Anda bertanya. Tapi kami sedang mencari alamat tipe 2 dari pelanggan 783.
Benar, tetapi kami tidak mendeklarasikan indeks ini sebagai unik. Jadi mungkin ada dua. Jika unik, pencarian dapat melakukan pencarian tunggal, dan dapat tersandung selama pencarian biner, tetapi dalam kasus ini, pencarian biner harus diselesaikan, untuk menemukan baris pertama dalam jangkauan. Dalam hal ini, ini adalah baris 71.
Tapi kami tidak berhenti di sini. Sekarang kita perlu melihat apakah memang ada yang kedua! Jadi ia membaca baris 72 juga, dan menemukan bahwa pasangan CustomerID+AddressTypeiD memang terlalu besar, dan pencariannya selesai.
Dan ini terjadi tiga kali. Ketiga kalinya, tidak menemukan baris untuk pelanggan 783 dan tipe alamat 5, tetapi tidak mengetahuinya sebelumnya, dan masih perlu menyelesaikan pencarian.
Jadi baris yang benar-benar dibaca di ketiga pencarian ini (untuk menemukan dua baris untuk output) jauh lebih banyak daripada jumlah yang dikembalikan. Ada sekitar 7 di tingkat indeks 1, dan sekitar 7 lagi di tingkat daun hanya untuk menemukan awal kisaran. Kemudian ia membaca baris yang kita pedulikan, dan kemudian baris setelah itu. Kedengarannya lebih seperti 16 bagi saya, dan ini dilakukan tiga kali, menghasilkan sekitar 48 baris.
Tetapi Pembacaan Baris Aktual bukan tentang jumlah baris yang benar-benar dibaca, tetapi jumlah baris yang dikembalikan oleh Predikat Seek, yang diuji terhadap Predikat Residual. Dan dalam hal itu, hanya 2 baris yang ditemukan oleh 3 pencarian.
Anda mungkin berpikir pada titik ini bahwa ada sejumlah ketidakefektifan di sini. Pencarian kedua juga akan membaca halaman 712, memeriksa 6 atau 7 baris yang sama di sana, dan kemudian membaca halaman 1004, dan menelusurinya… seperti pencarian ketiga.
Jadi mungkin akan lebih baik untuk mendapatkan ini dalam satu pencarian, membaca halaman 712 dan halaman 1004 hanya sekali masing-masing. Lagi pula, jika saya melakukan ini dengan sistem berbasis kertas, saya akan mencari pelanggan 783, dan kemudian memindai semua jenis alamat mereka. Karena saya tahu bahwa seorang pelanggan cenderung tidak memiliki banyak alamat. Itu keuntungan yang saya miliki dibandingkan mesin database. Mesin basis data mengetahui melalui statistiknya bahwa pencarian akan menjadi yang terbaik, tetapi tidak mengetahui bahwa pencarian hanya boleh turun satu tingkat, ketika dapat mengatakan bahwa ia memiliki apa yang tampak seperti Indeks Ideal.
Jika saya mengubah kueri saya untuk mengambil berbagai jenis alamat, dari 2 hingga 5, maka saya hampir mendapatkan perilaku yang saya inginkan:
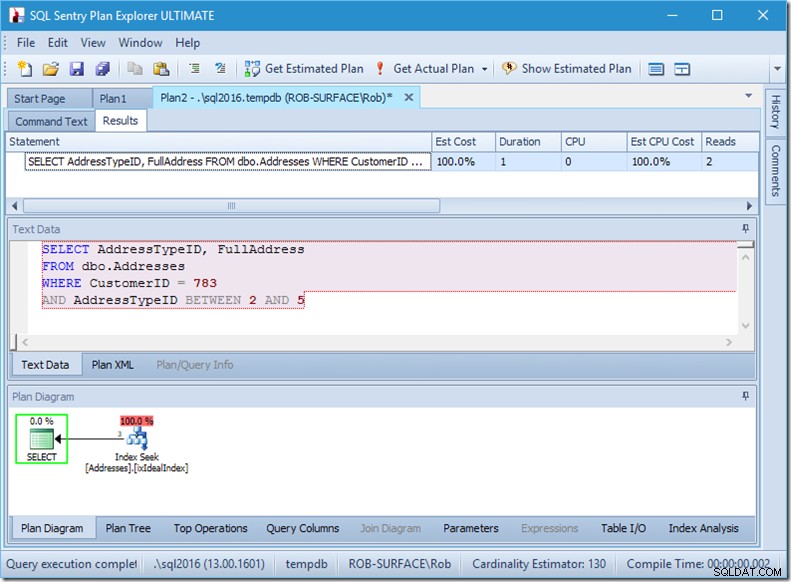
Lihat – bacaannya turun menjadi 2, dan saya tahu halaman mana itu…
…tapi hasil saya salah. Karena saya hanya ingin alamat tipe 2, 4, dan 5, bukan 3. Saya harus mengatakannya agar tidak memiliki 3, tetapi saya harus berhati-hati bagaimana melakukan ini. Lihat dua contoh berikut.
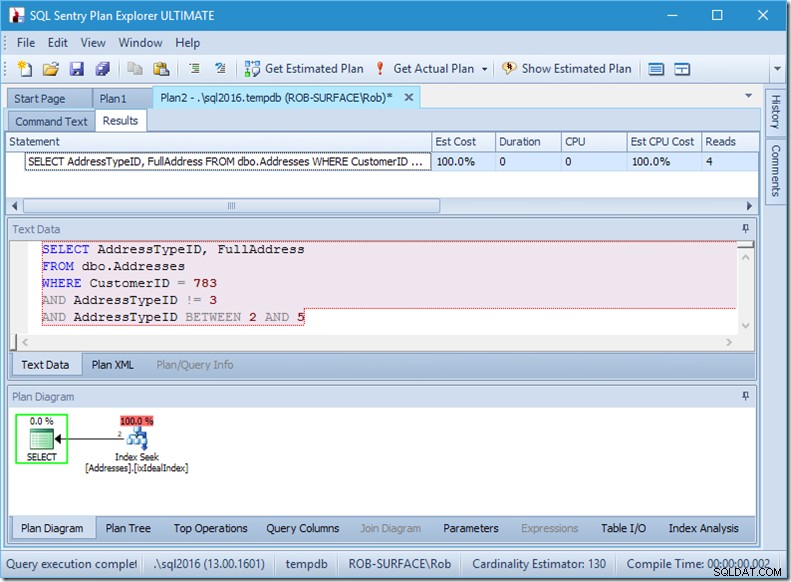
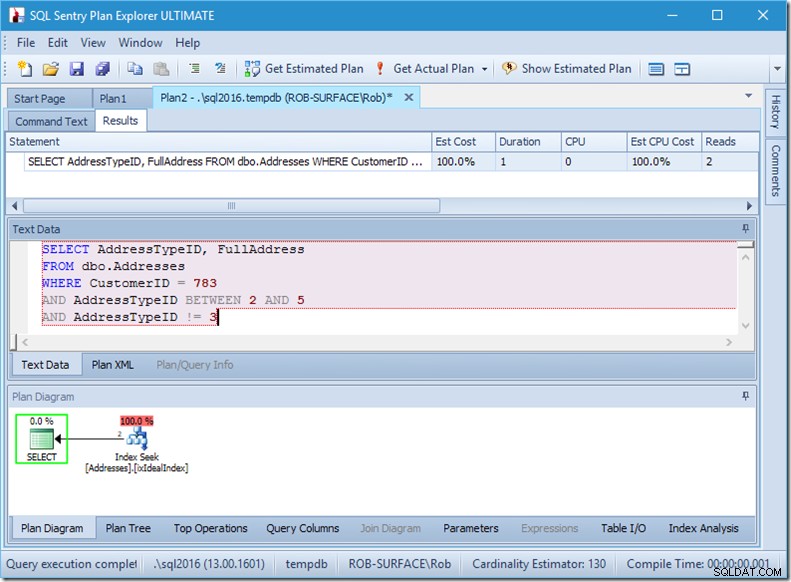
Saya dapat meyakinkan Anda bahwa urutan predikat tidak masalah, tetapi di sini jelas. Jika kita menempatkan "bukan 3" terlebih dahulu, ia melakukan dua pencarian (4 pembacaan), tetapi jika kita menempatkan "bukan 3" kedua, ia melakukan pencarian tunggal (2 pembacaan).
Masalahnya adalah AddressTypeID !=3 dikonversi menjadi (AddressTypeID> 3 OR AddressTypeID <3), yang kemudian dilihat sebagai dua predikat pencarian yang sangat berguna.
Jadi preferensi saya adalah menggunakan predikat non-sargable untuk mengatakan bahwa saya hanya menginginkan tipe alamat 2, 4, dan 5. Dan saya dapat melakukannya dengan memodifikasi AddressTypeID dalam beberapa cara, seperti menambahkan nol padanya.
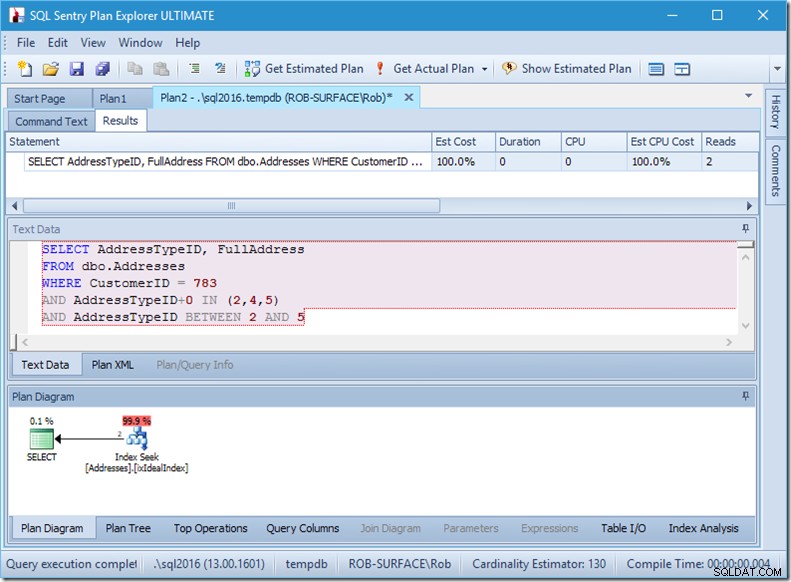
Sekarang saya memiliki pemindaian rentang yang bagus dan ketat dalam satu pencarian, dan saya masih memastikan bahwa kueri saya hanya mengembalikan baris yang saya inginkan.
Oh, tapi itu properti Actual Rows Read? Itu sekarang lebih tinggi dari properti Baris Aktual, karena Predikat Seek menemukan alamat tipe 3, yang ditolak oleh Predikat Residual.
Saya telah menukar tiga pencarian sempurna untuk satu pencarian tidak sempurna, yang saya perbaiki dengan predikat residual.
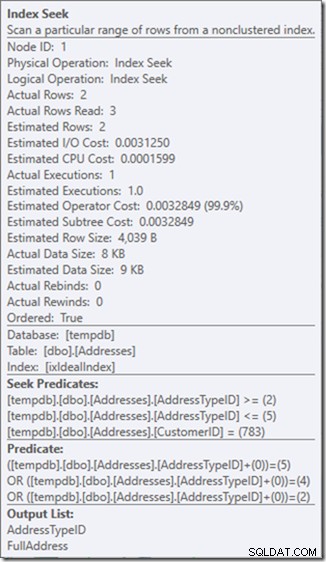
Dan bagi saya, itu terkadang merupakan harga yang pantas dibayar, memberi saya rencana kueri yang jauh lebih menyenangkan bagi saya. Itu tidak jauh lebih murah, meskipun hanya sepertiga dari pembacaan (karena hanya akan ada dua pembacaan fisik), tetapi ketika saya memikirkan pekerjaan yang dilakukannya, saya jauh lebih nyaman dengan apa yang saya tanyakan. untuk melakukan cara ini.