Artikel ini adalah yang ketiga dari seri tentang ambang pengoptimalan untuk mengelompokkan dan menggabungkan data. Di Bagian 1 saya membahas algoritma Stream Aggregate yang telah dipesan sebelumnya. Di Bagian 2 saya membahas algoritma Sort + Stream Aggregate yang tidak dipesan sebelumnya. Di bagian ini saya membahas algoritma Hash Match (Aggregate), yang akan saya sebut sebagai Hash Aggregate. Saya juga memberikan ringkasan dan perbandingan antara algoritma yang saya bahas di Bagian 1, Bagian 2, dan Bagian 3.
Saya akan menggunakan database sampel yang sama yang disebut PerformanceV3, yang saya gunakan di artikel sebelumnya dalam seri ini. Pastikan bahwa sebelum Anda menjalankan contoh di artikel, Anda terlebih dahulu menjalankan kode berikut untuk menghapus beberapa indeks yang tidak diperlukan:
DROP INDEX idx_nc_sid_od_cid ON dbo.Orders; DROP INDEX idx_unc_od_oid_i_cid_eid ON dbo.Orders;
Hanya dua indeks yang harus ditinggalkan pada tabel ini adalah idx_cl_od (dikelompokkan dengan orderdate sebagai kuncinya) dan PK_Orders (tidak dikelompokkan dengan orderid sebagai kuncinya).
Hash Agregat
Algoritma Hash Aggregate mengatur grup dalam tabel hash berdasarkan beberapa fungsi hash yang dipilih secara internal. Tidak seperti algoritma Stream Aggregate, tidak perlu menggunakan baris dalam urutan grup. Pertimbangkan kueri berikut (kami akan menyebutnya Kueri 1) sebagai contoh (memaksa agregat hash dan paket serial):
SELECT empid, COUNT(*) AS numorders FROM dbo.Orders GROUP BY empid OPTION (HASH GROUP, MAXDOP 1);
Gambar 1 menunjukkan rencana untuk Query 1.
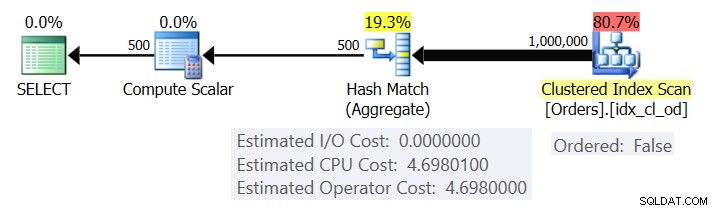
Gambar 1:Rencana untuk Kueri 1
Paket memindai baris dari indeks berkerumun menggunakan properti Dipesan:Salah (pemindaian tidak diperlukan untuk mengirimkan baris yang diurutkan oleh kunci indeks). Biasanya, pengoptimal akan lebih memilih untuk memindai indeks penutup tersempit, yang dalam kasus kami adalah indeks berkerumun. Rencananya membuat tabel hash dengan kolom dan agregat yang dikelompokkan. Kueri kami meminta agregat COUNT bertipe INT. Rencana tersebut sebenarnya menghitungnya sebagai nilai yang diketik BIGINT, oleh karena itu operator Hitung Skalar, menerapkan konversi implisit ke INT.
Microsoft tidak secara publik membagikan algoritme hash yang mereka gunakan. Ini adalah teknologi yang sangat eksklusif. Namun, untuk mengilustrasikan konsep tersebut, anggaplah SQL Server menggunakan fungsi hash % 250 (modulo 250) untuk kueri kita di atas. Sebelum memproses baris apa pun, tabel hash kami memiliki 250 ember yang mewakili 250 kemungkinan hasil dari fungsi hash (0 hingga 249). Saat SQL Server memproses setiap baris, SQL Server menerapkan fungsi hash
orderid empid ------- ----- 320 3 30 5 660 253 820 3 850 1 1000 255 700 3 1240 253 350 4 400 255
Gambar 2 menunjukkan tiga status tabel hash:sebelum setiap baris diproses, setelah 5 baris pertama diproses, dan setelah 10 baris pertama diproses. Setiap item dalam daftar tertaut menyimpan tuple (empid, COUNT(*)).
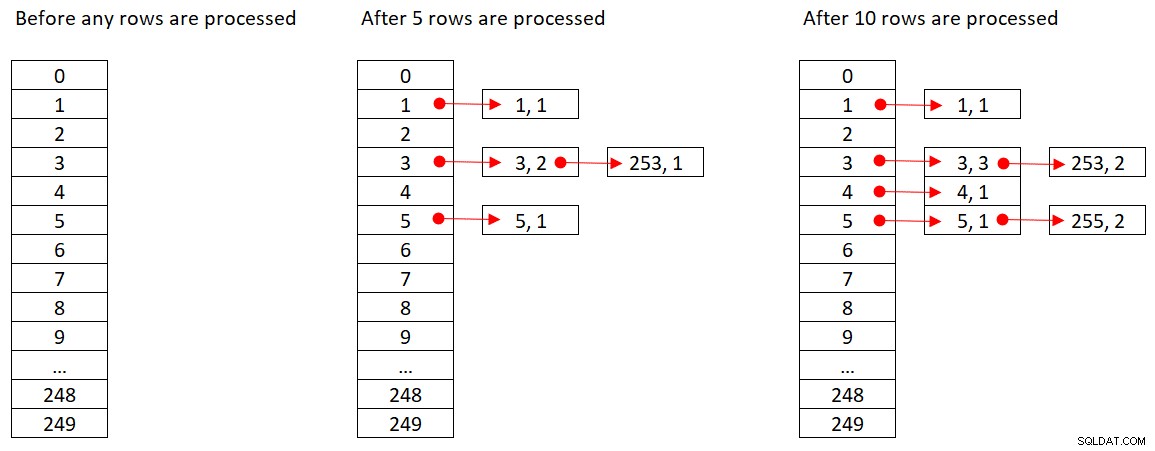
Gambar 2:Status tabel hash
Setelah operator Hash Aggregate selesai menggunakan semua baris input, tabel hash memiliki semua grup dengan status akhir agregat.
Seperti operator Sortir, operator Hash Aggregate membutuhkan hibah memori, dan jika kehabisan memori, perlu tumpah ke tempdb; namun, sementara pengurutan membutuhkan pemberian memori yang sebanding dengan jumlah baris yang akan diurutkan, hashing membutuhkan pemberian memori yang sebanding dengan jumlah grup. Jadi, terutama ketika kumpulan pengelompokan memiliki kepadatan tinggi (jumlah grup kecil), algoritme ini membutuhkan memori yang jauh lebih sedikit daripada saat pengurutan eksplisit diperlukan.
Pertimbangkan dua kueri berikut (sebut saja Kueri 1 dan Kueri 2):
SELECT empid, COUNT(*) AS numorders FROM dbo.Orders GROUP BY empid OPTION (HASH GROUP, MAXDOP 1); SELECT empid, COUNT(*) AS numorders FROM dbo.Orders GROUP BY empid OPTION (ORDER GROUP, MAXDOP 1);
Gambar 3 membandingkan pemberian memori untuk kueri ini.

Gambar 3:Rencana untuk Kueri 1 dan Kueri 2
Perhatikan perbedaan besar antara pemberian memori dalam dua kasus.
Untuk biaya operator Hash Aggregate, kembali ke Gambar 1, perhatikan bahwa tidak ada biaya I/O, melainkan hanya biaya CPU. Selanjutnya, cobalah untuk merekayasa balik rumus penetapan biaya CPU menggunakan teknik serupa dengan yang saya bahas di bagian sebelumnya dalam seri ini. Faktor-faktor yang berpotensi mempengaruhi biaya operator adalah jumlah baris input, jumlah grup keluaran, fungsi agregat yang digunakan, dan apa yang Anda kelompokkan (kardinalitas kumpulan pengelompokan, tipe data yang digunakan).
Anda mengharapkan operator ini memiliki biaya awal dalam persiapan untuk membangun tabel hash. Anda juga mengharapkannya untuk menskalakan secara linier sehubungan dengan jumlah baris dan grup. Itu memang yang saya temukan. Namun, sementara biaya operator Stream Agregat dan Sortir tidak dipengaruhi oleh apa yang Anda kelompokkan, tampaknya biaya operator Hash Aggregate adalah—baik dalam hal kardinalitas kumpulan pengelompokan dan tipe data yang digunakan.
Untuk mengamati bahwa kardinalitas kumpulan pengelompokan memengaruhi biaya operator, periksa biaya CPU operator Hash Aggregate dalam paket untuk kueri berikut (sebut saja Kueri 3 dan Kueri 4):
SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 50 AS grp1, orderid % 20 AS grp2, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 50, orderid % 20 OPTION(HASH GROUP, MAXDOP 1);
Tentu saja, Anda ingin memastikan bahwa perkiraan jumlah baris input dan grup output sama dalam kedua kasus. Perkiraan rencana untuk kueri ini ditunjukkan pada Gambar 4.
Gambar 4:Rencana untuk Kueri 3 dan Kueri 4
Seperti yang Anda lihat, biaya CPU dari operator Hash Aggregate adalah 0,16903 saat mengelompokkan menurut satu kolom bilangan bulat, dan 0,174016 saat mengelompokkan dengan dua kolom bilangan bulat, dengan yang lainnya sama. Artinya, kardinalitas himpunan pengelompokan memang mempengaruhi biaya.
Mengenai apakah tipe data dari elemen yang dikelompokkan memengaruhi biaya, saya menggunakan kueri berikut untuk memeriksanya (sebut saja Kueri 5, Kueri 6, dan Kueri 7):
SELECT CAST(orderid AS SMALLINT) % CAST(1000 AS SMALLINT) AS grp,
MAX(orderdate) AS maxod
FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D
GROUP BY CAST(orderid AS SMALLINT) % CAST(1000 AS SMALLINT)
OPTION(HASH GROUP, MAXDOP 1);
SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod
FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D
GROUP BY orderid % 1000
OPTION(HASH GROUP, MAXDOP 1);
SELECT CAST(orderid AS BIGINT) % CAST(1000 AS BIGINT) AS grp,
MAX(orderdate) AS maxod
FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D
GROUP BY CAST(orderid AS BIGINT) % CAST(1000 AS BIGINT)
OPTION(HASH GROUP, MAXDOP 1); Paket untuk ketiga kueri memiliki perkiraan jumlah baris input dan grup keluaran yang sama, namun semuanya mendapatkan perkiraan biaya CPU yang berbeda (0,121766, 0,16903, dan 0,171716), oleh karena itu jenis data yang digunakan memang memengaruhi biaya.
Jenis fungsi agregat juga tampaknya berdampak pada biaya. Misalnya, pertimbangkan dua kueri berikut (sebut saja Kueri 8 dan Kueri 9):
SELECT orderid % 1000 AS grp, COUNT(*) AS numorders FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1);
Perkiraan biaya CPU untuk Agregat Hash dalam paket untuk Kueri 8 adalah 0,166344, dan di Kueri 9 adalah 0,16903.
Ini bisa menjadi latihan yang menarik untuk mencoba dan mencari tahu dengan tepat bagaimana kardinalitas himpunan pengelompokan, tipe data, dan fungsi agregat yang digunakan mempengaruhi biaya; Saya hanya tidak mengejar aspek penetapan biaya ini. Jadi, setelah membuat pilihan kumpulan pengelompokan dan fungsi agregat untuk kueri Anda, Anda dapat merekayasa balik rumus penetapan biaya. Misalnya, mari kita rekayasa balik rumus biaya CPU untuk operator Hash Aggregate saat mengelompokkan berdasarkan satu kolom integer dan mengembalikan agregat MAX(orderdate). Rumusnya harus:
Biaya CPU operator =Dengan menggunakan teknik yang saya tunjukkan dalam artikel sebelumnya di seri ini, saya mendapatkan rumus rekayasa terbalik berikut:
Biaya CPU operator =0,017749 + @numrows * 0,00000667857 + @numgroups * 0,0000177087Anda dapat memeriksa keakuratan rumus menggunakan kueri berikut:
SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 2000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 2000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 3000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D GROUP BY orderid % 3000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 6000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D GROUP BY orderid % 6000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 5000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D GROUP BY orderid % 5000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(HASH GROUP, MAXDOP 1);
Saya mendapatkan hasil berikut:
numrows numgroups predictedcost estimatedcost ----------- ----------- -------------- -------------- 100000 1000 0.703315 0.703316 100000 2000 0.721023 0.721024 200000 3000 1.40659 1.40659 200000 6000 1.45972 1.45972 500000 5000 3.44558 3.44558 500000 10000 3.53412 3.53412
Rumusnya tampaknya tepat.
Ringkasan dan perbandingan biaya
Sekarang kami memiliki rumus biaya untuk tiga strategi yang tersedia:Stream Aggregate yang telah dipesan sebelumnya, Sort + Stream Aggregate, dan Hash Aggregate. Tabel berikut merangkum dan membandingkan karakteristik penetapan biaya dari ketiga algoritme:
Agregat Aliran yang Dipesan di muka
Urutkan + Aliran Agregat
Hash Agregat
Rumus
@numgroups * 0,0000005
Sejumlah kecil baris:
9.99127891201865E-05 + @numrows * LOG(@numrows) * 2.25061348918698E-06
Jumlah baris yang banyak:
1.35166186417734E-04 + @numrows * LOG(@numrows) * 6.62193536908588E-06
+
@numrows * 0,0000006 +
@numgroups * 0,0000005
@numrows * 0,00000667857 +
@numgroups * 0,0000177087
* Pengelompokan menurut kolom bilangan bulat tunggal, menghasilkan MAX(
Penskalaan
Biaya I/O Startup
Biaya CPU Startup
Menurut rumus ini, Gambar 5 menunjukkan cara masing-masing strategi menskalakan jumlah baris input yang berbeda, menggunakan jumlah grup tetap 500 sebagai contoh.
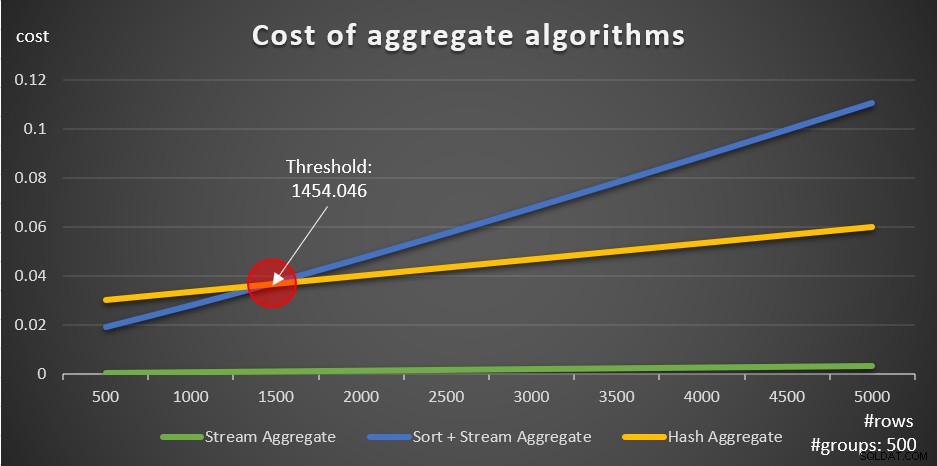
Gambar 5:Biaya algoritme agregat
Anda dapat dengan jelas melihat bahwa jika data telah dipesan sebelumnya, misalnya, dalam indeks penutup, strategi Stream Aggregate yang telah dipesan sebelumnya adalah pilihan terbaik, terlepas dari berapa banyak baris yang terlibat. Misalnya, Anda perlu membuat kueri tabel Pesanan, dan menghitung tanggal pesanan maksimum untuk setiap karyawan. Anda membuat indeks penutup berikut:
CREATE INDEX idx_eid_od ON dbo.Orders(empid, orderdate);
Berikut adalah lima kueri, meniru tabel Pesanan dengan jumlah baris yang berbeda (10.000, 20.000, 30.000, 40.000, dan 50.000):
SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (10000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (30000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (40000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (50000) * FROM dbo.Orders) AS D GROUP BY empid;
Gambar 6 menunjukkan rencana untuk kueri ini.
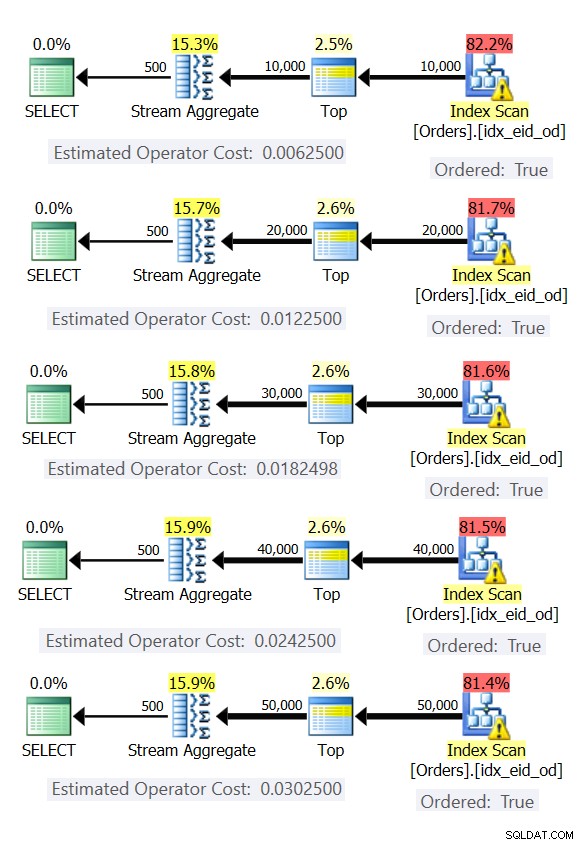
Gambar 6:Rencana dengan strategi Stream Agregat yang telah dipesan sebelumnya
Dalam semua kasus, paket melakukan pemindaian berurutan dari indeks penutup, dan menerapkan operator Stream Aggregate tanpa perlu penyortiran eksplisit.
Gunakan kode berikut untuk menghapus indeks yang Anda buat untuk contoh ini:
DROP INDEX idx_eid_od ON dbo.Orders;
Hal penting lainnya yang perlu diperhatikan tentang grafik pada Gambar 5 adalah apa yang terjadi ketika data tidak diurutkan sebelumnya. Ini terjadi saat tidak ada indeks penutup, serta saat Anda mengelompokkan menurut ekspresi yang dimanipulasi sebagai lawan dari kolom dasar. Ada ambang pengoptimalan—dalam kasus kami di 1454.046 baris—di bawahnya strategi Sort + Stream Aggregate memiliki biaya lebih rendah, dan pada atau di atasnya strategi Hash Aggregate memiliki biaya lebih rendah. Ini ada hubungannya dengan fakta bahwa hash yang pertama memiliki biaya startup yang lebih rendah, tetapi skala dengan cara n log n, sedangkan yang terakhir memiliki biaya startup yang lebih tinggi tetapi skala secara linier. Ini membuat yang pertama lebih disukai dengan sejumlah kecil baris input. Jika rumus rekayasa balik kami akurat, dua kueri berikut (sebut saja Kueri 10 dan Kueri 11) akan mendapatkan paket yang berbeda:
SELECT orderid % 500 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (1454) * FROM dbo.Orders) AS D GROUP BY orderid % 500; SELECT orderid % 500 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (1455) * FROM dbo.Orders) AS D GROUP BY orderid % 500;
Rencana untuk kueri ini ditunjukkan pada Gambar 7.
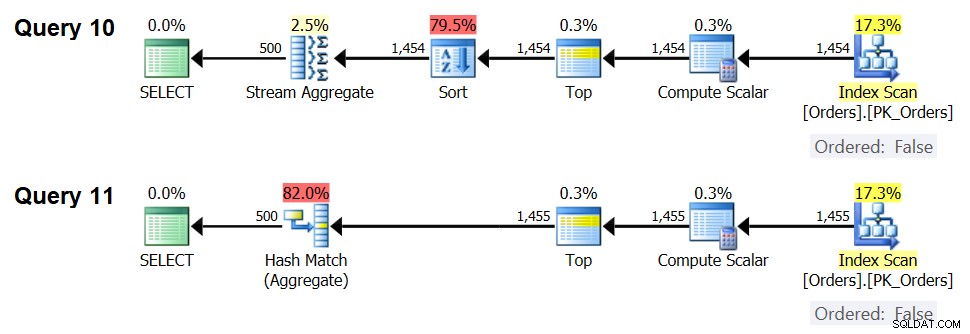
Gambar 7:Rencana untuk Kueri 10 dan Kueri 11
Memang, dengan 1.454 baris input (di bawah ambang pengoptimalan), pengoptimal secara alami lebih memilih algoritma Sortir + Aliran Agregat untuk Kueri 10, dan dengan 1.455 baris input (di atas ambang pengoptimalan), pengoptimal secara alami lebih memilih algoritme Hash Agregat untuk Kueri 11 .
Potensi untuk operator Agregat Adaptif
Salah satu aspek rumit dari ambang optimasi adalah masalah parameter sniffing saat menggunakan kueri sensitif parameter dalam prosedur tersimpan. Pertimbangkan prosedur tersimpan berikut sebagai contoh:
CREATE OR ALTER PROC dbo.EmpOrders @initialorderid AS INT AS SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= @initialorderid GROUP BY empid; GO
Anda membuat indeks optimal berikut untuk mendukung kueri prosedur tersimpan:
CREATE INDEX idx_oid_i_eid ON dbo.Orders(orderid) INCLUDE(empid);
Anda membuat indeks dengan orderid sebagai kunci untuk mendukung filter rentang kueri, dan menyertakan empid untuk cakupan. Ini adalah situasi di mana Anda tidak dapat benar-benar membuat indeks yang akan mendukung filter rentang dan baris yang difilter diurutkan sebelumnya oleh kumpulan pengelompokan. Ini berarti bahwa pengoptimal harus membuat pilihan antara Sortir + aliran Agregat dan algoritma Agregat Hash. Berdasarkan rumus penetapan biaya kami, ambang pengoptimalan adalah antara 937 dan 938 baris masukan (misalnya, 937,5 baris).
Misalkan Anda menjalankan prosedur tersimpan pertama kali dengan masukan ID pesanan awal yang memberi Anda sedikit kecocokan (di bawah ambang batas):
EXEC dbo.EmpOrders @initialorderid = 999991;
SQL Server menghasilkan rencana yang menggunakan algoritma Sort + Stream Agregat, dan menyimpan rencana tersebut. Eksekusi selanjutnya menggunakan kembali paket yang di-cache, terlepas dari berapa banyak baris yang terlibat. Misalnya, eksekusi berikut memiliki sejumlah kecocokan di atas ambang pengoptimalan:
EXEC dbo.EmpOrders @initialorderid = 990001;
Namun, itu menggunakan kembali paket yang di-cache meskipun faktanya tidak optimal untuk eksekusi ini. Itu adalah masalah sniffing parameter klasik.
SQL Server 2017 memperkenalkan kemampuan pemrosesan kueri adaptif, yang dirancang untuk mengatasi situasi seperti itu dengan menentukan selama eksekusi kueri strategi mana yang akan digunakan. Di antara peningkatan tersebut adalah operator Adaptive Join yang selama eksekusi menentukan apakah akan mengaktifkan algoritma Loop atau Hash berdasarkan ambang pengoptimalan yang dihitung. Cerita agregat kami meminta operator Agregat Adaptif yang serupa, yang selama eksekusi akan membuat pilihan antara strategi Urutkan + Aliran Agregat dan strategi Agregat Hash, berdasarkan ambang pengoptimalan yang dihitung. Gambar 8 mengilustrasikan rencana semu berdasarkan ide ini.
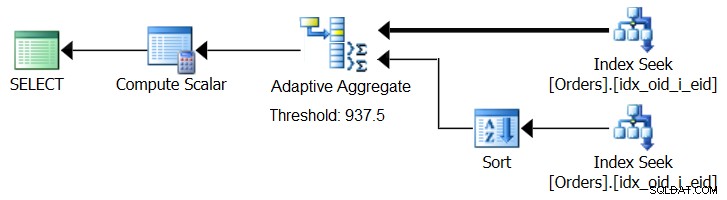
Gambar 8:Paket semu dengan operator Adaptive Aggregate
Untuk saat ini, untuk mendapatkan paket seperti itu, Anda perlu menggunakan Microsoft Paint. Namun karena konsep pemrosesan kueri adaptif sangat cerdas dan bekerja dengan sangat baik, masuk akal untuk mengharapkan peningkatan lebih lanjut di area ini di masa mendatang.
Jalankan kode berikut untuk menghapus indeks yang Anda buat untuk contoh ini:
DROP INDEX idx_oid_i_eid ON dbo.Orders;
Kesimpulan
Dalam artikel ini saya membahas penetapan biaya dan penskalaan algoritma Hash Aggregate dan membandingkannya dengan strategi Stream Aggregate dan Sort + Stream Aggregate. Saya menjelaskan ambang pengoptimalan yang ada antara strategi Sort + Stream Aggregate dan Hash Aggregate. Dengan sejumlah kecil baris input, yang pertama lebih disukai dan dengan jumlah besar yang terakhir. Saya juga menjelaskan potensi untuk menambahkan operator Adaptive Aggregate, mirip dengan operator Adaptive Join yang sudah diterapkan, untuk membantu menangani masalah sniffing parameter saat menggunakan kueri sensitif parameter. Bulan depan saya akan melanjutkan diskusi dengan membahas pertimbangan paralelisme dan kasus yang memerlukan penulisan ulang kueri.