Artikel ini adalah yang keempat dari seri tentang ambang pengoptimalan. Seri ini mencakup pengelompokan dan penggabungan data, menjelaskan berbagai algoritme yang dapat digunakan SQL Server, dan model penetapan biaya yang membantunya memilih di antara algoritme. Dalam artikel ini saya fokus pada pertimbangan paralelisme. Saya membahas berbagai strategi paralelisme yang dapat digunakan SQL Server, ambang batas untuk memilih antara paket serial dan paralel, dan logika penetapan biaya yang diterapkan SQL Server menggunakan konsep yang disebut derajat paralelisme untuk penetapan biaya (DOP untuk biaya).
Saya akan terus menggunakan tabel dbo.Orders dalam contoh database PerformanceV3 dalam contoh saya. Sebelum menjalankan contoh dalam artikel ini, jalankan kode berikut untuk menghapus beberapa indeks yang tidak diperlukan:
JAUHKAN INDEKS JIKA ADA idx_nc_sid_od_cid PADA dbo.Orders;TURUNKAN INDEKS JIKA ADA idx_unc_od_oid_i_cid_eid PADA dbo.Orders;
Hanya dua indeks yang harus ditinggalkan pada tabel ini adalah idx_cl_od (dikelompokkan dengan orderdate sebagai kuncinya) dan PK_Orders (tidak dikelompokkan dengan orderid sebagai kuncinya).
Strategi paralelisme
Selain harus memilih antara berbagai strategi pengelompokan dan agregasi (Stream Aggregate yang telah dipesan sebelumnya, Sort + Stream Aggregate, Hash Aggregate), SQL Server juga perlu memilih apakah akan menggunakan paket serial atau paralel. Bahkan, ia dapat memilih di antara beberapa strategi paralelisme yang berbeda. SQL Server menggunakan logika penetapan biaya yang menghasilkan ambang pengoptimalan yang dalam kondisi berbeda membuat satu strategi lebih disukai daripada yang lain. Kami telah membahas secara mendalam logika penetapan biaya yang digunakan SQL Server dalam paket serial di bagian seri sebelumnya. Di bagian ini saya akan memperkenalkan sejumlah strategi paralelisme yang dapat digunakan SQL Server untuk menangani pengelompokan dan agregasi. Awalnya, saya tidak akan membahas detail logika penetapan biaya, melainkan hanya menjelaskan opsi yang tersedia. Nanti di artikel saya akan menjelaskan cara kerja rumus penetapan biaya, dan faktor penting dalam rumus tersebut yang disebut DOP untuk penetapan biaya.
Seperti yang akan Anda pelajari nanti, SQL Server memperhitungkan jumlah CPU logis di mesin dalam rumus penetapan biaya untuk paket paralel. Dalam contoh saya, kecuali saya mengatakan sebaliknya, saya menganggap sistem target memiliki 8 CPU logis. Jika Anda ingin mencoba contoh yang akan saya berikan, untuk mendapatkan paket dan nilai biaya yang sama seperti yang saya lakukan, Anda perlu menjalankan kode pada mesin dengan 8 CPU logis juga. Jika mesin Anda kebetulan memiliki jumlah CPU yang berbeda, Anda dapat mengemulasi mesin dengan 8 CPU—untuk tujuan biaya—seperti:
DBCC OPTIMIZER_WHATIF(CPU, 8);
Meskipun alat ini tidak didokumentasikan dan didukung secara resmi, alat ini cukup nyaman untuk tujuan penelitian dan pembelajaran.
Tabel Pesanan dalam database sampel kami memiliki 1.000.000 baris dengan ID pesanan dalam kisaran 1 hingga 1.000.000. Untuk mendemonstrasikan tiga strategi paralelisme yang berbeda untuk pengelompokan dan agregasi, saya akan memfilter pesanan yang ID pesanannya lebih besar dari atau sama dengan 300001 (700.000 kecocokan), dan mengelompokkan data dalam tiga cara berbeda (menurut custid [20.000 grup sebelum memfilter], oleh empid [500 grup], dan oleh shipperid [5 grup]), dan hitung jumlah pesanan per grup.
Gunakan kode berikut untuk membuat indeks guna mendukung kueri yang dikelompokkan:
BUAT INDEX idx_oid_i_eid PADA dbo.Orders(orderid) INCLUDE(empid);BUAT INDEX idx_oid_i_sid PADA dbo.Orders(orderid) INCLUDE(shipperid);BUAT INDEX idx_oid_id_orderid.Orders ON pra>Kueri berikut menerapkan pemfilteran dan pengelompokan yang disebutkan di atas:
-- Query 1:Serial SELECT custid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY custidOPTION(MAXDOP 1); -- Kueri 2:Paralel, bukan custid SELECT lokal/global, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY custid; -- Query 3:Pararel lokal paralel global SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY empid; -- Kueri 4:Pengirim SELECT serial global paralel lokal, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY shipperid;Perhatikan bahwa Kueri 1 dan Kueri 2 adalah sama (keduanya dikelompokkan berdasarkan custid), hanya yang pertama memaksa paket serial dan yang terakhir mendapatkan paket paralel pada mesin dengan 8 CPU. Saya menggunakan dua contoh ini untuk membandingkan strategi serial dan paralel untuk kueri yang sama.
Gambar 1 menunjukkan perkiraan rencana untuk keempat kueri:
Gambar 1:Strategi paralelisme
Untuk saat ini, jangan khawatir tentang nilai biaya yang ditunjukkan pada gambar dan penyebutan istilah DOP untuk penetapan biaya. Saya akan membahasnya nanti. Pertama, fokuslah untuk memahami strategi dan perbedaan di antara mereka.
Strategi yang digunakan dalam rencana serial untuk Kueri 1 harus Anda ketahui dari bagian sebelumnya dalam seri. Paket menyaring pesanan yang relevan menggunakan pencarian di indeks penutup yang Anda buat sebelumnya. Kemudian, dengan perkiraan jumlah baris yang akan dikelompokkan dan digabungkan, pengoptimal lebih memilih strategi Agregat Hash daripada strategi Urutkan + Aliran Agregat.
Rencana untuk Query 2 menggunakan strategi paralelisme sederhana yang hanya menggunakan satu operator agregat. Operator Pencarian Indeks paralel mendistribusikan paket baris ke utas yang berbeda secara round-robin. Setiap paket baris dapat berisi beberapa ID pelanggan yang berbeda. Agar operator agregat tunggal dapat menghitung jumlah grup akhir yang benar, semua baris yang termasuk dalam grup yang sama harus ditangani oleh utas yang sama. Untuk alasan ini, operator pertukaran Paralelisme (Aliran Partisi Ulang) digunakan untuk mempartisi ulang aliran dengan set pengelompokan (custid). Terakhir, operator pertukaran Paralelisme (Mengumpulkan Aliran) digunakan untuk mengumpulkan aliran dari beberapa utas menjadi satu aliran baris hasil.
Rencana untuk Kueri 3 dan Kueri 4 menggunakan strategi paralelisme yang lebih kompleks. Paket mulai mirip dengan paket untuk Query 2 di mana operator Index Seek paralel mendistribusikan paket baris ke utas yang berbeda. Kemudian pekerjaan agregasi dilakukan dalam dua langkah:satu operator agregat mengelompokkan secara lokal dan mengagregasi baris utas saat ini (perhatikan anggota hasil partialagg1004), dan operator agregat kedua secara global mengelompokkan dan mengagregasi hasil dari agregat lokal (perhatikan globalagg1005 anggota hasil). Masing-masing dari dua langkah agregat—lokal dan global—dapat menggunakan salah satu dari algoritme agregat yang saya jelaskan sebelumnya dalam seri ini. Kedua paket untuk Kueri 3 dan Kueri 4 dimulai dengan Agregat Hash lokal dan dilanjutkan dengan Agregat Sortir + Aliran global. Perbedaan antara keduanya adalah bahwa yang pertama menggunakan paralelisme di kedua langkah (maka pertukaran Repartition Streams digunakan antara keduanya dan pertukaran Gather Streams setelah agregat global), dan yang kemudian menangani agregat lokal di zona paralel dan global agregat di zona serial (oleh karena itu pertukaran Gather Streams digunakan di antara keduanya).
Saat melakukan riset tentang pengoptimalan kueri secara umum, dan paralelisme secara khusus, ada baiknya Anda memahami alat yang memungkinkan Anda mengontrol berbagai aspek pengoptimalan untuk melihat efeknya. Anda sudah tahu cara memaksakan paket serial (dengan petunjuk MAXDOP 1), dan cara meniru lingkungan yang, untuk tujuan biaya, memiliki sejumlah CPU logis (DBCC OPTIMIZER_WHATIF, dengan opsi CPU). Alat praktis lainnya adalah petunjuk kueri ENABLE_PARALLEL_PLAN_PREFERENCE (diperkenalkan di SQL Server 2016 SP1 CU2), yang memaksimalkan paralelisme. Yang saya maksud dengan ini adalah bahwa jika paket paralel didukung untuk kueri, paralelisme akan lebih disukai di semua bagian paket yang dapat ditangani secara paralel, seolah-olah gratis. Misalnya, amati pada Gambar 1 bahwa secara default rencana untuk Query 4 menangani agregat lokal di zona serial dan agregat global di zona paralel. Berikut kueri yang sama, hanya kali ini dengan petunjuk kueri ENABLE_PARALLEL_PLAN_PREFERENCE diterapkan (kami akan menyebutnya Kueri 5):
SELECT shipperid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY shipperidOPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'));Rencana untuk Query 5 ditunjukkan pada Gambar 2:
Gambar 2:Memaksimalkan paralelisme
Perhatikan bahwa kali ini agregat lokal dan global ditangani di zona paralel.
Pilihan paket serial / paralel
Ingatlah bahwa selama optimasi kueri, SQL Server membuat beberapa rencana kandidat dan memilih satu dengan biaya terendah di antara yang dihasilkannya. Istilah biaya adalah sedikit keliru karena rencana kandidat dengan biaya terendah seharusnya, menurut perkiraan, yang memiliki waktu berjalan terendah, bukan yang dengan jumlah sumber daya terendah yang digunakan secara keseluruhan. Misalnya, antara rencana kandidat serial dan rencana paralel yang dihasilkan untuk kueri yang sama, rencana paralel kemungkinan akan menggunakan lebih banyak sumber daya, karena perlu menggunakan operator pertukaran yang menyinkronkan utas (mendistribusikan, mempartisi ulang, dan mengumpulkan aliran). Namun, agar rencana paralel membutuhkan lebih sedikit waktu untuk menyelesaikan berjalan daripada rencana serial, penghematan yang dicapai dengan melakukan pekerjaan dengan banyak utas perlu lebih besar daripada pekerjaan ekstra yang dilakukan oleh operator pertukaran. Dan ini perlu dicerminkan oleh rumus biaya yang digunakan SQL Server ketika paralelisme terlibat. Bukan tugas yang mudah untuk dilakukan secara akurat!
Selain biaya paket paralel yang harus lebih rendah dari biaya paket serial agar lebih disukai, biaya alternatif paket serial harus lebih besar atau sama dengan ambang biaya untuk paralelisme . Ini adalah opsi konfigurasi server yang disetel ke 5 secara default yang mencegah kueri dengan biaya yang cukup rendah untuk ditangani dengan paralelisme. Pemikiran di sini adalah bahwa sistem dengan sejumlah besar kueri kecil secara keseluruhan akan lebih diuntungkan dari penggunaan paket serial, daripada membuang banyak sumber daya untuk menyinkronkan utas. Anda masih dapat memiliki beberapa kueri dengan paket serial yang dijalankan pada saat yang bersamaan, dengan memanfaatkan sumber daya multi-CPU mesin secara efisien. Faktanya, banyak profesional SQL Server ingin meningkatkan ambang biaya untuk paralelisme dari default 5 ke nilai yang lebih tinggi. Sistem yang menjalankan sejumlah kecil kueri besar secara bersamaan akan lebih diuntungkan dengan menggunakan paket paralel.
Untuk rekap, agar SQL Server lebih memilih paket paralel daripada alternatif serial, biaya paket serial harus setidaknya ambang biaya untuk paralelisme, dan biaya paket paralel harus lebih rendah daripada biaya paket serial (menyiratkan berpotensi waktu berjalan yang lebih rendah).
Sebelum saya sampai ke rincian rumus biaya yang sebenarnya, saya akan mengilustrasikan dengan contoh skenario yang berbeda di mana pilihan dibuat antara rencana serial dan paralel. Pastikan sistem Anda menggunakan 8 CPU logis untuk mendapatkan biaya kueri yang serupa dengan milik saya jika Anda ingin mencoba contohnya.
Pertimbangkan kueri berikut (kami akan menyebutnya Kueri 6 dan Kueri 7):
-- Query 6:Serial SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=400001GROUP BY empid; -- Kueri 7:Paralel paksa SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=400001GROUP BY empidOPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'));Rencana untuk kueri ini ditunjukkan pada Gambar 3.
Gambar 3:Biaya serial
Di sini, biaya paket paralel [dipaksa] lebih rendah daripada biaya paket serial; namun, biaya paket serial lebih rendah dari ambang biaya default untuk paralelisme 5, oleh karena itu SQL Server memilih paket serial secara default.
Pertimbangkan kueri berikut (kami akan menyebutnya Kueri 8 dan Kueri 9):
-- Query 8:Parallel SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY empid; -- Query 9:Serial SELECT empid yang dipaksakan, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY empidOPTION(MAXDOP 1);Rencana untuk kueri ini ditunjukkan pada Gambar 4.
Gambar 4:Biaya serial>=ambang biaya untuk paralelisme, biaya paralel
Di sini, biaya paket serial [dipaksa] lebih besar atau sama dengan ambang biaya untuk paralelisme, dan biaya paket paralel lebih rendah dari biaya paket serial, oleh karena itu SQL Server memilih paket paralel secara default.
Pertimbangkan kueri berikut (kami akan menyebutnya Kueri 10 dan Kueri 11):
-- Query 10:Serial SELECT *FROM dbo.OrdersWHERE orderid>=100000; -- Kueri 11:PILIH paralel paksa *FROM dbo.OrdersWHERE orderid>=100000OPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'));Rencana untuk kueri ini ditunjukkan pada Gambar 5.
Gambar 5:Biaya serial>=ambang biaya untuk paralelisme, biaya paralel>=biaya serial
Di sini, biaya paket serial lebih besar atau sama dengan ambang biaya untuk paralelisme; namun, biaya paket serial lebih rendah daripada biaya paket paralel [dipaksa], oleh karena itu SQL Server memilih paket serial secara default.
Ada hal lain yang perlu Anda ketahui tentang mencoba memaksimalkan paralelisme dengan petunjuk ENABLE_PARALLEL_PLAN_PREFERENCE. Agar SQL Server bahkan dapat menggunakan paket paralel, harus ada beberapa enabler paralelisme seperti predikat residual, pengurutan, agregat, dan sebagainya. Paket yang hanya menerapkan pemindaian indeks atau pencarian indeks tanpa predikat residual, dan tanpa pengaktif paralelisme lainnya, akan diproses dengan paket serial. Pertimbangkan kueri berikut sebagai contoh (kami akan menyebutnya Kueri 12 dan Kueri 13):
-- Permintaan 12 PILIH *FROM dbo.OrdersOPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE')); -- Kueri 13 PILIH *FROM dbo.OrdersWHERE orderid>=100000OPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'));Rencana untuk kueri ini ditunjukkan pada Gambar 6.
Gambar 6:Pengaktif paralelisme
Kueri 12 mendapatkan paket serial meskipun ada petunjuk karena tidak ada pengaktif paralelisme. Kueri 13 mendapatkan paket paralel karena ada predikat residual yang terlibat.
Menghitung dan menguji DOP untuk penetapan biaya
Microsoft harus mengkalibrasi formula penetapan biaya dalam upaya untuk memiliki biaya paket paralel yang lebih rendah daripada biaya paket serial yang mencerminkan waktu pengoperasian yang lebih rendah dan sebaliknya. Salah satu ide potensial adalah mengambil biaya CPU operator serial dan membaginya dengan jumlah CPU logis di mesin untuk menghasilkan biaya CPU operator paralel. Jumlah logis CPU dalam mesin adalah faktor utama yang menentukan tingkat paralelisme kueri, atau disingkat DOP (jumlah utas yang dapat digunakan di zona paralel dalam rencana). Pemikiran sederhana di sini adalah bahwa jika operator membutuhkan waktu T untuk menyelesaikan unit saat menggunakan satu utas, dan derajat paralelisme kueri adalah D, operator akan membutuhkan waktu T/D untuk menyelesaikan saat menggunakan utas D. Dalam praktiknya, hal-hal tidak sesederhana itu. Misalnya, biasanya Anda memiliki beberapa kueri yang berjalan secara bersamaan dan bukan hanya satu, dalam hal ini satu kueri tidak akan mendapatkan semua sumber daya CPU mesin. Jadi, Microsoft datang dengan ide tingkat paralelisme untuk biaya (DOP untuk penetapan biaya, singkatnya). Ukuran ini biasanya lebih rendah daripada jumlah CPU logis dalam mesin dan merupakan faktor pembagian biaya CPU operator serial untuk menghitung biaya CPU operator paralel.
Biasanya, DOP untuk penetapan biaya dihitung sebagai jumlah CPU logis dibagi 2, menggunakan pembagian bilangan bulat. Ada pengecualian. Ketika jumlah CPU adalah 2 atau 3, DOP untuk penetapan biaya diatur ke 2. Dengan 4 atau lebih CPU, DOP untuk penetapan biaya diatur ke #CPU / 2, sekali lagi, menggunakan pembagian bilangan bulat. Itu hingga maksimum tertentu, yang tergantung pada jumlah memori yang tersedia untuk mesin. Dalam mesin dengan memori hingga 4.096 MB, DOP maksimum untuk penetapan biaya adalah 8; dengan lebih dari 4.096 MB, DOP maksimum untuk penetapan biaya adalah 32.
Untuk menguji logika ini, Anda sudah tahu cara mengemulasi jumlah CPU logis yang diinginkan menggunakan DBCC OPTIMIZER_WHATIF, dengan opsi CPU, seperti:
DBCC OPTIMIZER_WHATIF(CPU, 8);Menggunakan perintah yang sama dengan opsi MemoryMBs, Anda dapat meniru jumlah memori yang diinginkan dalam MB, seperti:
DBCC OPTIMIZER_WHATIF(MemoryMBs, 16384);Gunakan kode berikut untuk memeriksa status opsi emulasi yang ada:
DBCC TRACEON(3604); DBCC OPTIMIZER_WHATIF(Status); DBCC TRACEOFF(3604);Gunakan kode berikut untuk mengatur ulang semua opsi:
DBCC OPTIMIZER_WHATIF(ResetAll);Berikut adalah kueri T-SQL yang dapat Anda gunakan untuk menghitung DOP untuk penetapan biaya berdasarkan jumlah input CPU logis dan jumlah memori:
DECLARE @NumCPUs SEBAGAI INT =8, @MemoryMBs SEBAGAI INT =16384; SELECT CASE WHEN @NumCPUs =1 THEN 1 WHEN @NumCPUs <=3 THEN 2 WHEN @NumCPUs>=4 THEN (SELECT MIN(n) FROM ( VALUES(@NumCPUs / 2), (MaxDOP4C ) ) AS D2(n)) AKHIR SEBAGAI DOP4CFROM ( VALUES( KASUS KETIKA @MemoryMBs <=4096 THEN 8 ELSE 32 END ) ) AS D1(MaxDOP4C);Dengan nilai input yang ditentukan, kueri ini mengembalikan 4.
Tabel 1 merinci DOP untuk penetapan biaya yang Anda dapatkan berdasarkan jumlah logis CPU dan jumlah memori di mesin Anda.
| #CPU | DOP untuk biaya saat MemoryMBs <=4096 | DOP untuk biaya ketika MemoryMBs> 4096 |
|---|---|---|
| 1 | 1 | 1 |
| 2-5 | 2 | 2 |
| 6-7 | 3 | 3 |
| 8-9 | 4 | 4 |
| 10-11 | 5 | 5 |
| 12-13 | 6 | 6 |
| 14-15 | 7 | 7 |
| 16-17 | 8 | 8 |
| 18-19 | 8 | 9 |
| 20-21 | 8 | 10 |
| 22-23 | 8 | 11 |
| 24-25 | 8 | 12 |
| 26-27 | 8 | 13 |
| 28-29 | 8 | 14 |
| 30-31 | 8 | 15 |
| 32-33 | 8 | 16 |
| 34-35 | 8 | 17 |
| 36-37 | 8 | 18 |
| 38-39 | 8 | 19 |
| 40-41 | 8 | 20 |
| 42-43 | 8 | 21 |
| 44-45 | 8 | 22 |
| 46-47 | 8 | 23 |
| 48-49 | 8 | 24 |
| 50-51 | 8 | 25 |
| 52-53 | 8 | 26 |
| 54-55 | 8 | 27 |
| 56-57 | 8 | 28 |
| 58-59 | 8 | 29 |
| 60-61 | 8 | 30 |
| 62-63 | 8 | 31 |
| >=64 | 8 | 32 |
Tabel 1:DOP untuk penetapan biaya
Sebagai contoh, mari kita lihat kembali Query 1 dan Query 2 yang ditampilkan sebelumnya:
-- Query 1:PILIH serial paksa, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY custidOPTION(MAXDOP 1); -- Kueri 2:Secara alami paralel SELECT custid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY custid;
Rencana untuk kueri ini ditunjukkan pada Gambar 7.
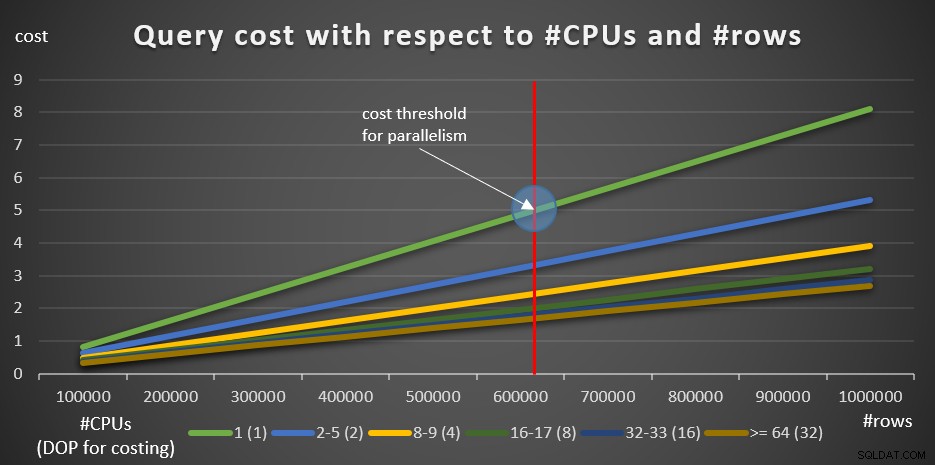 Gambar 7:DOP untuk biaya
Gambar 7:DOP untuk biaya
Kueri 1 memaksa paket serial, sedangkan Kueri 2 mendapatkan paket paralel di lingkungan saya (meniru 8 CPU logis dan memori 16.384 MB). Ini berarti bahwa DOP untuk penetapan biaya di lingkungan saya adalah 4. Seperti yang disebutkan, biaya CPU operator paralel dihitung sebagai biaya CPU operator serial dibagi dengan DOP untuk penetapan biaya. Anda dapat melihat bahwa memang demikian halnya dalam paket paralel kami dengan operator Index Seek dan Hash Aggregate yang dijalankan secara paralel.
Adapun biaya operator pertukaran, mereka terbuat dari biaya awal dan beberapa biaya konstan per baris, yang dapat Anda rekayasa balik dengan mudah.
Perhatikan bahwa dalam strategi pengelompokan dan agregasi paralel sederhana, yang digunakan di sini, perkiraan kardinalitas dalam denah serial dan paralel adalah sama. Itu karena hanya satu operator agregat yang dipekerjakan. Nanti Anda akan melihat bahwa semuanya berbeda saat menggunakan strategi lokal/global.
Kueri berikut membantu mengilustrasikan pengaruh jumlah CPU logis dan jumlah baris yang terlibat pada biaya kueri (10 kueri, dengan penambahan 100 ribu baris):
SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=900001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=800001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=700001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=600001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=500001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=400001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=200001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=100001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=000001GROUP BY empid;
Gambar 8 menunjukkan hasilnya.
Gambar 8:Biaya kueri sehubungan dengan #CPU dan #rows
Garis hijau mewakili biaya kueri yang berbeda (dengan jumlah baris yang berbeda) menggunakan paket serial. Baris lain mewakili biaya paket paralel dengan jumlah CPU logis yang berbeda, dan DOP masing-masing untuk biaya. Garis merah menunjukkan titik di mana biaya kueri serial adalah 5—ambang biaya default untuk pengaturan paralelisme. Di sebelah kiri titik ini (lebih sedikit baris yang akan dikelompokkan dan digabungkan), biasanya, pengoptimal tidak akan mempertimbangkan rencana paralel. Agar dapat meneliti biaya paket paralel di bawah ambang batas biaya untuk paralelisme, Anda dapat melakukan salah satu dari dua hal. Salah satu opsi adalah menggunakan petunjuk kueri ENABLE_PARALLEL_PLAN_PREFERENCE, tetapi sebagai pengingat, opsi ini memaksimalkan paralelisme daripada hanya memaksanya. Jika itu bukan efek yang diinginkan, Anda bisa menonaktifkan ambang biaya untuk paralelisme, seperti:
EXEC sp_configure 'tampilkan opsi lanjutan', 1; KONFIGURASI ULANG; EXEC sp_configure 'ambang biaya untuk paralelisme', 0; EXEC sp_configure 'tampilkan opsi lanjutan', 0; KONFIGURASI ULANG;
Jelas, itu bukan langkah cerdas dalam sistem produksi, tetapi sangat berguna untuk tujuan penelitian. Itulah yang saya lakukan untuk menghasilkan informasi untuk grafik pada Gambar 8.
Dimulai dengan 100 ribu baris, dan menambahkan peningkatan 100 ribu, semua grafik tampaknya menyiratkan bahwa memiliki ambang biaya untuk paralelisme bukanlah faktor, paket paralel akan selalu lebih disukai. Memang demikian halnya dengan kueri kami dan jumlah baris yang terlibat. Namun, coba jumlah baris yang lebih kecil, dimulai dengan 10 ribu dan meningkat dengan kenaikan 10 ribu menggunakan lima kueri berikut (sekali lagi, tetap nonaktifkan ambang biaya untuk paralelisme untuk saat ini):
SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=990001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=980001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=970001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=960001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=950001GROUP BY empid;
Gambar 9 menunjukkan biaya kueri dengan paket serial dan paralel (meniru 4 CPU, DOP untuk biaya 2).
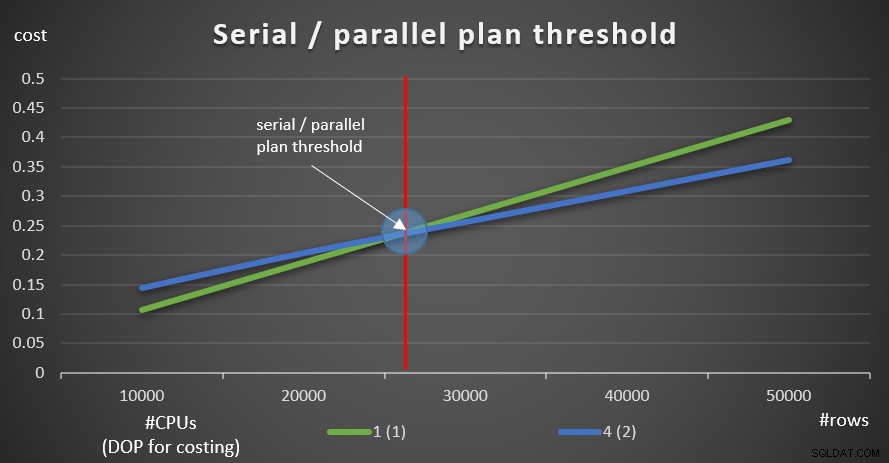 Gambar 9:Serial / ambang batas paket paralel
Gambar 9:Serial / ambang batas paket paralel
Seperti yang Anda lihat, ada ambang pengoptimalan di mana paket serial lebih disukai, dan di atasnya paket paralel lebih disukai. Seperti yang disebutkan, dalam sistem normal di mana Anda mempertahankan ambang biaya untuk pengaturan paralelisme pada nilai default 5, atau lebih tinggi, ambang batas efektif tetap lebih tinggi daripada di grafik ini.
Sebelumnya saya menyebutkan bahwa ketika SQL Server memilih pengelompokan sederhana dan strategi paralelisme agregasi, perkiraan kardinalitas dari rencana serial dan paralel adalah sama. Pertanyaannya adalah, bagaimana SQL Server menangani perkiraan kardinalitas untuk strategi paralelisme lokal/global.
Untuk mengetahuinya, saya akan menggunakan Kueri 3 dan Kueri 4 dari contoh kami sebelumnya:
-- Query 3:Paralel lokal paralel global SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY empid; -- Kueri 4:Pengirim SELECT serial global paralel lokal, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY shipperid;
Dalam sistem dengan 8 CPU logis dan DOP efektif untuk nilai biaya 4, saya mendapatkan paket yang ditunjukkan pada Gambar 10.
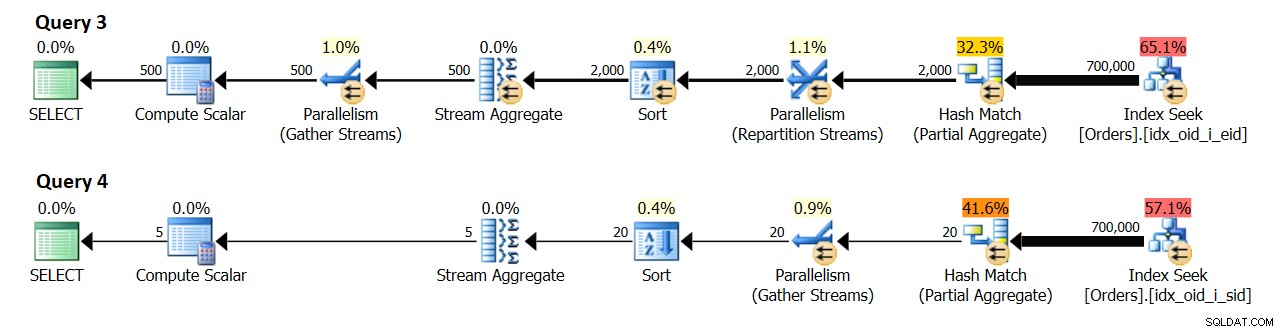 Gambar 10:Perkiraan kardinalitas
Gambar 10:Perkiraan kardinalitas
Kueri 3 mengelompokkan pesanan berdasarkan empid. 500 kelompok karyawan yang berbeda diharapkan pada akhirnya.
Kueri 4 mengelompokkan pesanan berdasarkan shipperid. 5 kelompok pengirim yang berbeda diharapkan pada akhirnya.
Anehnya, tampaknya perkiraan kardinalitas untuk jumlah grup yang dihasilkan oleh agregat lokal adalah { jumlah grup berbeda yang diharapkan oleh setiap utas } * { DOP untuk biaya }. Dalam praktiknya, Anda menyadari bahwa jumlahnya biasanya akan dua kali lebih banyak karena yang diperhitungkan adalah DOP untuk eksekusi (alias, hanya DOP), yang terutama didasarkan pada jumlah CPU logis. Bagian ini agak sulit untuk ditiru untuk tujuan penelitian karena perintah DBCC OPTIMIZER_WHATIF dengan opsi CPU memengaruhi perhitungan DOP untuk penetapan biaya, tetapi DOP untuk eksekusi tidak akan lebih besar dari jumlah aktual CPU logis yang dilihat oleh instance SQL Server Anda. Jumlah ini pada dasarnya didasarkan pada jumlah penjadwal SQL Server dimulai. Anda bisa mengontrol jumlah penjadwal SQL Server dimulai dengan menggunakan parameter startup -P{ #schedulers }, tetapi itu adalah alat penelitian yang sedikit lebih agresif dibandingkan dengan opsi sesi.
Bagaimanapun, tanpa meniru sumber daya apa pun, mesin uji saya memiliki 4 CPU logis, menghasilkan DOP untuk biaya 2, dan DOP untuk eksekusi 4. Di lingkungan saya, agregat lokal dalam rencana untuk Kueri 3 menunjukkan perkiraan 1.000 grup hasil (500 x 2), dan sebenarnya 2.000 (500 x 4). Demikian pula, agregat lokal dalam rencana untuk Kueri 4 menunjukkan perkiraan 10 grup hasil (5 x 2) dan aktual 20 (5 x 4).
Setelah selesai bereksperimen, jalankan kode berikut untuk pembersihan:
-- Tetapkan ambang biaya untuk paralelisme ke default EXEC sp_configure 'tampilkan opsi lanjutan', 1; KONFIGURASI ULANG; EXEC sp_configure 'ambang biaya untuk paralelisme', 5; EXEC sp_configure 'tampilkan opsi lanjutan', 0; RECONFIGURE;GO -- Setel ulang opsi OPTIMIZER_WHATIF DBCC OPTIMIZER_WHATIF(ResetAll); -- Jatuhkan indeks DROP INDEX idx_oid_i_sid PADA dbo.Orders;TURUN INDEX idx_oid_i_eid PADA dbo.Orders;TURUN INDEX idx_oid_i_cid PADA dbo.Orders;
Kesimpulan
Dalam artikel ini saya menjelaskan sejumlah strategi paralelisme yang digunakan SQL Server untuk menangani pengelompokan dan agregasi. Konsep penting untuk dipahami dalam optimasi kueri dengan rencana paralel adalah derajat paralelisme (DOP) untuk penetapan biaya. Saya menunjukkan sejumlah ambang pengoptimalan, termasuk ambang batas antara paket serial dan paralel, dan ambang biaya pengaturan untuk paralelisme. Sebagian besar konsep yang saya jelaskan di sini tidak unik untuk pengelompokan dan agregasi, melainkan hanya berlaku untuk pertimbangan rencana paralel di SQL Server secara umum. Bulan depan saya akan melanjutkan seri dengan membahas pengoptimalan dengan penulisan ulang kueri.