Setiap produk memiliki bug, dan SQL Server tidak terkecuali. Menggunakan fitur produk dengan cara yang sedikit tidak biasa (atau menggabungkan fitur yang relatif baru bersama-sama) adalah cara yang bagus untuk menemukannya. Bug bisa menarik, dan bahkan mendidik, tetapi mungkin sebagian kesenangan hilang ketika penemuan itu menyebabkan pager Anda berbunyi pada jam 4 pagi, mungkin setelah malam sosial yang khusus dengan teman-teman…
Bug yang menjadi subjek posting ini mungkin cukup langka di alam liar, tetapi ini bukan kasus tepi klasik. Saya tahu setidaknya satu konsultan yang pernah mengalaminya dalam sistem produksi. Tentang topik yang sama sekali tidak terkait, saya harus menggunakan kesempatan ini untuk menyapa "halo" kepada DBA (blog) Tua yang Pemarah.
Saya akan mulai dengan beberapa latar belakang yang relevan tentang penggabungan gabungan. Jika Anda yakin telah mengetahui segala sesuatu yang perlu diketahui tentang merge join, atau hanya ingin memotong, silakan gulir ke bawah ke bagian berjudul, "The Bug."
Gabung Bergabung
Merge join bukanlah hal yang sangat rumit, dan bisa sangat efisien dalam situasi yang tepat. Ini mengharuskan inputnya diurutkan pada tombol gabung, dan berkinerja terbaik dalam mode satu-ke-banyak (di mana setidaknya inputnya unik pada tombol gabung). Untuk gabungan satu-ke-banyak berukuran sedang, penggabungan gabungan serial bukanlah pilihan yang buruk sama sekali, asalkan persyaratan penyortiran input dapat dipenuhi tanpa melakukan pengurutan eksplisit.
Menghindari pengurutan paling sering dicapai dengan mengeksploitasi urutan yang disediakan oleh indeks. Penggabungan gabungan juga dapat memanfaatkan urutan pengurutan yang dipertahankan dari pengurutan sebelumnya yang tidak dapat dihindari. Hal yang keren tentang merge join adalah ia dapat berhenti memproses baris input segera setelah salah satu input kehabisan baris. Satu hal terakhir:gabung gabung tidak peduli apakah urutan pengurutan input naik atau turun (meskipun kedua input harus sama). Contoh berikut menggunakan tabel Numbers standar untuk menggambarkan sebagian besar poin di atas:
CREATE TABLE #T1 (col1 integer CONSTRAINT PK1 PRIMARY KEY (col1 DESC)); CREATE TABLE #T2 (col1 integer CONSTRAINT PK2 PRIMARY KEY (col1 DESC)); INSERT #T1 SELECT n FROM dbo.Numbers WHERE n BETWEEN 10000 AND 19999; INSERT #T2 SELECT n FROM dbo.Numbers WHERE n BETWEEN 18000 AND 21999;
Perhatikan bahwa indeks yang memberlakukan kunci utama pada dua tabel tersebut didefinisikan sebagai menurun. Rencana kueri untuk INSERT memiliki sejumlah fitur menarik:
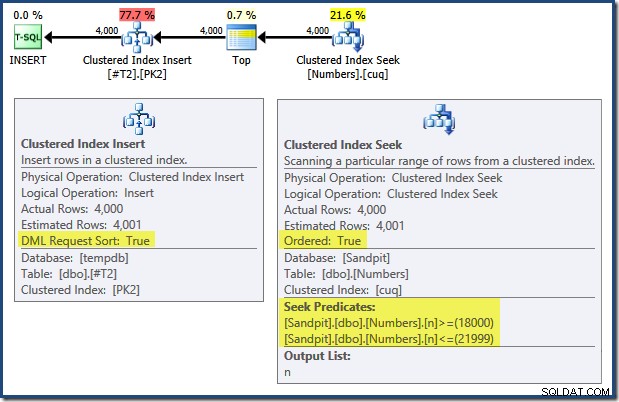
Membaca dari kiri ke kanan (seperti yang masuk akal!) Sisipan Indeks Berkelompok memiliki set properti "Urutan Permintaan DML". Ini berarti operator memerlukan baris dalam urutan kunci Indeks Clustered. Indeks berkerumun (menerapkan kunci utama dalam kasus ini) didefinisikan sebagai DESC , jadi baris dengan nilai yang lebih tinggi harus tiba terlebih dahulu. Indeks berkerumun di tabel Numbers saya adalah ASC , jadi pengoptimal kueri menghindari pengurutan eksplisit dengan mencari kecocokan tertinggi di tabel Numbers (21.999) terlebih dahulu, lalu memindai ke kecocokan terendah (18.000) dalam urutan indeks terbalik. Tampilan "Plan Tree" di SQL Sentry Plan Explorer menunjukkan pemindaian terbalik (mundur) dengan jelas:
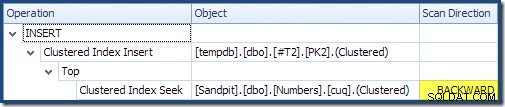
Pemindaian mundur membalikkan urutan alami indeks. Pemindaian mundur dari ASC kunci indeks mengembalikan baris dalam urutan kunci menurun; pemindaian mundur DESC kunci indeks mengembalikan baris dalam urutan kunci menaik. "Arah pemindaian" tidak menunjukkan urutan kunci yang dikembalikan dengan sendirinya – Anda harus tahu apakah indeksnya ASC atau DESC untuk membuat tekad itu.
Menggunakan tabel dan data pengujian ini (T1 memiliki 10.000 baris bernomor dari 10.000 hingga 19.999 inklusif; T2 memiliki 4.000 baris bernomor dari 18.000 hingga 21.999) kueri berikut menggabungkan dua tabel dan mengembalikan hasil dalam urutan menurun dari kedua kunci:
SELECT
T1.col1,
T2.col1
FROM #T1 AS T1
JOIN #T2 AS T2
ON T2.col1 = T1.col1
ORDER BY
T1.col1 DESC,
T2.col1 DESC; Kueri mengembalikan 2.000 baris yang cocok dengan benar seperti yang Anda harapkan. Rencana pasca eksekusi adalah sebagai berikut:
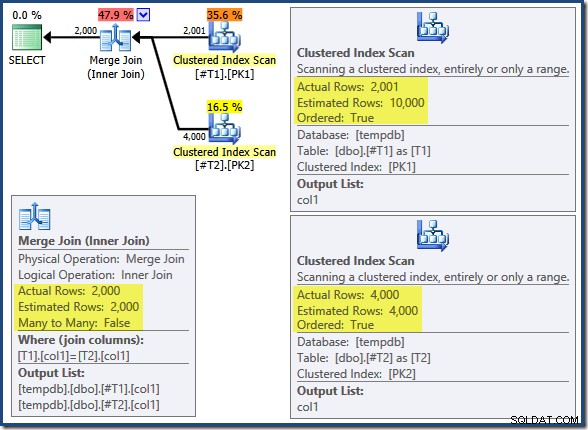
Gabung Gabung tidak berjalan dalam mode banyak-ke-banyak (input teratas unik pada tombol gabung) dan perkiraan kardinalitas 2.000 baris benar-benar tepat. Pemindaian Indeks Berkelompok tabel T2 diurutkan (walaupun kita harus menunggu beberapa saat untuk mengetahui apakah urutan itu maju atau mundur) dan perkiraan kardinalitas 4.000 baris juga tepat. Pemindaian Indeks Berkelompok tabel T1 juga dipesan, tetapi hanya 2.001 baris yang dibaca sedangkan 10.000 diperkirakan. Tampilan pohon rencana menunjukkan kedua Pemindaian Indeks Clustered diurutkan ke depan:
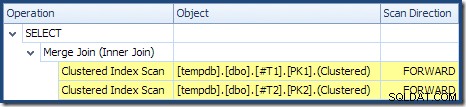
Ingatlah bahwa membaca DESC indeks FORWARD akan menghasilkan baris dalam urutan kunci terbalik. Inilah yang dibutuhkan oleh ORDER BY T1.col DESC, T2.col1 DESC klausa, jadi tidak diperlukan pengurutan eksplisit. Kode semu untuk Gabung Gabung satu-ke-banyak (direproduksi dari blog Gabung Gabung Craig Freedman) adalah:

Pemindaian urutan menurun dari T1 mengembalikan baris mulai dari 19.999 dan turun menuju 10.000. Pemindaian urutan menurun dari T2 mengembalikan baris mulai dari 21.999 dan turun menuju 18.000. Semua 4.000 baris dalam T2 akhirnya dibaca, tetapi proses penggabungan berulang berhenti ketika nilai kunci 17.999 dibaca dari T1 , karena T2 kehabisan baris. Oleh karena itu, pemrosesan penggabungan selesai tanpa sepenuhnya membaca T1 . Bunyinya baris dari 19.999 ke 17.999 inklusif; total 2.001 baris seperti yang ditunjukkan pada rencana eksekusi di atas.
Jangan ragu untuk menjalankan kembali pengujian dengan ASC indeks sebagai gantinya, juga mengubah ORDER BY klausa dari DESC ke ASC . Rencana eksekusi yang dihasilkan akan sangat mirip, dan tidak ada jenis yang diperlukan.
Untuk meringkas poin-poin yang akan menjadi penting dalam sekejap, Merge Join membutuhkan input yang diurutkan dengan kunci gabung, tetapi tidak masalah apakah kunci diurutkan secara menaik atau menurun.
Bug
Untuk mereproduksi bug, setidaknya salah satu tabel kita perlu dipartisi. Agar hasil dapat dikelola, contoh ini hanya akan menggunakan sejumlah kecil baris, sehingga fungsi partisi juga memerlukan batasan kecil:
CREATE PARTITION FUNCTION PF (integer) AS RANGE RIGHT FOR VALUES (5, 10, 15); CREATE PARTITION SCHEME PS AS PARTITION PF ALL TO ([PRIMARY]);
Tabel pertama berisi dua kolom, dan dipartisi dengan PRIMARY KEY:
CREATE TABLE dbo.T1
(
T1ID integer IDENTITY (1,1) NOT NULL,
SomeID integer NOT NULL,
CONSTRAINT [PK dbo.T1 T1ID]
PRIMARY KEY CLUSTERED (T1ID)
ON PS (T1ID)
);
Tabel kedua tidak dipartisi. Ini berisi kunci utama dan kolom yang akan bergabung ke tabel pertama:
CREATE TABLE dbo.T2
(
T2ID integer IDENTITY (1,1) NOT NULL,
T1ID integer NOT NULL,
CONSTRAINT [PK dbo.T2 T2ID]
PRIMARY KEY CLUSTERED (T2ID)
ON [PRIMARY]
); Contoh Data
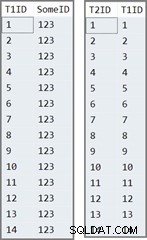
Tabel pertama memiliki 14 baris, semua dengan nilai yang sama di SomeID kolom. SQL Server memberikan IDENTITY nilai kolom, bernomor 1 sampai 14.
INSERT dbo.T1
(SomeID)
VALUES
(123), (123), (123),
(123), (123), (123),
(123), (123), (123),
(123), (123), (123),
(123), (123);
Tabel kedua hanya diisi dengan IDENTITY nilai dari tabel satu:
INSERT dbo.T2 (T1ID) SELECT T1ID FROM dbo.T1;
Data dalam dua tabel terlihat seperti ini:
Kueri Pengujian
Kueri pertama hanya menggabungkan kedua tabel, menerapkan predikat klausa WHERE tunggal (yang kebetulan cocok dengan semua baris dalam contoh yang sangat disederhanakan ini):
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123; Hasilnya berisi semua 14 baris, seperti yang diharapkan:

Karena jumlah baris yang sedikit, pengoptimal memilih rencana penggabungan loop bersarang untuk kueri ini:
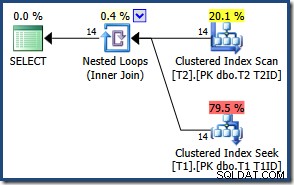
Hasilnya sama (dan masih benar) jika kita paksakan hash atau gabung gabung:
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (HASH JOIN);
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN);
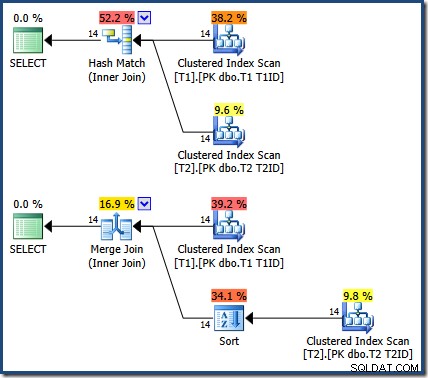
Gabung Gabung ada satu-ke-banyak, dengan pengurutan eksplisit pada T1ID diperlukan untuk tabel T2 .
Masalah Indeks Menurun
Semuanya baik-baik saja sampai suatu hari (untuk alasan bagus yang tidak perlu menjadi perhatian kita di sini) administrator lain menambahkan indeks turun pada SomeID kolom tabel 1
CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC);
Kueri kami terus memberikan hasil yang benar ketika pengoptimal memilih Nested Loops atau Hash Join, tetapi itu adalah cerita yang berbeda ketika Merge Join digunakan. Berikut ini masih menggunakan petunjuk kueri untuk memaksa Gabung Gabung, tetapi ini hanya konsekuensi dari jumlah baris yang rendah dalam contoh. Pengoptimal secara alami akan memilih paket Gabung Gabung yang sama dengan data tabel yang berbeda.
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN); Rencana eksekusi adalah:
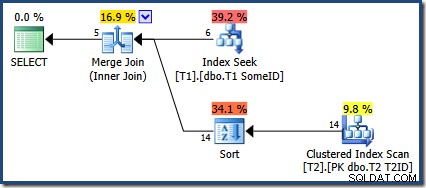
Pengoptimal telah memilih untuk menggunakan indeks baru, tetapi kueri sekarang hanya menghasilkan lima baris keluaran:

Apa yang terjadi dengan 9 baris lainnya? Agar jelas, hasil ini salah. Data tidak berubah, jadi 14 baris harus dikembalikan (karena masih dengan paket Nested Loops atau Hash Join).
Penyebab dan Penjelasan
Indeks nonclustered baru di SomeID tidak dideklarasikan sebagai unik, sehingga kunci indeks berkerumun secara diam-diam ditambahkan ke semua tingkat indeks yang tidak berkerumun. SQL Server menambahkan T1ID kolom (kunci berkerumun) ke indeks noncluster seperti jika kita telah membuat indeks seperti ini:
CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC, T1ID);
Perhatikan kurangnya DESC qualifier pada T1ID yang ditambahkan secara diam-diam kunci. Kunci indeks adalah ASC secara default. Ini bukan masalah itu sendiri (meskipun berkontribusi). Hal kedua yang terjadi pada indeks kita secara otomatis adalah ia dipartisi dengan cara yang sama seperti tabel dasar. Jadi, spesifikasi indeks lengkapnya, jika kita menuliskannya secara eksplisit, adalah:
CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC, T1ID ASC) ON PS (T1ID);
Sekarang ini adalah struktur yang cukup kompleks, dengan kunci dalam berbagai urutan yang berbeda. Cukup rumit bagi pengoptimal kueri untuk salah ketika menalar tentang urutan pengurutan yang disediakan oleh indeks. Sebagai ilustrasi, pertimbangkan kueri sederhana berikut:
SELECT
T1ID,
PartitionID = $PARTITION.PF(T1ID)
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID ASC;
Kolom tambahan hanya akan menunjukkan kepada kita di partisi mana baris saat ini berada. Jika tidak, itu hanya kueri sederhana yang mengembalikan T1ID nilai dalam urutan menaik, WHERE SomeID = 123 . Sayangnya, hasilnya tidak seperti yang ditentukan oleh kueri:
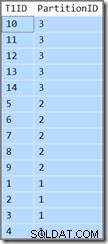
Kueri mengharuskan T1ID nilai harus dikembalikan dalam urutan menaik, tetapi bukan itu yang kami dapatkan. Kami mendapatkan nilai dalam urutan menaik per partisi , tetapi partisi itu sendiri dikembalikan dalam urutan terbalik! Jika partisi dikembalikan dalam urutan menaik (dan T1ID nilai tetap diurutkan dalam setiap partisi seperti yang ditunjukkan) hasilnya akan benar.
Rencana kueri menunjukkan bahwa pengoptimal dibingungkan oleh DESC leading terdepan kunci indeks, dan berpikir itu perlu membaca partisi dalam urutan terbalik untuk hasil yang benar:
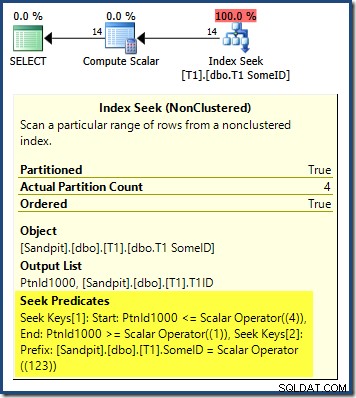
Pencarian partisi dimulai dari partisi paling kanan (4) dan berlanjut ke belakang ke partisi 1. Anda mungkin berpikir kami dapat memperbaiki masalah ini dengan mengurutkan secara eksplisit nomor partisi ASC di ORDER BY klausa:
SELECT
T1ID,
PartitionID = $PARTITION.PF(T1ID)
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
PartitionID ASC, -- New!
T1ID ASC; Kueri ini mengembalikan hasil yang sama (ini bukan kesalahan cetak atau copy/paste error):
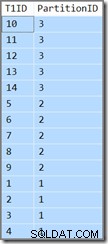
Id partisi masih dalam turun urutan (tidak menaik, seperti yang ditentukan) dan T1ID hanya diurutkan naik dalam setiap partisi. Begitulah kebingungan pengoptimal, ia benar-benar berpikir (tarik napas dalam-dalam sekarang) bahwa memindai indeks kunci menurun yang dipartisi ke arah maju, tetapi dengan partisi terbalik, akan menghasilkan urutan yang ditentukan oleh kueri.
Terus terang, saya tidak menyalahkannya, berbagai pertimbangan urutan membuat kepala saya sakit juga.
Sebagai contoh terakhir, pertimbangkan:
SELECT
T1ID
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID DESC; Hasilnya adalah:

Sekali lagi, T1ID urutkan urutan dalam setiap partisi turun dengan benar, tetapi partisi itu sendiri terdaftar mundur (mereka pergi dari 1 ke 3 ke bawah baris). Jika partisi dikembalikan dalam urutan terbalik, hasilnya akan benar menjadi 14, 13, 12, 11, 10, 9, … 5, 4, 3, 2, 1 .
Kembali ke Gabung Gabung
Penyebab hasil yang salah dengan kueri Gabung Bergabung sekarang terlihat:
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN);
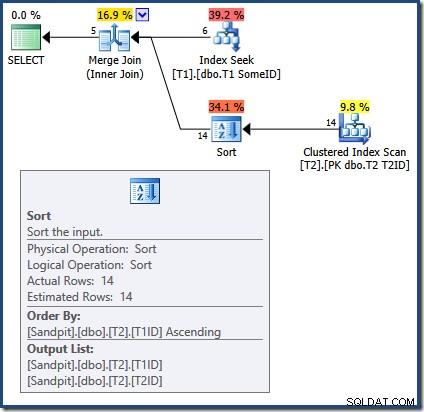
Gabung Gabung membutuhkan input yang diurutkan. Masukan dari T2 secara eksplisit diurutkan berdasarkan T1TD jadi tidak apa-apa. Pengoptimal salah memberi alasan bahwa indeks pada T1 dapat memberikan baris dalam T1ID memesan. Seperti yang telah kita lihat, ini tidak terjadi. Pencarian Indeks menghasilkan keluaran yang sama dengan kueri yang telah kita lihat:
SELECT
T1ID
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID ASC;

Hanya 5 baris pertama yang ada di T1ID memesan. Nilai berikutnya (5) tentu saja tidak dalam urutan menaik, dan Gabung Gabung menafsirkan ini sebagai akhir aliran daripada menghasilkan kesalahan (secara pribadi saya mengharapkan pernyataan ritel di sini). Bagaimanapun, efeknya adalah bahwa Gabung Gabung salah menyelesaikan pemrosesan lebih awal. Sebagai pengingat, hasil (tidak lengkap) adalah:

Kesimpulan
Ini adalah bug yang sangat serius menurut saya. Pencarian indeks sederhana dapat mengembalikan hasil yang tidak sesuai dengan ORDER BY ayat. Lebih tepatnya, penalaran internal pengoptimal benar-benar rusak untuk indeks nonclustered non-unik yang dipartisi dengan kunci utama menurun.
Ya, ini adalah sedikit susunan yang tidak biasa. Tetapi, seperti yang telah kita lihat, hasil yang benar dapat tiba-tiba digantikan oleh hasil yang salah hanya karena seseorang menambahkan indeks turun. Ingat indeks yang ditambahkan tampak cukup polos:tidak ada ASC/DESC eksplisit ketidakcocokan kunci, dan tidak ada partisi eksplisit.
Bug tidak terbatas pada Gabung Bergabung. Berpotensi setiap kueri yang melibatkan tabel yang dipartisi dan yang bergantung pada urutan pengurutan indeks (eksplisit atau implisit) dapat menjadi korban. Bug ini ada di semua versi SQL Server dari 2008 hingga 2014 CTP 1 inklusif. Windows SQL Azure Database tidak mendukung partisi, sehingga masalah tidak muncul. SQL Server 2005 menggunakan model implementasi yang berbeda untuk partisi (berdasarkan APPLY ) dan juga tidak mengalami masalah ini.
Jika Anda punya waktu, harap pertimbangkan untuk memilih item Connect saya untuk bug ini.
Resolusi
Perbaikan untuk masalah ini sekarang tersedia dan didokumentasikan dalam artikel Basis Pengetahuan. Harap perhatikan bahwa perbaikan memerlukan pembaruan kode dan tanda lacak 4199 , yang memungkinkan berbagai perubahan prosesor kueri lainnya. Tidak biasa untuk bug hasil yang salah diperbaiki di bawah 4199. Saya meminta klarifikasi tentang itu dan jawabannya adalah:
Meskipun masalah ini melibatkan hasil yang salah seperti hotfix lain yang melibatkan prosesor kueri, kami hanya mengaktifkan perbaikan ini di bawah bendera pelacakan 4199 untuk SQL Server 2008, 2008 R2, dan 2012. Namun, perbaikan ini "aktif" oleh default tanpa tanda jejak di SQL Server 2014 RTM.