Penggabungan dua atau lebih kumpulan data paling sering diekspresikan dalam T-SQL menggunakan UNION ALL ayat. Mengingat bahwa pengoptimal SQL Server sering dapat menyusun ulang hal-hal seperti bergabung dan agregat untuk meningkatkan kinerja, cukup masuk akal untuk mengharapkan bahwa SQL Server juga akan mempertimbangkan untuk menyusun ulang input rangkaian, di mana ini akan memberikan keuntungan. Misalnya, pengoptimal dapat mempertimbangkan manfaat menulis ulang A UNION ALL B sebagai B UNION ALL A .
Faktanya, pengoptimal SQL Server tidak melakukan hal ini. Lebih tepatnya, ada beberapa dukungan terbatas untuk pengurutan ulang input gabungan dalam rilis SQL Server hingga 2008 R2, tetapi ini dihapus di SQL Server 2012, dan tidak muncul lagi sejak itu.
SQL Server 2008 R2
Secara intuitif, urutan input rangkaian hanya penting jika ada tujuan baris . Secara default, SQL Server mengoptimalkan rencana eksekusi berdasarkan bahwa semua baris yang memenuhi syarat akan dikembalikan ke klien. Saat sasaran baris berlaku, pengoptimal mencoba menemukan rencana eksekusi yang akan menghasilkan beberapa baris pertama dengan cepat.
Sasaran baris dapat ditetapkan dengan beberapa cara, misalnya menggunakan TOP , sebuah FAST n petunjuk kueri, atau dengan menggunakan EXISTS (yang menurut sifatnya perlu menemukan paling banyak satu baris). Jika tidak ada tujuan baris (yaitu klien memerlukan semua baris), umumnya tidak masalah urutan input rangkaian dibaca:Setiap input akhirnya akan diproses sepenuhnya dalam kasus apa pun.
Dukungan terbatas dalam versi hingga SQL Server 2008 R2 berlaku jika ada tujuan tepat satu baris . Dalam keadaan khusus ini, SQL Server akan menyusun ulang input rangkaian berdasarkan perkiraan biaya.
Ini tidak dilakukan selama pengoptimalan berbasis biaya (seperti yang diharapkan), melainkan sebagai penulisan ulang pasca-pengoptimalan menit terakhir dari keluaran pengoptimal normal. Pengaturan ini memiliki keuntungan karena tidak menambah ruang pencarian rencana berbasis biaya (berpotensi satu alternatif untuk setiap kemungkinan pemesanan ulang), sambil tetap menghasilkan rencana yang dioptimalkan untuk mengembalikan baris pertama dengan cepat.
Contoh
Contoh berikut menggunakan dua tabel dengan konten yang identik:Satu juta baris bilangan bulat dari satu hingga satu juta. Satu tabel adalah tumpukan tanpa indeks nonclustered; yang lain memiliki indeks berkerumun yang unik:
CREATE TABLE dbo.Expensive
(
Val bigint NOT NULL
);
CREATE TABLE dbo.Cheap
(
Val bigint NOT NULL,
CONSTRAINT [PK dbo.Cheap Val]
UNIQUE CLUSTERED (Val)
);
GO
INSERT dbo.Cheap WITH (TABLOCKX)
(Val)
SELECT TOP (1000000)
Val = ROW_NUMBER() OVER (ORDER BY SV1.number)
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2
ORDER BY
Val
OPTION (MAXDOP 1);
GO
INSERT dbo.Expensive WITH (TABLOCKX)
(Val)
SELECT
C.Val
FROM dbo.Cheap AS C
OPTION (MAXDOP 1); Tidak Ada Sasaran Baris
Kueri berikut mencari baris yang sama di setiap tabel, dan mengembalikan gabungan dua set:
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005; Rencana eksekusi yang dihasilkan oleh pengoptimal kueri adalah:
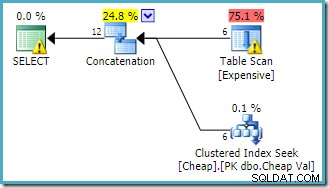
Peringatan pada root SELECT operator memberi tahu kami tentang indeks yang jelas hilang di tabel heap. Peringatan pada operator Table Scan ditambahkan oleh Sentry One Plan Explorer. Ini menarik perhatian kami pada biaya I/O dari predikat residual yang tersembunyi di dalam pemindaian.
Urutan input ke Penggabungan tidak menjadi masalah di sini, karena kami belum menetapkan tujuan baris. Kedua input akan sepenuhnya dibaca untuk mengembalikan semua baris hasil. Yang menarik (meskipun ini tidak dijamin) perhatikan bahwa urutan input mengikuti urutan tekstual dari kueri asli. Perhatikan juga bahwa urutan baris hasil akhir juga tidak ditentukan, karena kami tidak menggunakan ORDER BY tingkat atas ayat. Kami akan menganggap bahwa itu disengaja dan pemesanan terakhir tidak penting untuk tugas yang ada.
Jika kita membalik urutan tertulis dari tabel dalam kueri seperti ini:
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005; Rencana eksekusi mengikuti perubahan, mengakses tabel berkerumun terlebih dahulu (sekali lagi, ini tidak dijamin):
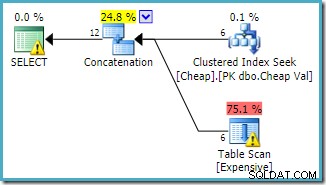
Kedua kueri mungkin diharapkan memiliki karakteristik kinerja yang sama, karena keduanya melakukan operasi yang sama, hanya dalam urutan yang berbeda.
Dengan Sasaran Baris
Jelas, kurangnya pengindeksan pada tabel heap biasanya akan membuat pencarian baris tertentu lebih mahal, dibandingkan dengan operasi yang sama pada tabel berkerumun. Jika kita meminta pengoptimal untuk rencana yang mengembalikan baris pertama dengan cepat, kita akan mengharapkan SQL Server untuk mengurutkan ulang input rangkaian sehingga tabel cluster yang murah dikonsultasikan terlebih dahulu.
Menggunakan kueri yang menyebutkan tabel heap terlebih dahulu, dan menggunakan petunjuk kueri FAST 1 untuk menentukan sasaran baris:
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005
OPTION (FAST 1); Perkiraan rencana eksekusi yang dihasilkan pada instance SQL Server 2008 R2 adalah:
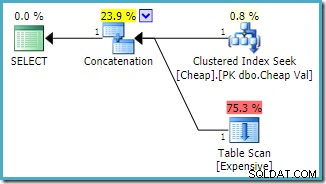
Perhatikan bahwa input rangkaian telah disusun ulang untuk mengurangi perkiraan biaya pengembalian baris pertama. Perhatikan juga bahwa indeks yang hilang dan peringatan I/O residual telah hilang. Tidak ada masalah yang terkait dengan bentuk rencana ini ketika tujuannya adalah untuk mengembalikan satu baris secepat mungkin.
Kueri yang sama dijalankan di SQL Server 2016 (menggunakan salah satu model estimasi kardinalitas) adalah:
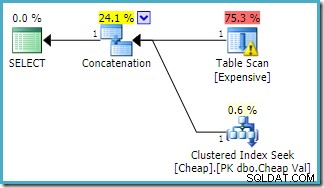
SQL Server 2016 tidak menyusun ulang input rangkaian. Peringatan Plan Explorer I/O telah kembali, tetapi sayangnya pengoptimal belum menghasilkan peringatan indeks yang hilang kali ini (meskipun relevan).
Pengaturan ulang umum
Seperti disebutkan, penulisan ulang pasca-pengoptimalan yang menyusun ulang input rangkaian hanya efektif untuk:
- SQL Server 2008 R2 dan sebelumnya
- Gol satu baris tepat satu
Jika kita benar-benar hanya ingin satu baris dikembalikan, daripada rencana yang dioptimalkan untuk mengembalikan baris pertama dengan cepat (tetapi yang pada akhirnya akan tetap mengembalikan semua baris), kita dapat menggunakan TOP klausa dengan tabel turunan atau ekspresi tabel umum (CTE):
SELECT TOP (1)
UA.Val
FROM
(
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005
) AS UA; Pada SQL Server 2008 R2 atau yang lebih lama, ini menghasilkan rencana input yang disusun ulang secara optimal:
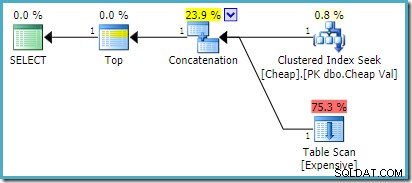
Di SQL Server 2012, 2014, dan 2016 tidak ada pengurutan ulang pasca-optimasi yang terjadi:
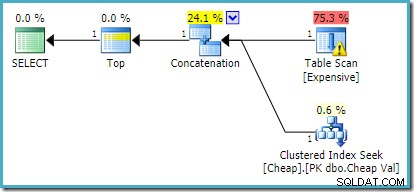
Jika kita ingin lebih dari satu baris dikembalikan, misalnya menggunakan TOP (2) , penulisan ulang yang diinginkan tidak akan diterapkan pada SQL Server 2008 R2 bahkan jika FAST 1 petunjuk juga digunakan. Dalam situasi itu, kita perlu menggunakan trik seperti menggunakan TOP dengan variabel dan OPTIMIZE FOR petunjuk:
DECLARE @TopRows bigint = 2; -- Number of rows actually needed
SELECT TOP (@TopRows)
UA.Val
FROM
(
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005
) AS UA
OPTION (OPTIMIZE FOR (@TopRows = 1)); -- Just a hint Petunjuk kueri cukup untuk menetapkan satu tujuan baris, sedangkan nilai waktu proses variabel memastikan jumlah baris (2) yang diinginkan dikembalikan.
Rencana eksekusi sebenarnya pada SQL Server 2008 R2 adalah:
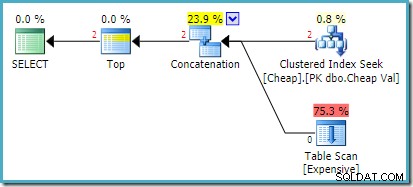
Kedua baris yang dikembalikan berasal dari input seek yang disusun ulang, dan Pemindaian Tabel tidak dijalankan sama sekali. Plan Explorer menunjukkan jumlah baris dengan warna merah karena perkiraannya adalah untuk satu baris (karena petunjuk) sedangkan dua baris ditemukan saat waktu berjalan.
Tanpa UNION SEMUA
Masalah ini juga tidak terbatas pada kueri yang ditulis secara eksplisit dengan UNION ALL . Konstruksi lain seperti EXISTS dan OR juga dapat mengakibatkan pengoptimal memperkenalkan operator penggabungan, yang mungkin mengalami kekurangan pengurutan ulang input. Ada pertanyaan baru-baru ini tentang Administrator Basis Data Stack Exchange dengan masalah ini. Mengubah kueri dari pertanyaan itu untuk menggunakan tabel contoh kami:
SELECT
CASE
WHEN
EXISTS
(
SELECT 1
FROM dbo.Expensive AS E
WHERE E.Val BETWEEN 751000 AND 751005
)
OR EXISTS
(
SELECT 1
FROM dbo.Cheap AS C
WHERE C.Val BETWEEN 751000 AND 751005
)
THEN 1
ELSE 0
END; Rencana eksekusi pada SQL Server 2016 memiliki tabel heap pada input pertama:
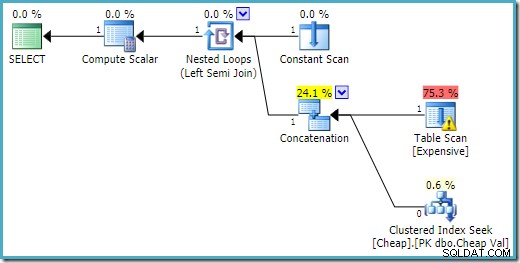
Pada SQL Server 2008 R2 urutan input dioptimalkan untuk mencerminkan tujuan baris tunggal dari semi join:
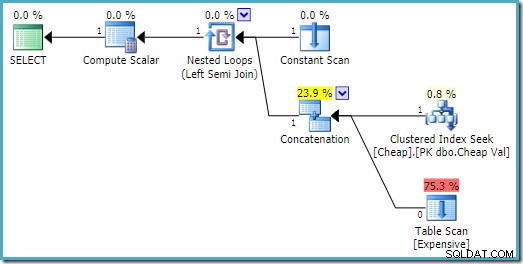
Dalam rencana yang lebih optimal, pemindaian heap tidak pernah dijalankan.
Solusi
Dalam beberapa kasus, akan terlihat jelas bagi penulis kueri bahwa salah satu input rangkaian akan selalu lebih murah untuk dijalankan daripada yang lain. Jika itu benar, cukup valid untuk menulis ulang kueri sehingga input rangkaian yang lebih murah muncul terlebih dahulu dalam urutan tertulis. Tentu saja ini berarti penulis kueri perlu menyadari batasan pengoptimal ini, dan bersiap untuk mengandalkan perilaku yang tidak terdokumentasi.
Masalah yang lebih sulit muncul ketika biaya input rangkaian bervariasi dengan keadaan, mungkin tergantung pada nilai parameter. Menggunakan OPTION (RECOMPILE) tidak akan membantu pada SQL Server 2012 atau yang lebih baru. Opsi tersebut dapat membantu pada SQL Server 2008 R2 atau yang lebih lama, tetapi hanya jika persyaratan sasaran baris tunggal juga terpenuhi.
Jika ada kekhawatiran tentang mengandalkan perilaku yang diamati (input rangkaian rencana kueri yang cocok dengan urutan teks kueri), panduan rencana dapat digunakan untuk memaksa bentuk rencana. Di mana pesanan input yang berbeda optimal untuk keadaan yang berbeda, beberapa panduan rencana dapat digunakan, di mana kondisinya dapat dikodekan secara akurat terlebih dahulu. Ini hampir tidak ideal.
Pemikiran Terakhir
Pengoptimal kueri SQL Server sebenarnya berisi berbasis biaya aturan eksplorasi, UNIAReorderInputs , yang mampu menghasilkan variasi urutan masukan gabungan dan mengeksplorasi alternatif selama pengoptimalan berbasis biaya (bukan sebagai penulisan ulang pasca-pengoptimalan satu kali).
Aturan ini saat ini tidak diaktifkan untuk penggunaan umum. Sejauh yang saya tahu, itu hanya diaktifkan ketika panduan paket atau USE PLAN petunjuk hadir. Hal ini memungkinkan mesin untuk berhasil memaksa rencana yang dibuat untuk kueri yang memenuhi syarat untuk penulisan ulang pengurutan ulang input, bahkan ketika kueri saat ini tidak memenuhi syarat.
Perasaan saya adalah bahwa aturan eksplorasi ini sengaja dibatasi untuk penggunaan ini, karena kueri yang akan mendapat manfaat dari penyusunan ulang input gabungan sebagai bagian dari pengoptimalan berbasis biaya dianggap tidak cukup umum, atau mungkin karena ada kekhawatiran bahwa upaya ekstra tidak akan membuahkan hasil. mati. Pandangan saya sendiri adalah bahwa pengurutan ulang input operator gabungan harus selalu dieksplorasi saat tujuan baris berlaku.
Sangat disayangkan bahwa penulisan ulang pasca-optimasi (lebih terbatas) tidak efektif di SQL Server 2012 atau yang lebih baru. Ini mungkin karena bug halus, tetapi saya tidak dapat menemukan apa pun tentang ini di dokumentasi, basis pengetahuan, atau di Connect. Saya telah menambahkan item Connect baru di sini.
Pembaruan 9 Agustus 2017 :Ini sekarang diperbaiki di bawah bendera pelacakan 4199 untuk SQL Server 2014 dan 2016, lihat KB 4023419:
MEMPERBAIKI:Kueri dengan UNION ALL dan sasaran baris dapat berjalan lebih lambat di SQL Server 2014 atau versi yang lebih baru jika dibandingkan dengan SQL Server 2008 R2