Model Relasional dari manajemen data pertama kali dikembangkan oleh Dr. Edgar F. Codd pada tahun 1969. Sistem manajemen basis data relasional modern (RDBMSes) diselaraskan dengan paradigma tersebut. Struktur kunci yang diidentifikasi dengan RDBMS adalah struktur logis yang disebut "tabel". Tabel terutama terdiri dari baris dan kolom (juga disebut catatan dan atribut atau tupel dan bidang). Dalam pengertian matematika yang ketat, istilah tabel sebenarnya disebut sebagai relasi dan menjelaskan istilah "Model Relasional". Dalam matematika, relasi adalah representasi dari suatu himpunan.
Atribut ekspresi memberikan deskripsi yang baik tentang tujuan kolom – atribut ini mencirikan kumpulan baris yang terkait dengannya. Setiap kolom harus dari tipe data tertentu dan setiap baris harus memiliki beberapa karakteristik pengidentifikasi unik yang disebut "kunci". Perubahan data biasanya lebih efisien bila dilakukan dengan menggunakan model relasional sementara pengambilan data mungkin lebih cepat dengan Model Hirarki yang lebih lama yang telah didefinisikan ulang dalam model sistem NoSQL.
Normalisasi Data adalah proses matematis dari pemodelan data bisnis ke dalam bentuk yang memastikan bahwa setiap entitas diwakili oleh satu relasi (tabel). Pendukung awal model relasional mengusulkan konsep Bentuk Normal. Edgar Codd mendefinisikan Bentuk Normal pertama, kedua, dan ketiga. Dia kemudian bergabung dengan Raymond F. Boyce. Bersama-sama mereka mendefinisikan Bentuk Normal Boyce-Codd. Sekarang, enam Bentuk Normal didefinisikan secara teoritis tetapi dalam sebagian besar aplikasi praktis, kami biasanya memperluas Normalisasi hingga Bentuk Normal Ketiga. Setiap Bentuk Normal berusaha untuk menghindari anomali selama modifikasi data, mengurangi redundansi dan ketergantungan data dalam tabel. Setiap tingkat normalisasi cenderung memperkenalkan lebih banyak tabel, mengurangi redundansi, meningkatkan kesederhanaan setiap tabel tetapi juga meningkatkan kompleksitas sistem manajemen basis data relasional secara keseluruhan. Jadi secara struktural sistem RDBM cenderung lebih kompleks daripada sistem Hirarki.
Mengapa Normalisasi Basis Data:Empat Anomali
Penyimpanan data tanpa normalisasi menyebabkan sejumlah masalah dengan konsumsi data. Para pendukung normalisasi menyebut masalah seperti itu sebagai anomali. Untuk menggambarkan anomali tersebut, mari kita lihat data yang disajikan pada Gambar 1.

Gbr. 1 Meja Staf
Listing 1. Tabel Dasar untuk Mendemonstrasikan Normalisasi Database.
1.1. Buat Tabel
use privatework go create table staffers ( staffID int identity (1,1) ,StaffName varchar(50) ,Role varchar(50) ,Department varchar (100) ,Manager varchar (50) ,Gender char(1) ,DateofBirth datetime2 )
1.2. Sisipkan Baris
insert into staffers values ('John Doe','Engineering','Kweku Amarh','M','06-Oct-1965');
insert into staffers values ('Henry Ofori','Engineering','Kweku Amarh','M','06-Mar-1982');
insert into staffers values ('Jessica Yuiah','Engineering','Kweku Amarh','F','06-Oct-1965');
insert into staffers values ('Ahmed Assah','Engineering','Kweku Amarh','M','06-Oct-1965'); 1.3. Kueri Tabelnya
select * from staffers;
Tabel ini pada dasarnya mewakili dua set data yang telah digabungkan secara tidak sengaja:nama staf dan departemen. Perhatikan bahwa semua staf berasal dari departemen yang sama:Teknik. Itu dilakukan untuk kesederhanaan dan untuk menunjukkan normalisasi. Ada tiga masalah utama yang terkait dengan manipulasi struktur ini:
Anomali Penyisipan
Untuk memasukkan record baru, kita harus terus mengulang nama departemen dan manajer.
Anomali Penghapusan
Untuk menghapus catatan staf, kami juga harus menghapus manajer dan departemen terkait. Jika ada kebutuhan untuk menghapus catatan SEMUA staf, kami juga harus menghapus semua departemen dan semua manajer.
Anomali Pembaruan
Jika ada kebutuhan untuk mengganti manajer departemen mana pun, kita harus membuat perubahan di setiap baris tabel ini karena nilainya diduplikasi untuk setiap staf.
Bentuk Normal Basis Data
Di bagian artikel berikut, kami akan mencoba mendeskripsikan Bentuk Normal ke-1, ke-2, dan ke-3 yang lebih mungkin diamati dalam Sistem RDBM yang sebenarnya. Ada perluasan lain dari teori seperti Bentuk Normal Keempat, Kelima, dan Boyce-Codd tetapi dalam artikel ini, kita akan membatasi diri pada Tiga Bentuk Normal.
Bentuk Normal Pertama
Bentuk Normal Pertama ditentukan oleh empat aturan:
Setiap kolom harus berisi nilai dengan tipe data yang sama.
Tabel Staf sudah memenuhi aturan ini.
Setiap kolom dalam tabel harus atomik.
Ini pada dasarnya berarti Anda harus membagi isi kolom sampai tidak dapat dibagi lagi. Perhatikan bahwa Peran kolom di Staf tabel melanggar aturan 2 untuk baris dengan StaffID=3.
Setiap baris dalam tabel harus unik.
Keunikan dalam tabel yang dinormalisasi biasanya dicapai dengan menggunakan Kunci Utama. Kunci Utama secara unik mendefinisikan setiap baris dalam tabel. Sebagian besar waktu, Kunci Utama didefinisikan hanya oleh satu kolom. Kunci Utama yang terdiri dari lebih dari satu kolom disebut Kunci Komposit.
Urutan penyimpanan catatan tidak penting.
Untuk menyelaraskan data di Staffs tabel dengan prinsip First Normal Form kita perlu membagi tabel seperti yang ditunjukkan pada Gambar 2, 3 dan 4.
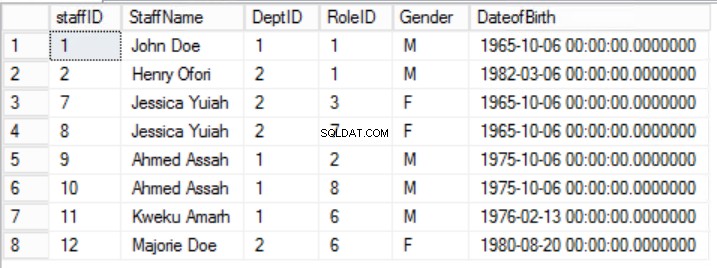
Gbr. 2 Meja Staf
Kami telah mempersempit data di Staf tabel dan menerapkan Kunci Primer Komposit untuk menjamin keunikan. Kami juga telah membuat dua tabel tambahan Peran dan Departemen yang memiliki hubungan dengan Staf inti tabel diimplementasikan menggunakan Kunci Asing. Tinjau DDL di Daftar 2.
Daftar 2. DDL dari Staf Baru Tabel Bentuk Normal Pertama.
USE [PrivateWork] GO CREATE TABLE [dbo].[staffers]( [staffID] [int] IDENTITY(1,1) NOT NULL, [StaffName] [varchar](50) NULL, [DeptID] [int] NOT NULL, [RoleID] [int] NOT NULL, [Gender] [char](1) NULL, [DateofBirth] [datetime2](7) NULL, PRIMARY KEY CLUSTERED ( [staffID] ASC, [RoleID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[staffers1NF] WITH CHECK ADD FOREIGN KEY([DeptID]) REFERENCES [dbo].[Department] ([DeptID]) GO ALTER TABLE [dbo].[staffers1NF] WITH CHECK ADD FOREIGN KEY([RoleID]) REFERENCES [dbo].[Roles] ([RoleID]) GO
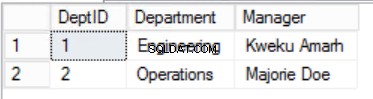
Gbr. Tabel 3 Departemen
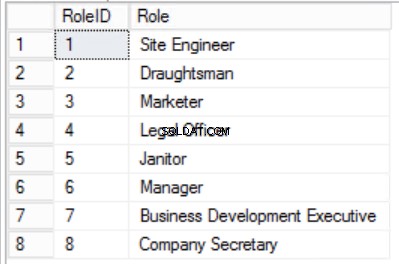
Gbr. 4 Tabel Peran
Bentuk Normal Kedua
Bentuk Normal 1 harus sudah ada.
Setiap kolom bukan kunci tidak boleh memiliki Ketergantungan Sebagian pada Kunci Utama.
Tujuan dari aturan kedua adalah bahwa semua kolom tabel harus bergantung pada semua kolom yang terdiri dari Kunci Utama bersama-sama. Melihat kembali tabel pada Gambar 2, 3 dan 4, kami menemukan bahwa kami telah mencapai semua persyaratan Bentuk Normal Pertama. Kami juga telah mencapai persyaratan Bentuk Normal Kedua untuk dua tabel Peran dan Departemen . Namun, dalam kasus Staf meja, kami masih memiliki masalah. Kunci Utama kami terdiri dari kolom StaffID dan RoleID.
Aturan 2 dari Bentuk Normal Kedua dilanggar di sini oleh fakta bahwa Gender dan Tanggal Lahir staf tidak bergantung pada RoleID. Ada Ketergantungan Parsial.
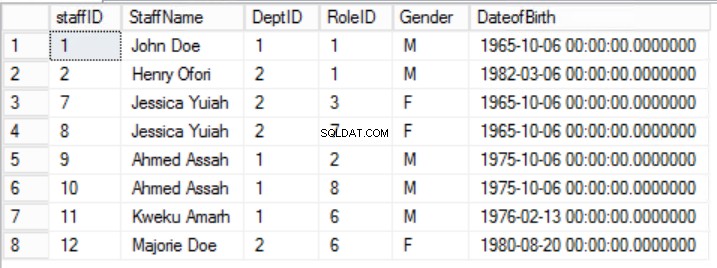
Gbr. 5 Staf untuk Formulir Normal Pertama
Dalam contoh yang diberikan, kita dapat mencoba memperbaikinya dengan menghapus RoleID dari Kunci Utama tetapi jika kita melakukan ini, kita akan melanggar aturan lain:peran keunikan yang dinyatakan dalam Bentuk Normal Pertama. Kita harus mengambil pendekatan lain. Kami akan memodifikasi Staf meja dengan pemahaman bahwa seorang staf dapat memainkan lebih dari satu peran. Lihat Gambar 6.
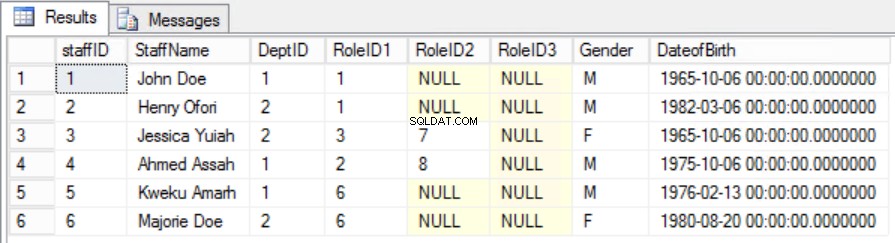
Gbr. 6 Tabel Staff untuk Bentuk Normal Kedua
Kami telah berhasil mempertahankan keunikan sekaligus menghilangkan Ketergantungan Sebagian.
Listing 3. DDL Tabel Staffer Baru untuk Bentuk Normal Kedua.
USE [PrivateWork] GO CREATE TABLE [dbo].[staffers2NF]( [staffID] [int] IDENTITY(1,1) NOT NULL, [StaffName] [varchar](50) NULL, [DeptID] [int] NOT NULL, [RoleID1] [int] NOT NULL, [RoleID2] [int] NULL, [RoleID3] [int] NULL, [Gender] [char](1) NULL, [DateofBirth] [datetime2](7) NULL, PRIMARY KEY CLUSTERED ( [staffID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([DeptID]) REFERENCES [dbo].[Department] ([DeptID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID1]) REFERENCES [dbo].[Roles] ([RoleID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID2]) REFERENCES [dbo].[Roles] ([RoleID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID3]) REFERENCES [dbo].[Roles] ([RoleID]) GO
Bentuk Normal Ketiga
Bentuk Normal ke-2 harus sudah ada.
Setiap kolom bukan kunci tidak boleh memiliki Ketergantungan Transitif pada Kunci Utama.
Tujuan dari bentuk normal ketiga adalah tidak boleh ada kolom yang bergantung pada kolom non-kunci meskipun kolom non-kunci tersebut sudah bergantung pada Kunci Utama.
Sebagai contoh, asumsikan kami memutuskan untuk menambahkan kolom tambahan ke Staffs tabel seperti yang ditunjukkan pada Gambar. 7 untuk melihat dengan jelas manajer staf. Dengan melakukan itu kita akan melanggar aturan Bentuk Normal Ketiga kedua, karena Nama Manajer bergantung pada DeptID dan DeptID, pada gilirannya, bergantung pada StaffID. Ini adalah Ketergantungan Transitif.
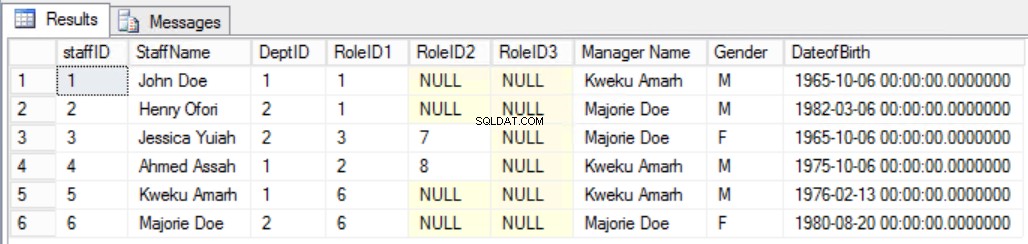
Gbr. 7 Tabel Staff untuk Bentuk Normal Ketiga (Aturan Rusak)
Akan lebih baik untuk mempertahankan formulir lama dan menampilkan informasi yang diperlukan menggunakan gabungan antara tabel Staf dan tabel Departemen.
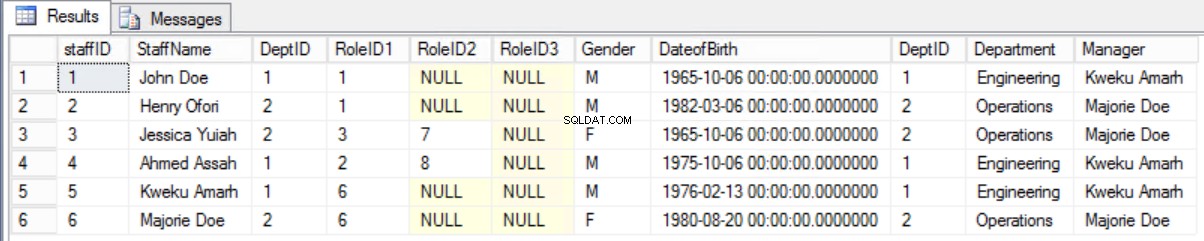
Gbr. 8 Bergabung Antara Staf dan Departemen
Daftar 4. Permintaan untuk Menampilkan Staf dan Manajer.
select * from staffers2NF s join Department d on s.DeptID=d.DeptID;
Aplikasi Praktis
Sebagian besar aplikasi dewasa menerapkan aturan normalisasi hingga batas yang wajar. Kami melihat bahwa implementasi normalisasi data memunculkan penggunaan Primary Key Constraints dan Foreign Key Constraints. Selain itu, masalah seperti pengindeksan Kunci Asing juga muncul saat kita mempelajari subjek lebih dalam. Sebelumnya kami telah menyebutkan bagaimana kurangnya normalisasi dapat mempengaruhi kelancaran manipulasi data seperti yang dijelaskan dalam Anomali Penyisipan, Penghapusan, dan Pembaruan. Kurangnya normalisasi yang tepat juga dapat secara tidak langsung memengaruhi kinerja kueri.
Baru-baru ini saya menemukan tabel yang bentuknya seperti yang ditunjukkan pada tabel 1 yang akan kita sebut Customer_Accounts.
S/Tidak | Nama | No_Akun | No Telepon_ |
1 | Kenneth Igiri | 9922344592 | 2348039988456, 2348039988456, 2348039988456 |
2 | Ernest Doe | 6677554897 | 2348022887546, 2348039988456 |
Tabel 1 Akun_Pelanggan
Masalah utama tabel ini adalah tabel ini melanggar aturan kedua dari Bentuk Normal Pertama. Hasil dalam kasus kami adalah bahwa mencari pelanggan berdasarkan nomor telepon mereka memerlukan penggunaan LIKE di klausa WHERE dan % di depan.
Select account_no from Customer_Accounts where Phone_No like ‘%2348039988456%’;
Dampak dari konstruksi di atas adalah pengoptimal tidak pernah menggunakan indeks yang merupakan masalah kinerja yang sangat besar.
Kesimpulan
Normalisasi Data terletak di bidang Desain Basis Data dan baik pengembang maupun DBA harus memperhatikan aturan yang diuraikan dalam artikel ini. Itu selalu lebih baik untuk menyelesaikan normalisasi sebelum database masuk ke produksi. Manfaat dari Sistem Manajemen Basis Data Relasional yang dirancang dengan baik tidak sia-sia.



