Sekarang komunitas analitik data besar kami telah mulai menggunakan Apache Spark secara penuh untuk pemrosesan data besar. Pemrosesan bisa untuk kueri ad-hoc, kueri bawaan, pemrosesan grafik, pembelajaran mesin, dan bahkan untuk streaming data.
Oleh karena itu pemahaman tentang Spark Job Submission sangat penting bagi masyarakat. Sampaikan dengan senang hati untuk berbagi dengan Anda pembelajaran tentang langkah-langkah yang terlibat dalam Pengajuan Pekerjaan Apache Spark.
Pada dasarnya memiliki dua langkah,

Pengajuan Pekerjaan
Pekerjaan Spark dikirimkan secara otomatis ketika tindakan seperti count () dilakukan pada RDD.
Secara internal runJob() untuk dipanggil pada SparkContext dan kemudian memanggil penjadwal yang berjalan sebagai bagian dari deriver.
Penjadwal terdiri dari 2 bagian – Penjadwal DAG dan Penjadwal Tugas.
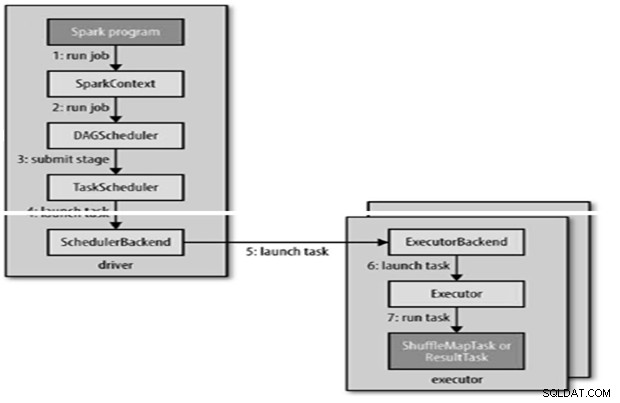
Konstruksi DAG
Ada dua jenis konstruksi DAG,

- Pekerjaan Spark sederhana adalah pekerjaan yang tidak memerlukan pengacakan dan karena itu hanya memiliki satu tahap yang terdiri dari tugas hasil, seperti tugas khusus peta di MapReduce
- Pekerjaan Spark Kompleks melibatkan operasi pengelompokan dan memerlukan satu atau beberapa tahapan acak.
- Penjadwal DAG Spark mengubah tugas menjadi dua tahap.
- Penjadwal DAG bertanggung jawab untuk membagi tahapan menjadi tugas untuk diserahkan ke penjadwal tugas.
- Setiap tugas diberikan preferensi penempatan oleh penjadwal DAG untuk memungkinkan penjadwal tugas memanfaatkan lokalitas data.
- Tahapan anak hanya dikirimkan setelah orang tua mereka berhasil menyelesaikannya.
Penjadwalan Tugas
- Penjadwal tugas akan mengirimkan serangkaian tugas; ia menggunakan daftar pelaksana yang berjalan untuk aplikasi dan membuat pemetaan tugas ke pelaksana yang mempertimbangkan preferensi penempatan.
- Penjadwal tugas ditetapkan ke pelaksana yang memiliki inti bebas, setiap tugas dialokasikan satu inti secara default. Itu dapat diubah dengan parameter spark.task.cpus.
- Spark menggunakan Akka, yang merupakan platform berbasis aktor untuk membangun aplikasi terdistribusi berbasis peristiwa yang sangat skalabel.
- Spark tidak menggunakan Hadoop RPC untuk panggilan jarak jauh.
Eksekusi Tugas
Seorang pelaksana menjalankan tugas sebagai berikut,
- Ini memastikan bahwa JAR dan ketergantungan file untuk tugas itu mutakhir.
- Membatalkan serialisasi kode tugas.
- Kode tugas dijalankan.
- Tugas mengembalikan hasil ke driver, yang dirakit menjadi hasil akhir untuk dikembalikan ke pengguna.
Referensi
- Panduan Definitif Hadoop
- Komunitas Open Source Analytics &Big Data
Artikel ini awalnya muncul di sini. Diterbitkan ulang dengan izin. Kirim keluhan hak cipta Anda di sini.