Saya baru-baru ini dimarahi karena menyarankan bahwa, dalam beberapa kasus, indeks yang tidak berkerumun akan berkinerja lebih baik untuk kueri tertentu daripada indeks berkerumun. Orang ini menyatakan bahwa indeks berkerumun selalu yang terbaik karena selalu mencakup definisi, dan bahwa setiap indeks yang tidak berkerumun dengan beberapa atau semua kolom kunci yang sama selalu berlebihan.
Saya dengan senang hati akan setuju bahwa indeks berkerumun selalu mencakup (dan untuk menghindari ambiguitas di sini, kita akan tetap berpegang pada tabel berbasis disk dengan indeks B-tree tradisional).
 Saya tidak setuju, bahwa indeks berkerumun selalu lebih cepat dari indeks non-cluster. Saya juga tidak setuju bahwa selalu berlebihan untuk membuat indeks non-clustered atau batasan unik yang terdiri dari kolom yang sama (atau beberapa kolom yang sama) di kunci clustering.
Saya tidak setuju, bahwa indeks berkerumun selalu lebih cepat dari indeks non-cluster. Saya juga tidak setuju bahwa selalu berlebihan untuk membuat indeks non-clustered atau batasan unik yang terdiri dari kolom yang sama (atau beberapa kolom yang sama) di kunci clustering.
Mari kita ambil contoh ini, Warehouse.StockItemTransactions , dari WideWorldImporters. Indeks berkerumun diimplementasikan melalui kunci utama hanya pada StockItemTransactionID kolom (cukup umum ketika Anda memiliki semacam ID pengganti yang dihasilkan oleh IDENTITY atau SEQUENCE).
Ini adalah hal yang cukup umum untuk meminta hitungan seluruh tabel (meskipun dalam banyak kasus ada cara yang lebih baik). Ini bisa untuk pemeriksaan biasa atau sebagai bagian dari prosedur pagination. Kebanyakan orang akan melakukannya dengan cara ini:
SELECT COUNT(*) FROM Warehouse.StockItemTransactions;
Dengan skema saat ini, ini akan menggunakan indeks non-cluster:
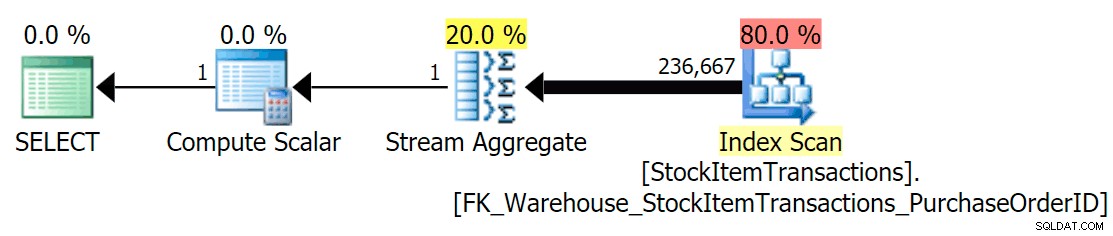
Kita tahu bahwa indeks yang tidak berkerumun tidak berisi semua kolom dalam indeks berkerumun. Operasi penghitungan hanya perlu memastikan bahwa semua baris disertakan, tanpa mempedulikan kolom mana yang ada, jadi SQL Server biasanya akan memilih indeks dengan jumlah halaman terkecil (dalam hal ini, indeks yang dipilih memiliki ~414 halaman).
Sekarang mari kita jalankan kueri lagi, kali ini bandingkan dengan kueri petunjuk yang memaksa penggunaan indeks berkerumun.
SELECT COUNT(*) FROM Warehouse.StockItemTransactions; SELECT COUNT(*) /* with hint */ FROM Warehouse.StockItemTransactions WITH (INDEX(1));
Kami mendapatkan bentuk rencana yang hampir sama, tetapi kami dapat melihat perbedaan besar dalam pembacaan (414 untuk indeks yang dipilih vs. 1,982 untuk indeks yang dikelompokkan):
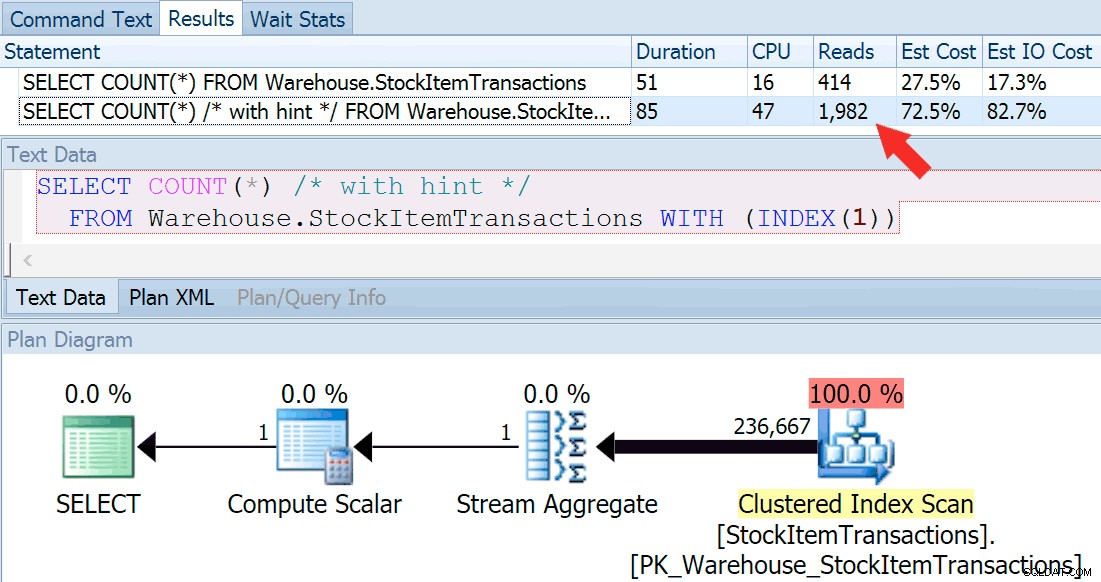
Durasi sedikit lebih tinggi untuk indeks berkerumun, tetapi perbedaannya dapat diabaikan ketika kita berurusan dengan sejumlah kecil data cache pada disk cepat. Perbedaan itu akan jauh lebih jelas dengan lebih banyak data, pada disk yang lambat, atau pada sistem dengan tekanan memori.
Jika kita melihat tooltips untuk operasi pemindaian, kita dapat melihat bahwa meskipun jumlah baris dan perkiraan biaya CPU identik, perbedaan besar berasal dari perkiraan biaya I/O (karena SQL Server tahu bahwa ada lebih banyak halaman di indeks berkerumun daripada indeks tidak berkerumun):
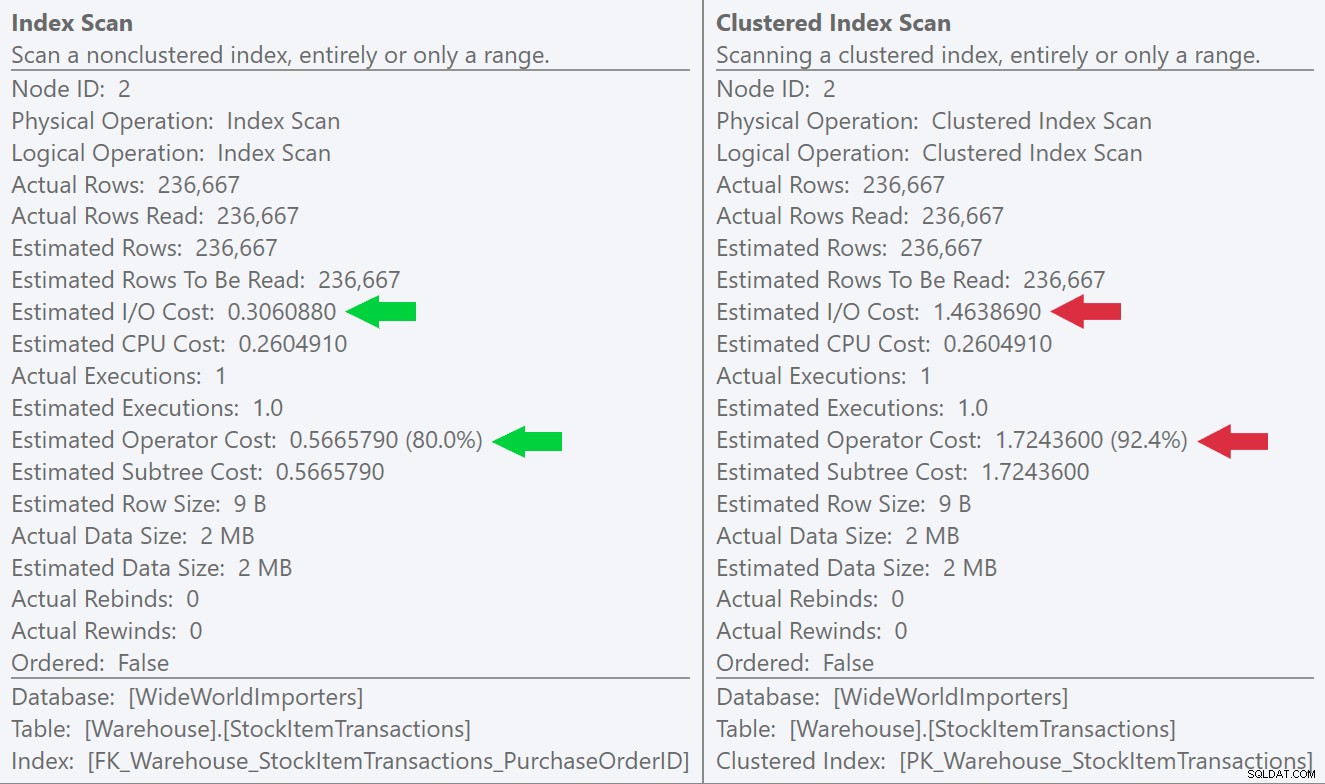
Kita bisa melihat perbedaan ini lebih jelas lagi jika kita membuat indeks baru yang unik hanya pada kolom ID (membuatnya "berlebihan" dengan indeks berkerumun, kan?):
CREATE UNIQUE INDEX NewUniqueNCIIndex ON Warehouse.StockItemTransactions(StockItemTransactionID);
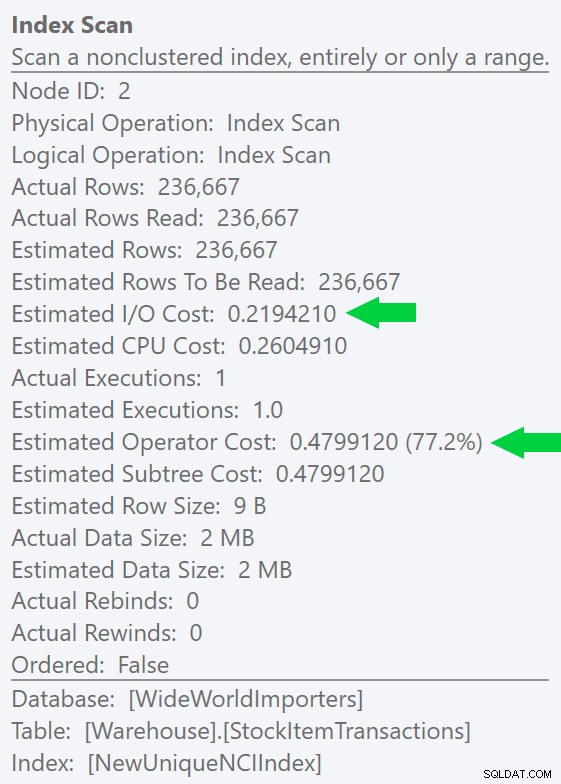 Menjalankan kueri serupa dengan petunjuk indeks eksplisit menghasilkan bentuk rencana yang sama, tetapi perkiraan I/O yang lebih rendah biaya (dan bahkan durasi yang lebih rendah) – lihat gambar di sebelah kanan. Dan jika Anda menjalankan kueri asli tanpa petunjuk, Anda akan melihat bahwa SQL Server sekarang juga memilih indeks ini.
Menjalankan kueri serupa dengan petunjuk indeks eksplisit menghasilkan bentuk rencana yang sama, tetapi perkiraan I/O yang lebih rendah biaya (dan bahkan durasi yang lebih rendah) – lihat gambar di sebelah kanan. Dan jika Anda menjalankan kueri asli tanpa petunjuk, Anda akan melihat bahwa SQL Server sekarang juga memilih indeks ini.
Ini mungkin tampak jelas, tetapi banyak orang akan percaya bahwa indeks berkerumun adalah pilihan terbaik di sini. SQL Server hampir selalu akan sangat mendukung metode apa pun yang akan menyediakan cara termurah untuk melakukan semua I/O, dan dalam kasus pemindaian penuh, itu akan menjadi indeks "paling kurus". Ini juga dapat terjadi dengan kedua jenis pencarian (scan tunggal dan rentang), setidaknya saat indeks tertutup.
Sekarang, seperti biasa, itu tidak dengan cara apa pun berarti Anda harus pergi dan membuat indeks tambahan di semua tabel Anda untuk memenuhi kueri penghitungan. Tidak hanya itu cara yang tidak efisien untuk memeriksa ukuran tabel (sekali lagi, lihat artikel ini), tetapi indeks untuk mendukung itu berarti Anda menjalankan kueri itu lebih sering daripada memperbarui data. Ingatlah bahwa setiap indeks memerlukan ruang pada disk, ruang pada memori, dan semua penulisan pada tabel juga harus menyentuh setiap indeks (kecuali indeks yang difilter).
Ringkasan
Saya dapat menemukan banyak contoh lain yang menunjukkan kapan non-clustered dapat berguna dan sepadan dengan biaya pemeliharaan, bahkan ketika menduplikasi kolom kunci dari indeks clustered. Indeks yang tidak berkerumun dapat dibuat dengan kolom kunci yang sama tetapi dalam urutan kunci yang berbeda, atau dengan ASC/DESC yang berbeda pada kolom itu sendiri untuk mendukung urutan presentasi alternatif dengan lebih baik. Anda juga dapat memiliki indeks non-cluster yang hanya membawa sebagian kecil baris melalui penggunaan filter. Terakhir, jika Anda dapat memenuhi kueri paling umum dengan indeks yang lebih tipis dan tidak berkerumun, itu juga lebih baik untuk konsumsi memori.
Tapi sungguh, poin saya dari seri ini hanyalah untuk menunjukkan contoh tandingan yang menggambarkan kebodohan membuat pernyataan menyeluruh seperti ini. Saya akan meninggalkan Anda dengan penjelasan dari Paul White yang, dalam jawaban DBA.SE, menjelaskan mengapa indeks yang tidak berkerumun seperti itu sebenarnya dapat berkinerja jauh lebih baik daripada indeks berkerumun. Hal ini berlaku bahkan ketika keduanya menggunakan salah satu jenis pencarian:
- Perbedaan antara pencarian indeks berkerumun dan pencarian indeks tidak berkerumun