[ Bagian 1 | Bagian 2 | Bagian 3 | Bagian 4 ]
Banyak yang telah ditulis selama bertahun-tahun tentang memahami dan mengoptimalkan SELECT kueri, tetapi lebih sedikit tentang modifikasi data. Rangkaian postingan ini membahas masalah khusus untuk INSERT , UPDATE , DELETE dan MERGE kueri – Masalah Halloween.
Ungkapan "Masalah Halloween" awalnya diciptakan dengan referensi ke SQL UPDATE permintaan yang seharusnya memberikan kenaikan 10% untuk setiap karyawan yang berpenghasilan kurang dari $25.000. Masalahnya adalah kueri itu terus memberikan kenaikan 10% sampai semua orang mendapatkan setidaknya $25.000. Kita akan melihat nanti dalam seri ini bahwa masalah mendasar juga berlaku untuk INSERT , DELETE dan MERGE pertanyaan, tetapi untuk entri pertama ini, akan sangat membantu untuk memeriksa UPDATE masalah dengan sedikit detail.
Latar Belakang
Bahasa SQL menyediakan cara bagi pengguna untuk menentukan perubahan basis data menggunakan UPDATE pernyataan, tetapi sintaks tidak mengatakan apa pun tentang bagaimana mesin database harus melakukan perubahan. Di sisi lain, standar SQL tidak menetapkan bahwa hasil dari UPDATE harus sama seperti jika telah dieksekusi dalam tiga fase terpisah dan tidak tumpang tindih:
- Penelusuran hanya baca menentukan catatan yang akan diubah dan nilai kolom baru
- Perubahan diterapkan pada rekaman yang terpengaruh
- Keterbatasan konsistensi basis data telah diverifikasi
Menerapkan ketiga fase ini secara harfiah dalam mesin basis data akan menghasilkan hasil yang benar, tetapi kinerjanya mungkin tidak terlalu baik. Hasil antara pada setiap tahap akan membutuhkan memori sistem, mengurangi jumlah kueri yang dapat dijalankan sistem secara bersamaan. Memori yang diperlukan mungkin juga melebihi yang tersedia, membutuhkan setidaknya sebagian dari set pembaruan untuk ditulis ke penyimpanan disk dan dibaca kembali nanti. Last but not least, setiap baris dalam tabel perlu disentuh beberapa kali di bawah model eksekusi ini.
Strategi alternatif adalah memproses UPDATE berturut-turut pada suatu waktu. Ini memiliki keuntungan hanya menyentuh setiap baris sekali, dan umumnya tidak memerlukan memori untuk penyimpanan (meskipun beberapa operasi, seperti pengurutan penuh, harus memproses set input penuh sebelum menghasilkan baris pertama output). Model berulang ini adalah yang digunakan oleh mesin eksekusi kueri SQL Server.
Tantangan untuk pengoptimal kueri adalah menemukan rencana eksekusi berulang (baris demi baris) yang memenuhi UPDATE semantik yang diperlukan oleh standar SQL, sambil mempertahankan kinerja dan manfaat konkurensi dari eksekusi pipelined.
Pemrosesan Pembaruan
Untuk mengilustrasikan masalah awal, kami akan menerapkan kenaikan 10% untuk setiap karyawan yang berpenghasilan kurang dari $25.000 menggunakan Employees tabel di bawah ini:

CREATE TABLE dbo.Employees
(
Name nvarchar(50) NOT NULL,
Salary money NOT NULL
);
INSERT dbo.Employees
(Name, Salary)
VALUES
('Brown', $22000),
('Smith', $21000),
('Jones', $25000);
UPDATE e
SET Salary = Salary * $1.1
FROM dbo.Employees AS e
WHERE Salary < $25000; Strategi pembaruan tiga fase
Tahap pertama read-only menemukan semua record yang memenuhi WHERE predikat klausa, dan menyimpan informasi yang cukup untuk tahap kedua untuk melakukan pekerjaannya. Dalam praktiknya, ini berarti merekam pengidentifikasi unik untuk setiap baris kualifikasi (kunci indeks berkerumun atau pengidentifikasi baris tumpukan) dan nilai gaji baru. Setelah fase satu selesai, seluruh rangkaian informasi pembaruan diteruskan ke fase kedua, yang menempatkan setiap catatan untuk diperbarui menggunakan pengenal unik, dan mengubah gaji ke nilai baru. Fase ketiga kemudian memeriksa bahwa tidak ada batasan integritas database yang dilanggar oleh status akhir tabel.
Strategi berulang
Pendekatan ini membaca satu baris pada satu waktu dari tabel sumber. Jika baris memenuhi WHERE predikat klausa, kenaikan gaji diterapkan. Proses ini berulang sampai semua baris telah diproses dari sumbernya. Contoh rencana eksekusi menggunakan model ini ditunjukkan di bawah ini:

Seperti biasa untuk pipeline yang digerakkan oleh permintaan SQL Server, eksekusi dimulai dari operator paling kiri – UPDATE pada kasus ini. Ini meminta baris dari Pembaruan Tabel, yang meminta baris dari Skalar Hitung, dan ke bawah rantai ke Pemindaian Tabel:
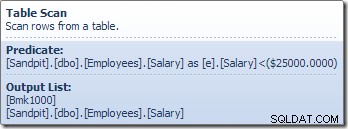
Operator Pemindaian Tabel membaca baris satu per satu dari mesin penyimpanan, hingga menemukan satu yang memenuhi predikat Gaji. Daftar keluaran pada grafik di atas menunjukkan operator Pemindaian Tabel yang mengembalikan pengidentifikasi baris dan nilai kolom Gaji saat ini untuk baris ini. Satu baris yang berisi referensi ke dua bagian informasi ini diteruskan ke Skalar Hitung:
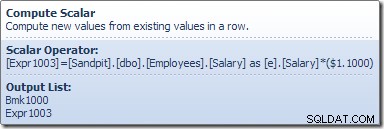
Skalar Hitung mendefinisikan ekspresi yang menerapkan kenaikan gaji ke baris saat ini. Ini mengembalikan baris yang berisi referensi ke pengidentifikasi baris dan gaji yang dimodifikasi ke Pembaruan Tabel, yang memanggil mesin penyimpanan untuk melakukan modifikasi data. Proses berulang ini terus berlanjut hingga Pemindaian Tabel kehabisan baris. Proses dasar yang sama diikuti jika tabel memiliki indeks berkerumun:
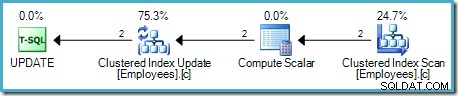
Perbedaan utama adalah bahwa kunci indeks berkerumun dan uniquifier (jika ada) digunakan sebagai pengidentifikasi baris alih-alih heap RID.
Masalahnya
Perubahan dari operasi tiga fase logis yang didefinisikan dalam standar SQL ke model eksekusi fisik berulang telah memperkenalkan sejumlah perubahan halus, hanya satu yang akan kita lihat hari ini. Masalah dapat terjadi dalam contoh yang sedang berjalan jika ada indeks nonclustered pada kolom Gaji, yang diputuskan oleh pengoptimal kueri untuk menemukan baris yang memenuhi syarat (Gaji <$25,000):
CREATE NONCLUSTERED INDEX nc1 ON dbo.Employees (Salary);
Model eksekusi baris demi baris sekarang dapat menghasilkan hasil yang salah, atau bahkan masuk ke loop tak terbatas. Pertimbangkan rencana eksekusi iteratif (imajiner) yang mencari indeks Gaji, mengembalikan baris sekaligus ke Skalar Hitung, dan akhirnya ke operator Pembaruan:

Ada beberapa Skalar Komputasi tambahan dalam paket ini karena pengoptimalan yang melewatkan pemeliharaan indeks nonclustered jika nilai Gaji tidak berubah (hanya mungkin untuk gaji nol dalam kasus ini).
Mengabaikan itu, fitur penting dari rencana ini adalah bahwa kita sekarang memiliki pemindaian indeks parsial yang dipesan yang melewati baris pada satu waktu ke operator yang memodifikasi indeks yang sama (sorotan hijau pada grafik SQL Sentry Plan Explorer di atas memperjelas Clustered Operator Pembaruan Indeks memelihara tabel dasar dan indeks nonclustered).
Bagaimanapun, masalahnya adalah bahwa dengan memproses satu baris pada satu waktu, Pembaruan dapat memindahkan baris saat ini di depan posisi pemindaian yang digunakan oleh Pencarian Indeks untuk menemukan baris yang akan diubah. Bekerja melalui contoh akan membuat pernyataan itu sedikit lebih jelas:
Indeks nonclustered dikunci, dan diurutkan naik, pada nilai gaji. Indeks juga berisi penunjuk ke baris induk di tabel dasar (baik RID tumpukan atau kunci indeks berkerumun ditambah uniquifier jika perlu). Untuk membuat contoh lebih mudah diikuti, asumsikan tabel dasar sekarang memiliki indeks berkerumun unik pada kolom Nama, sehingga isi indeks yang tidak berkerumun pada awal pemrosesan pembaruan adalah:
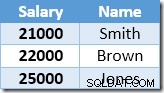
Baris pertama yang dikembalikan oleh Index Seek adalah gaji $21.000 untuk Smith. Nilai ini diperbarui menjadi $23.100 di tabel dasar dan indeks nonclustered oleh operator Clustered Index. Indeks nonclustered sekarang berisi:
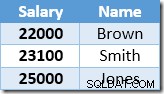
Baris berikutnya yang dikembalikan oleh Index Seek adalah entri $22.000 untuk Brown yang diperbarui menjadi $24.200:
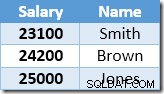
Sekarang Pencarian Indeks menemukan nilai $23.100 untuk Smith, yang diperbarui lagi , menjadi $25.410. Proses ini berlanjut hingga semua karyawan memiliki gaji minimal $25.000 – yang bukan merupakan hasil yang benar untuk UPDATE yang diberikan pertanyaan. Efek yang sama dalam keadaan lain dapat menyebabkan pembaruan yang tidak terkendali yang hanya berakhir ketika server kehabisan ruang log atau terjadi kesalahan luapan (dapat terjadi dalam kasus ini jika seseorang memiliki gaji nol). Ini adalah Masalah Halloween yang berlaku untuk pembaruan.
Menghindari Masalah Halloween untuk Pembaruan
Pembaca yang jeli akan memperhatikan bahwa perkiraan persentase biaya dalam rencana Index Seek imajiner tidak berjumlah 100%. Ini bukan masalah dengan Plan Explorer – Saya sengaja menghapus operator kunci dari paket:

Pengoptimal kueri mengenali bahwa rencana pembaruan yang disalurkan ini rentan terhadap Masalah Halloween, dan memperkenalkan Eager Table Spool untuk mencegahnya terjadi. Tidak ada tanda petunjuk atau jejak untuk mencegah penyertaan spool dalam rencana eksekusi ini karena diperlukan untuk kebenaran.
Seperti namanya, spool dengan bersemangat menghabiskan semua baris dari operator turunannya (Indeks Seek) sebelum mengembalikan baris ke induknya, Compute Scalar. Efeknya adalah untuk memperkenalkan pemisahan fase yang lengkap – semua baris yang memenuhi syarat dibaca dan disimpan ke penyimpanan sementara sebelum pembaruan dilakukan.
Ini membawa kita lebih dekat ke semantik logis tiga fase dari standar SQL, meskipun harap dicatat eksekusi rencana pada dasarnya masih berulang, dengan operator di sebelah kanan spool membentuk kursor baca , dan operator di sebelah kiri membentuk kursor tulis . Isi spool masih dibaca dan diproses baris demi baris (tidak diteruskan secara massal karena perbandingan dengan standar SQL mungkin membuat Anda percaya).
Kelemahan dari pemisahan fasa adalah sama seperti yang disebutkan sebelumnya. Tabel Spool mengkonsumsi tempdb space (halaman dalam buffer pool) dan mungkin memerlukan pembacaan dan penulisan fisik ke disk di bawah tekanan memori. Pengoptimal kueri menetapkan perkiraan biaya ke kumparan (tunduk pada semua peringatan biasa tentang perkiraan) dan akan memilih antara rencana yang memerlukan perlindungan terhadap Masalah Halloween versus yang tidak berdasarkan perkiraan biaya seperti biasa. Secara alami, pengoptimal mungkin salah memilih di antara opsi karena alasan normal apa pun.
Dalam hal ini, trade-off adalah antara peningkatan efisiensi dengan mencari langsung ke catatan kualifikasi (mereka yang memiliki gaji <$25.000) versus perkiraan biaya spool yang diperlukan untuk menghindari Masalah Halloween. Rencana alternatif (dalam kasus khusus ini) adalah pemindaian penuh indeks berkerumun (atau tumpukan). Strategi ini tidak memerlukan Perlindungan Halloween yang sama karena kunci indeks berkerumun tidak diubah:

Karena kunci indeks stabil, baris tidak dapat berpindah posisi dalam indeks di antara iterasi, menghindari Masalah Halloween dalam kasus ini. Bergantung pada biaya runtime dari Clustered Index Scan dibandingkan dengan kombinasi Index Seek plus Eager Table Spool yang terlihat sebelumnya, satu rencana dapat dijalankan lebih cepat daripada yang lain. Pertimbangan lain adalah bahwa paket dengan Perlindungan Halloween akan memperoleh lebih banyak kunci daripada paket yang sepenuhnya disalurkan, dan kunci akan ditahan lebih lama.
Pemikiran Terakhir
Memahami Masalah Halloween dan pengaruhnya terhadap rencana kueri modifikasi data akan membantu Anda menganalisis rencana eksekusi perubahan data, dan dapat menawarkan peluang untuk menghindari biaya dan efek samping perlindungan yang tidak perlu jika tersedia alternatif.
Ada beberapa bentuk Masalah Halloween, tidak semuanya disebabkan oleh membaca dan menulis pada kunci-kunci dari indeks umum. Masalah Halloween juga tidak terbatas pada UPDATE pertanyaan. Pengoptimal kueri memiliki lebih banyak trik untuk menghindari Masalah Halloween selain dari pemisahan fase paksa menggunakan Eager Table Spool. Poin-poin ini (dan lebih banyak lagi) akan dieksplorasi dalam angsuran berikutnya dari seri ini.
[ Bagian 1 | Bagian 2 | Bagian 3 | Bagian 4 ]