Secara umum, jenis Sortir terbaik adalah yang dihindari sepenuhnya. Dengan pengindeksan yang cermat dan terkadang beberapa penulisan kueri kreatif, kita sering kali dapat menghilangkan kebutuhan akan operator Sortir dari rencana eksekusi. Jika data yang akan diurutkan berukuran besar, menghindari pengurutan semacam ini dapat menghasilkan peningkatan kinerja yang sangat signifikan.
Jenis Pengurutan terbaik kedua adalah yang tidak dapat kita hindari, tetapi yang menyimpan jumlah memori yang sesuai, dan menggunakan semua atau sebagian besar untuk melakukan sesuatu yang berharga. Menjadi berharga dapat mengambil banyak bentuk. Terkadang, Sortir dapat membayar lebih dari itu sendiri dengan mengaktifkan operasi selanjutnya yang bekerja jauh lebih efisien pada input yang diurutkan. Di lain waktu, Sortir sangat diperlukan, dan kita hanya perlu membuatnya seefisien mungkin.
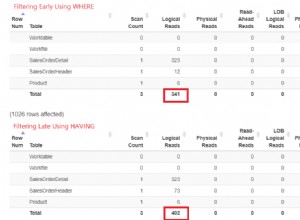
Kemudian muncul Jenis yang biasanya ingin kita hindari:yang menyimpan jauh lebih banyak memori daripada yang mereka butuhkan, dan yang menyimpan terlalu sedikit. Kasus terakhir adalah yang menjadi fokus kebanyakan orang. Dengan cadangan memori yang tidak mencukupi (atau tersedia) untuk menyelesaikan operasi penyortiran yang diperlukan dalam memori, operator Sort akan, dengan beberapa pengecualian, menumpahkan baris data ke tempdb . Pada kenyataannya, ini hampir selalu berarti menulis halaman pengurutan ke penyimpanan fisik (dan membacanya kembali nanti tentunya).
Di SQL Server versi modern, Sortir yang tumpah menghasilkan ikon peringatan dalam rencana pasca-eksekusi, yang mungkin mencakup detail tentang berapa banyak data yang tumpah, berapa banyak utas yang terlibat, dan tingkat tumpahan.
Latar Belakang:Tingkat Tumpahan
Pertimbangkan tugas menyortir 4000MB data, ketika kita hanya memiliki 500MB memori yang tersedia. Jelas, kami tidak dapat mengurutkan seluruh rangkaian dalam memori sekaligus, tetapi kami dapat memecah tugas:
Pertama-tama kita membaca data 500MB, mengurutkannya di memori, lalu menulis hasilnya ke disk. Melakukan ini sebanyak 8 kali menghabiskan seluruh input 4000MB, menghasilkan 8 set data yang diurutkan berukuran 500MB. Langkah kedua adalah melakukan penggabungan 8 arah dari kumpulan data yang diurutkan. Perhatikan bahwa penggabungan diperlukan, bukan rangkaian sederhana dari kumpulan karena data hanya dijamin untuk diurutkan sesuai kebutuhan dalam kumpulan 500MB tertentu pada tahap perantara.
Pada prinsipnya, kita dapat membaca dan menggabungkan satu baris pada satu waktu dari masing-masing dari delapan urutan, tetapi ini tidak akan terlalu efisien. Sebagai gantinya, kami membaca bagian pertama dari setiap jenis yang dijalankan kembali ke memori, katakanlah 60MB. Ini menghabiskan 8 x 60MB =480MB dari 500MB yang kami miliki. Kami kemudian dapat secara efisien melakukan penggabungan 8-arah dalam memori untuk sementara waktu, buffering hasil akhir yang diurutkan dengan memori 20MB yang masih tersedia. Saat setiap buffer memori run sort dikosongkan, kita membaca bagian baru run ke memori. Setelah semua sort berjalan digunakan, sortir selesai.
Ada beberapa detail tambahan dan pengoptimalan yang dapat kami sertakan, tetapi itu adalah garis besar dasar tumpahan Level 1, juga dikenal sebagai tumpahan satu arah. Satu pass ekstra pada data diperlukan untuk menghasilkan keluaran akhir yang diurutkan.
Sekarang, penggabungan n-cara secara teoritis dapat mengakomodasi jenis ukuran apa pun, dalam jumlah memori berapa pun, hanya dengan meningkatkan jumlah set menengah yang diurutkan secara lokal. Masalahnya adalah ketika 'n' meningkat, kita akhirnya membaca &menulis potongan data yang lebih kecil. Misalnya, menyortir 400GB data dalam 500MB memori akan berarti sesuatu seperti penggabungan 800 arah, dengan hanya sekitar 0,6MB dari setiap set menengah yang diurutkan dalam memori pada satu waktu (800 x 0,6MB =480MB, menyisakan ruang untuk penyangga keluaran).
Beberapa lintasan gabungan dapat digunakan untuk mengatasi ini. Ide umumnya adalah untuk secara progresif menggabungkan potongan kecil menjadi yang lebih besar, sampai kita dapat secara efisien menghasilkan aliran keluaran akhir yang diurutkan. Dalam contoh, ini mungkin berarti menggabungkan 40 dari 800 set yang diurutkan lewat pertama sekaligus, menghasilkan 20 potongan yang lebih besar, yang kemudian dapat digabungkan lagi untuk membentuk output. Dengan total dua lintasan ekstra pada data, ini akan menjadi tumpahan Level 2, dan seterusnya. Untungnya, peningkatan linier level tumpahan memungkinkan peningkatan eksponensial dalam ukuran sortir, sehingga level tumpahan sortir dalam jarang diperlukan.
Tumpahan "Level 15.000"
Pada titik ini, Anda mungkin bertanya-tanya apa kombinasi dari hibah memori kecil dan ukuran data yang sangat besar yang mungkin menghasilkan tumpahan sortir level 15.000. Mencoba menyortir seluruh Internet dalam memori 1MB? Mungkin, tapi itu terlalu sulit untuk didemonstrasikan. Sejujurnya, saya tidak tahu apakah tingkat tumpahan yang benar-benar tinggi bahkan mungkin terjadi di SQL Server. Tujuannya di sini (cheat, pasti) adalah untuk membuat SQL Server melaporkan tumpahan level 15.000.
Bahan utamanya adalah partisi. Sejak SQL Server 2012, kami telah diizinkan (nyaman) maksimum 15.000 partisi per objek (dukungan untuk 15.000 partisi juga tersedia pada 2008 SP2 dan 2008 R2 SP1, tetapi Anda harus mengaktifkannya secara manual per database, dan waspadai semua peringatan).
Hal pertama yang kita perlukan adalah fungsi partisi 15.000 elemen dan skema partisi terkait. Untuk menghindari blok kode inline yang sangat besar, skrip berikut menggunakan SQL dinamis untuk menghasilkan pernyataan yang diperlukan:
DECLARE
@sql nvarchar(max) =
N'
CREATE PARTITION FUNCTION PF (integer)
AS RANGE LEFT
FOR VALUES
(1';
DECLARE @i integer = 2;
WHILE @i < 15000
BEGIN
SET @sql += N',' + CONVERT(nvarchar(5), @i);
SET @i += 1;
END;
SET @sql = @sql + N');';
EXECUTE (@sql);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]); Skripnya cukup mudah untuk dimodifikasi ke angka yang lebih rendah jika pengaturan Anda bermasalah dengan 15.000 partisi (terutama dari sudut pandang memori, seperti yang akan kita lihat segera). Langkah selanjutnya adalah membuat tabel heap normal (tidak dipartisi) dengan satu kolom bilangan bulat, lalu mengisinya dengan bilangan bulat dari 1 hingga 15.000 inklusif:
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.Test1 (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; Itu harus selesai dalam 100 ms atau lebih. Jika Anda memiliki tabel angka yang tersedia, jangan ragu untuk menggunakannya untuk pengalaman yang lebih berbasis himpunan. Cara tabel dasar diisi tidak penting. Untuk mendapatkan tumpahan level 15.000, yang perlu kita lakukan sekarang adalah membuat indeks berkerumun yang dipartisi di atas tabel:
CREATE UNIQUE CLUSTERED INDEX CUQ ON dbo.Test1 (c1) WITH (MAXDOP = 1) ON PS (c1);
Waktu eksekusi sangat tergantung pada sistem penyimpanan yang digunakan. Di laptop saya, menggunakan SSD konsumen yang cukup umum dari beberapa tahun yang lalu, dibutuhkan sekitar 20 detik, yang cukup signifikan mengingat kami hanya berurusan dengan total 15.000 baris. Pada Azure VM dengan spesifikasi yang cukup rendah dengan kinerja I/O yang sangat buruk, pengujian yang sama membutuhkan waktu hampir 20 menit.
Analisis
Rencana eksekusi untuk pembangunan indeks adalah:
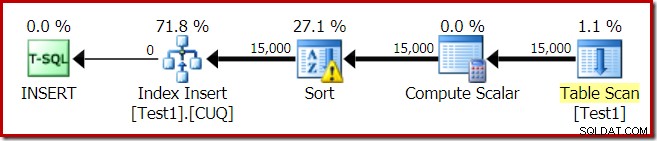
Pemindaian Tabel membaca 15.000 baris dari tabel tumpukan kami. Compute Scalar menghitung nomor partisi indeks tujuan untuk setiap baris menggunakan fungsi internal RangePartitionNew() . Sortir adalah bagian yang paling menarik dari rencana, jadi kita akan melihatnya lebih detail.
Pertama, Sortir Peringatan, seperti yang ditampilkan di Plan Explorer:

Peringatan serupa dari SSMS (diambil dari skrip yang berbeda):
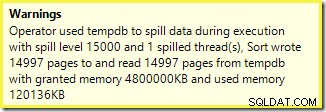
Hal pertama yang harus diperhatikan adalah laporan tingkat tumpahan 15.000 jenis, seperti yang dijanjikan. Ini tidak sepenuhnya akurat, tetapi detailnya cukup menarik. Sortir dalam paket ini memiliki Partition ID properti, yang biasanya tidak ada:
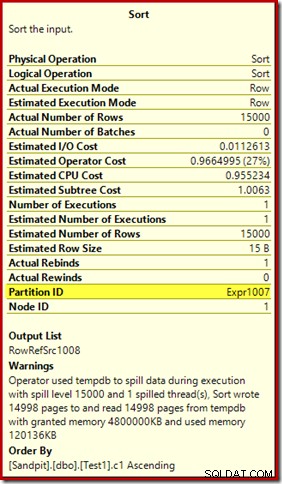
Properti ini disetel sama dengan definisi fungsi partisi internal di Compute Scalar.
Ini adalah bangunan indeks yang tidak selaras , karena sumber dan tujuan memiliki pengaturan partisi yang berbeda. Dalam hal ini, perbedaan itu muncul karena tabel tumpukan sumber tidak dipartisi, tetapi indeks tujuan. Akibatnya, 15.000 jenis terpisah dibuat saat runtime:satu per partisi target yang tidak kosong. Masing-masing jenis tumpahan ke level 1, dan SQL Server menjumlahkan semua tumpahan ini untuk memberikan tingkat tumpahan pengurutan akhir sebesar 15.000.
15.000 jenis terpisah menjelaskan hibah memori yang besar. Setiap instans pengurutan memiliki ukuran minimum 40 halaman, yaitu 40 x 8KB =320KB. Oleh karena itu, 15.000 jenis memerlukan minimal 15.000 x 320KB =4.800.000KB. Itu hanya sedikit dari 4,6GB RAM yang disediakan khusus untuk kueri yang mengurutkan 15.000 baris yang berisi satu kolom bilangan bulat. Dan setiap sortir tumpah ke disk, meskipun hanya menerima satu baris! Jika paralelisme digunakan untuk pembuatan indeks, pemberian memori dapat ditingkatkan lebih lanjut dengan jumlah utas. Perhatikan juga bahwa satu baris ditulis dalam sebuah halaman, yang menjelaskan jumlah halaman yang ditulis dan dibaca dari tempdb. Tampaknya ada kondisi balapan yang berarti jumlah halaman yang dilaporkan seringkali kurang dari 15.000.
Contoh ini mencerminkan kasus tepi, tentu saja, tetapi masih sulit untuk memahami mengapa setiap pengurutan menumpahkan satu barisnya alih-alih menyortir dalam memori yang telah diberikan. Mungkin ini dirancang untuk beberapa alasan, atau mungkin hanya bug. Apa pun masalahnya, masih cukup menghibur untuk melihat beberapa ratus KB data yang memakan waktu begitu lama dengan pemberian memori 4,6GB dan tumpahan level 15.000. Kecuali Anda menemukannya di lingkungan produksi, mungkin. Bagaimanapun, itu adalah sesuatu yang harus diperhatikan.
Laporan tumpahan tingkat 15.000 yang menyesatkan cukup banyak bermuara pada batasan representasi dalam keluaran rencana pertunjukan. Masalah mendasar adalah sesuatu yang muncul di banyak tempat di mana tindakan berulang terjadi, misalnya di bagian dalam loop bersarang bergabung. Tentu akan berguna untuk dapat melihat perincian yang lebih tepat daripada total keseluruhan dalam kasus ini. Seiring waktu, area ini sedikit meningkat, jadi kami sekarang memiliki lebih banyak informasi rencana per utas, atau per partisi untuk beberapa operasi. Perjalanan masih panjang.
Masih kurang membantu jika 15.000 tumpahan tingkat 1 yang terpisah dilaporkan di sini sebagai satu tumpahan tingkat 15.000.
Uji Variasi
Artikel ini lebih tentang menyoroti keterbatasan informasi rencana dan potensi kinerja yang buruk ketika jumlah partisi yang ekstrim digunakan, daripada tentang membuat operasi contoh tertentu lebih efisien, tetapi ada beberapa variasi menarik yang ingin saya lihat juga .
Online, Urutkan dalam tempdb
Melakukan operasi pembuatan indeks terpartisi yang sama dengan ONLINE = ON, SORT_IN_TEMPDB = ON tidak menderita hibah memori yang sama besar dan tumpah:
CREATE TABLE dbo.Test2
(
c1 integer NOT NULL
);
-- Copy the sample data
INSERT dbo.Test2 WITH (TABLOCKX)
(c1)
SELECT
T1.c1
FROM dbo.Test1 AS T1
OPTION (MAXDOP 1);
-- Partitioned clustered index build
CREATE CLUSTERED INDEX CUQ
ON dbo.Test2 (c1)
WITH (MAXDOP = 1, ONLINE = ON, SORT_IN_TEMPDB = ON)
ON PS (c1);
Perhatikan bahwa menggunakan ONLINE sendiri tidak cukup. Faktanya, itu menghasilkan rencana yang sama seperti sebelumnya dengan semua masalah yang sama, plus overhead tambahan untuk membangun setiap partisi indeks secara online. Bagi saya, itu menghasilkan waktu eksekusi lebih dari satu menit. Astaga tahu berapa lama waktu yang dibutuhkan untuk instance Azure spesifikasi rendah dengan kinerja I/O yang mengerikan.
Bagaimanapun, rencana eksekusi dengan ONLINE = ON, SORT_IN_TEMPDB = ON adalah:

Sortir dilakukan sebelum nomor partisi tujuan dihitung. Itu tidak memiliki properti ID Partisi, jadi itu hanya semacam biasa. Seluruh operasi berjalan selama sekitar sepuluh detik (masih ada banyak partisi yang harus dibuat). Ini cadangan kurang dari 3MB memori, dan menggunakan maksimal 816KB. Peningkatan yang cukup baik dibandingkan 4,6 GB dan 15.000 tumpahan.
Indeks dulu, lalu data
Hasil serupa dapat diperoleh dengan menulis data ke tabel heap terlebih dahulu:
-- Heap source
CREATE TABLE dbo.SourceData
(
c1 integer NOT NULL
);
-- Add data
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.SourceData (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; Selanjutnya, buat tabel clustered yang dipartisi kosong dan masukkan data dari heap:
-- Destination table
CREATE TABLE dbo.Test3
(
c1 integer NOT NULL
)
ON PS (c1); -- Optional
-- Partitioned Clustered Index
CREATE CLUSTERED INDEX CUQ
ON dbo.Test3 (c1)
ON PS (c1);
-- Add data
INSERT dbo.Test3 WITH (TABLOCKX)
(c1)
SELECT
SD.c1
FROM dbo.SourceData AS SD
OPTION (MAXDOP 1);
-- Clean up
DROP TABLE dbo.SourceData; Ini memakan waktu sekitar sepuluh detik, dengan hibah memori 2MB dan tidak tumpah:
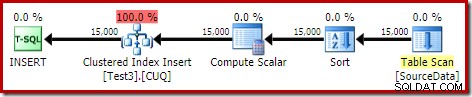
Tentu saja, pengurutan juga dapat dihindari sepenuhnya dengan mengindeks tabel sumber (tidak dipartisi), dan memasukkan data dalam urutan indeks (pengurutan terbaik tidak ada pengurutan sama sekali, ingat).
Heap yang dipartisi, lalu data, lalu indeks
Untuk variasi terakhir ini, pertama-tama kita membuat tumpukan yang dipartisi dan memuat 15.000 baris pengujian:
CREATE TABLE dbo.Test4
(
c1 integer NOT NULL
)
ON PS (c1);
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.Test4 (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; Skrip itu berjalan selama satu atau dua detik, yang cukup bagus. Langkah terakhir adalah membuat indeks berkerumun yang dipartisi:
CREATE CLUSTERED INDEX CUQ ON dbo.Test4 (c1) WITH (MAXDOP = 1) ON PS (c1);
Itu adalah bencana yang lengkap, baik dari sudut pandang kinerja, dan dari perspektif informasi rencana pertunjukan. Operasi itu sendiri berjalan kurang dari satu menit, dengan rencana eksekusi berikut:

Ini adalah rencana penyisipan colocated. Pemindaian Konstan berisi baris untuk setiap id partisi. Sisi dalam loop mencari partisi heap saat ini (ya, pencarian di heap). Sortir memiliki properti id partisi (meskipun ini konstan per iterasi loop) sehingga ada pengurutan per partisi dan perilaku tumpahan yang tidak diinginkan. Peringatan statistik pada tabel heap adalah palsu.
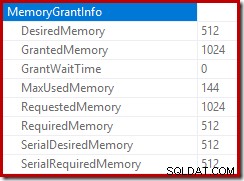
Akar dari rencana penyisipan menunjukkan bahwa hibah memori sebesar 1MB telah dicadangkan, dengan maksimum 144KB yang digunakan:
Operator sortir tidak melaporkan tumpahan level 15.000, tetapi sebaliknya membuat berantakan total matematika iterasi per-loop yang terlibat:

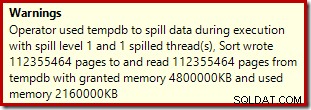
Memantau memori memberikan DMV selama eksekusi menunjukkan bahwa kueri ini sebenarnya hanya mencadangkan 1MB, dengan maksimum 144KB yang digunakan pada setiap iterasi perulangan. (Sebaliknya, penyimpanan memori 4,6 GB pada pengujian pertama benar-benar asli.) Hal ini tentu saja membingungkan.
Masalahnya (seperti yang disebutkan sebelumnya) adalah bahwa SQL Server menjadi bingung tentang cara terbaik untuk melaporkan apa yang terjadi pada banyak iterasi. Mungkin tidak praktis untuk memasukkan informasi kinerja rencana per partisi per iterasi, tetapi tidak ada salahnya untuk menghindari fakta bahwa pengaturan saat ini terkadang menghasilkan hasil yang membingungkan. Kami hanya dapat berharap bahwa suatu hari nanti dapat ditemukan cara yang lebih baik untuk melaporkan jenis informasi ini, dalam format yang lebih konsisten.