Berbeda dengan seri 'penyetelan performa spontan', saya ingin membahas bagaimana fragmentasi indeks dapat merayap pada Anda dalam beberapa keadaan.
Apa itu Fragmentasi Indeks?
Kebanyakan orang menganggap 'fragmentasi indeks' sebagai masalah di mana halaman daun indeks rusak – halaman daun indeks dengan nilai kunci berikutnya bukanlah yang secara fisik berdekatan dalam file data ke halaman daun indeks yang saat ini sedang diperiksa . Ini disebut fragmentasi logis (dan beberapa orang menyebutnya sebagai fragmentasi eksternal – istilah membingungkan yang tidak saya sukai).
Fragmentasi logis terjadi ketika halaman daun indeks penuh dan diperlukan ruang di atasnya, baik untuk penyisipan atau untuk membuat catatan yang ada lebih lama (dari memperbarui kolom dengan panjang variabel). Dalam hal ini, Storage Engine membuat halaman baru yang kosong dan memindahkan 50% baris (biasanya, tetapi tidak selalu) dari halaman penuh ke halaman baru. Operasi ini menciptakan ruang di kedua halaman, memungkinkan penyisipan atau pembaruan untuk melanjutkan, dan disebut pemisahan halaman. Ada kasus patologis menarik yang melibatkan pemisahan halaman berulang dari satu operasi dan pemisahan halaman yang meningkatkan level indeks, tetapi hal tersebut berada di luar cakupan postingan ini.
Ketika pemisahan halaman terjadi, biasanya menyebabkan fragmentasi logis karena halaman baru yang dialokasikan sangat tidak mungkin secara fisik berdekatan dengan halaman yang sedang dipisah. Ketika indeks memiliki banyak fragmentasi logis, pemindaian indeks melambat karena pembacaan fisik halaman yang diperlukan tidak dapat dilakukan secara efisien (menggunakan pembacaan 'readahead' multi-halaman) ketika halaman daun tidak disimpan secara berurutan dalam file data .
Itulah definisi dasar dari fragmentasi indeks, tetapi ada jenis kedua dari fragmentasi indeks yang kebanyakan orang tidak pertimbangkan:kepadatan halaman yang rendah (kadang-kadang disebut fragmentasi internal, sekali lagi, istilah membingungkan yang saya tidak suka).
Kepadatan halaman adalah ukuran seberapa banyak data yang disimpan pada halaman daun indeks. Ketika pemisahan halaman terjadi dengan kasus 50/50 biasa, setiap halaman daun (yang membelah dan yang baru) dibiarkan dengan kepadatan halaman hanya 50%. Semakin rendah kepadatan halaman, semakin banyak ruang kosong yang ada di indeks sehingga semakin banyak ruang disk dan memori buffer pool yang dapat Anda anggap terbuang sia-sia. Saya membuat blog tentang masalah ini beberapa tahun yang lalu dan Anda dapat membacanya di sini.
Sekarang setelah saya memberikan definisi dasar dari dua jenis fragmentasi indeks, saya akan merujuknya secara kolektif sebagai 'fragmentasi'.
Untuk sisa postingan ini, saya ingin membahas tiga kasus di mana indeks berkerumun dapat menjadi terfragmentasi bahkan jika Anda menghindari operasi yang jelas-jelas akan menyebabkan fragmentasi (yaitu penyisipan acak dan memperbarui catatan menjadi lebih lama).
Fragmentasi dari Penghapusan
“Bagaimana bisa penghapusan dari halaman daun indeks berkerumun menyebabkan pemisahan halaman?” Anda mungkin bertanya. Tidak akan, dalam keadaan normal (dan saya duduk memikirkannya selama beberapa menit untuk memastikan tidak ada kasus patologis yang aneh! Tapi lihat bagian di bawah…) Namun, penghapusan dapat menyebabkan kepadatan halaman semakin rendah.
Bayangkan kasus di mana indeks berkerumun memiliki nilai kunci identitas bigint, sehingga sisipan akan selalu berada di sisi kanan indeks dan tidak akan pernah, pernah dimasukkan ke dalam bagian indeks sebelumnya (kecuali seseorang menanam kembali nilai identitas – berpotensi sangat bermasalah!). Sekarang bayangkan bahwa beban kerja menghapus catatan dari tabel yang tidak lagi diperlukan, setelah itu tugas pembersihan hantu latar belakang akan merebut kembali ruang pada halaman dan itu akan menjadi ruang kosong.
Dengan tidak adanya penyisipan acak (tidak mungkin dalam skenario kami kecuali seseorang melakukan penyemaian ulang identitas atau menentukan nilai kunci untuk digunakan setelah mengaktifkan SET IDENTITY INSERT untuk tabel), tidak ada catatan baru yang akan menggunakan ruang yang dibebaskan dari catatan yang dihapus. Ini berarti bahwa kepadatan halaman rata-rata dari bagian sebelumnya dari indeks berkerumun akan terus menurun, yang mengarah ke peningkatan jumlah ruang disk yang terbuang dan memori buffer pool seperti yang saya jelaskan sebelumnya.
Penghapusan dapat menyebabkan fragmentasi, selama Anda menganggap kepadatan halaman sebagai bagian dari 'fragmentasi'.
Fragmentasi dari Isolasi Snapshot
SQL Server 2005 memperkenalkan dua tingkat isolasi baru:isolasi snapshot dan isolasi snapshot read-commited. Keduanya memiliki semantik yang sedikit berbeda, tetapi pada dasarnya memungkinkan kueri untuk melihat tampilan basis data secara tepat waktu, dan untuk pemilihan bebas-lock-collision. Itu penyederhanaan yang luas, tapi itu cukup untuk tujuan saya.
Untuk memfasilitasi tingkat isolasi ini, tim pengembangan di Microsoft yang saya pimpin menerapkan mekanisme yang disebut pembuatan versi. Cara kerja pembuatan versi adalah bahwa setiap kali catatan berubah, versi catatan sebelum diubah disalin ke penyimpanan versi di tempdb, dan rekaman yang diubah mendapat tag versi 14-byte yang ditambahkan di bagian akhir. Tag berisi penunjuk ke versi rekaman sebelumnya, ditambah stempel waktu yang dapat digunakan untuk menentukan versi rekaman yang benar untuk dibaca kueri tertentu. Sekali lagi, sangat disederhanakan, tetapi hanya penambahan 14 byte yang kami minati.
Jadi, setiap kali rekaman berubah saat salah satu dari tingkat isolasi ini berlaku, rekaman tersebut dapat diperluas sebesar 14 byte jika belum ada tag versi untuk rekaman tersebut. Bagaimana jika tidak ada cukup ruang untuk 14 byte tambahan pada halaman daun indeks? Benar, akan terjadi pemisahan halaman, menyebabkan fragmentasi.
Masalah besar, Anda mungkin berpikir, karena catatan tetap berubah, jadi jika ukurannya berubah, maka pemisahan halaman mungkin akan terjadi. Tidak – logika itu hanya berlaku jika perubahan record adalah untuk meningkatkan ukuran kolom dengan panjang variabel. Tag versi akan ditambahkan meskipun kolom dengan panjang tetap diperbarui!
Itu benar – saat pembuatan versi sedang dimainkan, pembaruan pada kolom dengan panjang tetap dapat menyebabkan rekaman meluas, berpotensi menyebabkan pemisahan dan fragmentasi halaman. Yang lebih menarik adalah bahwa penghapusan juga akan menambahkan tag 14-byte, sehingga penghapusan dalam indeks berkerumun dapat menyebabkan pemisahan halaman saat versi sedang digunakan!
Intinya di sini adalah bahwa mengaktifkan salah satu bentuk isolasi snapshot dapat menyebabkan fragmentasi tiba-tiba mulai terjadi di indeks berkerumun di mana sebelumnya tidak ada kemungkinan fragmentasi.
Fragmentasi dari Sekunder yang Dapat Dibaca
Kasus terakhir yang ingin saya diskusikan adalah menggunakan sekunder yang dapat dibaca, bagian dari fitur grup ketersediaan yang ditambahkan di SQL Server 2012.
Saat Anda mengaktifkan sekunder yang dapat dibaca, semua kueri yang Anda lakukan terhadap replika sekunder dikonversi menjadi menggunakan isolasi snapshot di bawah selimut. Ini mencegah kueri memblokir pemutaran ulang rekaman log secara konstan dari replika utama, karena kode pemulihan memperoleh kunci seiring berjalannya waktu.
Untuk melakukan ini, perlu ada tag versi 14-byte pada catatan di replika sekunder. Ada masalah, karena semua replika harus identik, agar pemutaran ulang log berfungsi. Yah, tidak cukup. Konten tag versi tidak relevan karena hanya digunakan pada instance yang membuatnya. Tetapi replika sekunder tidak dapat menambahkan tag versi, membuat catatan lebih lama, karena itu akan mengubah tata letak fisik catatan pada halaman dan menghentikan pemutaran ulang log. Jika tag versi sudah ada, itu bisa menggunakan ruang tanpa merusak apa pun.
Jadi itulah yang terjadi. Storage Engine memastikan bahwa semua tag pembuatan versi yang diperlukan untuk replika sekunder sudah ada, dengan menambahkannya di replika utama!
Segera setelah replika sekunder yang dapat dibaca dari database dibuat, pembaruan apa pun ke catatan di replika utama menyebabkan catatan memiliki tag 14-byte kosong yang ditambahkan, sehingga 14-byte diperhitungkan dengan benar di semua catatan log . Tag tidak digunakan untuk apa pun (kecuali isolasi snapshot diaktifkan pada replika utama itu sendiri), tetapi fakta bahwa tag itu dibuat menyebabkan catatan meluas, dan jika halaman sudah penuh maka...
Ya, mengaktifkan sekunder yang dapat dibaca menyebabkan efek yang sama pada replika utama seperti jika Anda mengaktifkan isolasi snapshot di dalamnya – fragmentasi.
Ringkasan
Jangan berpikir bahwa karena Anda menghindari menggunakan GUID sebagai kunci cluster dan menghindari memperbarui kolom panjang variabel di tabel Anda, maka indeks berkerumun Anda akan kebal terhadap fragmentasi. Seperti yang telah saya jelaskan di atas, ada beban kerja dan faktor lingkungan lain yang dapat menyebabkan masalah fragmentasi dalam indeks berkerumun yang perlu Anda waspadai.
Sekarang jangan spontan dan berpikir bahwa Anda tidak boleh menghapus catatan, tidak boleh menggunakan isolasi snapshot, dan tidak boleh menggunakan sekunder yang dapat dibaca. Anda hanya perlu menyadari bahwa semua itu dapat menyebabkan fragmentasi dan mengetahui cara mendeteksi, menghapus, dan menguranginya.
SQL Sentry memiliki alat yang keren, Fragmentation Manager, yang dapat Anda gunakan sebagai add-on untuk Performance Advisor untuk membantu mencari tahu di mana masalah fragmentasi dan kemudian mengatasinya. Anda mungkin terkejut dengan fragmentasi yang Anda temukan saat memeriksa! Sebagai contoh cepat, di sini saya dapat melihat secara visual – hingga ke tingkat partisi individu – seberapa banyak fragmentasi yang ada, seberapa cepat hal itu terjadi, pola apa pun yang ada, dan dampak aktualnya terhadap memori yang terbuang dalam sistem:
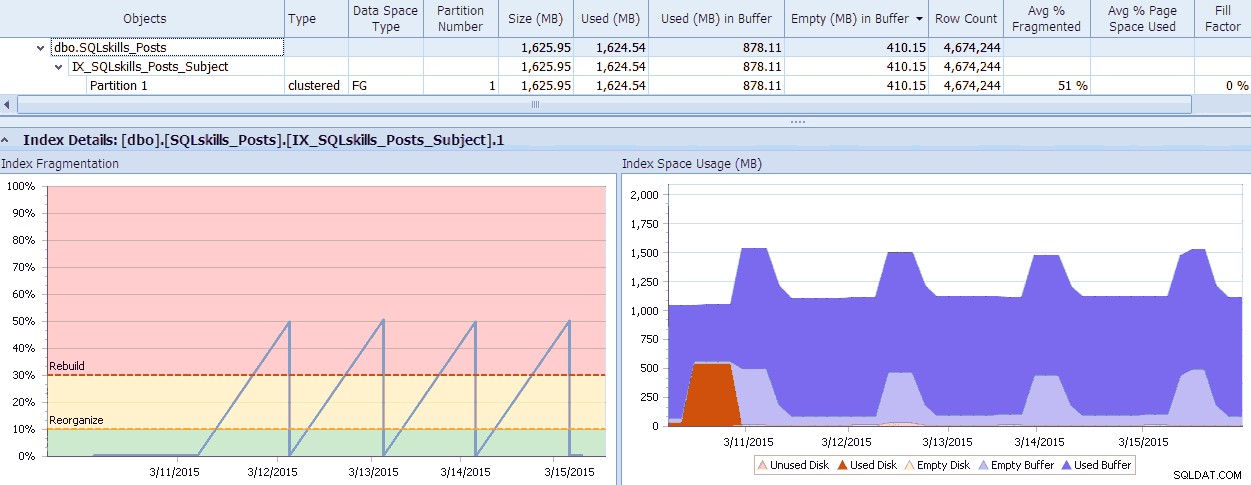 Data SQL Sentry Fragmentation Manager (klik untuk memperbesar)
Data SQL Sentry Fragmentation Manager (klik untuk memperbesar)
Di postingan saya berikutnya, saya akan membahas lebih lanjut tentang fragmentasi dan cara memitigasinya agar tidak terlalu bermasalah.