Seorang pengembang Oracle yang sering menggunakan ekspresi reguler dalam kode cepat atau lambat dapat menghadapi fenomena yang memang mistis. Pencarian jangka panjang untuk akar masalah dapat menyebabkan penurunan berat badan, nafsu makan, dan memicu berbagai jenis gangguan psikosomatik - semua ini dapat dicegah dengan bantuan fungsi regexp_replace. Ini dapat memiliki hingga 6 argumen:
REGEXP_REPLACE (
- string_sumber,
- templat,
- pengganti_string,
- posisi awal pencarian kecocokan dengan template (default 1),
- posisi kemunculan template dalam string sumber (secara default 0 sama dengan semua kemunculan),
- pengubah (sejauh ini adalah kuda hitam)
)
Mengembalikan source_string yang dimodifikasi di mana semua kemunculan template diganti dengan nilai yang diteruskan dalam parameter substituting_string. Seringkali versi singkat dari fungsi digunakan, di mana 3 argumen pertama ditentukan, yang cukup untuk menyelesaikan banyak masalah. Aku akan melakukan hal yang sama. Misalkan kita perlu menutupi semua karakter string dengan tanda bintang di string 'MASK:huruf kecil'. Untuk menentukan rentang karakter huruf kecil, pola ‘[a-z]‘ harus sesuai.
select regexp_replace('MASK: lower case', '[a-z]', '*') as result from dual Harapan
+------------------+ | RESULT | +------------------+ | MASK: ***** **** | +------------------+
Kenyataan
+------------------+ | RESULT | +------------------+ | *A**: ***** **** | +------------------+
Jika acara ini belum direproduksi di database Anda, maka Anda beruntung sejauh ini. Tetapi lebih sering Anda mulai menggali kode, mengubah string dari satu set karakter ke karakter lainnya dan akhirnya, keputusasaan datang.
Mendefinisikan masalah
Pertanyaan muncul – apa yang istimewa dari huruf 'A' sehingga tidak diganti karena karakter huruf besar lainnya tidak seharusnya diganti juga. Mungkin ada huruf lain yang benar kecuali yang ini. Penting untuk melihat seluruh alfabet karakter huruf besar.
select regexp_replace('ABCDEFJHIGKLMNOPQRSTUVWXYZ', '[a-z]', '*') as alphabet from dual
+----------------------------+
| ALPHABET |
+----------------------------+
| A************************* |
+----------------------------+ Namun
Jika argumen ke-6 fungsi tidak ditentukan secara eksplisit, misalnya, 'i' adalah case-insensitivity atau 'c' case-sensitivity ketika membandingkan string sumber dengan template, ekspresi reguler menggunakan parameter NLS_SORT sesi/database secara default. Misalnya:
select value from sys.nls_session_parameters where parameter = 'NLS_SORT' +---------+ | VALUE | +---------+ | ENGLISH | +---------+
Parameter ini menentukan metode pengurutan dalam ORDER BY. Jika kita berbicara tentang pengurutan karakter individu sederhana, maka angka biner tertentu (kode NLSSORT) sesuai dengan masing-masing karakter dan pengurutan sebenarnya terjadi berdasarkan nilai angka-angka ini.
Untuk mengilustrasikannya, mari kita ambil beberapa karakter pertama dan terakhir dari alfabet, baik huruf kecil, maupun huruf besar, dan tempatkan mereka dalam kumpulan tabel yang tidak berurutan dan beri nama ABC. Kemudian, mari urutkan kumpulan ini berdasarkan bidang SYMBOL dan tampilkan kode NLSSORT-nya dalam format HEX di sebelah setiap simbol.
with ABC as (
select column_value as symbol
from table(sys.odcivarchar2list('A','B','C','X','Y','Z','a','b','c','x','y','z'))
)
select symbol,
nlssort(symbol) nls_code_hex
from ABC
order by symbol
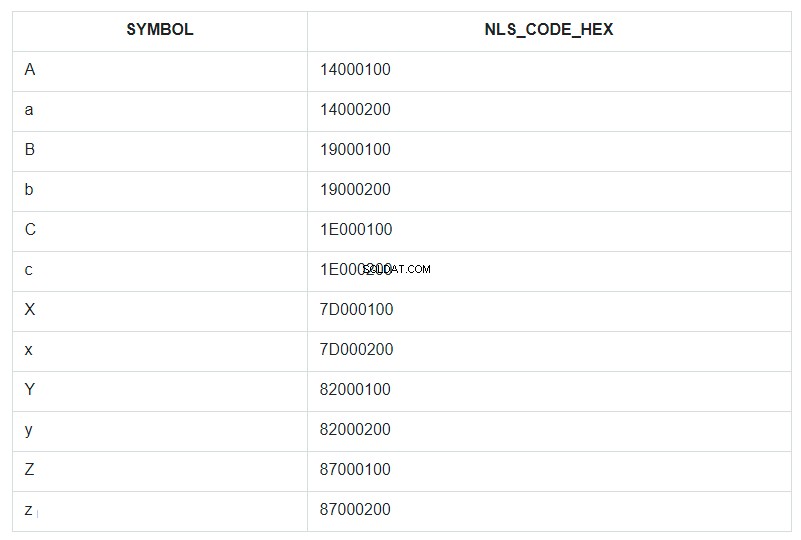
Dalam kueri, ORDER BY ditentukan untuk bidang SYMBOL, tetapi kenyataannya, dalam database, pengurutan dilakukan berdasarkan nilai dari bidang NLS_CODE_HEX.
Sekarang, kembali ke rentang dari template dan lihat tabel – apa vertikal antara simbol 'a' (kode 14000200) dan 'z' (kode 87000200)? Semuanya kecuali huruf kapital 'A'. Itu saja yang telah diganti dengan tanda bintang. Dan kode 14000100 huruf 'A' tidak termasuk dalam penggantian range 14000200 sampai 87000200.
Obat
Tentukan pengubah sensitivitas huruf besar-kecil secara eksplisit
select regexp_replace('MASK: lower case', '[a-z]', '*', 1, 0, 'c') from dual
+------------------+
| RESULT |
+------------------+
| MASK: ***** **** |
+------------------+
Beberapa sumber mengatakan bahwa pengubah 'c' disetel secara default, tetapi kami baru saja melihat bahwa ini tidak sepenuhnya benar. Dan jika seseorang tidak melihatnya, maka parameter NLS_SORT dari sesi/basis datanya kemungkinan besar diatur ke BINARY dan penyortiran dilakukan sesuai dengan kode karakter yang sebenarnya. Memang, jika Anda mengubah parameter sesi, masalahnya akan terpecahkan.
ALTER SESSION SET NLS_SORT=BINARY;
select regexp_replace('MASK: lower case', '[a-z]', '*') as result from dual
+------------------+
| RESULT |
+------------------+
| MASK: ***** **** |
+------------------+ Pengujian dilakukan di Oracle 12c.
Jangan ragu untuk meninggalkan komentar Anda dan berhati-hatilah.