Catatan:Posting ini awalnya diterbitkan hanya di eBook kami, High Performance Techniques for SQL Server, Volume 2. Anda dapat mengetahui tentang eBook kami di sini.
Ringkasan:Artikel ini membahas beberapa perilaku mengejutkan BUKAN pemicu dan mengungkapkan bug estimasi kardinalitas serius di SQL Server 2014.
Pemicu dan Pembuatan Versi Baris
Hanya pemicu DML SETELAH yang menggunakan versi baris (dalam SQL Server 2005 dan seterusnya) untuk menyediakan disisipkan dan dihapus pseudo-tabel di dalam prosedur pemicu. Poin ini tidak dibuat dengan jelas di banyak dokumentasi resmi. Di sebagian besar tempat, dokumentasi hanya mengatakan bahwa versi baris digunakan untuk membangun disisipkan dan dihapus tabel dalam pemicu tanpa kualifikasi (contoh di bawah):
Penggunaan Sumber Daya Versi Baris
Memahami Tingkat Isolasi Berbasis Versi Baris
Mengontrol Eksekusi Pemicu Saat Mengimpor Data Secara Massal
Agaknya, versi asli dari entri ini ditulis sebelum BUKAN pemicu ditambahkan ke produk, dan tidak pernah diperbarui. Entah itu, atau itu adalah kesalahan sederhana (tetapi berulang).
Bagaimanapun, cara kerja versi baris dengan pemicu SETELAH cukup intuitif. Pemicu ini menyala setelah modifikasi yang dimaksud telah dilakukan, jadi mudah untuk melihat bagaimana mempertahankan versi dari baris yang dimodifikasi memungkinkan mesin database menyediakan disisipkan dan dihapus pseudo-tabel. dihapus pseudo-tabel dibangun dari versi baris yang terpengaruh sebelum modifikasi dilakukan; yang dimasukkan pseudo-tabel dibentuk dari versi baris yang terpengaruh seperti pada saat prosedur pemicu dimulai.
Alih-alih Pemicu
BUKAN pemicu berbeda karena jenis pemicu DML ini menggantikan tindakan yang dipicu. dimasukkan dan dihapus pseudo-tabel sekarang mewakili perubahan yang akan telah dibuat, apakah pernyataan pemicu benar-benar dieksekusi. Pembuatan versi baris tidak dapat digunakan untuk pemicu ini karena tidak ada modifikasi yang terjadi, menurut definisi. Jadi, jika tidak menggunakan versi baris, bagaimana SQL Server melakukannya?
Jawabannya adalah SQL Server memodifikasi rencana eksekusi untuk memicu pernyataan DML ketika ada pemicu BUKAN. Daripada memodifikasi tabel yang terpengaruh secara langsung, rencana eksekusi menulis informasi tentang perubahan ke meja kerja yang tersembunyi. Meja kerja ini berisi semua data yang diperlukan untuk melakukan perubahan asli, jenis modifikasi yang akan dilakukan pada setiap baris (menghapus atau menyisipkan), serta informasi apa pun yang diperlukan dalam pemicu untuk klausa OUTPUT.
Rencana eksekusi tanpa pemicu
Untuk melihat semua ini beraksi, pertama-tama kita akan menjalankan tes sederhana tanpa kehadiran pemicu BUKAN:
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
INSERT dbo.Test
(RowID, Data)
VALUES
(1, 100),
(2, 200),
(3, 300);
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; Rencana eksekusi untuk penghapusan sangat mudah:
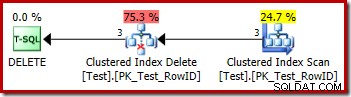
Setiap baris yang memenuhi syarat diteruskan langsung ke operator Penghapusan Indeks Cluster, yang menghapusnya. Mudah.
Rencana eksekusi dengan BUKAN pemicu
Sekarang mari kita ubah pengujian untuk menyertakan pemicu INSTEAD OF DELETE (pemicu yang hanya melakukan tindakan penghapusan yang sama untuk kesederhanaan):
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
INSERT dbo.Test
(RowID, Data)
VALUES
(1, 100),
(2, 200),
(3, 300);
GO
CREATE TRIGGER dbo_Test_IOD
ON dbo.Test
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
DELETE FROM dbo.Test
WHERE EXISTS
(
SELECT * FROM Deleted
WHERE Deleted.RowID = dbo.Test.RowID
);
END;
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; Rencana eksekusi untuk DELETE sekarang sangat berbeda:
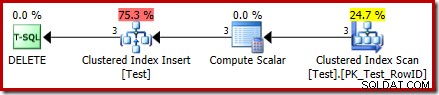
Operator Penghapusan Indeks Tergugus telah digantikan oleh Indeks Tergugus Sisipkan . Ini adalah sisipan ke meja kerja tersembunyi, yang diganti namanya (dalam representasi rencana eksekusi publik) menjadi nama tabel dasar yang terpengaruh oleh penghapusan. Penggantian nama terjadi ketika rencana tampilan XML dihasilkan dari representasi rencana eksekusi internal, jadi tidak ada cara terdokumentasi untuk melihat meja kerja yang tersembunyi.
Sebagai akibat dari perubahan ini, rencana tersebut tampaknya melakukan penyisipan ke tabel dasar untuk menghapus baris dari itu. Ini membingungkan, tetapi setidaknya mengungkapkan keberadaan pemicu BUKAN. Mengganti operator Sisipkan dengan Hapus mungkin akan lebih membingungkan. Mungkin yang ideal adalah ikon grafis baru untuk meja kerja BUKAN pemicu? Bagaimanapun, itu adalah apa adanya.
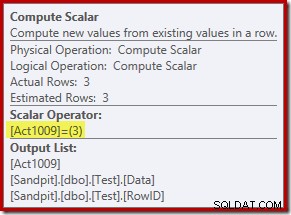
Operator Compute Scalar yang baru mendefinisikan jenis tindakan yang dilakukan pada setiap baris. Kode tindakan ini adalah bilangan bulat, dengan arti sebagai berikut:
- 3 =HAPUS
- 4 =MASUKKAN
- 259 =HAPUS dalam paket MERGE
- 260 =INSERT dalam paket MERGE
Untuk kueri ini, tindakannya adalah konstanta 3, artinya setiap baris harus dihapus :
Perbarui Tindakan
Selain itu, rencana eksekusi BUKAN PEMBARUAN menggantikan operator Pembaruan tunggal dengan dua Indeks Berkelompok Menyisipkan ke meja kerja tersembunyi yang sama – satu untuk disisipkan baris pseudo-tabel, dan satu untuk dihapus baris pseudo-tabel. Contoh rencana eksekusi:

MERGE yang melakukan UPDATE juga menghasilkan rencana eksekusi dengan dua sisipan ke tabel dasar yang sama untuk alasan yang sama:

Rencana Eksekusi Pemicu
Rencana eksekusi untuk badan pemicu juga memiliki beberapa fitur menarik:
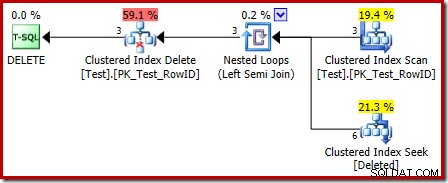
Hal pertama yang harus diperhatikan adalah bahwa ikon grafis yang digunakan untuk tabel yang dihapus tidak sama dengan ikon yang digunakan dalam rencana pemicu SETELAH:
Representasi dalam rencana pemicu BUKAN adalah Clustered Index Seek. Objek yang mendasarinya adalah meja kerja internal yang sama yang kita lihat sebelumnya, meskipun di sini diberi nama dihapus alih-alih diberi nama tabel dasar, mungkin untuk semacam konsistensi dengan pemicu AFTER.
Operasi pencarian pada dihapus tabel mungkin tidak seperti yang Anda harapkan (jika Anda mengharapkan pencarian di RowID):
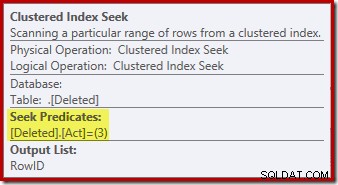
'Pencarian' ini mengembalikan semua baris dari meja kerja yang memiliki kode tindakan 3 (hapus), membuatnya persis sama dengan Pemindaian yang Dihapus operator terlihat di rencana pemicu SETELAH. Meja kerja internal yang sama digunakan untuk menampung baris untuk keduanya disisipkan dan dihapus pseudo-tabel di BUKAN pemicu. Setara dengan Pemindaian yang Disisipkan adalah pencarian kode tindakan 4 (yang dimungkinkan dalam hapus pemicu, tetapi hasilnya akan selalu kosong). Tidak ada indeks pada meja kerja internal selain dari indeks berkerumun non-unik pada tindakan kolom saja. Selain itu, tidak ada statistik yang terkait dengan indeks internal ini.
Analisis sejauh ini mungkin membuat Anda bertanya-tanya di mana penggabungan antara kolom RowID dilakukan. Perbandingan ini terjadi pada operator Nested Loops Left Semi Join sebagai predikat residual:
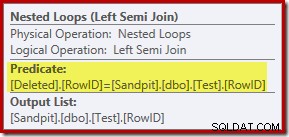
Sekarang kita tahu 'mencari' secara efektif adalah pemindaian penuh dari dihapus tabel, rencana eksekusi yang dipilih oleh pengoptimal kueri tampaknya cukup tidak efisien. Alur keseluruhan dari rencana eksekusi adalah bahwa setiap baris dari tabel Uji berpotensi dibandingkan dengan seluruh rangkaian dihapus baris, yang terdengar sangat mirip dengan produk kartesius.
Anugrahnya adalah bahwa gabungan adalah semigabung, yang berarti proses perbandingan berhenti untuk baris Tes yang diberikan segera setelah dihapus pertama. baris memenuhi predikat residual. Namun demikian, strateginya tampaknya aneh. Mungkin rencana eksekusi akan lebih baik jika tabel Test berisi lebih banyak baris?
Tes pemicu dengan 1.000 baris
Skrip berikut dapat digunakan untuk menguji pemicu dengan jumlah baris yang lebih banyak. Kita akan mulai dengan 1.000:
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
SET STATISTICS XML OFF;
SET NOCOUNT ON;
GO
DECLARE @i integer = 1;
WHILE @i <= 1000
BEGIN
INSERT dbo.Test (RowID, Data)
VALUES (@i, @i * 100);
SET @i += 1;
END;
GO
CREATE TRIGGER dbo_Test_IOD
ON dbo.Test
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
DELETE FROM dbo.Test
WHERE EXISTS
(
SELECT * FROM Deleted
WHERE Deleted.RowID = dbo.Test.RowID
);
END;
GO
SET STATISTICS XML ON;
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; Rencana eksekusi untuk badan pemicu sekarang:
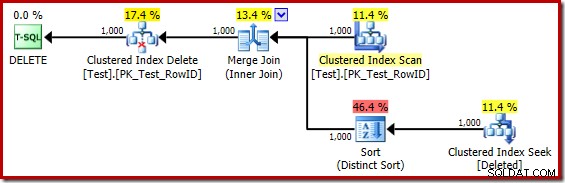
Secara mental mengganti Pencarian Indeks Clustered (menyesatkan) dengan Pemindaian yang Dihapus, rencananya secara umum terlihat cukup bagus. Pengoptimal telah memilih Gabung Gabung satu-ke-banyak alih-alih Gabung Semi Loop Bersarang, yang tampaknya masuk akal. The Distinct Sort adalah tambahan yang aneh:
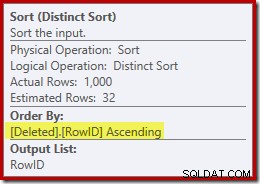
Jenis ini melakukan dua fungsi. Pertama, menyediakan gabungan gabungan dengan input yang diurutkan yang dibutuhkannya, yang cukup adil karena tidak ada indeks pada meja kerja internal untuk memberikan urutan yang diperlukan. Hal kedua yang dilakukan pengurutan adalah membedakan pada RowID. Ini mungkin tampak aneh, karena RowID adalah kunci utama dari tabel dasar.
Masalahnya adalah bahwa baris di dihapus tabel hanyalah baris kandidat yang diidentifikasi oleh kueri DELETE asli. Tidak seperti pemicu AFTER, baris ini belum diperiksa untuk batasan atau pelanggaran kunci, sehingga pemroses kueri tidak menjamin bahwa baris ini sebenarnya unik.
Secara umum, ini adalah poin yang sangat penting untuk diingat dengan BUKAN pemicu:tidak ada jaminan bahwa baris yang disediakan memenuhi salah satu batasan pada tabel dasar (termasuk NOT NULL). Ini tidak hanya penting untuk diingat oleh penulis pemicu; itu juga membatasi penyederhanaan dan transformasi yang dapat dilakukan oleh pengoptimal kueri.
Masalah kedua yang ditampilkan di properti Sortir di atas, tetapi tidak disorot, adalah bahwa perkiraan keluaran hanya 32 baris. Meja kerja internal tidak memiliki statistik yang terkait dengannya, jadi pengoptimal menebak pada efek operasi Distinct. Kami 'tahu' bahwa nilai RowID unik, tetapi tanpa informasi yang sulit untuk dilanjutkan, pengoptimal membuat tebakan yang buruk. Masalah ini akan kembali menghantui kita di ujian selanjutnya.
Tes pemicu dengan 5.000 baris
Sekarang ubah skrip pengujian untuk menghasilkan 5.000 baris:
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
SET STATISTICS XML OFF;
SET NOCOUNT ON;
GO
DECLARE @i integer = 1;
WHILE @i <= 5000
BEGIN
INSERT dbo.Test (RowID, Data)
VALUES (@i, @i * 100);
SET @i += 1;
END;
GO
CREATE TRIGGER dbo_Test_IOD
ON dbo.Test
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
DELETE FROM dbo.Test
WHERE EXISTS
(
SELECT * FROM Deleted
WHERE Deleted.RowID = dbo.Test.RowID
);
END;
GO
SET STATISTICS XML ON;
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; Rencana eksekusi pemicu adalah:
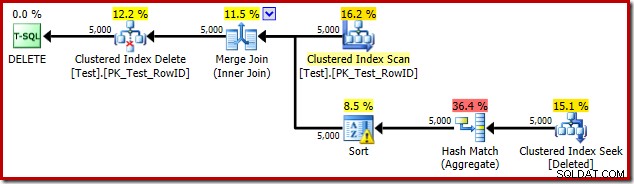
Kali ini pengoptimal telah memutuskan untuk membagi operasi yang berbeda dan mengurutkan. Pembedaan pada RowID dilakukan oleh operator Hash Match (Aggregate):
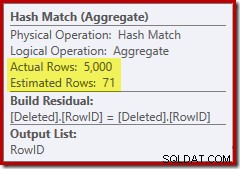
Perhatikan perkiraan pengoptimal untuk output adalah 71 baris. Faktanya, 5.000 baris bertahan dari perbedaan karena RowID unik. Perkiraan yang tidak akurat berarti bahwa fraksi yang tidak memadai dari pemberian memori kueri dialokasikan ke Sort, yang akhirnya tumpah ke tempdb :
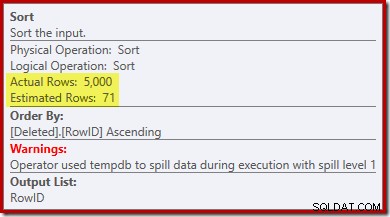
Tes ini harus dilakukan pada SQL Server 2012 atau lebih tinggi untuk melihat peringatan pengurutan dalam rencana eksekusi. Di versi sebelumnya, paket tidak berisi informasi tentang tumpahan – jejak Profiler pada acara Peringatan Urutkan akan diperlukan untuk mengungkapkannya (dan Anda perlu menghubungkannya kembali ke kueri sumber).
Tes pemicu dengan 5.000 baris di SQL Server 2014
Jika pengujian sebelumnya diulang pada SQL Server 2014, dalam database yang disetel ke tingkat kompatibilitas 120 sehingga penaksir kardinalitas (CE) baru digunakan, rencana eksekusi pemicu berbeda lagi:
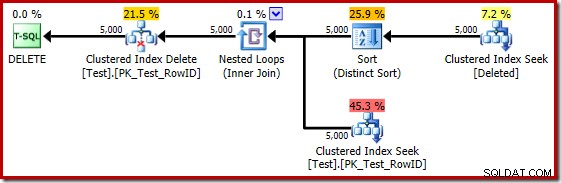
Dalam beberapa hal, rencana eksekusi ini tampak seperti perbaikan. Pengurutan Berbeda (tidak perlu) masih ada, tetapi strategi keseluruhan tampaknya lebih alami:untuk setiap kandidat RowID yang berbeda di dihapus tabel, gabungkan ke tabel dasar (sehingga verifikasi bahwa baris kandidat benar-benar ada) lalu hapus.
Sayangnya, paket 2014 didasarkan pada perkiraan kardinalitas yang lebih buruk daripada yang kami lihat di SQL Server 2012. Mengalihkan SQL Sentry Plan Explorer untuk menampilkan perkiraan jumlah baris menunjukkan masalah dengan jelas:
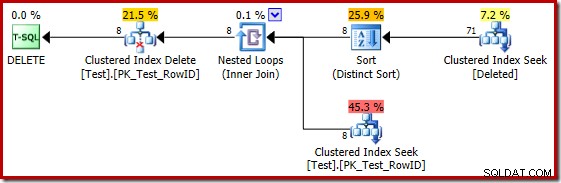
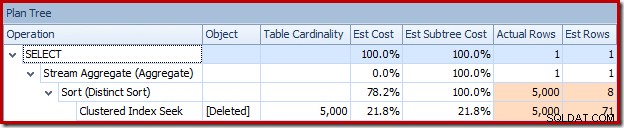
Pengoptimal memilih strategi Nested Loops untuk penggabungan karena mengharapkan jumlah baris yang sangat kecil pada input teratasnya. Masalah pertama terjadi di Clustered Index Seek. Pengoptimal mengetahui bahwa tabel yang dihapus berisi 5.000 baris pada saat ini, seperti yang dapat kita lihat dengan beralih ke tampilan Plan Tree dan menambahkan kolom Kardinalitas Tabel opsional (yang saya harap disertakan secara default):
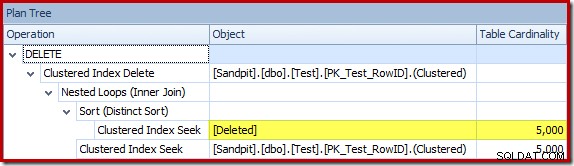
Penaksir kardinalitas 'lama' di SQL Server 2012 dan sebelumnya cukup pintar untuk mengetahui bahwa 'mencari' di meja kerja internal akan mengembalikan semua 5.000 baris (sehingga memilih gabungan gabungan). CE baru tidak begitu pintar. Ia melihat meja kerja sebagai 'kotak hitam' dan menebak efek dari kode tindakan pencarian =3:
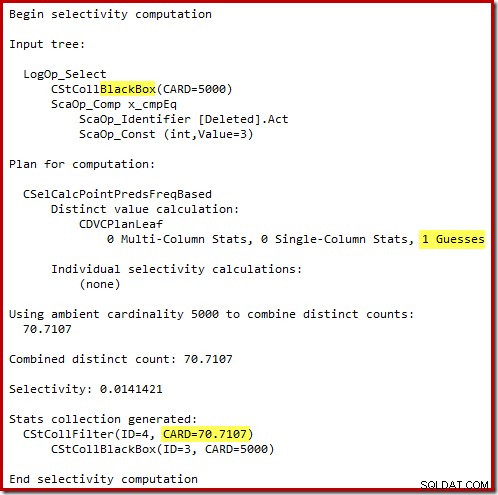
Tebakan 71 baris (dibulatkan ke atas) adalah hasil yang cukup menyedihkan, tetapi kesalahan bertambah ketika CE baru memperkirakan baris untuk operasi berbeda pada 71 baris tersebut:
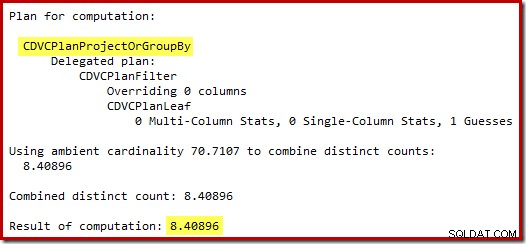
Berdasarkan 8 baris yang diharapkan, pengoptimal memilih strategi Nested Loops. Cara lain untuk melihat kesalahan estimasi ini adalah dengan menambahkan pernyataan berikut ke badan pemicu (hanya untuk tujuan pengujian):
SELECT COUNT_BIG(DISTINCT RowID) FROM Deleted;
Rencana estimasi menunjukkan kesalahan estimasi dengan jelas:
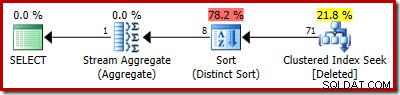
Paket sebenarnya masih menunjukkan 5.000 baris saja:
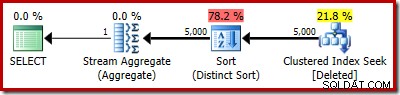
Atau Anda dapat membandingkan estimasi versus aktual pada saat yang sama dalam tampilan Plan Tree:
Satu juta baris…
Perkiraan tebakan yang buruk saat menggunakan penaksir kardinalitas 2014 menyebabkan pengoptimal memilih strategi Nested Loops bahkan ketika tabel Uji berisi satu juta baris. CE baru 2014 perkiraan rencana untuk tes itu adalah:
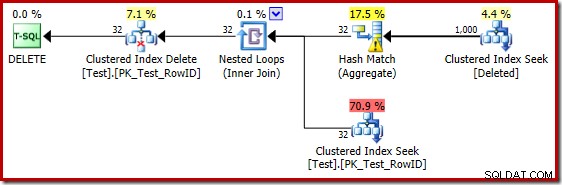
'Pencarian' memperkirakan 1.000 baris dari kardinalitas 1.000.000 yang diketahui dan perkiraan yang berbeda adalah 32 baris. Rencana pasca-eksekusi mengungkapkan efek pada memori yang dicadangkan untuk Hash Match:
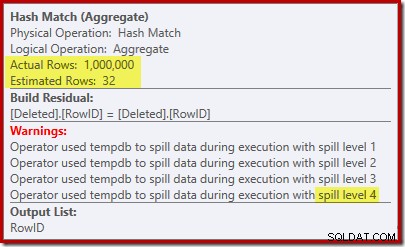
Mengharapkan hanya 32 baris, Hash Match mendapat masalah nyata, secara rekursif menumpahkan tabel hashnya sebelum akhirnya selesai.
Pemikiran Akhir
Meskipun benar bahwa pemicu tidak boleh ditulis untuk melakukan sesuatu yang dapat dicapai dengan integritas referensial deklaratif, juga benar bahwa ditulis dengan baik pemicu yang menggunakan efisien rencana eksekusi dapat sebanding dalam kinerja dengan biaya pemeliharaan indeks nonclustered ekstra.
Ada dua masalah praktis dengan pernyataan di atas. Pertama (dan dengan keinginan terbaik di dunia) orang tidak selalu menulis kode pemicu yang baik. Kedua, mendapatkan rencana eksekusi yang baik dari pengoptimal kueri dalam semua keadaan bisa jadi sulit. Sifat pemicu adalah bahwa mereka dipanggil dengan berbagai kardinalitas input dan distribusi data.
Bahkan untuk pemicu SETELAH, kurangnya indeks dan statistik pada dihapus dan dimasukkan pseudo-tabel berarti pemilihan rencana sering didasarkan pada tebakan atau informasi yang salah. Bahkan di mana rencana yang baik awalnya dipilih, eksekusi kemudian dapat menggunakan kembali rencana yang sama ketika kompilasi ulang akan menjadi pilihan yang lebih baik. Ada beberapa cara untuk mengatasi keterbatasan, terutama melalui penggunaan tabel sementara dan indeks/statistik eksplisit, tetapi bahkan di sana diperlukan kehati-hatian (karena pemicu adalah bentuk prosedur tersimpan).
Dengan BUKAN pemicu, risikonya bisa lebih besar karena isi dimasukkan dan dihapus tabel adalah kandidat yang belum diverifikasi – pengoptimal kueri tidak dapat menggunakan batasan pada tabel dasar untuk menyederhanakan dan menyempurnakan rencana eksekusinya. Penaksir kardinalitas baru di SQL Server 2014 juga merupakan langkah mundur yang nyata dalam hal BUKAN rencana pemicu. Menebak efek dari operasi pencarian yang diperkenalkan oleh mesin itu sendiri adalah kekeliruan yang mengejutkan dan tidak diinginkan.