Ini juga bukan fragmentasi yang baik
Bulan lalu saya menulis tentang fragmentasi indeks clustered tak terduga jadi, kali ini, saya ingin membahas beberapa hal yang dapat Anda lakukan untuk menghindari terjadi fragmentasi indeks. Saya akan menganggap Anda telah membaca posting sebelumnya dan akrab dengan istilah yang saya definisikan di sana, dan sepanjang sisa artikel ini, ketika saya mengatakan 'fragmentasi' saya mengacu pada fragmentasi logis dan masalah kepadatan halaman yang rendah.
Pilih Kunci Cluster yang Baik
Struktur data yang paling mahal untuk dioperasikan untuk menghilangkan fragmentasi adalah indeks berkerumun dari sebuah tabel, karena ini adalah struktur terbesar karena berisi semua data tabel. Dari perspektif fragmentasi, masuk akal untuk memilih kunci cluster yang cocok dengan pola penyisipan tabel, sehingga tidak ada kemungkinan penyisipan terjadi pada halaman yang tidak memiliki ruang dan karenanya menyebabkan pemisahan halaman dan menyebabkan fragmentasi.
Apa yang merupakan kunci klaster terbaik untuk tabel apa pun adalah masalah banyak perdebatan, tetapi secara umum Anda tidak akan salah jika kunci klaster Anda memiliki properti sederhana berikut:
- Sempit (yaitu kolom sesedikit mungkin)
- Statis (yaitu Anda tidak pernah memperbaruinya)
- Unik
- Selalu meningkat
Ini adalah properti yang terus meningkat yang paling penting untuk pencegahan fragmentasi, karena menghindari penyisipan acak yang dapat menyebabkan pemisahan halaman pada halaman yang sudah penuh. Contoh dari pilihan kunci tersebut adalah identitas int dan kolom identitas bigint, atau bahkan GUID berurutan dari fungsi NEWSEQUENTIALID().
Dengan jenis kunci ini, baris baru akan memiliki nilai kunci yang dijamin lebih tinggi dari semua yang lain dalam tabel, sehingga titik penyisipan baris baru akan berada di akhir halaman paling kanan dalam struktur indeks berkerumun. Akhirnya baris baru akan mengisi halaman itu dan halaman lain akan ditambahkan ke sisi kanan indeks, tetapi tanpa terjadi pemisahan halaman yang merusak.
Sekarang, jika Anda memiliki kunci indeks berkerumun yang tidak pernah meningkat, mungkin prosedur yang sangat kompleks dan tidak menyenangkan untuk mengubahnya menjadi yang terus meningkat, jadi jangan khawatir – sebagai gantinya Anda dapat menggunakan faktor isian seperti yang saya bahas di bawah.
Omong-omong, untuk wawasan yang lebih mendalam tentang memilih kunci klaster dan semua konsekuensinya, lihat kategori blog Kunci Pengelompokan Kimberly (baca dari bawah ke atas).
Jangan Perbarui Kolom Kunci Indeks
Setiap kali kolom kunci diperbarui, itu bukan hanya pembaruan di tempat yang sederhana, meskipun banyak tempat online dan di buku mengatakan itu (mereka salah). Kolom kunci tidak dapat diperbarui di tempatnya karena nilai kunci baru akan berarti bahwa baris tersebut berada dalam urutan kunci yang salah untuk indeks. Alih-alih, pembaruan kolom kunci diterjemahkan menjadi penghapusan baris penuh ditambah sisipan baris penuh dengan nilai kunci baru. Jika halaman tempat baris baru akan disisipkan tidak memiliki cukup ruang di dalamnya, pemisahan halaman akan terjadi, menyebabkan fragmentasi.
Menghindari pembaruan kolom kunci seharusnya mudah dilakukan untuk indeks berkerumun, karena ini adalah desain yang buruk yang memerlukan pembaruan kunci klaster dari baris tabel. Namun, untuk indeks nonclustered, tidak dapat dihindari jika pembaruan ke tabel kebetulan melibatkan kolom di mana ada indeks nonclustered. Untuk kasus tersebut, Anda harus menggunakan faktor isian.
Jangan Perbarui Kolom Panjang Variabel
Yang ini lebih mudah diucapkan daripada dilakukan. Jika Anda harus menggunakan kolom dengan panjang variabel dan mungkin saja kolom tersebut diperbarui, maka kolom tersebut mungkin akan bertambah sehingga memerlukan lebih banyak ruang untuk baris yang diperbarui, yang mengarah ke pemisahan halaman jika halaman sudah penuh.
Ada beberapa hal yang dapat Anda lakukan untuk menghindari fragmentasi dalam kasus ini:
- Gunakan faktor isian
- Gunakan kolom dengan panjang tetap, jika overhead dari semua byte padding tambahan tidak terlalu bermasalah dibandingkan dengan fragmentasi atau menggunakan faktor isian
- Gunakan nilai placeholder untuk 'menyimpan' ruang untuk kolom – ini adalah trik yang dapat Anda gunakan jika aplikasi memasuki baris baru dan kemudian kembali untuk mengisi beberapa detail, menyebabkan perluasan kolom dengan panjang variabel
- Lakukan penghapusan plus penyisipan alih-alih pembaruan
Gunakan Faktor Isi
Seperti yang Anda lihat, banyak cara untuk menghindari fragmentasi tidak menyenangkan karena melibatkan perubahan aplikasi atau skema, sehingga menggunakan faktor isian adalah cara mudah untuk mengurangi fragmentasi.
Faktor pengisian indeks adalah pengaturan untuk indeks yang menentukan berapa banyak ruang kosong yang tersisa di setiap halaman tingkat daun saat indeks dibuat, dibangun kembali, atau ditata ulang. Idenya adalah bahwa ada cukup ruang kosong pada halaman untuk memungkinkan penyisipan acak atau pertumbuhan baris (dari tag versi yang ditambahkan atau kolom panjang variabel yang diperbarui) tanpa halaman terisi dan memerlukan pemisahan halaman. Namun, akhirnya halaman akan terisi, dan secara berkala ruang kosong perlu disegarkan dengan membangun kembali atau mengatur ulang indeks (umumnya disebut melakukan pemeliharaan indeks). Triknya adalah menemukan faktor pengisian yang tepat untuk digunakan, bersama dengan periodisitas pemeliharaan indeks yang tepat.
Anda dapat membaca lebih lanjut tentang menyetel faktor pengisian di MSDN di sini. Jangan terjebak dalam pengaturan faktor pengisian untuk seluruh instance (menggunakan sp_configure) karena itu berarti bahwa semua indeks akan dibangun kembali atau diatur ulang menggunakan nilai faktor pengisian tersebut, bahkan indeks yang tidak memiliki masalah fragmentasi. Anda tidak ingin indeks berkerumun besar Anda, dengan kunci bagus yang terus meningkat, semuanya memiliki 30% ruang level daun yang terbuang untuk mempersiapkan sisipan acak yang tidak akan pernah terjadi. Jauh lebih baik untuk mengetahui indeks mana yang benar-benar terpengaruh oleh fragmentasi dan hanya menetapkan faktor pengisian untuk indeks tersebut.
Tidak ada jawaban yang benar atau formula ajaib yang bisa saya berikan untuk ini. Praktik yang diterima secara umum adalah menempatkan faktor pengisian 70 (artinya menyisakan 30% ruang kosong) untuk indeks di mana fragmentasi menjadi masalah, memantau seberapa cepat fragmentasi terjadi, dan kemudian memodifikasi faktor pengisian atau frekuensi pemeliharaan indeks (atau keduanya).
Ya, ini berarti Anda sengaja membuang-buang ruang dalam indeks untuk menghindari fragmentasi, tetapi itu adalah pertukaran yang baik untuk dilakukan mengingat betapa mahalnya pemisahan halaman dan betapa merugikannya fragmentasi untuk kinerja. Dan ya, terlepas dari apa yang mungkin dikatakan beberapa orang, ini tetap penting bahkan jika Anda menggunakan SSD.
Ringkasan
Ada beberapa hal sederhana yang dapat Anda lakukan untuk menghindari terjadinya fragmentasi, tetapi segera setelah Anda masuk ke indeks nonclustered, atau menggunakan isolasi snapshot atau sekunder yang dapat dibaca, fragmentasi muncul kembali dan Anda perlu mencoba untuk mencegahnya.
Sekarang jangan terburu-buru dan berpikir bahwa Anda harus menetapkan faktor pengisian 70 pada semua instans Anda – Anda harus memilih dan mengaturnya dengan hati-hati, seperti yang saya jelaskan di atas.
Dan jangan lupa tentang SQL Sentry Fragmentation Manager, yang dapat Anda gunakan (sebagai tambahan untuk Performance Advisor) untuk membantu mencari tahu di mana masalah fragmentasi dan kemudian mengatasinya. Misalnya, pada tab Indeks, Anda dapat dengan mudah mengurutkan indeks berdasarkan fragmentasi tertinggi terlebih dahulu (dan, jika Anda suka, terapkan filter ke kolom jumlah baris, untuk mengabaikan tabel yang lebih kecil):
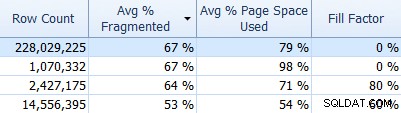
Dan kemudian lihat apakah indeks tersebut menggunakan faktor pengisian default (0%), atau mungkin faktor pengisian non-default, yang mungkin tidak cocok untuk data dan pola DML Anda. Saya akan membiarkan Anda menebak yang mana di tangkapan layar di atas yang paling ingin saya selidiki. Menerapkan faktor pengisian indeks yang lebih tepat adalah cara paling sederhana untuk mengatasi masalah apa pun yang Anda temukan.