[Lihat indeks semua pos kebiasaan buruk / praktik terbaik]
Salah satu slide dalam presentasi Kebiasaan Buruk &Praktik Terbaik saya yang berulang berjudul "Menyalahgunakan COUNT(*) ." Saya melihat penyalahgunaan ini cukup banyak di alam liar, dan itu mengambil beberapa bentuk.
Berapa banyak baris dalam tabel?
Saya biasanya melihat ini:
SELECT @count = COUNT(*) FROM dbo.tablename;
SQL Server harus menjalankan pemindaian pemblokiran terhadap seluruh tabel untuk mendapatkan jumlah ini. Itu mahal. Informasi ini disimpan dalam tampilan katalog dan DMV, dan Anda dapat memperolehnya tanpa semua I/O atau pemblokiran itu:
SELECT @count = SUM(p.rows) FROM sys.partitions AS p INNER JOIN sys.tables AS t ON p.[object_id] = t.[object_id] INNER JOIN sys.schemas AS s ON t.[schema_id] = s.[schema_id] WHERE p.index_id IN (0,1) -- heap or clustered index AND t.name = N'tablename' AND s.name = N'dbo';
(Anda bisa mendapatkan informasi yang sama dari sys.dm_db_partition_stats , tetapi dalam hal ini ubah p.rows ke p.row_count (yay konsistensi!). Sebenarnya, ini adalah tampilan yang sama yang digunakan sp_spaceused menggunakan untuk menurunkan hitungan – dan meskipun lebih mudah untuk mengetik daripada kueri di atas, saya sarankan untuk tidak menggunakannya hanya untuk mendapatkan hitungan karena semua perhitungan tambahan yang dilakukannya – kecuali jika Anda menginginkan informasi itu juga. Perhatikan juga bahwa ini menggunakan fungsi metadata yang tidak mematuhi tingkat isolasi luar Anda, sehingga Anda bisa menunggu pemblokiran saat Anda memanggil prosedur ini.)
Sekarang, memang benar bahwa tampilan ini tidak 100% akurat hingga mikrodetik. Kecuali Anda menggunakan heap, hasil yang lebih andal dapat diperoleh dari sys.dm_db_index_physical_stats() kolom record_count (yay konsistensi lagi!), namun fungsi ini dapat memiliki dampak kinerja, masih dapat memblokir, dan mungkin bahkan lebih mahal daripada SELECT COUNT(*) – harus melakukan operasi fisik yang sama, tetapi harus menghitung informasi tambahan tergantung pada mode (seperti fragmentasi, yang tidak Anda pedulikan dalam kasus ini). Peringatan dalam dokumentasi menceritakan bagian dari cerita, relevan jika Anda menggunakan Grup Ketersediaan (dan kemungkinan memengaruhi Pencerminan Basis Data dengan cara yang sama):
Dokumentasi juga menjelaskan mengapa nomor ini mungkin tidak dapat diandalkan untuk heap (dan juga memberi mereka quasi-pass untuk inkonsistensi baris vs. record):
Untuk heap, jumlah record yang dikembalikan dari fungsi ini mungkin tidak cocok dengan jumlah baris yang dikembalikan dengan menjalankan SELECT COUNT(*) terhadap heap. Ini karena satu baris mungkin berisi beberapa record. Misalnya, dalam beberapa situasi pembaruan, satu baris tumpukan mungkin memiliki catatan penerusan dan catatan yang diteruskan sebagai hasil dari operasi pembaruan. Juga, sebagian besar baris LOB besar dipecah menjadi beberapa catatan dalam penyimpanan LOB_DATA.
Jadi saya akan condong ke sys.partitions sebagai cara untuk mengoptimalkan ini, mengorbankan sedikit akurasi.
- "Tapi saya tidak bisa menggunakan DMV; hitungan saya harus sangat akurat!"
Hitungan "super akurat" sebenarnya tidak ada artinya. Mari kita pertimbangkan bahwa satu-satunya pilihan Anda untuk penghitungan "super akurat" adalah mengunci seluruh tabel dan melarang siapa pun menambahkan atau menghapus baris apa pun (tetapi tanpa mencegah pembacaan bersama), mis.:
SELECT @count = COUNT(*) FROM dbo.table_name WITH (TABLOCK); -- not TABLOCKX!
Jadi, kueri Anda bersenandung, memindai semua data, bekerja menuju hitungan "sempurna" itu. Sementara itu, permintaan tulis diblokir, dan menunggu. Tiba-tiba, ketika penghitungan akurat Anda dikembalikan, kunci Anda di atas meja dilepaskan, dan semua permintaan tulis yang diantrekan dan menunggu, mulai menembakkan semua jenis sisipan, pembaruan, dan penghapusan pada tabel Anda. Seberapa "super akurat" hitungan Anda sekarang? Apakah layak mendapatkan penghitungan "akurat" yang sudah sangat usang? Jika sistem tidak sibuk, maka ini bukan masalah besar – tetapi jika sistem tidak sibuk, saya berpendapat cukup kuat bahwa DMV akan sangat akurat.
Anda bisa menggunakan NOLOCK sebagai gantinya, tetapi itu hanya berarti penulis dapat mengubah data saat Anda membacanya, dan menyebabkan masalah lain juga (saya membicarakannya baru-baru ini). Tidak apa-apa untuk banyak stadion baseball, tetapi tidak jika tujuan Anda adalah akurasi. DMV akan tepat (atau setidaknya lebih dekat) dalam banyak skenario, dan lebih jauh dalam sangat sedikit (bahkan tidak ada yang dapat saya pikirkan).
Terakhir, Anda dapat menggunakan Read Committed Snapshot Isolation. Kendra Little memiliki posting fantastis tentang tingkat isolasi snapshot, tetapi saya akan mengulangi daftar peringatan yang saya sebutkan di NOLOCK saya artikel:
- Kunci Sch-S masih perlu diambil bahkan di bawah RCSI.
- Tingkat isolasi snapshot menggunakan versi baris di tempdb, jadi Anda benar-benar perlu menguji dampaknya di sana.
- RCSI tidak dapat menggunakan pemindaian urutan alokasi yang efisien; Anda akan melihat pemindaian jarak.
- Paul White (@SQL_Kiwi) memiliki beberapa postingan bagus yang harus Anda baca tentang level isolasi ini:
- Baca Isolasi Snapshot yang Dikomit
- Modifikasi Data di bawah Isolasi Snapshot yang Dikomit Baca
- Tingkat Isolasi SNAPSHOT
Selain itu, bahkan dengan RCSI, mendapatkan penghitungan "akurat" membutuhkan waktu (dan sumber daya tambahan di tempdb). Pada saat operasi selesai, apakah hitungannya masih akurat? Hanya jika tidak ada yang menyentuh meja untuk sementara waktu. Jadi salah satu manfaat RCSI (pembaca tidak menghalangi penulis) terbuang percuma.
Berapa banyak baris yang cocok dengan klausa WHERE?
Ini adalah skenario yang sedikit berbeda – Anda perlu mengetahui berapa banyak baris yang ada untuk subset tabel tertentu. Anda tidak dapat menggunakan DMV untuk ini, kecuali WHERE klausa cocok dengan indeks yang difilter atau sepenuhnya mencakup partisi yang tepat (atau banyak).
Jika Anda WHERE klausa dinamis, Anda bisa menggunakan RCSI, seperti yang dijelaskan di atas.
Jika Anda WHERE klausa tidak dinamis, Anda juga dapat menggunakan RCSI, tetapi Anda juga dapat mempertimbangkan salah satu opsi berikut:
- Indeks yang difilter – misalnya jika Anda memiliki filter sederhana seperti
is_active = 1ataustatus < 5, maka Anda dapat membuat indeks seperti ini:CREATE INDEX ix_f ON dbo.table_name(leading_pk_column) WHERE is_active = 1;
Sekarang, Anda bisa mendapatkan penghitungan yang cukup akurat dari DMV, karena akan ada entri yang mewakili indeks ini (Anda hanya perlu mengidentifikasi index_id alih-alih mengandalkan heap(0)/clustered index(1)). Namun, Anda perlu mempertimbangkan beberapa kelemahan indeks yang difilter.
- Tampilan yang diindeks - misalnya jika Anda sering menghitung pesanan oleh pelanggan, tampilan yang diindeks dapat membantu (walaupun tolong jangan menganggap ini sebagai dukungan umum bahwa "tampilan yang diindeks meningkatkan semua kueri!"):
CREATE VIEW dbo.view_name WITH SCHEMABINDING AS SELECT customer_id, customer_count = COUNT_BIG(*) FROM dbo.table_name GROUP BY customer_id; GO CREATE UNIQUE CLUSTERED INDEX ix_v ON dbo.view_name(customer_id);Sekarang, data dalam tampilan akan terwujud, dan hitungan dijamin akan disinkronkan dengan data tabel (ada beberapa bug yang tidak jelas di mana ini tidak benar, seperti yang ini dengan
MERGE, tetapi umumnya ini dapat diandalkan). Jadi sekarang Anda bisa mendapatkan hitungan per pelanggan (atau untuk sekumpulan pelanggan) dengan mengkueri tampilan, dengan biaya kueri yang jauh lebih rendah (1 atau 2 pembacaan):SELECT customer_count FROM dbo.view_name WHERE customer_id = <x>;
Tidak ada makan siang gratis . Anda perlu mempertimbangkan biaya tambahan untuk mempertahankan tampilan yang diindeks dan dampaknya terhadap porsi penulisan beban kerja Anda. Jika Anda tidak sering menjalankan jenis kueri ini, sepertinya tidak ada gunanya.
Apakah setidaknya satu baris cocok dengan klausa WHERE?
Ini juga merupakan pertanyaan yang sedikit berbeda. Tapi saya sering melihat ini:
IF (SELECT COUNT(*) FROM dbo.table_name WHERE <some clause>) > 0 -- or = 0 for not exists
Karena Anda jelas tidak peduli dengan jumlah sebenarnya, Anda hanya peduli jika setidaknya ada satu baris, saya benar-benar berpikir Anda harus mengubahnya menjadi berikut:
IF EXISTS (SELECT 1 FROM dbo.table_name WHERE <some clause>)
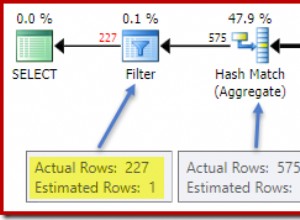
Ini setidaknya memiliki kemungkinan hubungan arus pendek sebelum akhir tabel tercapai, dan hampir selalu akan mengungguli COUNT variasi (meskipun ada beberapa kasus di mana SQL Server cukup pintar untuk mengonversi IF (SELECT COUNT...) > 0 ke IF EXISTS() yang lebih sederhana ). Dalam skenario kasus terburuk mutlak, di mana tidak ada baris yang ditemukan (atau baris pertama ditemukan pada halaman terakhir dalam pemindaian), kinerjanya akan sama.
[Lihat indeks semua pos kebiasaan buruk / praktik terbaik]