Anda mungkin berpikir pemeliharaan database bukan urusan Anda. Namun, jika Anda mendesain model secara proaktif, Anda akan mendapatkan database yang membuat hidup lebih mudah bagi mereka yang harus memeliharanya.
Desain database yang baik membutuhkan proaktif, kualitas yang dianggap baik di lingkungan kerja apa pun. Jika Anda tidak terbiasa dengan istilah tersebut, proaktif adalah kemampuan untuk mengantisipasi masalah dan menyiapkan solusi saat masalah terjadi – atau lebih baik lagi, merencanakan dan bertindak agar masalah tidak terjadi sejak awal.
Pengusaha memahami bahwa proaktif dari karyawan atau kontraktor mereka sama dengan penghematan biaya. Itulah mengapa mereka menghargainya dan mendorong orang untuk mempraktikkannya.
Dalam peran Anda sebagai pemodel data, cara terbaik untuk menunjukkan proaktif adalah merancang model yang mengantisipasi dan menghindari masalah yang secara rutin mengganggu pemeliharaan basis data. Atau, setidaknya, yang secara substansial menyederhanakan solusi untuk masalah tersebut.
Bahkan jika Anda tidak bertanggung jawab atas pemeliharaan basis data, pemodelan untuk pemeliharaan basis data yang mudah menuai banyak manfaat. Misalnya, Anda tidak dapat dipanggil kapan pun untuk menyelesaikan keadaan darurat data yang menghabiskan waktu berharga yang dapat Anda habiskan untuk tugas desain atau pemodelan yang sangat Anda sukai!
Membuat Hidup Lebih Mudah untuk Orang IT
Saat mendesain database, kita perlu berpikir di luar penyampaian DER dan pembuatan skrip pembaruan. Setelah database masuk ke produksi, teknisi pemeliharaan harus menangani segala macam potensi masalah, dan bagian dari tugas kita sebagai pemodel database adalah meminimalkan kemungkinan terjadinya masalah tersebut.
Mari kita mulai dengan melihat apa artinya membuat desain database yang baik dan bagaimana aktivitas tersebut terkait dengan tugas pemeliharaan database reguler.
Apa itu Pemodelan Data?
Pemodelan data adalah tugas membuat abstrak, biasanya grafis, representasi dari repositori informasi. Tujuan dari pemodelan data adalah untuk mengekspos atribut, dan hubungan antara, entitas yang datanya disimpan dalam repositori.
Model data dibangun di sekitar kebutuhan masalah bisnis. Aturan dan persyaratan ditentukan sebelumnya melalui masukan dari pakar bisnis sehingga dapat dimasukkan ke dalam desain repositori data baru atau diadaptasi dalam iterasi yang sudah ada.
Idealnya, model data adalah dokumen hidup yang berkembang seiring dengan perubahan kebutuhan bisnis. Mereka memainkan peran penting dalam mendukung keputusan bisnis dan dalam perencanaan arsitektur dan strategi sistem. Model data harus tetap sinkron dengan database yang diwakilinya sehingga berguna untuk rutinitas pemeliharaan database tersebut.
Tantangan Pemeliharaan Basis Data Umum
Mempertahankan database memerlukan pemantauan konstan, otomatis atau sebaliknya, untuk memastikan tidak kehilangan keunggulannya. Praktik terbaik pemeliharaan basis data memastikan basis data selalu menyimpan:
- Integritas dan kualitas informasi
- Kinerja
- Ketersediaan
- Skalabilitas
- Kemampuan beradaptasi dengan perubahan
- Kemamputelusuran
- Keamanan
Banyak tips pemodelan data yang tersedia untuk membantu Anda membuat desain database yang baik setiap saat. Yang dibahas di bawah ini bertujuan khusus untuk memastikan atau memfasilitasi pemeliharaan kualitas database yang disebutkan di atas.
Integritas dan Kualitas Informasi
Tujuan mendasar dari praktik terbaik pemeliharaan database adalah untuk memastikan informasi dalam database menjaga integritasnya. Ini penting agar pengguna tetap percaya pada informasi.
Ada dua jenis integritas:integritas fisik dan integritas logis .
Integritas Fisik
Menjaga integritas fisik database dilakukan dengan melindungi informasi dari faktor eksternal seperti perangkat keras atau kegagalan daya. Pendekatan yang paling umum dan diterima secara luas adalah melalui strategi pencadangan yang memadai yang memungkinkan pemulihan database dalam waktu yang wajar jika bencana menghancurkannya.
Untuk DBA dan administrator server yang mengelola penyimpanan database, penting untuk mengetahui apakah database dapat dipartisi menjadi beberapa bagian dengan frekuensi pembaruan yang berbeda. Hal ini memungkinkan mereka untuk mengoptimalkan penggunaan penyimpanan dan rencana pencadangan.
Model data dapat mencerminkan partisi itu dengan mengidentifikasi area "suhu" data yang berbeda dan dengan mengelompokkan entitas ke dalam area tersebut. "Suhu" mengacu pada frekuensi tabel menerima informasi baru. Tabel yang sangat sering diperbarui adalah yang "terpanas"; yang tidak pernah atau jarang diperbarui adalah yang "paling dingin".

Model data sistem e-niaga yang membedakan data panas, hangat, dan dingin.
DBA atau administrator sistem dapat menggunakan pengelompokan logis ini untuk mempartisi file database dan membuat rencana pencadangan yang berbeda untuk setiap partisi.
Integritas Logis
Mempertahankan integritas logis dari database sangat penting untuk keandalan dan kegunaan informasi yang diberikannya. Jika database tidak memiliki integritas logis, aplikasi yang menggunakannya akan mengungkapkan inkonsistensi dalam data cepat atau lambat. Menghadapi inkonsistensi ini, pengguna tidak mempercayai informasi dan hanya mencari sumber data yang lebih andal.
Di antara tugas-tugas pemeliharaan database, menjaga integritas logis dari informasi adalah perpanjangan dari tugas pemodelan database, hanya itu dimulai setelah database dimasukkan ke dalam produksi dan berlanjut sepanjang masa pakainya. Bagian terpenting dari area pemeliharaan ini adalah beradaptasi dengan perubahan.
Manajemen Perubahan
Perubahan aturan atau persyaratan bisnis merupakan ancaman konstan terhadap integritas logis database. Anda mungkin merasa senang dengan model data yang telah Anda buat, mengetahui bahwa model tersebut disesuaikan dengan sempurna untuk bisnis, merespons dengan informasi yang tepat untuk kueri apa pun, dan tidak memasukkan anomali penyisipan, pembaruan, atau penghapusan apa pun. Nikmati momen kepuasan ini, karena ini berumur pendek!
Pemeliharaan database melibatkan menghadapi kebutuhan untuk membuat perubahan dalam model setiap hari. Ini memaksa Anda untuk menambahkan objek baru atau mengubah yang sudah ada, memodifikasi kardinalitas hubungan, mendefinisikan kembali kunci utama, mengubah tipe data, dan melakukan hal-hal lain yang membuat kita para pemodel menggigil.
Perubahan terjadi sepanjang waktu. Mungkin ada beberapa persyaratan yang dijelaskan salah sejak awal, persyaratan baru telah muncul, atau Anda secara tidak sengaja memperkenalkan beberapa kekurangan pada model Anda (bagaimanapun juga, kami pemodel data hanyalah manusia).
Model Anda harus mudah dimodifikasi ketika kebutuhan akan perubahan muncul. Sangat penting untuk menggunakan alat desain database untuk pemodelan yang memungkinkan Anda membuat versi model Anda, menghasilkan skrip untuk memigrasi database dari satu versi ke versi lain, dan mendokumentasikan setiap keputusan desain dengan benar.
Tanpa alat ini, setiap perubahan yang Anda buat pada desain Anda menciptakan risiko integritas yang terungkap pada saat yang paling tidak tepat. Vertabelo memberi Anda semua fungsi ini dan menangani pemeliharaan riwayat versi model tanpa Anda harus memikirkannya.
Pembuatan versi otomatis pada Vertabelo sangat membantu dalam mempertahankan perubahan pada model data.
Manajemen perubahan dan kontrol versi juga merupakan faktor penting dalam menyematkan aktivitas pemodelan data ke dalam siklus hidup pengembangan perangkat lunak.
Pemfaktoran Ulang
Saat Anda menerapkan perubahan ke database yang digunakan, Anda harus 100% yakin bahwa tidak ada informasi yang hilang dan integritasnya tidak terpengaruh sebagai konsekuensi dari perubahan tersebut. Untuk melakukan ini, Anda dapat menggunakan teknik refactoring. Mereka biasanya diterapkan ketika Anda ingin meningkatkan desain tanpa mempengaruhi semantiknya, tetapi mereka juga dapat digunakan untuk memperbaiki kesalahan desain atau menyesuaikan model dengan persyaratan baru.
Ada sejumlah besar teknik refactoring. Mereka biasanya digunakan untuk memberikan kehidupan baru ke database warisan, dan ada prosedur buku teks yang memastikan perubahan tidak merusak informasi yang ada. Seluruh buku telah ditulis tentang itu; Saya sarankan Anda membacanya.
Tetapi untuk meringkas, kita dapat mengelompokkan teknik refactoring ke dalam kategori berikut:
- Kualitas data: Membuat perubahan yang memastikan konsistensi dan koherensi data. Contohnya termasuk menambahkan tabel pencarian dan memigrasikannya ke data yang diulang di tabel lain dan menambahkan batasan pada kolom.
- Struktural: Membuat perubahan pada struktur tabel yang tidak mengubah semantik model. Contohnya termasuk menggabungkan dua kolom menjadi satu, menambahkan kunci pengganti, dan membagi kolom menjadi dua.
- Integritas referensial: Menerapkan perubahan untuk memastikan bahwa baris yang direferensikan ada dalam tabel terkait atau bahwa baris yang tidak direferensikan dapat dihapus. Contohnya termasuk menambahkan batasan kunci asing pada kolom dan menambahkan batasan nilai bukan nol ke tabel.
- Arsitektur: Membuat perubahan yang bertujuan untuk meningkatkan interaksi aplikasi dengan database. Contohnya termasuk membuat indeks, membuat tabel hanya-baca, dan merangkum satu atau beberapa tabel dalam sebuah tampilan.
Teknik yang memodifikasi semantik model, serta yang tidak mengubah model data dengan cara apa pun, tidak dianggap sebagai teknik refactoring. Ini termasuk menyisipkan baris ke tabel, menambahkan kolom baru, membuat tabel atau tampilan baru, dan memperbarui data dalam tabel.
Menjaga Kualitas Informasi
Kualitas informasi dalam database adalah sejauh mana data memenuhi harapan organisasi untuk akurasi, validitas, kelengkapan, dan konsistensi. Menjaga kualitas data sepanjang siklus hidup database sangat penting bagi penggunanya untuk membuat keputusan yang benar dan tepat menggunakan data di dalamnya.
Tanggung jawab Anda sebagai pemodel data adalah memastikan model Anda menjaga kualitas informasinya pada tingkat setinggi mungkin. Untuk melakukan ini:
- Desain harus mengikuti setidaknya bentuk normal ke-3 sehingga anomali penyisipan, pembaruan, atau penghapusan tidak terjadi. Pertimbangan ini berlaku terutama untuk database untuk penggunaan transaksional, di mana data ditambahkan, diperbarui, dan dihapus secara teratur. Ini tidak benar-benar berlaku dalam database untuk penggunaan analitis (yaitu, gudang data), karena pembaruan dan penghapusan data jarang dilakukan, jika pernah.
- Tipe data setiap bidang di setiap tabel harus sesuai dengan atribut yang diwakilinya dalam model logika. Ini lebih dari sekadar mendefinisikan dengan benar apakah suatu bidang bertipe data numerik, tanggal, atau alfanumerik. Penting juga untuk menentukan dengan benar rentang dan ketepatan nilai yang didukung oleh setiap bidang. Contoh:atribut tipe Tanggal yang diterapkan dalam database sebagai bidang Tanggal/Waktu dapat menyebabkan masalah dalam kueri, karena nilai yang disimpan dengan bagian waktunya selain nol mungkin berada di luar cakupan kueri yang menggunakan rentang tanggal.
- Dimensi dan fakta yang mendefinisikan struktur gudang data harus selaras dengan kebutuhan bisnis. Saat mendesain gudang data, dimensi dan fakta model harus didefinisikan dengan benar sejak awal. Melakukan modifikasi setelah database beroperasi akan menimbulkan biaya pemeliharaan yang sangat tinggi.
Mengelola Pertumbuhan
Tantangan besar lainnya dalam memelihara database adalah mencegah pertumbuhannya mencapai batas kapasitas penyimpanan secara tidak terduga. Untuk membantu manajemen ruang penyimpanan, Anda dapat menerapkan prinsip yang sama yang digunakan dalam prosedur pencadangan:kelompokkan tabel dalam model Anda sesuai dengan kecepatan pertumbuhannya.
Pembagian menjadi dua area biasanya sudah cukup. Tempatkan tabel dengan penambahan baris yang sering di satu area, tabel yang barisnya jarang disisipkan di area lain. Memiliki model yang disektor dengan cara ini memungkinkan administrator penyimpanan untuk mempartisi file database sesuai dengan tingkat pertumbuhan masing-masing area. Mereka dapat mendistribusikan partisi di antara media penyimpanan yang berbeda dengan kapasitas atau kemungkinan pertumbuhan yang berbeda.
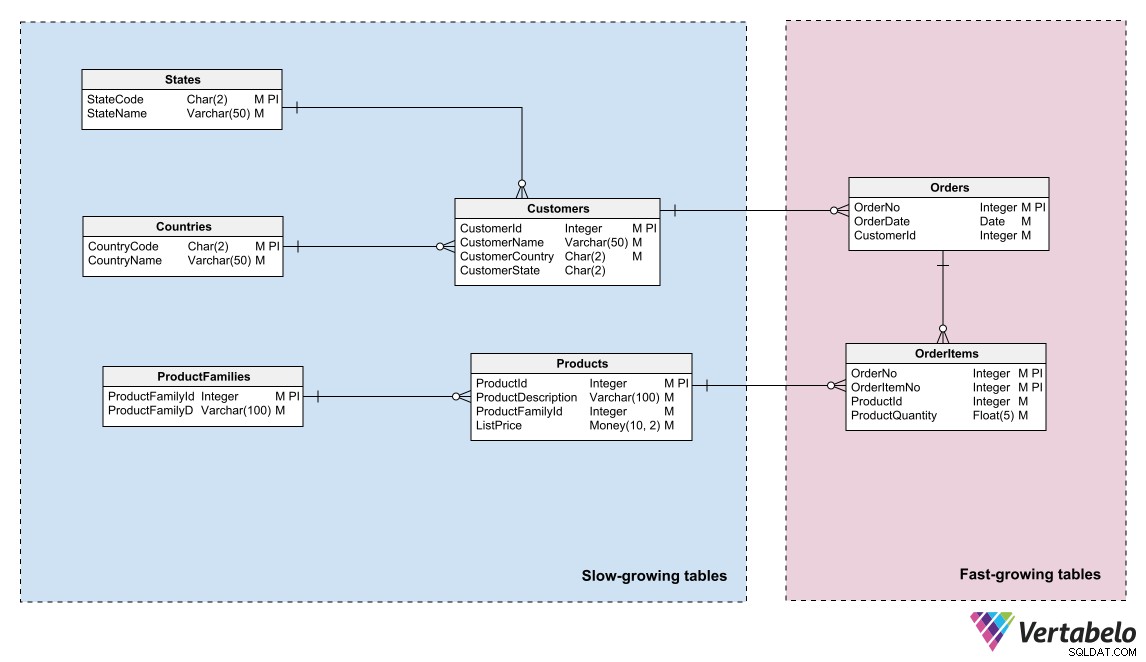
Pengelompokan tabel berdasarkan tingkat pertumbuhannya membantu menentukan persyaratan penyimpanan dan mengelola pertumbuhannya.
Log
Kami membuat model data yang mengharapkannya memberikan informasi sebagaimana adanya pada saat kueri. Namun, kita cenderung mengabaikan kebutuhan database untuk mengingat semua yang telah terjadi di masa lalu kecuali jika pengguna secara khusus memerlukannya.
Bagian dari pemeliharaan database adalah mengetahui bagaimana, kapan, mengapa, dan oleh siapa bagian data tertentu diubah. Ini mungkin untuk hal-hal seperti mencari tahu kapan harga produk berubah atau meninjau perubahan catatan medis pasien di rumah sakit. Logging dapat digunakan bahkan untuk memperbaiki kesalahan pengguna atau aplikasi karena memungkinkan Anda mengembalikan status informasi ke titik di masa lalu tanpa perlu menggunakan prosedur pemulihan cadangan yang rumit.
Sekali lagi, bahkan jika pengguna tidak membutuhkannya secara eksplisit, mengingat perlunya pencatatan proaktif adalah cara yang sangat berharga untuk memfasilitasi pemeliharaan basis data dan menunjukkan kemampuan Anda untuk mengantisipasi masalah. Memiliki data logging memungkinkan tanggapan langsung ketika seseorang perlu meninjau informasi historis.
Ada strategi yang berbeda untuk model database untuk mendukung logging, yang semuanya menambah kompleksitas model. Satu pendekatan disebut logging di tempat, yang menambahkan kolom ke setiap tabel untuk merekam informasi versi. Ini adalah opsi sederhana yang tidak melibatkan pembuatan skema terpisah atau tabel khusus logging. Namun, hal itu memengaruhi desain model karena kunci utama asli tabel tidak lagi valid sebagai kunci utama – nilainya diulang dalam baris yang mewakili versi berbeda dari data yang sama.
Pilihan lain untuk menyimpan informasi log adalah dengan menggunakan tabel bayangan. Tabel bayangan adalah replika dari tabel model dengan penambahan kolom untuk merekam data jejak log. Strategi ini tidak memerlukan modifikasi tabel dalam model aslinya, tetapi Anda harus ingat untuk memperbarui tabel bayangan yang sesuai saat Anda mengubah model data Anda.
Namun strategi lain adalah menggunakan subskema dari tabel generik yang merekam setiap penyisipan, penghapusan, atau modifikasi ke tabel lain.
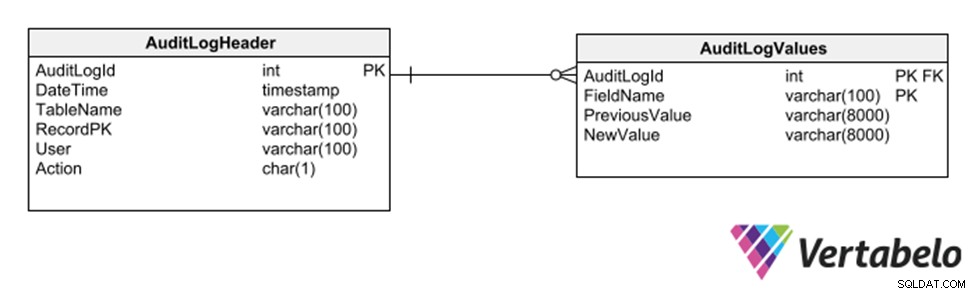
Tabel umum untuk menyimpan jejak audit database.
Strategi ini memiliki keuntungan karena tidak memerlukan modifikasi model untuk merekam jejak audit. Namun, karena menggunakan kolom generik bertipe varchar, ini membatasi jenis data yang dapat direkam dalam jejak log.
Pemeliharaan Kinerja dan Pembuatan Indeks
Hampir semua database memiliki kinerja yang baik ketika baru mulai digunakan dan tabelnya hanya berisi beberapa baris. Tetapi segera setelah aplikasi mulai mengisinya dengan data, kinerja dapat menurun dengan sangat cepat jika tindakan pencegahan tidak diambil dalam merancang model. Ketika ini terjadi, DBA dan administrator sistem akan menghubungi Anda untuk membantu mereka memecahkan masalah kinerja.
Pembuatan/saran otomatis indeks pada basis data produksi adalah alat yang berguna untuk memecahkan masalah kinerja "di saat yang panas". Mesin basis data dapat menganalisis aktivitas basis data untuk melihat operasi mana yang membutuhkan waktu paling lama dan di mana ada peluang untuk mempercepat dengan membuat indeks.
Namun, jauh lebih baik untuk proaktif dan mengantisipasi situasi dengan mendefinisikan indeks sebagai bagian dari model data. Ini sangat mengurangi upaya pemeliharaan untuk meningkatkan kinerja database. Jika Anda tidak terbiasa dengan manfaat indeks basis data, saya sarankan untuk membaca semua tentang indeks, mulai dari yang paling dasar.
Ada aturan praktis yang memberikan panduan yang cukup untuk membuat indeks paling penting untuk kueri yang efisien. Yang pertama adalah menghasilkan indeks untuk kunci utama setiap tabel. Praktis setiap RDBMS menghasilkan indeks untuk setiap kunci utama secara otomatis, sehingga Anda dapat melupakan aturan ini.
Aturan lain adalah untuk menghasilkan indeks untuk kunci alternatif tabel, terutama dalam tabel yang kunci pengganti dibuat. Jika sebuah tabel memiliki kunci alami yang tidak digunakan sebagai kunci utama, kueri untuk menggabungkan tabel tersebut dengan orang lain kemungkinan besar melakukannya dengan kunci alami, bukan pengganti. Kueri tersebut tidak berkinerja baik kecuali Anda membuat indeks pada kunci alami.
Aturan praktis berikutnya untuk indeks adalah membuatnya untuk semua bidang yang merupakan kunci asing. Bidang ini adalah kandidat yang bagus untuk membuat gabungan dengan tabel lain. Jika disertakan dalam indeks, mereka digunakan oleh parser kueri untuk mempercepat eksekusi dan meningkatkan kinerja database.
Terakhir, adalah ide yang baik untuk menggunakan alat pembuatan profil pada staging atau database QA selama pengujian kinerja untuk mendeteksi peluang pembuatan indeks yang tidak jelas. Memasukkan indeks yang disarankan oleh alat pembuatan profil ke dalam model data sangat membantu dalam mencapai dan mempertahankan kinerja database setelah produksi.
Keamanan
Dalam peran Anda sebagai pemodel data, Anda dapat membantu menjaga keamanan database dengan menyediakan basis yang kokoh dan aman untuk menyimpan data untuk autentikasi pengguna. Perlu diingat bahwa informasi ini sangat sensitif dan tidak boleh terkena serangan cyber.
Agar desain Anda menyederhanakan pemeliharaan keamanan basis data, ikuti praktik terbaik untuk menyimpan data autentikasi, yang utama di antaranya adalah tidak menyimpan kata sandi dalam basis data bahkan dalam bentuk terenkripsi. Menyimpan hanya hashnya alih-alih kata sandi untuk setiap pengguna memungkinkan aplikasi untuk mengautentikasi login pengguna tanpa membuat risiko paparan kata sandi.
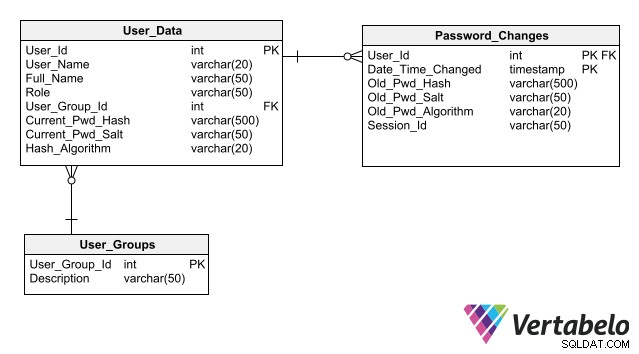
Skema lengkap untuk autentikasi pengguna yang menyertakan kolom untuk menyimpan hash sandi.
Visi untuk Masa Depan
Jadi, buat model Anda untuk perawatan database yang mudah dengan desain database yang baik dengan memperhatikan tip yang diberikan di atas. Dengan model data yang lebih dapat dipelihara, pekerjaan Anda terlihat lebih baik, dan Anda mendapatkan apresiasi dari DBA, teknisi pemeliharaan, dan administrator sistem.
Anda juga berinvestasi dalam ketenangan pikiran. Membuat basis data yang mudah dipelihara berarti Anda dapat menghabiskan waktu kerja Anda merancang model data baru, daripada berkeliaran menambal basis data yang gagal memberikan informasi yang benar tepat waktu.