Mesin eksekusi kueri SQL Server memiliki dua cara untuk mengimplementasikan operasi logis 'union all', menggunakan operator fisik Concatenation dan Merge Join Concatenation. Meskipun operasi logikanya sama, ada perbedaan penting antara dua operator fisik yang dapat membuat perbedaan besar pada efisiensi rencana eksekusi Anda.
Pengoptimal kueri melakukan pekerjaan yang wajar untuk memilih di antara dua opsi dalam banyak kasus, tetapi masih jauh dari sempurna di area ini. Artikel ini menjelaskan peluang penyetelan kueri yang disajikan oleh Merge Join Concatenation, dan merinci perilaku dan pertimbangan internal yang perlu Anda ketahui untuk memanfaatkannya secara maksimal.
Penggabungan

Operator Penggabungan relatif sederhana:keluarannya adalah hasil pembacaan penuh dari setiap masukannya secara berurutan. Operator Penggabungan adalah n-ary operator fisik, artinya dapat memiliki input '2…n'. Sebagai ilustrasi, mari kita lihat kembali contoh berbasis AdventureWorks dari artikel saya sebelumnya, "Menulis Ulang Kueri untuk Meningkatkan Kinerja":
SELECT * INTO dbo.TH FROM Production.TransactionHistory; CREATE UNIQUE CLUSTERED INDEX CUQ_TransactionID ON dbo.TH (TransactionID); CREATE NONCLUSTERED INDEX IX_ProductID ON dbo.TH (ProductID);
Kueri berikut mencantumkan ID produk dan transaksi untuk enam produk tertentu:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711;
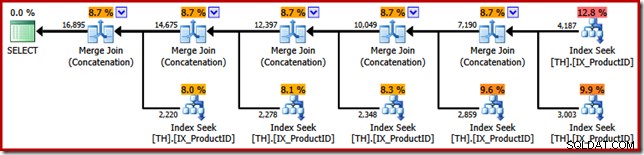
Ini menghasilkan rencana eksekusi yang menampilkan operator Penggabungan dengan enam input, seperti yang terlihat di SQL Sentry Plan Explorer:
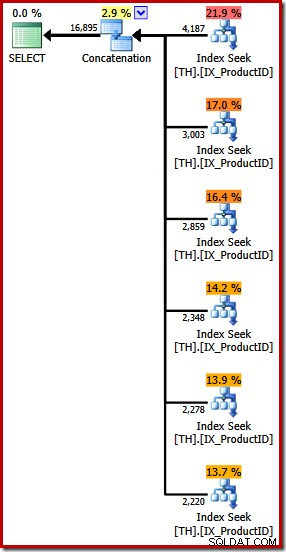
Paket di atas menampilkan Pencarian Indeks terpisah untuk setiap ID produk yang terdaftar, dalam urutan yang sama seperti yang ditentukan dalam kueri (membaca dari atas ke bawah). Pencarian Indeks paling atas adalah untuk produk 870, yang berikutnya turun untuk produk 873, lalu 921 dan seterusnya. Tentu saja tidak ada yang menjamin perilaku tersebut, itu hanya sesuatu yang menarik untuk diamati.
Saya sebutkan sebelumnya bahwa operator Concatenation membentuk outputnya dengan membaca dari inputnya secara berurutan. Ketika rencana ini dijalankan, kemungkinan besar kumpulan hasil akan menampilkan baris untuk produk 870 terlebih dahulu, kemudian 873, 921, 712, 707, dan terakhir produk 711. Sekali lagi, ini tidak dijamin karena kami tidak menentukan ORDER klausa BY, tetapi menunjukkan bagaimana Penggabungan beroperasi secara internal.
"Rencana Eksekusi" SSIS
Untuk alasan yang akan masuk akal dalam beberapa saat, pertimbangkan bagaimana kami dapat merancang paket SSIS untuk melakukan tugas yang sama. Kami tentu juga dapat menulis semuanya sebagai satu pernyataan T-SQL di SSIS, tetapi opsi yang lebih menarik adalah membuat sumber data terpisah untuk setiap produk, dan menggunakan komponen "Union All" SSIS sebagai pengganti SQL Server Concatenation operator:
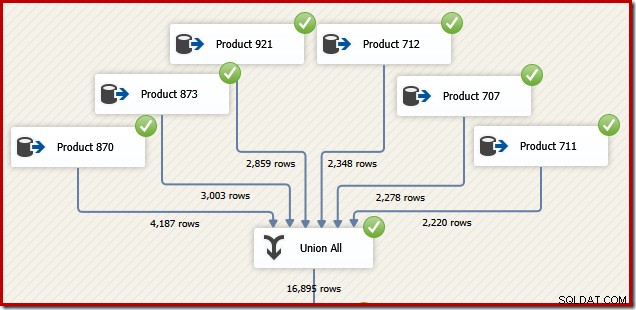
Sekarang bayangkan kita membutuhkan keluaran akhir dari aliran data tersebut dalam urutan ID Transaksi. Salah satu opsi adalah menambahkan komponen Sortir eksplisit setelah Union All:
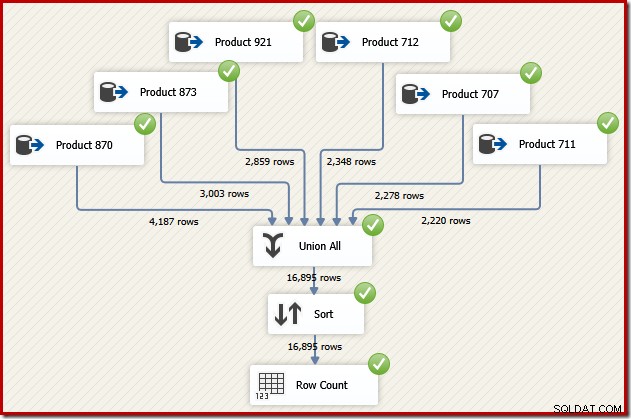
Itu pasti akan berhasil, tetapi perancang SSIS yang terampil dan berpengalaman akan menyadari bahwa ada opsi yang lebih baik:baca data sumber untuk setiap produk dalam urutan ID Transaksi (menggunakan indeks), lalu gunakan operasi pelestarian pesanan untuk menggabungkan set .
Di SSIS, komponen yang menggabungkan baris dari dua aliran data yang diurutkan menjadi satu aliran data yang diurutkan disebut "Gabung". Alur Data SSIS yang didesain ulang yang menggunakan Gabung untuk mengembalikan baris yang diinginkan dalam urutan ID Transaksi berikut:
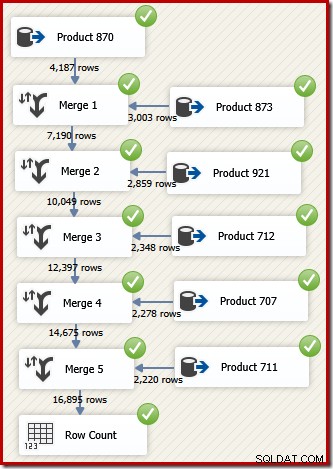
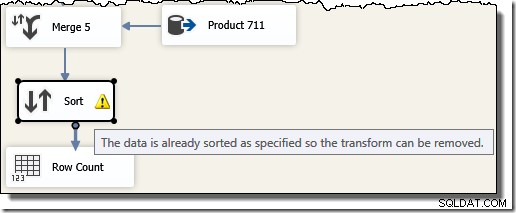
Perhatikan bahwa kita memerlukan lima komponen Merge yang terpisah karena Merge adalah komponen biner, tidak seperti komponen "Union All" SSIS, yang n-ary . Alur Penggabungan baru menghasilkan hasil dalam urutan ID Transaksi, tanpa memerlukan komponen Sortir yang mahal (dan memblokir). Memang, jika kami mencoba menambahkan Sort pada ID Transaksi setelah Penggabungan terakhir, SSIS menunjukkan peringatan untuk memberi tahu kami bahwa aliran sudah diurutkan dengan cara yang diinginkan:
Inti dari contoh SSIS sekarang dapat terungkap. Lihat rencana eksekusi yang dipilih oleh pengoptimal kueri SQL Server saat kami memintanya untuk mengembalikan hasil kueri T-SQL asli dalam urutan ID Transaksi (dengan menambahkan klausa ORDER BY):
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711 ORDER BY TransactionID;
Kesamaan dengan paket Penggabungan SSIS sangat mencolok; bahkan hingga kebutuhan lima operator "Gabung" biner. Satu perbedaan penting adalah bahwa SSIS memiliki komponen terpisah untuk "Merge Join" dan "Merge" sedangkan SQL Server menggunakan operator inti yang sama untuk keduanya.
Untuk lebih jelasnya, operator Gabung Bergabung (Penggabungan) dalam rencana eksekusi SQL Server tidak melakukan bergabung; mesin hanya menggunakan kembali operator fisik yang sama untuk mengimplementasikan serikat penjaga pesanan semua.
Menulis Rencana Eksekusi di SQL Server
SSIS tidak memiliki bahasa spesifikasi aliran data, atau pengoptimal untuk mengubah spesifikasi tersebut menjadi Tugas Aliran Data yang dapat dijalankan. Terserah desainer paket SSIS untuk menyadari bahwa Penggabungan yang mempertahankan pesanan dimungkinkan, atur properti komponen (seperti kunci pengurutan) dengan tepat, lalu bandingkan kinerjanya. Ini membutuhkan lebih banyak usaha (dan keterampilan) dari pihak desainer, tetapi ini memberikan tingkat kontrol yang sangat baik.
Situasi di SQL Server adalah kebalikannya:kami menulis kueri spesifikasi menggunakan bahasa T-SQL, kemudian bergantung pada pengoptimal kueri untuk mengeksplorasi opsi implementasi dan memilih yang efisien. Kami tidak memiliki opsi untuk menyusun rencana eksekusi secara langsung. Sebagian besar waktu, ini sangat diinginkan:SQL Server tidak diragukan lagi akan menjadi kurang populer jika setiap kueri mengharuskan kita untuk menulis paket gaya SSIS.
Namun demikian (seperti yang dijelaskan dalam posting saya sebelumnya), rencana yang dipilih oleh pengoptimal dapat peka terhadap T-SQL yang digunakan untuk menggambarkan hasil yang diinginkan. Mengulangi contoh dari artikel itu, kita dapat menulis kueri T-SQL asli menggunakan sintaks alternatif:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (870, 873, 921, 712, 707, 711) ORDER BY TransactionID;
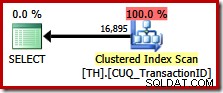
Kueri ini menetapkan hasil yang sama persis seperti sebelumnya, tetapi pengoptimal tidak mempertimbangkan rencana pengawetan pesanan (penggabungan gabungan), sebagai gantinya memilih untuk memindai Clustered Index (opsi yang jauh lebih efisien):
Memanfaatkan Pelestarian Pesanan di SQL Server
Menghindari penyortiran yang tidak perlu dapat menghasilkan peningkatan efisiensi yang signifikan, baik kita berbicara tentang SSIS atau SQL Server. Mencapai tujuan ini dapat menjadi lebih rumit dan sulit di SQL Server karena kita tidak memiliki kendali yang begitu halus atas rencana eksekusi, tetapi masih ada hal-hal yang dapat kita lakukan.
Secara khusus, memahami cara kerja operator SQL Server Merge Join Concatenation secara internal dapat membantu kami untuk terus menulis T-SQL relasional yang jelas, sambil mendorong pengoptimal kueri untuk mempertimbangkan opsi pemrosesan yang mempertahankan pesanan (penggabungan) jika sesuai.
Cara Kerja Merge Join Concatenation

Gabung Gabung biasa membutuhkan kedua input untuk diurutkan pada tombol gabung. Merge Join Concatenation, di sisi lain, cukup menggabungkan dua aliran yang sudah dipesan menjadi satu aliran yang dipesan – tidak ada gabungan, seperti itu.
Ini menimbulkan pertanyaan:apa sebenarnya 'urutan' yang dipertahankan?
Di SSIS, kita harus mengatur properti kunci sortir pada input Gabungkan untuk menentukan urutannya. SQL Server tidak memiliki yang setara dengan ini. Jawaban atas pertanyaan di atas sedikit rumit, jadi kami akan membahasnya selangkah demi selangkah.
Perhatikan contoh berikut, yang meminta penggabungan gabungan dari dua tabel heap yang tidak terindeks (kasus paling sederhana):
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT * FROM @T1 AS T1 UNION ALL SELECT * FROM @T2 AS T2 OPTION (MERGE UNION);
Kedua tabel ini tidak memiliki indeks, dan tidak ada klausa ORDER BY. Urutan apa yang akan 'dipertahankan' gabungan penggabungan bergabung? Untuk memberi Anda waktu sejenak untuk memikirkannya, pertama-tama mari kita lihat rencana eksekusi yang dihasilkan untuk kueri di atas dalam versi SQL Server sebelum 2012:
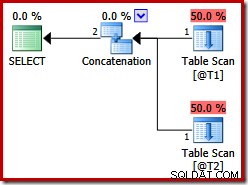
Tidak ada Merge Join Concatenation, meskipun ada petunjuk kueri:sebelum SQL Server 2012, petunjuk ini hanya berfungsi dengan UNION, bukan UNION ALL. Untuk mendapatkan rencana dengan operator gabungan yang diinginkan, kita perlu menonaktifkan implementasi logika UNION ALL (UNIA) menggunakan operator fisik Concatenation (CON). Harap perhatikan bahwa yang berikut ini tidak didokumentasikan dan tidak didukung untuk penggunaan produksi:
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT * FROM @T1 AS T1 UNION ALL SELECT * FROM @T2 AS T2 OPTION (QUERYRULEOFF UNIAtoCON);
Kueri tersebut menghasilkan paket yang sama seperti yang dilakukan SQL Server 2012 dan 2014 dengan petunjuk kueri MERGE UNION saja:
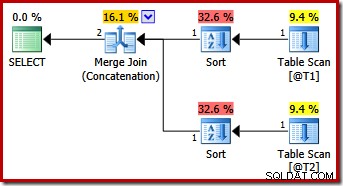
Mungkin secara tidak terduga, rencana eksekusi menampilkan jenis eksplisit pada kedua input ke penggabungan. Properti pengurutan adalah:
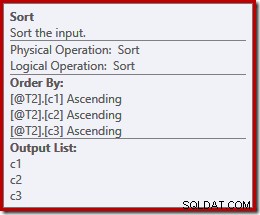
Masuk akal bahwa penggabungan pelestarian pesanan memerlukan urutan input yang konsisten, tetapi mengapa ia memilih (c1, c2, c3) alih-alih, katakanlah (c3, c1, c2) atau (c2, c3, c1)? Sebagai titik awal, input gabungan gabungan diurutkan pada daftar proyeksi output. Bintang-pilih dalam kueri diperluas ke (c1, c2, c3) sehingga urutan yang dipilih.
Urutkan berdasarkan Gabungkan Daftar Proyeksi Keluaran
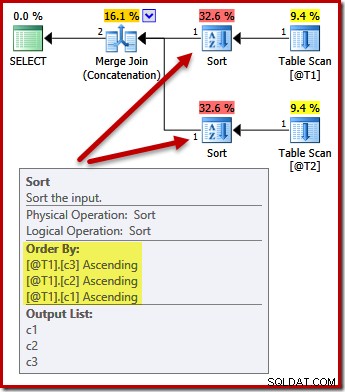
Untuk mengilustrasikan lebih lanjut, kita dapat memperluas sendiri bintang-pilih (sebagaimana seharusnya!) memilih urutan yang berbeda (c3, c2, c1) saat kita melakukannya:
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT c3, c2, c1 FROM @T1 AS T1 UNION ALL SELECT c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
Jenis sekarang berubah menjadi cocok (c3, c2, c1):
Sekali lagi, kueri keluaran order (dengan asumsi kami menambahkan beberapa data ke tabel) tidak dijamin akan diurutkan seperti yang ditunjukkan, karena kami tidak memiliki klausa ORDER BY. Contoh-contoh ini dimaksudkan hanya untuk menunjukkan bagaimana pengoptimal memilih urutan pengurutan input awal, tanpa adanya alasan lain untuk mengurutkan.
Urutan Penyortiran yang Bertentangan
Sekarang pertimbangkan apa yang terjadi jika kita meninggalkan daftar proyeksi sebagai (c3, c2, c1) dan menambahkan persyaratan untuk mengurutkan hasil kueri dengan (c1, c2, c3). Apakah input untuk penggabungan akan tetap diurutkan (c3, c2, c1) dengan pengurutan pasca-penggabungan aktif (c1, c2, c3) untuk memenuhi ORDER BY?
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT c3, c2, c1 FROM @T1 AS T1 UNION ALL SELECT c3, c2, c1 FROM @T2 AS T2 ORDER BY c1, c2, c3 OPTION (MERGE UNION);
Tidak. Pengoptimalnya cukup pintar untuk menghindari pengurutan dua kali:
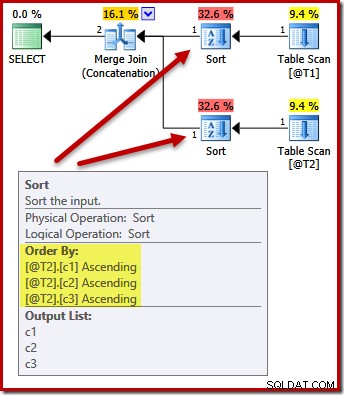
Mengurutkan kedua input pada (c1, c2, c3) dapat diterima dengan baik oleh penggabungan gabungan, jadi tidak diperlukan pengurutan ganda.
Perhatikan bahwa rencana ini berhasil menjamin bahwa urutan hasil akan (c1, c2, c3). Rencana tersebut terlihat sama dengan rencana sebelumnya tanpa ORDER BY, tetapi tidak semua detail internal disajikan dalam rencana eksekusi yang dapat dilihat pengguna.
Efek keunikan
Saat memilih urutan pengurutan untuk input gabungan, pengoptimal juga dipengaruhi oleh jaminan keunikan apa pun yang ada. Perhatikan contoh berikut, dengan lima kolom, tetapi perhatikan urutan kolom yang berbeda dalam operasi UNION ALL:
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
Rencana eksekusi mencakup pengurutan pada (c5, c1, c2, c4, c3) untuk tabel @T1 dan (c5, c4, c3, c2, c1) untuk tabel @T2:
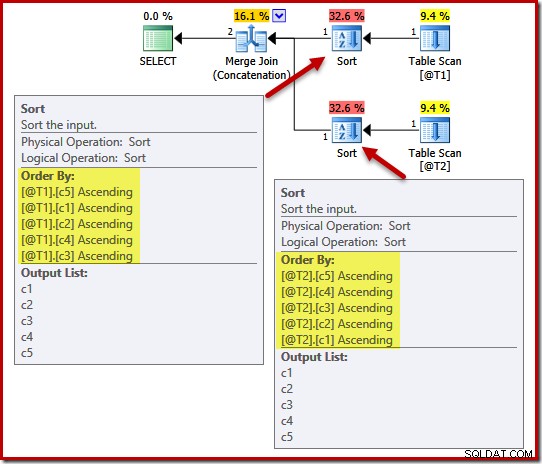
Untuk mendemonstrasikan efek keunikan pada jenis ini, kami akan menambahkan batasan UNIK ke kolom c1 pada tabel T1, dan kolom c4 pada tabel T2:
DECLARE @T1 AS TABLE (c1 int UNIQUE, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int UNIQUE, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
Intinya tentang keunikan adalah bahwa pengoptimal tahu bahwa ia dapat berhenti menyortir segera setelah menemukan kolom yang dijamin unik. Pengurutan menurut kolom tambahan setelah kunci unik ditemukan tidak akan memengaruhi urutan pengurutan akhir, menurut definisi.
Dengan adanya batasan UNIK, pengoptimal dapat menyederhanakan daftar pengurutan (c5, c1, c2, c4, c3) untuk T1 hingga (c5, c1) karena c1 unik. Demikian pula, daftar pengurutan (c5, c4, c3, c2, c1) untuk T2 disederhanakan menjadi (c5, c4) karena c4 adalah kunci:
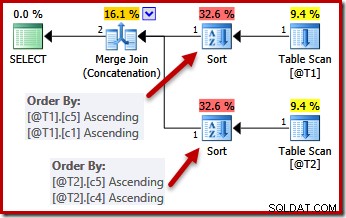
Paralelisme
Penyederhanaan karena kunci unik tidak diterapkan dengan sempurna. Dalam rencana paralel, aliran dipartisi sehingga semua baris untuk instance gabungan yang sama berakhir di utas yang sama. Partisi kumpulan data ini didasarkan pada kolom gabungan, dan tidak disederhanakan dengan adanya kunci.
Skrip berikut menggunakan tanda pelacakan yang tidak didukung 8649 untuk menghasilkan paket paralel untuk kueri sebelumnya (yang sebaliknya tidak akan diubah):
DECLARE @T1 AS TABLE (c1 int UNIQUE, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int UNIQUE, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION, QUERYTRACEON 8649);
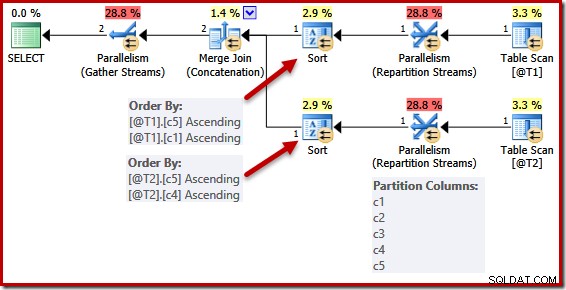
Daftar pengurutan disederhanakan seperti sebelumnya, tetapi operator Aliran Ulang Partisi masih mempartisi semua kolom. Jika penyederhanaan ini diterapkan secara konsisten, operator partisi ulang juga akan beroperasi pada (c5, c1) dan (c5, c4) saja.
Masalah dengan indeks non-unik
Alasan pengoptimal tentang persyaratan penyortiran untuk penggabungan gabungan dapat mengakibatkan masalah pengurutan yang tidak perlu, seperti yang ditunjukkan contoh berikut:
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE CLUSTERED INDEX cx ON #T1 (c1); CREATE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1 OPTION (MERGE UNION); DROP TABLE #T1, #T2;
Melihat kueri dan indeks yang tersedia, kami mengharapkan rencana eksekusi yang melakukan pemindaian berurutan dari indeks berkerumun, menggunakan penggabungan gabungan gabungan untuk menghindari perlunya penyortiran apa pun. Harapan ini sepenuhnya dibenarkan, karena indeks berkerumun memberikan urutan yang ditentukan dalam klausa ORDER BY. Sayangnya, paket yang kami dapatkan sebenarnya mencakup dua jenis:
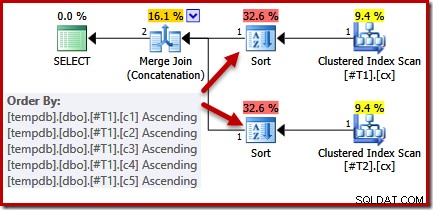
Tidak ada alasan bagus untuk jenis ini, mereka hanya muncul karena logika pengoptimal kueri tidak sempurna. Daftar kolom keluaran gabungan (c1, c2, c3, c4, c5) adalah superset dari ORDER BY, tetapi tidak ada unik kunci untuk menyederhanakan daftar itu. Sebagai hasil dari kesenjangan dalam alasan pengoptimal ini, disimpulkan bahwa penggabungan memerlukan input yang diurutkan pada (c1, c2, c3, c4, c5).
Kami dapat memverifikasi analisis ini dengan memodifikasi skrip untuk membuat salah satu indeks berkerumun menjadi unik:
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE CLUSTERED INDEX cx ON #T1 (c1); CREATE UNIQUE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1 OPTION (MERGE UNION); DROP TABLE #T1, #T2;
Rencana eksekusi sekarang hanya memiliki pengurutan di atas tabel dengan indeks non-unik:
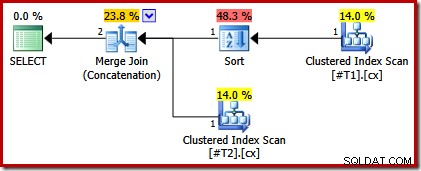
Jika sekarang kita membuat keduanya indeks berkerumun unik, tidak ada jenis yang muncul:
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE UNIQUE CLUSTERED INDEX cx ON #T1 (c1); CREATE UNIQUE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1; DROP TABLE #T1, #T2;
Dengan kedua indeks yang unik, daftar pengurutan input gabungan awal dapat disederhanakan menjadi kolom c1 saja. Daftar yang disederhanakan kemudian sama persis dengan klausa ORDER BY, jadi tidak diperlukan pengurutan dalam rencana akhir:
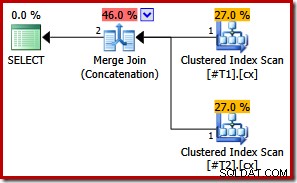
Perhatikan bahwa kita bahkan tidak memerlukan petunjuk kueri dalam contoh terakhir ini untuk mendapatkan rencana eksekusi yang optimal.
Pemikiran Akhir
Menghilangkan jenis dalam rencana eksekusi bisa jadi rumit. Dalam beberapa kasus, ini bisa sesederhana memodifikasi indeks yang ada (atau menyediakan yang baru) untuk mengirimkan baris dalam urutan yang diperlukan. Pengoptimal kueri melakukan pekerjaan yang wajar secara keseluruhan bila indeks yang sesuai tersedia.
Namun, dalam (banyak) kasus lain, menghindari pengurutan dapat memerlukan pemahaman yang lebih mendalam tentang mesin eksekusi, pengoptimal kueri, dan operator rencana itu sendiri. Menghindari penyortiran tidak diragukan lagi merupakan topik penyetelan kueri tingkat lanjut, tetapi juga topik yang sangat bermanfaat ketika semuanya berjalan dengan benar.