Bagian penting dari penyetelan kueri adalah memahami algoritme yang tersedia bagi pengoptimal untuk menangani berbagai konstruksi kueri, misalnya, memfilter, menggabungkan, mengelompokkan dan menggabungkan, dan bagaimana skalanya. Pengetahuan ini membantu Anda mempersiapkan lingkungan fisik yang optimal untuk kueri Anda, seperti membuat indeks yang tepat. Ini juga membantu Anda secara intuitif merasakan algoritme mana yang harus Anda lihat dalam rencana dalam serangkaian keadaan tertentu, berdasarkan keakraban Anda dengan ambang batas di mana pengoptimal harus beralih dari satu algoritme ke algoritme lainnya. Kemudian, saat menyetel kueri berperforma buruk, Anda dapat lebih mudah menemukan area dalam rencana kueri tempat pengoptimal mungkin membuat pilihan suboptimal, misalnya karena perkiraan kardinalitas yang tidak akurat, dan mengambil tindakan untuk memperbaikinya.
Bagian penting lainnya dari penyetelan kueri adalah berpikir di luar kebiasaan — di luar algoritme yang tersedia untuk pengoptimal saat menggunakan alat yang jelas. Jadilah kreatif. Katakanlah Anda memiliki kueri yang berkinerja buruk meskipun Anda mengatur lingkungan fisik yang optimal. Untuk konstruksi kueri yang Anda gunakan, algoritme yang tersedia untuk pengoptimal adalah x, y, dan z, dan pengoptimal memilih yang terbaik dalam situasi tersebut. Namun, kueri berkinerja buruk. Dapatkah Anda membayangkan rencana teoretis dengan algoritme yang dapat menghasilkan kueri dengan kinerja yang jauh lebih baik? Jika Anda dapat membayangkannya, kemungkinan besar Anda akan dapat mencapainya dengan beberapa penulisan ulang kueri, mungkin dengan konstruksi kueri yang kurang jelas untuk tugas tersebut.
Dalam rangkaian artikel ini, saya fokus pada pengelompokan dan pengumpulan data. Saya akan mulai dengan membahas algoritme yang tersedia untuk pengoptimal saat menggunakan kueri yang dikelompokkan. Saya kemudian akan menjelaskan skenario di mana tidak ada algoritme yang ada yang bekerja dengan baik dan menunjukkan penulisan ulang kueri yang menghasilkan kinerja dan penskalaan yang sangat baik.
Saya ingin mengucapkan terima kasih kepada Craig Freedman, Vassilis Papadimos, dan Joe Sack, anggota gabungan kumpulan orang terpintar di planet ini dan kumpulan pengembang SQL Server, untuk menjawab pertanyaan saya tentang pengoptimalan kueri!
Untuk contoh data saya akan menggunakan database yang disebut PerformanceV3. Anda dapat mengunduh skrip untuk membuat dan mengisi database dari sini. Saya akan menggunakan tabel bernama dbo.Orders, yang diisi dengan 1.000.000 baris. Tabel ini memiliki beberapa indeks yang tidak diperlukan dan dapat mengganggu contoh saya, jadi jalankan kode berikut untuk menghapus indeks yang tidak diperlukan itu:
DROP INDEX idx_nc_sid_od_cid ON dbo.Orders; DROP INDEX idx_unc_od_oid_i_cid_eid ON dbo.Orders;
Hanya dua indeks yang tersisa di tabel ini adalah indeks berkerumun yang disebut idx_cl_od pada kolom orderdate, dan indeks unik nonclustered yang disebut PK_Orders pada kolom orderid, yang memberlakukan batasan kunci utama.
EXEC sys.sp_helpindex 'dbo.Orders';
index_name index_description index_keys ----------- ----------------------------------------------------- ----------- idx_cl_od clustered located on PRIMARY orderdate PK_Orders nonclustered, unique, primary key located on PRIMARY orderid
Algoritme yang ada
SQL Server mendukung dua algoritme utama untuk menggabungkan data:Stream Aggregate dan Hash Aggregate. Dengan kueri yang dikelompokkan, algoritme Stream Agregat mengharuskan data diurutkan berdasarkan kolom yang dikelompokkan, jadi Anda perlu membedakan antara dua kasus. Salah satunya adalah Stream Aggregate yang telah dipesan sebelumnya, misalnya, ketika data diperoleh dipesan sebelumnya dari indeks. Lainnya adalah Stream Aggregate yang tidak dipesan sebelumnya, di mana langkah ekstra diperlukan untuk mengurutkan input secara eksplisit. Kedua kasus ini memiliki skala yang sangat berbeda sehingga sebaiknya Anda menganggapnya sebagai dua algoritme yang berbeda.
Algoritma Hash Aggregate mengatur grup dan agregatnya dalam tabel hash. Itu tidak memerlukan input untuk dipesan.
Dengan data yang cukup, pengoptimal mempertimbangkan untuk memparalelkan pekerjaan, menerapkan apa yang dikenal sebagai agregat lokal-global. Dalam kasus seperti itu, input dibagi menjadi beberapa utas, dan setiap utas menerapkan salah satu algoritme yang disebutkan di atas untuk mengagregasi subset barisnya secara lokal. Agregat global kemudian menggunakan salah satu algoritme yang disebutkan di atas untuk mengagregasi hasil agregat lokal.
Dalam artikel ini saya fokus pada algoritma Stream Aggregate yang telah dipesan sebelumnya dan penskalaannya. Di bagian mendatang dari seri ini, saya akan membahas algoritme lain dan menjelaskan ambang batas di mana pengoptimal beralih dari satu ke yang lain, dan kapan Anda harus mempertimbangkan penulisan ulang kueri.
Agregat Aliran yang Dipesan di muka
Diberikan kueri yang dikelompokkan dengan kumpulan pengelompokan yang tidak kosong (kumpulan ekspresi yang Anda kelompokkan), algoritme Stream Aggregate mengharuskan baris input diurutkan berdasarkan ekspresi yang membentuk kumpulan pengelompokan. Ketika algoritme memproses baris pertama dalam grup, algoritme menginisialisasi anggota yang memegang nilai agregat menengah dengan nilai yang relevan (mis., nilai baris pertama untuk agregat MAX). Ketika memproses baris bukan pertama dalam grup, ia menetapkan anggota itu dengan hasil perhitungan yang melibatkan nilai agregat antara dan nilai baris baru (misalnya, maksimum antara nilai agregat menengah dan nilai baru). Segera setelah salah satu anggota kumpulan pengelompokan mengubah nilainya, atau input dikonsumsi, nilai agregat saat ini dianggap sebagai hasil akhir untuk grup terakhir.
Salah satu cara agar data diurutkan seperti yang dibutuhkan oleh algoritma Stream Aggregate adalah dengan mendapatkannya diurutkan sebelumnya dari indeks. Anda memerlukan indeks untuk didefinisikan dengan kolom kumpulan pengelompokan sebagai kunci—dalam urutan apa pun di antaranya. Anda juga ingin indeks mencakup. Misalnya, pertimbangkan kueri berikut (kami akan menyebutnya Kueri 1):
SELECT shipperid, MAX(orderdate) AS maxorderid FROM dbo.Orders GROUP BY shipperid;
Indeks rowstore yang optimal untuk mendukung kueri ini akan didefinisikan dengan shipperid sebagai kolom kunci utama, dan tanggal pemesanan sebagai kolom yang disertakan, atau sebagai kolom kunci kedua:
CREATE INDEX idx_sid_od ON dbo.Orders(shipperid, orderdate);
Dengan indeks ini, Anda mendapatkan perkiraan paket yang ditunjukkan pada Gambar 1 (menggunakan SentryOne Plan Explorer).

Gambar 1:Rencana untuk Kueri 1
Perhatikan bahwa operator Pemindaian Indeks memiliki properti Dipesan:Benar yang menandakan bahwa ia diharuskan untuk mengirimkan baris yang diurutkan oleh kunci indeks. Operator Stream Aggregate kemudian menyerap baris yang diurutkan sesuai kebutuhan. Adapun bagaimana biaya operator dihitung; sebelum kita sampai ke itu, kata pengantar singkat dulu…
Seperti yang mungkin sudah Anda ketahui, ketika SQL Server mengoptimalkan kueri, ia mengevaluasi beberapa rencana kandidat, dan akhirnya memilih satu dengan perkiraan biaya terendah. Perkiraan biaya paket adalah jumlah dari semua perkiraan biaya operator. Pada gilirannya, perkiraan biaya setiap operator adalah jumlah dari perkiraan biaya I/O dan perkiraan biaya CPU. Unit biaya tidak ada artinya dalam dirinya sendiri. Relevansinya adalah dalam perbandingan yang dibuat oleh pengoptimal antara rencana kandidat. Artinya, formula penetapan biaya dirancang dengan tujuan bahwa, di antara rencana kandidat, rencana dengan biaya terendah (semoga) mewakili rencana yang akan selesai lebih cepat. Tugas yang sangat rumit untuk dilakukan dengan akurat!
Semakin formula penetapan biaya secara memadai memperhitungkan faktor-faktor yang benar-benar memengaruhi kinerja dan penskalaan algoritme, semakin akurat mereka, dan semakin besar kemungkinan yang diberikan perkiraan kardinalitas yang akurat, pengoptimal akan memilih rencana yang optimal. Bagaimanapun, jika Anda ingin memahami mengapa pengoptimal memilih satu algoritme versus algoritme lain, Anda perlu memahami dua hal utama:satu adalah cara kerja dan skala algoritme, dan yang lainnya adalah model penetapan biaya SQL Server.
Jadi kembali ke rencana pada Gambar 1; mari kita coba dan pahami bagaimana biaya dihitung. Sebagai kebijakan, Microsoft tidak akan mengungkapkan rumus internal costing yang mereka gunakan. Ketika saya masih kecil, saya tertarik dengan hal-hal yang terpisah. Jam tangan, radio, kaset (ya, saya setua itu), sebut saja. Saya ingin tahu bagaimana hal-hal dibuat. Demikian pula, saya melihat nilai dalam merekayasa balik formula karena jika saya berhasil memprediksi biaya dengan cukup akurat, itu mungkin berarti saya memahami algoritme dengan baik. Selama proses tersebut, Anda bisa belajar banyak.
Kueri kami menyerap 1.000.000 baris. Bahkan dengan jumlah baris ini, biaya I/O tampaknya dapat diabaikan dibandingkan dengan biaya CPU, jadi mungkin aman untuk mengabaikannya.
Adapun biaya CPU, Anda ingin mencoba dan mencari tahu faktor mana yang mempengaruhinya dan dengan cara apa. Secara teoritis mungkin ada beberapa faktor:jumlah baris input, jumlah grup, kardinalitas himpunan pengelompokan, tipe data dan ukuran anggota himpunan pengelompokan. Jadi, untuk mencoba dan mengukur pengaruh salah satu faktor ini, Anda ingin membandingkan perkiraan biaya dari dua kueri yang hanya berbeda dalam faktor yang ingin Anda ukur. Misalnya, untuk mengukur dampak jumlah baris pada biaya, miliki dua kueri dengan jumlah baris input yang berbeda, tetapi dengan semua aspek lain yang sama (jumlah grup, kardinalitas himpunan pengelompokan, dll.). Selain itu, penting untuk memverifikasi bahwa perkiraan angka—bukan yang sebenarnya—adalah angka yang diinginkan karena pengoptimal bergantung pada perkiraan angka untuk menghitung biaya.
Saat melakukan perbandingan seperti itu, ada baiknya memiliki teknik yang memungkinkan Anda untuk sepenuhnya mengontrol angka perkiraan. Misalnya, cara sederhana untuk mengontrol perkiraan jumlah baris input adalah dengan membuat kueri ekspresi tabel yang didasarkan pada kueri TOP dan menerapkan fungsi agregat di kueri luar. Jika Anda khawatir karena penggunaan operator TOP Anda, pengoptimal akan menerapkan sasaran baris, dan itu akan menghasilkan penyesuaian biaya awal, ini hanya berlaku untuk operator yang muncul dalam paket di bawah operator Top (untuk kanan), bukan di atas (ke kiri). Operator Stream Aggregate secara alami muncul di atas operator Top dalam rencana karena menyerap baris yang difilter.
Untuk mengontrol perkiraan jumlah grup keluaran, Anda dapat melakukannya dengan menggunakan ekspresi pengelompokan
Untuk memastikan bahwa Anda mendapatkan algoritme Stream Agregat dan paket serial, Anda dapat memaksanya dengan petunjuk kueri:OPTION(ORDER GROUP, MAXDOP 1).
Anda juga ingin mengetahui apakah ada biaya awal untuk operator sehingga Anda dapat memperhitungkannya dalam formula rekayasa balik Anda.
Mari kita mulai dengan mencari tahu bagaimana jumlah baris input memengaruhi perkiraan biaya CPU operator. Jelas, faktor ini harus relevan dengan biaya operator. Selain itu, Anda mengharapkan biaya per baris konstan. Berikut adalah beberapa kueri untuk perbandingan yang hanya berbeda dalam perkiraan jumlah baris input (sebutkan masing-masing Kueri 2 dan Kueri 3):
SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1); SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1);
Gambar 2 memiliki bagian yang relevan dari perkiraan rencana untuk kueri ini:

Gambar 2:Rencana untuk Kueri 2 dan Kueri 3
Dengan asumsi biaya per baris konstan, Anda dapat menghitungnya sebagai perbedaan antara biaya operator dibagi dengan perbedaan antara kardinalitas input operator:
CPU cost per row = (0.125 - 0.065) / (200000 - 100000) = 0.0000006
Untuk memverifikasi bahwa angka yang Anda dapatkan memang konstan dan benar, Anda dapat mencoba dan memprediksi perkiraan biaya dalam kueri dengan jumlah baris input lainnya. Misalnya, perkiraan biaya dengan 500.000 baris input adalah:
Cost for 500K input rows = <cost for 100K input rows> + 400000 * 0.0000006 = 0.065 + 0.24 = 0.305
Gunakan kueri berikut untuk memeriksa apakah prediksi Anda akurat (sebut saja Kueri 4):
SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1);
Bagian yang relevan dari rencana untuk kueri ini ditunjukkan pada Gambar 3.
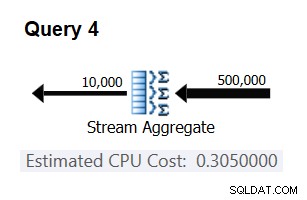
Gambar 3:Rencana untuk Kueri 4
Bingo. Secara alami, ada baiknya untuk memeriksa beberapa kardinalitas input tambahan. Dengan semua yang saya periksa, tesis bahwa ada biaya konstan per baris input 0,0000006 benar.
Selanjutnya, mari kita coba mencari tahu bagaimana perkiraan jumlah grup memengaruhi biaya CPU operator. Anda mengharapkan beberapa pekerjaan CPU diperlukan untuk memproses setiap grup, dan juga masuk akal untuk mengharapkannya konstan per grup. Untuk menguji tesis ini dan menghitung biaya per grup, Anda dapat menggunakan dua kueri berikut, yang hanya berbeda dalam jumlah grup hasil (sebut saja Kueri 5 dan Kueri 6 secara berurutan):
SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1); SELECT orderid % 20000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 20000 OPTION(ORDER GROUP, MAXDOP 1);
Bagian yang relevan dari perkiraan rencana kueri ditunjukkan pada Gambar 4.
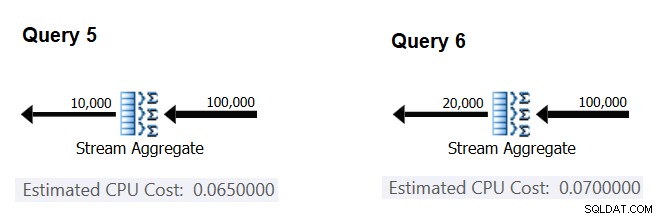
Gambar 4:Rencana untuk Query 5 dan Query 6
Mirip dengan cara Anda menghitung biaya tetap per baris input, Anda dapat menghitung biaya tetap per grup output sebagai perbedaan antara biaya operator dibagi dengan perbedaan antara kardinalitas output operator:
CPU cost per group = (0.07 - 0.065) / (20000 - 10000) = 0.0000005
Dan seperti yang saya tunjukkan sebelumnya, Anda dapat memverifikasi temuan Anda dengan memprediksi biaya dengan jumlah grup keluaran lain dan membandingkan angka prediksi Anda dengan yang dihasilkan oleh pengoptimal. Dengan semua jumlah grup yang saya coba, perkiraan biayanya akurat.
Dengan menggunakan teknik serupa, Anda dapat memeriksa apakah ada faktor lain yang memengaruhi biaya operator. Pengujian saya menunjukkan bahwa kardinalitas kumpulan pengelompokan (jumlah ekspresi yang Anda kelompokkan), tipe data dan ukuran ekspresi yang dikelompokkan tidak berdampak pada perkiraan biaya.
Yang tersisa adalah memeriksa apakah ada biaya awal yang berarti yang ditanggung oleh operator. Jika ada, rumus (semoga) lengkap untuk menghitung biaya CPU operator adalah:
Operator CPU cost = <startup cost> + <#input rows> * 0.0000006 + <#output groups> * 0.0000005
Jadi, Anda dapat memperoleh biaya awal dari yang lain:
Startup cost =- (<#input rows> * 0.0000006 + <#output groups> * 0.0000005)
Anda dapat menggunakan rencana kueri apa pun dari artikel ini untuk tujuan ini. Misalnya, dengan menggunakan angka-angka dari rencana untuk Kueri 5 yang ditunjukkan sebelumnya pada Gambar 4, Anda mendapatkan:
Startup cost = 0.065 - (100000 * 0.0000006 + 10000 * 0.0000005) = 0
Seperti yang terlihat, operator Stream Aggregate tidak memiliki biaya startup terkait CPU, atau sangat rendah sehingga tidak ditampilkan dengan presisi ukuran biaya.
Kesimpulannya, rumus rekayasa balik untuk biaya operator Agregat Aliran adalah:
I/O cost: negligible CPU cost: <#input rows> * 0.0000006 + <#output groups> * 0.0000005
Gambar 5 menggambarkan penskalaan biaya operator Stream Aggregate sehubungan dengan jumlah baris dan jumlah grup.
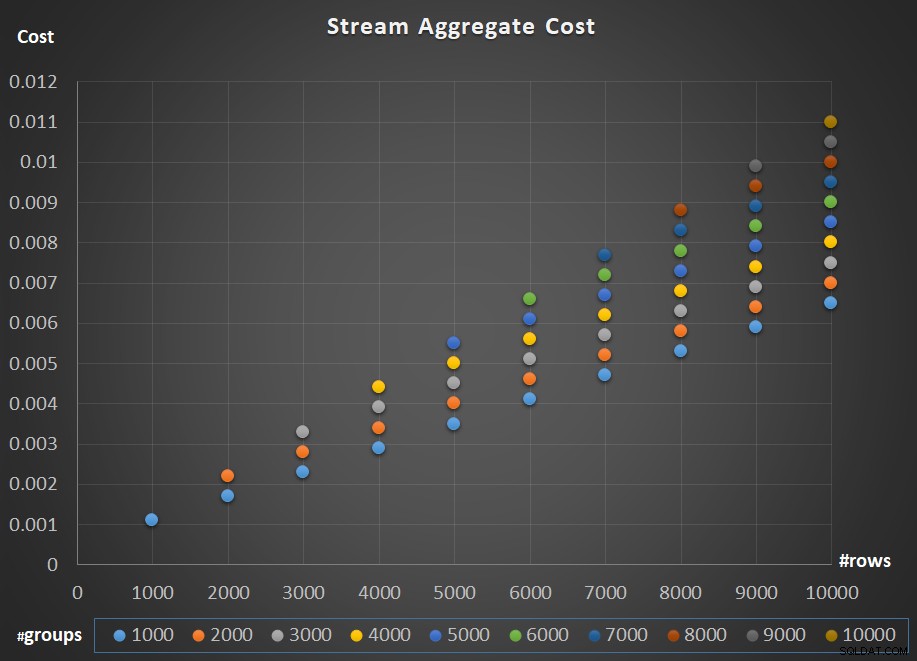
Gambar 5:Bagan penskalaan algoritma Agregat Aliran
Adapun penskalaan operator; itu linier. Dalam kasus di mana jumlah grup cenderung sebanding dengan jumlah baris, seluruh biaya operator meningkat dengan faktor yang sama dengan peningkatan jumlah baris dan grup. Artinya, menggandakan jumlah baris input dan grup input menghasilkan dua kali lipat biaya seluruh operator. Untuk mengetahui alasannya, misalkan kami menyatakan biaya operator sebagai:
r * 0.0000006 + g * 0.0000005
Jika Anda menambah jumlah baris dan jumlah grup dengan faktor p yang sama, Anda mendapatkan:
pr * 0.0000006 + pg * 0.0000005 = p * (r * 0.0000006 + g * 0.0000005)
Jadi jika, untuk sejumlah baris dan grup tertentu, biaya operator Stream Aggregate adalah C, meningkatkan jumlah baris dan grup dengan faktor p yang sama menghasilkan biaya operator pC. Lihat apakah Anda dapat memverifikasi ini dengan mengidentifikasi contoh dalam bagan di Gambar 5.
Dalam kasus di mana jumlah grup tetap cukup stabil bahkan ketika jumlah baris input bertambah, Anda masih mendapatkan penskalaan linier. Anda hanya mempertimbangkan biaya yang terkait dengan jumlah grup sebagai konstan. Artinya, jika untuk sejumlah baris dan grup tertentu, biaya operatornya adalah C =G (biaya yang terkait dengan jumlah grup) ditambah R (biaya yang terkait dengan jumlah baris), hanya menambah jumlah baris dengan faktor p menghasilkan G + pR. Dalam kasus seperti itu, tentu saja, seluruh biaya operator kurang dari pc. Artinya, menggandakan jumlah baris menghasilkan kurang dari dua kali lipat biaya seluruh operator.
Dalam praktiknya, dalam banyak kasus saat Anda mengelompokkan data, jumlah baris input jauh lebih besar daripada jumlah grup output. Fakta ini, ditambah dengan fakta bahwa alokasi biaya per baris dan biaya per grup hampir sama, porsi biaya operator yang dikaitkan dengan jumlah grup menjadi tidak berarti. Sebagai contoh, lihat rencana untuk Kueri 1 yang ditunjukkan sebelumnya pada Gambar 1. Dalam kasus seperti itu, aman untuk menganggap biaya operator hanya sebagai penskalaan linier sehubungan dengan jumlah baris input.
Kasus khusus
Ada kasus khusus di mana operator Stream Aggregate tidak memerlukan data yang diurutkan sama sekali. Jika Anda memikirkannya, algoritme Stream Aggregate memiliki persyaratan pengurutan yang lebih santai dari input dibandingkan saat Anda memerlukan data yang dipesan untuk tujuan presentasi, misalnya, ketika kueri memiliki klausa ORDER BY presentasi luar. Algoritme Stream Aggregate hanya membutuhkan semua baris dari grup yang sama untuk diurutkan bersama. Ambil set input {5, 1, 5, 2, 1, 2}. Untuk tujuan pengurutan presentasi, himpunan ini harus diurutkan seperti ini:1, 1, 2, 2, 5, 5. Untuk tujuan agregasi, algoritma Stream Aggregate akan tetap bekerja dengan baik jika data disusun dalam urutan berikut:5, 5, 1, 1, 2, 2. Dengan mengingat hal ini, saat Anda menghitung agregat skalar (kueri dengan fungsi agregat dan tidak ada klausa GROUP BY), atau mengelompokkan data dengan kumpulan pengelompokan kosong, tidak akan pernah ada lebih dari satu grup . Terlepas dari urutan baris input, algoritma Stream Aggregate dapat diterapkan. Algoritme Hash Aggregate melakukan hash pada data berdasarkan ekspresi kumpulan pengelompokan sebagai input, dan baik dengan agregat skalar maupun dengan kumpulan pengelompokan kosong, tidak ada input untuk di-hash. Jadi, baik dengan agregat skalar dan dengan agregat yang diterapkan ke kumpulan pengelompokan kosong, pengoptimal selalu menggunakan algoritme Stream Aggregate, tanpa mengharuskan data diurutkan sebelumnya. Setidaknya itulah yang terjadi dalam mode eksekusi baris, karena saat ini (pada SQL Server 2017 CU4) mode batch hanya tersedia dengan algoritma Hash Aggregate. Saya akan menggunakan dua kueri berikut untuk mendemonstrasikan ini (sebut saja Kueri 7 dan Kueri 8):
SELECT COUNT(*) AS numrows FROM dbo.Orders; SELECT COUNT(*) AS numrows FROM dbo.Orders GROUP BY ();
Rencana untuk kueri ini ditunjukkan pada Gambar 6.
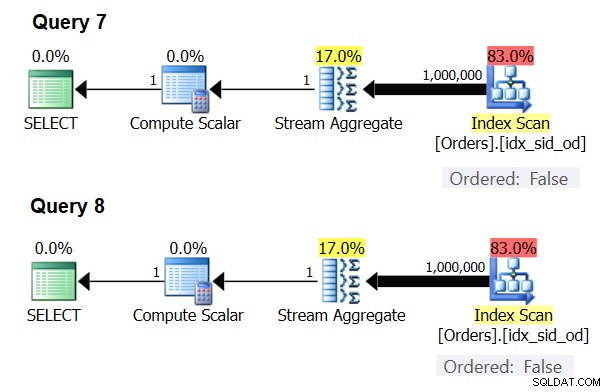
Gambar 6:Rencana untuk Query 7 dan Query 8
Coba paksa algoritma Hash Aggregate dalam kedua kasus:
SELECT COUNT(*) AS numrows FROM dbo.Orders OPTION(HASH GROUP); SELECT COUNT(*) AS numrows FROM dbo.Orders GROUP BY () OPTION(HASH GROUP);
Pengoptimal mengabaikan permintaan Anda dan menghasilkan paket yang sama seperti yang ditunjukkan pada Gambar 6.
Kuis cepat:apa perbedaan antara agregat skalar dan agregat yang diterapkan ke kumpulan pengelompokan kosong?
Jawaban:dengan set input kosong, agregat skalar mengembalikan hasil dengan satu baris, sedangkan agregat dalam kueri dengan set pengelompokan kosong mengembalikan set hasil kosong. Cobalah:
SELECT COUNT(*) AS numrows FROM dbo.Orders WHERE 1 = 2;
numrows ----------- 0 (1 row affected)
SELECT COUNT(*) AS numrows FROM dbo.Orders WHERE 1 = 2 GROUP BY ();
numrows ----------- (0 rows affected)
Setelah selesai, jalankan kode berikut untuk pembersihan:
DROP INDEX idx_sid_od ON dbo.Orders;
Ringkasan dan tantangan
Merekayasa balik formula penetapan biaya untuk algoritma Stream Aggregate adalah permainan anak-anak. Saya bisa saja memberi tahu Anda bahwa rumus penetapan biaya untuk algoritme Stream Aggregate yang telah dipesan sebelumnya adalah @numrows * 0,0000006 + @numgroups * 0,0000005 alih-alih seluruh artikel untuk menjelaskan bagaimana Anda mengetahuinya. Intinya, bagaimanapun, adalah untuk menggambarkan proses dan prinsip-prinsip rekayasa balik, sebelum beralih ke algoritma yang lebih kompleks dan ambang batas di mana satu algoritma menjadi lebih optimal daripada yang lain. Mengajari Anda cara memancing alih-alih memberi Anda jenis ikan. Saya telah belajar banyak, dan menemukan hal-hal yang bahkan belum pernah saya pikirkan, ketika mencoba merekayasa balik rumus penetapan biaya untuk berbagai algoritme.
Siap menguji kemampuan Anda? Misi Anda, jika Anda memilih untuk menerimanya, lebih sulit daripada merekayasa balik operator Stream Aggregate. Merekayasa balik rumus penetapan biaya dari operator Sortir serial. Ini penting untuk penelitian kami karena algoritme Stream Aggregate diterapkan untuk kueri dengan kumpulan pengelompokan yang tidak kosong, di mana data input tidak dipesan sebelumnya, memerlukan penyortiran eksplisit. Dalam kasus seperti itu, biaya dan penskalaan operasi agregat bergantung pada biaya dan penskalaan gabungan operator Sort dan Stream Aggregate.
Jika Anda berhasil mendekati prediksi biaya operator Sortir, Anda dapat merasa bahwa Anda berhak untuk menambahkan tanda tangan Anda “Reverse Engineer.” Ada banyak insinyur perangkat lunak di luar sana; tetapi Anda tentu tidak melihat banyak reverse engineer! Pastikan untuk menguji rumus Anda baik dengan angka kecil maupun dengan angka besar; Anda mungkin akan terkejut dengan apa yang Anda temukan.