Dalam posting terakhir saya ("Bung, siapa yang memiliki tabel #temp itu?"), Saya menyarankan bahwa di SQL Server 2012 dan di atasnya, Anda dapat menggunakan Acara yang Diperpanjang untuk memantau pembuatan tabel #temp. Ini akan memungkinkan Anda untuk menghubungkan objek tertentu yang menghabiskan banyak ruang di tempdb dengan sesi yang membuatnya (misalnya, untuk menentukan apakah sesi dapat dimatikan untuk mencoba mengosongkan ruang). Yang tidak saya diskusikan adalah overhead pelacakan ini – kami berharap Peristiwa yang Diperpanjang lebih ringan daripada pelacakan, tetapi tidak ada pemantauan yang sepenuhnya gratis.
Karena kebanyakan orang membiarkan jejak default diaktifkan, kami akan membiarkannya di tempatnya. Kami akan menguji kedua heap menggunakan SELECT INTO (yang tidak akan dikumpulkan oleh pelacakan default) dan indeks berkerumun (yang akan dikumpulkan), dan kami akan mengatur waktu batch sendiri sebagai baseline, lalu menjalankan batch lagi dengan sesi Acara yang Diperpanjang berjalan. Kami juga akan menguji SQL Server 2012 dan SQL Server 2014. Kumpulan itu sendiri cukup sederhana:
ATUR NOCOUNT AKTIF; SELECT SYSDATETIME();GO -- jalankan bagian ini hanya untuk tumpukan tumpukan:SELECT TOP (100) [object_id] INTO #foo FROM sys.all_objects ORDER BY [object_id];DROP TABLE #foo; -- jalankan bagian ini hanya untuk batch CIX:CREATE TABLE #bar(id INT PRIMARY KEY);INSERT #bar(id) SELECT TOP (100) [object_id] FROM sys.all_objects ORDER BY [object_id];DROP TABLE #bar; PERGI 100000 PILIH SYSDATETIME();
Kedua instans memiliki tempdb yang dikonfigurasi dengan empat file data dan dengan TF 1117 dan TF 1118 diaktifkan, dalam VM dengan empat CPU, memori 16GB, dan hanya SSD. Saya sengaja membuat tabel #temp kecil untuk memperkuat dampak yang diamati pada kumpulan itu sendiri (yang akan tenggelam jika membuat tabel #temp memakan waktu lama atau menyebabkan peristiwa pertumbuhan otomatis yang berlebihan).
Saya menjalankan batch ini di setiap skenario, dan inilah hasilnya, diukur dalam durasi batch dalam hitungan detik:
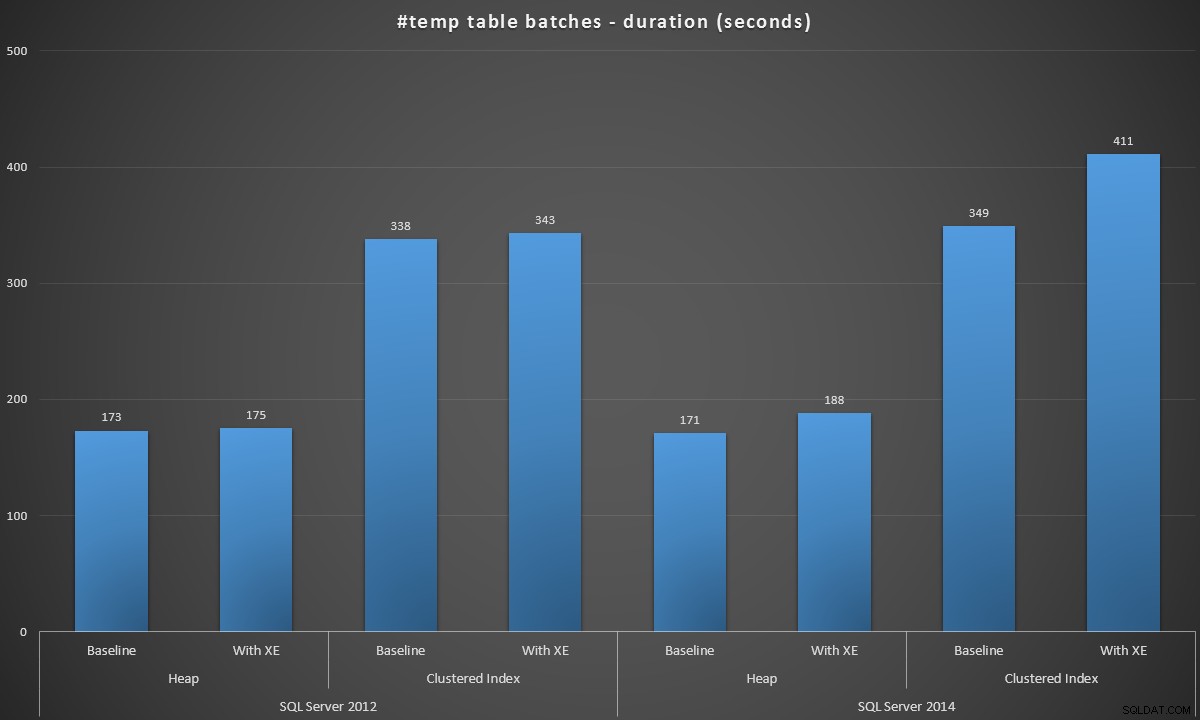
Durasi batch, dalam detik, untuk membuat 100.000 tabel #temp
Mengekspresikan data sedikit berbeda, jika kita membagi 100.000 dengan durasi, kita dapat menunjukkan jumlah tabel #temp yang dapat kita buat per detik di setiap skenario (baca:throughput). Ini dia hasilnya:
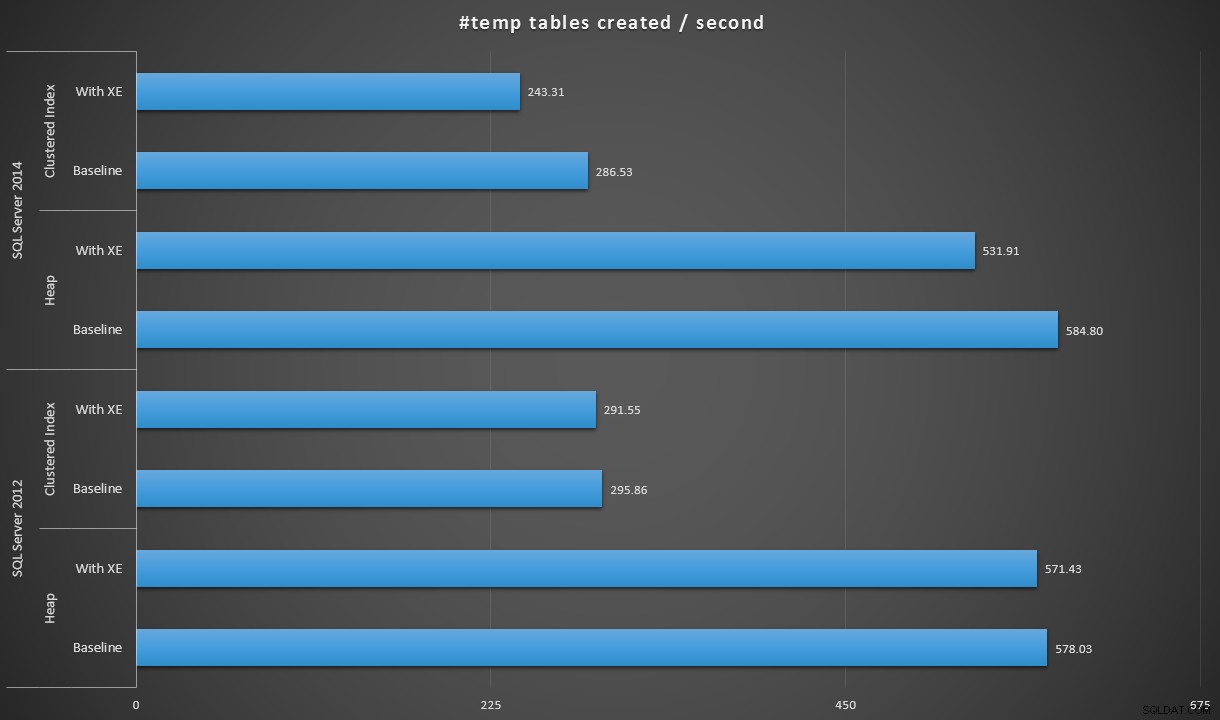
#tabel sementara dibuat per detik di bawah setiap skenario
Hasilnya sedikit mengejutkan bagi saya – saya berharap, dengan perbaikan SQL Server 2014 dalam logika penulisan yang bersemangat, populasi tumpukan setidaknya akan berjalan jauh lebih cepat. Heap pada tahun 2014 adalah dua detik lebih cepat dari tahun 2012 pada konfigurasi baseline, tetapi Extended Events meningkatkan waktunya sedikit (kira-kira meningkat 10% dari baseline); sementara waktu indeks berkerumun sebanding dengan tahun 2012 pada awal, tetapi naik hampir 18% dengan Acara yang Diperpanjang diaktifkan. Pada tahun 2012, delta untuk tumpukan dan indeks berkerumun jauh lebih sederhana – masing-masing 1,1% dan 1,5%. (Dan untuk lebih jelasnya, tidak ada peristiwa pertumbuhan otomatis yang terjadi selama pengujian mana pun.)
Jadi, saya pikir, bagaimana jika saya membuat sesi Acara Diperpanjang yang lebih ramping dan lebih kejam? Tentunya saya dapat menghapus beberapa kolom tindakan tersebut – mungkin saya hanya perlu nama login dan spid, dan dapat mengabaikan nama aplikasi, nama host, dan sql_text yang berpotensi mahal. Mungkin saya bisa menjatuhkan filter tambahan terhadap komit (mengumpulkan dua kali lebih banyak peristiwa, tetapi lebih sedikit CPU yang dihabiskan untuk pemfilteran) dan memungkinkan beberapa kehilangan peristiwa untuk mengurangi potensi dampak pada beban kerja. Sesi yang lebih ramping ini terlihat seperti ini:
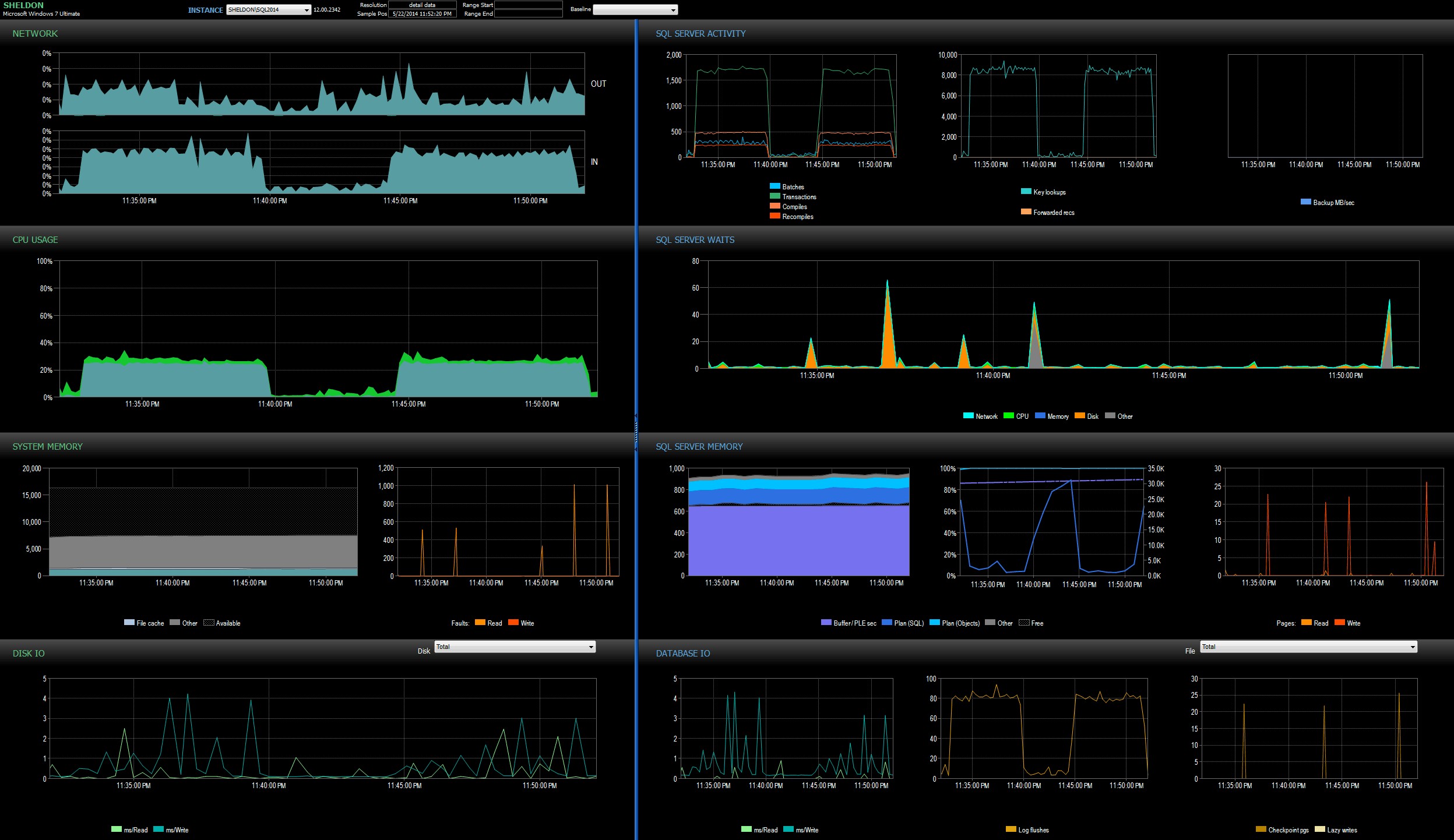
BUAT SESI ACARA [TempTableCreation2014_LeanerMeaner] PADA SERVER ADD EVENT sqlserver.object_created( TINDAKAN ( sqlserver.server_principal_name, sqlserver.session_id ) WHERE ( sqlserver.like_i_sql_unicode_string) TAR_file_unicode_string([object_0%D synchronous_targetfile'#0%D nama file' ( SET FILENAME ='c:\temp\TempTableCreation2014_LeanerMeaner.xel', MAX_FILE_SIZE =32768, MAX_ROLLOVER_FILES =10)DENGAN ( EVENT_RETENTION_MODE =ALLOW_MULTIPLE_EVENT_LOSS);GOALTER EVENT SERTION =STARTERTATEONRESTION SESI awal; Sayangnya, tidak, hasil yang sama. Lebih dari tiga menit untuk tumpukan, dan hanya di bawah tujuh menit untuk indeks berkerumun. Untuk menggali lebih dalam di mana waktu ekstra dihabiskan, saya menonton contoh 2014 dengan SQL Sentry, dan menjalankan hanya kumpulan indeks berkerumun tanpa sesi Acara yang Diperpanjang yang dikonfigurasi. Kemudian saya menjalankan batch lagi, kali ini dengan sesi XE yang lebih ringan dikonfigurasi. Waktu batch adalah 5:47 (347 detik) dan 6:55 (415 detik) – sangat sejalan dengan batch sebelumnya (saya senang melihat bahwa pemantauan kami tidak berkontribusi lebih jauh pada durasi :-)) . Saya memvalidasi bahwa tidak ada peristiwa yang dibatalkan, dan sekali lagi bahwa tidak ada peristiwa pertumbuhan otomatis yang terjadi.Saya melihat dasbor SQL Sentry dalam mode riwayat, yang memungkinkan saya untuk dengan cepat melihat metrik kinerja kedua kumpulan secara berdampingan:
Dasbor SQL Sentry, dalam mode riwayat, menampilkan kedua kumpulanKedua batch hampir identik dalam hal jaringan, CPU, transaksi, kompilasi, pencarian kunci, dll. Ada sedikit perbedaan dalam Menunggu – lonjakan selama batch pertama secara eksklusif WRITELOG, sementara ada beberapa CXPACKET menunggu kecil ditemukan di angkatan kedua. Teori kerja saya setelah tengah malam adalah bahwa mungkin sebagian besar keterlambatan yang diamati disebabkan oleh pengalihan konteks yang disebabkan oleh proses Peristiwa yang Diperpanjang. Karena kami tidak memiliki visibilitas apa pun tentang apa yang dilakukan XE di bawah selimut, kami juga tidak tahu mekanika dasar apa yang telah berubah di XE antara 2012 dan 2014, itulah cerita yang akan saya pertahankan untuk saat ini, sampai saya lebih nyaman dengan xperf dan/atau WinDbg.
Kesimpulan
Bagaimanapun, jelas bahwa pelacakan pembuatan tabel #temp tidak gratis, dan biayanya dapat bervariasi tergantung pada jenis tabel #temp yang Anda buat, jumlah informasi yang Anda kumpulkan di sesi XE Anda, dan bahkan versi SQL Server yang Anda gunakan. Jadi Anda dapat menjalankan pengujian serupa dengan apa yang telah saya lakukan di sini, dan memutuskan seberapa berharga pengumpulan informasi ini di lingkungan Anda.