Dalam utas terbaru di StackExchange, pengguna mengalami masalah berikut:
Saya ingin kueri yang mengembalikan orang pertama dalam tabel dengan GroupID =2. Jika tidak ada orang dengan GroupID =2, saya ingin orang pertama dengan RoleID =2.
Mari kita singkirkan, untuk saat ini, fakta bahwa "pertama" sangat ditentukan. Sebenarnya, pengguna tidak peduli orang mana yang mereka dapatkan, apakah itu datang secara acak, sewenang-wenang, atau melalui beberapa logika eksplisit selain kriteria utama mereka. Mengabaikan itu, katakanlah Anda memiliki tabel dasar:
CREATE TABLE dbo.Users ( UserID INT PRIMARY KEY, GroupID INT, RoleID INT );
Di dunia nyata mungkin ada kolom lain, batasan tambahan, mungkin kunci asing ke tabel lain, dan tentu saja indeks lainnya. Tapi mari kita buat ini tetap sederhana, dan buat kueri.
Kemungkinan Solusi
Dengan desain meja seperti itu, menyelesaikan masalah tampak mudah bukan? Upaya pertama yang mungkin Anda lakukan adalah:
SELECT TOP (1) UserID, GroupID, RoleID FROM dbo.Users WHERE GroupID = 2 OR RoleID = 2 ORDER BY CASE GroupID WHEN 2 THEN 1 ELSE 2 END;
Ini menggunakan TOP dan ORDER BY . bersyarat untuk memperlakukan pengguna dengan GroupID =2 sebagai prioritas yang lebih tinggi. Rencana untuk kueri ini cukup sederhana, dengan sebagian besar biaya terjadi dalam operasi sortir. Berikut adalah metrik runtime terhadap tabel kosong:
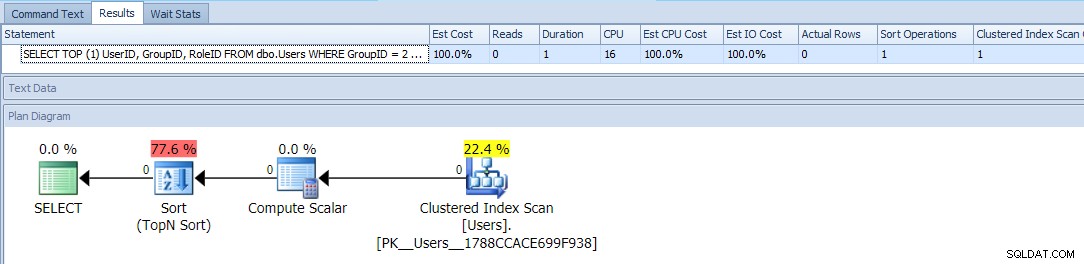
Sepertinya ini sebaik yang bisa Anda lakukan – rencana sederhana yang hanya memindai tabel sekali, dan selain jenis sial yang seharusnya bisa Anda jalani, tidak masalah, bukan?
Nah, jawaban lain di utas menawarkan variasi yang lebih kompleks ini:
SELECT TOP (1) UserID, GroupID, RoleID FROM ( SELECT TOP (1) UserID, GroupID, RoleID, o = 1 FROM dbo.Users WHERE GroupId = 2 UNION ALL SELECT TOP (1) UserID, GroupID, RoleID, o = 2 FROM dbo.Users WHERE RoleID = 2 ) AS x ORDER BY o;
Pada pandangan pertama, Anda mungkin akan berpikir bahwa kueri ini sangat kurang efisien, karena memerlukan dua pemindaian indeks berkerumun. Anda pasti benar tentang itu; berikut adalah rencana dan metrik runtime terhadap tabel kosong:
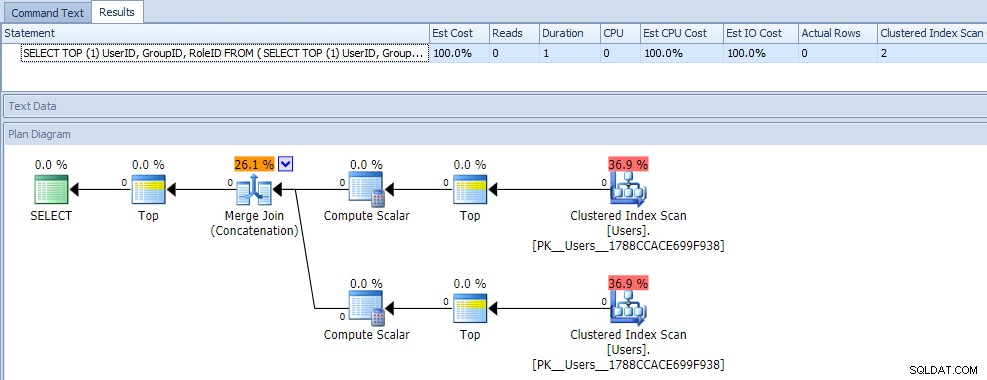
Tapi sekarang, mari kita tambahkan data
Untuk menguji kueri ini, saya ingin menggunakan beberapa data realistis. Jadi pertama-tama saya mengisi 1.000 baris dari sys.all_objects, dengan operasi modulo terhadap object_id untuk mendapatkan distribusi yang layak:
INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000) ABS([object_id]), ABS([object_id]) % 7, ABS([object_id]) % 4 FROM sys.all_objects ORDER BY [object_id]; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 126 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 248 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 26 overlap
Sekarang ketika saya menjalankan dua kueri, berikut adalah metrik waktu proses:

Versi UNION ALL hadir dengan I/O yang sedikit lebih sedikit (4 pembacaan vs. 5), durasi yang lebih rendah, dan perkiraan biaya keseluruhan yang lebih rendah, sedangkan versi ORDER BY bersyarat memiliki perkiraan biaya CPU yang lebih rendah. Data di sini cukup kecil untuk membuat kesimpulan tentang; Saya hanya menginginkannya sebagai taruhan di tanah. Sekarang, mari kita ubah distribusinya sehingga sebagian besar baris memenuhi setidaknya salah satu kriteria (dan terkadang keduanya):
DROP TABLE dbo.Users; GO CREATE TABLE dbo.Users ( UserID INT PRIMARY KEY, GroupID INT, RoleID INT ); GO INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000) ABS([object_id]), ABS([object_id]) % 2 + 1, SUBSTRING(RTRIM([object_id]),7,1) % 2 + 1 FROM sys.all_objects WHERE ABS([object_id]) > 9999999 ORDER BY [object_id]; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 500 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 475 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 221 overlap
Kali ini, urutan bersyarat menurut memiliki perkiraan biaya tertinggi di CPU dan I/O:

Tetapi sekali lagi, pada ukuran data ini, ada dampak yang relatif tidak penting terhadap durasi dan pembacaan, dan selain dari perkiraan biaya (yang sebagian besar dibuat), sulit untuk menyatakan pemenang di sini.
Jadi, mari kita tambahkan lebih banyak data
Sementara saya lebih suka membangun sampel data dari tampilan katalog, karena semua orang memilikinya, kali ini saya akan menggambar di atas tabel Sales.SalesOrderHeaderEnlarged dari AdventureWorks2012, diperluas menggunakan skrip ini dari Jonathan Kehayias. Di sistem saya, tabel ini memiliki 1.258.600 baris. Skrip berikut akan menyisipkan satu juta baris tersebut ke dalam tabel dbo.Users kami:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000000) SalesOrderID, SalesOrderID % 7, SalesOrderID % 4 FROM Sales.SalesOrderHeaderEnlarged; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 142,857 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 250,000 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 35,714 overlap
Oke, sekarang ketika kita menjalankan kueri, kita melihat masalah:variasi ORDER BY telah menjadi paralel dan telah menghapus pembacaan dan CPU, menghasilkan perbedaan durasi hampir 120X:
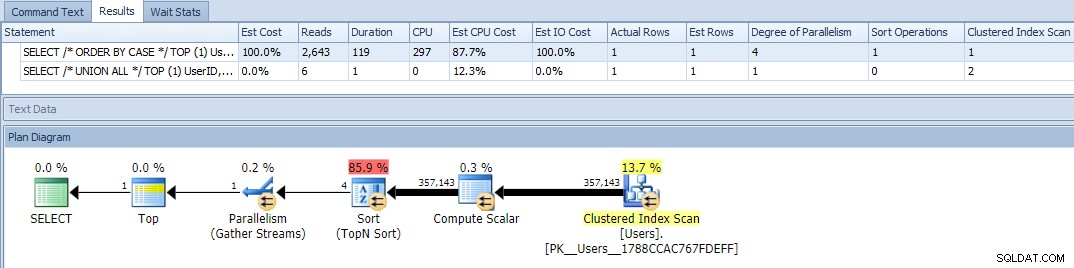
Menghilangkan paralelisme (menggunakan MAXDOP) tidak membantu:
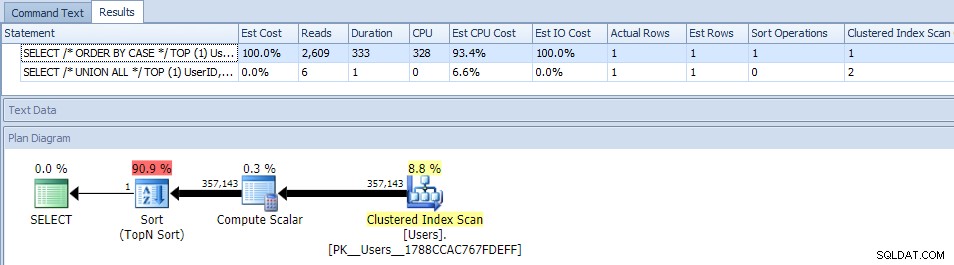
(Paket UNION ALL masih terlihat sama.)
Dan jika kita mengubah kemiringan menjadi genap, di mana 95% baris memenuhi setidaknya satu kriteria:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (475000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged WHERE SalesOrderID % 2 = 1 UNION ALL SELECT TOP (475000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged WHERE SalesOrderID % 2 = 0; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, 1, 1 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 542,851 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 542,851 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 135,702 overlap
Kueri masih menunjukkan bahwa pengurutan itu sangat mahal:

Dan dengan MAXDOP =1 jauh lebih buruk (lihat saja durasinya):

Terakhir, bagaimana kira-kira 95% condong ke kedua arah (mis. sebagian besar baris memenuhi kriteria GroupID, atau sebagian besar baris memenuhi kriteria RoleID)? Skrip ini akan memastikan setidaknya 95% data memiliki GroupID =2:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (950000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 957,143 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 185,714 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 142,857 overlap
Hasilnya cukup mirip (saya hanya akan berhenti mencoba MAXDOP mulai sekarang):

Dan kemudian jika kita condong ke arah lain, di mana setidaknya 95% data memiliki RoleID =2:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (950000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 185,714 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 957,143 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 142,857 overlap
Hasil:

Kesimpulan
Tidak ada satu pun kasus yang dapat saya buat melakukan kueri ORDER BY "lebih sederhana" – bahkan dengan satu pemindaian indeks yang lebih sedikit – mengungguli kueri UNION ALL yang lebih kompleks. Terkadang Anda harus sangat berhati-hati tentang apa yang harus dilakukan SQL Server saat Anda memperkenalkan operasi seperti sort ke dalam semantik kueri Anda, dan tidak bergantung pada kesederhanaan rencana saja (tidak peduli bias apa pun yang mungkin Anda miliki berdasarkan skenario sebelumnya).
Naluri pertama Anda mungkin sering benar, tetapi saya yakin ada kalanya ada opsi yang lebih baik yang terlihat, di permukaan, seperti itu tidak mungkin berhasil dengan lebih baik. Seperti dalam contoh ini. Saya menjadi sedikit lebih baik dalam mempertanyakan asumsi yang saya buat dari pengamatan, dan tidak membuat pernyataan menyeluruh seperti "pemindaian tidak pernah berkinerja baik" dan "kueri yang lebih sederhana selalu berjalan lebih cepat." Jika Anda menghilangkan kata tidak pernah dan selalu dari kosakata Anda, Anda mungkin mendapati diri Anda lebih banyak menguji asumsi dan pernyataan tersebut, dan berakhir dengan jauh lebih baik.



