Menambahkan indeks yang difilter dapat memiliki efek samping yang mengejutkan pada kueri yang ada, meskipun tampaknya indeks baru yang difilter sama sekali tidak terkait. Postingan ini melihat contoh yang memengaruhi pernyataan DELETE yang menghasilkan kinerja yang buruk dan peningkatan risiko kebuntuan.
Lingkungan Uji
Tabel berikut akan digunakan di seluruh postingan ini:
CREATE TABLE dbo.Data
(
RowID integer IDENTITY NOT NULL,
SomeValue integer NOT NULL,
StartDate date NOT NULL,
CurrentFlag bit NOT NULL,
Padding char(50) NOT NULL DEFAULT REPLICATE('ABCDE', 10),
CONSTRAINT PK_Data_RowID
PRIMARY KEY CLUSTERED (RowID)
); Pernyataan berikut ini membuat 499.999 baris data sampel:
INSERT dbo.Data WITH (TABLOCKX)
(SomeValue, StartDate, CurrentFlag)
SELECT
CONVERT(integer, RAND(n) * 1e6) % 1000,
DATEADD(DAY, (N.n - 1) % 31, '20140101'),
CONVERT(bit, 0)
FROM dbo.Numbers AS N
WHERE
N.n >= 1
AND N.n < 500000; Itu menggunakan tabel Numbers sebagai sumber bilangan bulat berurutan dari 1 hingga 499.999. Jika Anda tidak memiliki salah satunya di lingkungan pengujian Anda, kode berikut dapat digunakan untuk membuat kode yang berisi bilangan bulat dari 1 hingga 1.000.000 secara efisien:
WITH
N1 AS (SELECT N1.n FROM (VALUES (1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS N1 (n)),
N2 AS (SELECT L.n FROM N1 AS L CROSS JOIN N1 AS R),
N3 AS (SELECT L.n FROM N2 AS L CROSS JOIN N2 AS R),
N4 AS (SELECT L.n FROM N3 AS L CROSS JOIN N2 AS R),
N AS (SELECT ROW_NUMBER() OVER (ORDER BY n) AS n FROM N4)
SELECT
-- Destination column type integer NOT NULL
ISNULL(CONVERT(integer, N.n), 0) AS n
INTO dbo.Numbers
FROM N
OPTION (MAXDOP 1);
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_Numbers_n
PRIMARY KEY (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1); Dasar dari pengujian selanjutnya adalah menghapus baris dari tabel pengujian untuk StartDate tertentu. Untuk membuat proses mengidentifikasi baris yang akan dihapus lebih efisien, tambahkan indeks nonclustered ini:
CREATE NONCLUSTERED INDEX
IX_Data_StartDate
ON dbo.Data
(StartDate); Contoh Data
Setelah langkah-langkah tersebut selesai, sampel akan terlihat seperti ini:
SELECT TOP (100)
D.RowID,
D.SomeValue,
D.StartDate,
D.CurrentFlag,
D.Padding
FROM dbo.Data AS D
ORDER BY
D.RowID;
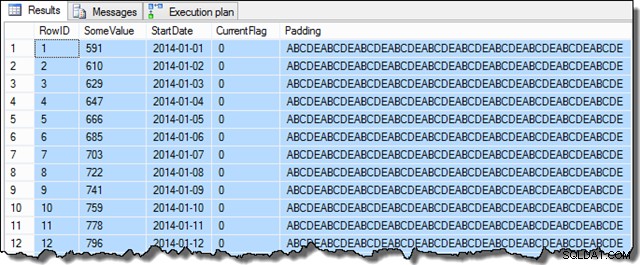
Data kolom SomeValue mungkin sedikit berbeda karena pembuatan pseudo-acak, tetapi perbedaan ini tidak penting. Secara keseluruhan, data sampel berisi 16.129 baris untuk masing-masing dari 31 tanggal StartDate pada Januari 2014:
SELECT
D.StartDate,
NumRows = COUNT_BIG(*)
FROM dbo.Data AS D
GROUP BY
D.StartDate
ORDER BY
D.StartDate;
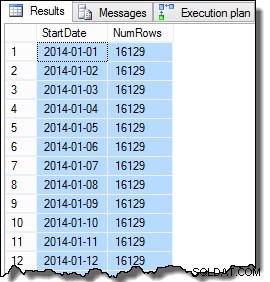
Langkah terakhir yang perlu kita lakukan untuk membuat data agak realistis, adalah menyetel kolom CurrentFlag ke true untuk RowID tertinggi untuk setiap StartDate. Skrip berikut menyelesaikan tugas ini:
WITH LastRowPerDay AS
(
SELECT D.CurrentFlag
FROM dbo.Data AS D
WHERE D.RowID =
(
SELECT MAX(D2.RowID)
FROM dbo.Data AS D2
WHERE D2.StartDate = D.StartDate
)
)
UPDATE LastRowPerDay
SET CurrentFlag = 1; Rencana eksekusi untuk pembaruan ini menampilkan kombinasi Segmen-Top untuk secara efisien menemukan RowID tertinggi per hari:

Perhatikan bagaimana rencana eksekusi memiliki sedikit kemiripan dengan bentuk tertulis dari kueri. Ini adalah contoh yang bagus tentang bagaimana pengoptimal bekerja dari spesifikasi SQL logis, daripada mengimplementasikan SQL secara langsung. Jika Anda bertanya-tanya, Eager Table Spool dalam paket itu diperlukan untuk Perlindungan Halloween.
Menghapus Data Sehari
Oke, jadi dengan penyisihan selesai, tugas yang ada adalah menghapus baris untuk StartDate tertentu. Ini adalah jenis kueri yang mungkin Anda jalankan secara rutin pada tanggal paling awal dalam tabel, di mana data telah mencapai akhir masa pakainya.
Mengambil 1 Januari 2014 sebagai contoh kami, kueri penghapusan pengujian sederhana:
DELETE dbo.Data WHERE StartDate = '20140101';
Rencana eksekusinya juga cukup sederhana, meskipun perlu dilihat sedikit detail:

Analisis Rencana
Pencarian Indeks di paling kanan menggunakan indeks nonclustered untuk menemukan baris untuk nilai StartDate yang ditentukan. Ini hanya mengembalikan nilai RowID yang ditemukannya, seperti yang dikonfirmasi oleh tooltip operator:
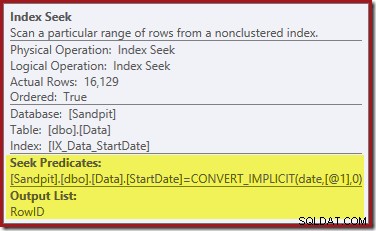
Jika Anda bertanya-tanya bagaimana indeks StartDate berhasil mengembalikan RowID, ingatlah bahwa RowID adalah indeks berkerumun unik untuk tabel, sehingga secara otomatis disertakan dalam indeks nonclustered StartDate.
Operator berikutnya dalam rencana adalah Penghapusan Indeks Clustered. Ini menggunakan nilai RowID yang ditemukan oleh Index Seek untuk menemukan baris yang akan dihapus.
Operator terakhir dalam rencana adalah Penghapusan Indeks. Ini menghapus baris dari indeks nonclustered IX_Data_StartDate yang terkait dengan RowID dihapus oleh Penghapusan Indeks Clustered. Untuk menemukan baris ini dalam indeks nonclustered, pemroses kueri memerlukan StartDate (kunci untuk indeks nonclustered).
Ingat Pencarian Indeks asli tidak mengembalikan Tanggal Mulai, hanya RowID. Jadi bagaimana prosesor kueri mendapatkan StartDate untuk penghapusan indeks? Dalam kasus khusus ini, pengoptimal mungkin telah memperhatikan bahwa nilai StartDate adalah konstan dan mengoptimalkannya, tetapi bukan ini yang terjadi. Jawabannya adalah operator Penghapusan Indeks Berkelompok membaca nilai StartDate untuk baris saat ini dan menambahkannya ke aliran. Bandingkan Output List dari Clustered Index Delete yang ditunjukkan di bawah ini, dengan Index Seek tepat di atas:
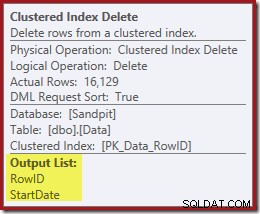
Mungkin tampak mengejutkan melihat operator Hapus data membaca, tetapi ini adalah cara kerjanya. Pemroses kueri tahu bahwa ia harus menemukan baris dalam indeks berkerumun untuk menghapusnya, jadi mungkin juga menunda membaca kolom yang diperlukan untuk mempertahankan indeks yang tidak berkerumun sampai saat itu, jika bisa.
Menambahkan Indeks yang Difilter
Sekarang bayangkan seseorang memiliki kueri penting terhadap tabel ini yang berkinerja buruk. DBA yang membantu melakukan analisis dan menambahkan indeks terfilter berikut:
CREATE NONCLUSTERED INDEX
FIX_Data_SomeValue_CurrentFlag
ON dbo.Data (SomeValue)
INCLUDE (CurrentFlag)
WHERE CurrentFlag = 1; Indeks yang difilter baru memiliki efek yang diinginkan pada kueri bermasalah, dan semua orang senang. Perhatikan bahwa indeks baru tidak mereferensikan kolom StartDate sama sekali, jadi kami tidak mengharapkannya memengaruhi kueri penghapusan hari sama sekali.
Menghapus hari dengan indeks yang difilter pada tempatnya
Kami dapat menguji harapan itu dengan menghapus data untuk kedua kalinya:
DELETE dbo.Data WHERE StartDate = '20140102';
Tiba-tiba, rencana eksekusi telah berubah menjadi Pemindaian Indeks Clustered paralel:

Perhatikan tidak ada operator Penghapusan Indeks yang terpisah untuk indeks baru yang difilter. Pengoptimal telah memilih untuk mempertahankan indeks ini di dalam operator Penghapusan Indeks Cluster. Ini disorot di SQL Sentry Plan Explorer seperti yang ditunjukkan di atas ("+1 indeks non-clustered") dengan detail lengkap di tooltip:
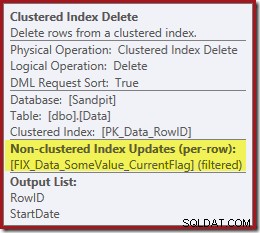
Jika tabelnya besar (pikirkan gudang data), perubahan ke pemindaian paralel ini mungkin sangat signifikan. Apa yang terjadi pada Pencarian Indeks yang bagus di StartDate, dan mengapa indeks terfilter yang sama sekali tidak terkait mengubah banyak hal secara dramatis?
Menemukan Masalah
Petunjuk pertama datang dari melihat properti dari Clustered Index Scan:
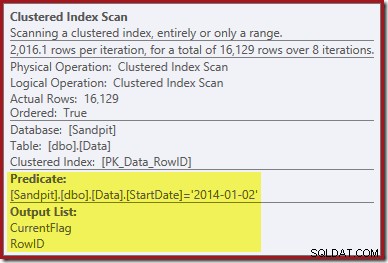
Selain menemukan nilai RowID untuk dihapus oleh operator Clustered Index Delete, operator ini sekarang membaca nilai CurrentFlag. Kebutuhan kolom ini tidak jelas, tetapi setidaknya mulai menjelaskan keputusan untuk memindai:kolom CurrentFlag bukan bagian dari indeks nonclustered StartDate kami.
Kami dapat mengonfirmasi ini dengan menulis ulang kueri penghapusan untuk memaksa penggunaan indeks nonclustered StartDate:
DELETE D
FROM dbo.Data AS D
WITH (INDEX(IX_Data_StartDate))
WHERE StartDate = '20140103'; Rencana eksekusi lebih dekat ke bentuk aslinya, tetapi sekarang memiliki fitur Pencarian Kunci:
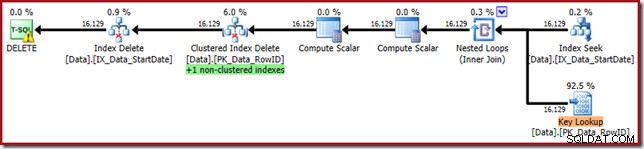
Properti Pencarian Kunci mengonfirmasi bahwa operator ini mengambil nilai CurrentFlag:
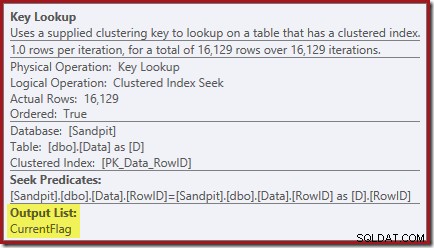
Anda mungkin juga telah memperhatikan segitiga peringatan dalam dua rencana terakhir. Ini adalah peringatan indeks yang tidak ada:
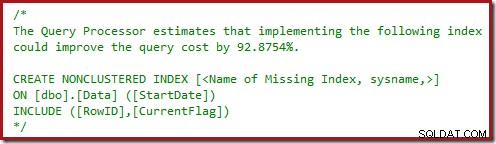
Ini adalah konfirmasi lebih lanjut bahwa SQL Server ingin melihat kolom CurrentFlag disertakan dalam indeks nonclustered. Alasan perubahan ke Pemindaian Indeks Clustered paralel sekarang jelas:pemroses kueri memutuskan bahwa pemindaian tabel akan lebih murah daripada melakukan Pencarian Kunci.
Ya, tapi kenapa?
Ini semua sangat aneh. Dalam rencana eksekusi asli, SQL Server dapat membaca data kolom tambahan yang diperlukan untuk mempertahankan indeks nonclustered di operator Clustered Index Delete. Nilai kolom CurrentFlag diperlukan untuk mempertahankan indeks yang difilter, jadi mengapa SQL Server tidak menanganinya dengan cara yang sama?
Jawaban singkatnya adalah bisa, tetapi hanya Jika indeks yang difilter dipertahankan di operator Penghapusan Indeks yang terpisah. Kami dapat memaksa ini untuk kueri saat ini menggunakan tanda pelacakan tidak berdokumen 8790. Tanpa tanda ini, pengoptimal memilih apakah akan mempertahankan setiap indeks di operator terpisah atau sebagai bagian dari operasi tabel dasar.
-- Forced wide update plan DELETE dbo.Data WHERE StartDate = '20140105' OPTION (QUERYTRACEON 8790);
Rencana eksekusi kembali mencari indeks nonclustered StartDate:
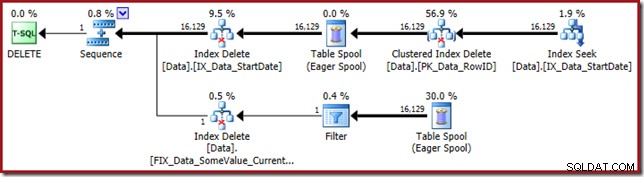
Pencarian Indeks hanya mengembalikan nilai RowID (tanpa CurrentFlag):
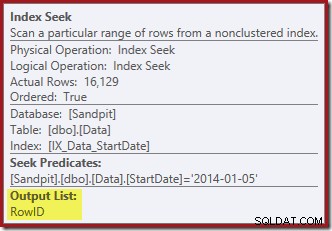
Dan Indeks Clustered Hapus terbaca kolom yang diperlukan untuk mempertahankan indeks nonclustered, termasuk CurrentFlag:
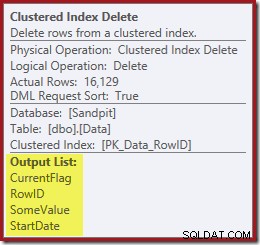
Data ini dengan bersemangat ditulis ke spool tabel, yang diputar ulang untuk setiap indeks yang perlu dipelihara. Perhatikan juga operator Filter eksplisit sebelum operator Index Delete untuk indeks yang difilter.
Pola lain yang harus diperhatikan
Masalah ini tidak selalu menghasilkan pemindaian tabel alih-alih pencarian indeks. Untuk melihat contohnya, tambahkan indeks lain ke tabel pengujian:
CREATE NONCLUSTERED INDEX
IX_Data_SomeValue_CurrentFlag
ON dbo.Data (SomeValue, CurrentFlag); Perhatikan bahwa indeks ini tidak difilter, dan tidak melibatkan kolom StartDate. Sekarang coba kueri penghapusan hari lagi:
DELETE dbo.Data WHERE StartDate = '20140104';
Pengoptimal sekarang muncul dengan monster ini:
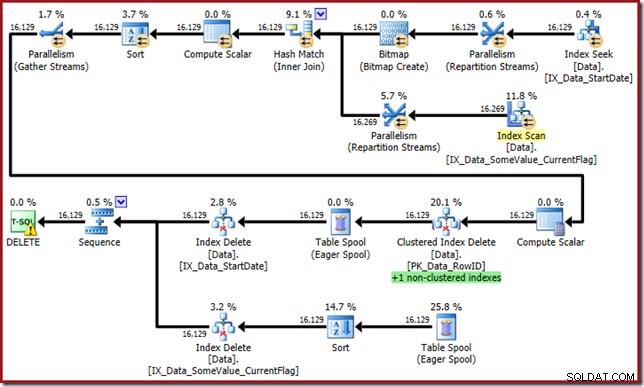
Rencana kueri ini memiliki faktor kejutan yang tinggi, tetapi akar masalahnya sama. Kolom CurrentFlag masih diperlukan, tetapi sekarang pengoptimal memilih strategi persimpangan indeks untuk mendapatkannya alih-alih pemindaian tabel. Menggunakan tanda jejak memaksa rencana pemeliharaan per indeks dan kewarasan sekali lagi dipulihkan (satu-satunya perbedaan adalah pemutaran ulang spool ekstra untuk mempertahankan indeks baru):
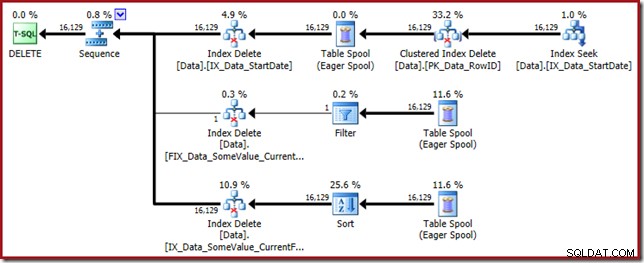
Hanya indeks yang difilter yang menyebabkan ini
Masalah ini hanya terjadi jika pengoptimal memilih untuk mempertahankan indeks yang difilter di operator Penghapusan Indeks Tergugus. Indeks yang tidak difilter tidak terpengaruh, seperti yang ditunjukkan contoh berikut. Langkah pertama adalah membuang indeks yang difilter:
DROP INDEX FIX_Data_SomeValue_CurrentFlag ON dbo.Data;
Sekarang kita perlu menulis kueri dengan cara yang meyakinkan pengoptimal untuk mempertahankan semua indeks di Hapus Indeks Cluster. Pilihan saya untuk ini adalah menggunakan variabel dan petunjuk untuk menurunkan ekspektasi jumlah baris pengoptimal:
-- All qualifying rows will be deleted
DECLARE @Rows bigint = 9223372036854775807;
-- Optimize the plan for deleting 100 rows
DELETE TOP (@Rows)
FROM dbo.Data
OUTPUT
Deleted.RowID,
Deleted.SomeValue,
Deleted.StartDate,
Deleted.CurrentFlag
WHERE StartDate = '20140106'
OPTION (OPTIMIZE FOR (@Rows = 100)); Rencana eksekusi adalah:
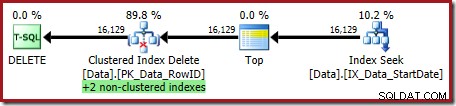
Kedua indeks nonclustered dikelola oleh Clustered Index Delete:
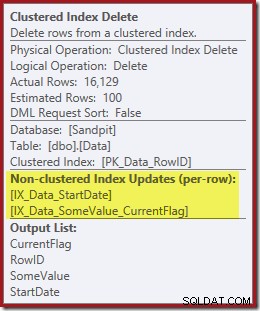
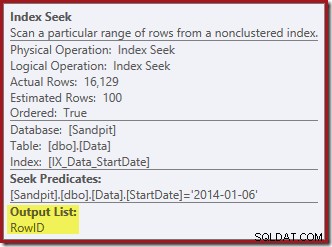
Pencarian Indeks hanya mengembalikan RowID:
Kolom yang diperlukan untuk pemeliharaan indeks diambil secara internal oleh operator hapus; detail ini tidak ditampilkan dalam output rencana pertunjukan (sehingga daftar output dari operator hapus akan kosong). Saya menambahkan OUTPUT klausa ke kueri untuk menampilkan Indeks Clustered Hapus sekali lagi mengembalikan data yang tidak diterima pada inputnya:
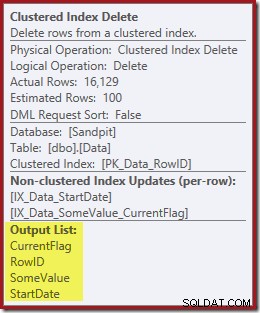
Pemikiran Terakhir
Ini adalah batasan yang sulit untuk diatasi. Di satu sisi, kami biasanya tidak ingin menggunakan tanda jejak yang tidak berdokumen dalam sistem produksi.
'Perbaikan' alami adalah menambahkan kolom yang diperlukan untuk pemeliharaan indeks yang difilter ke semua indeks nonclustered yang mungkin digunakan untuk menemukan baris yang akan dihapus. Ini bukan proposisi yang sangat menarik, dari beberapa sudut pandang. Alternatif lain adalah tidak menggunakan indeks yang difilter sama sekali, tetapi itu juga tidak ideal.
Perasaan saya adalah bahwa pengoptimal kueri harus mempertimbangkan alternatif pemeliharaan per indeks untuk indeks yang difilter secara otomatis, tetapi alasannya tampaknya tidak lengkap di area ini sekarang (dan berdasarkan heuristik sederhana daripada biaya per indeks/per baris dengan benar alternatif).
Untuk menempatkan beberapa angka di sekitar pernyataan itu, rencana pemindaian indeks berkerumun paralel yang dipilih oleh pengoptimal masuk pada 5,5 unit dalam pengujian saya. Kueri yang sama dengan tanda pelacakan memperkirakan biaya 1,4 unit. Dengan indeks ketiga di tempat, rencana perpotongan indeks paralel yang dipilih oleh pengoptimal memiliki perkiraan biaya 4,9 , sedangkan rencana bendera jejak masuk pada 2,7 unit (semua pengujian pada SQL Server 2014 RTM CU1 build 12.0.2342 di bawah model estimasi kardinalitas 120, dan dengan bendera pelacakan 4199 diaktifkan).
Saya menganggap ini sebagai perilaku yang harus ditingkatkan. Anda dapat memilih untuk setuju atau tidak setuju dengan saya pada item Connect ini.