Apa itu optimasi kueri di SQL Server? Ini adalah topik besar. Setiap teknik atau masalah membutuhkan artikel terpisah untuk menutupi dasarnya. Tetapi ketika Anda baru mulai meningkatkan level game Anda dengan kueri, Anda memerlukan sesuatu yang lebih sederhana untuk diandalkan. Ini adalah tujuan dari artikel ini.
Anda mungkin mengatakan kueri Anda optimal, semuanya berkinerja baik, dan pengguna senang. Tentu saja, kinerja bukanlah segalanya. Hasilnya juga harus benar. Baik itu gabungan, subkueri, sinonim, CTE, tampilan, atau apa pun, kinerjanya harus dapat diterima.
Dan pada akhirnya, Anda bisa pulang dengan pengguna Anda. Anda tidak ingin tinggal di kantor memperbaiki kueri yang berjalan lambat dalam semalam.
Sebelum kita mulai, izinkan saya meyakinkan Anda bahwa perjalanan ini tidak akan sulit. Ini hanya akan menjadi primer. Kami akan memiliki contoh yang tidak akan terlalu asing bagi Anda juga. Terakhir, saat Anda siap untuk mempelajari lebih dalam, kami akan menyajikan beberapa tautan yang dapat Anda lihat.
Mari kita mulai.
1. Optimasi SQL Query Dimulai dari Desain dan Arsitektur
Terkejut? Optimalisasi kueri SQL bukanlah renungan atau bantuan band ketika sesuatu rusak. Kueri Anda berjalan secepat yang dimungkinkan oleh desain Anda. Kita berbicara tentang tabel yang dinormalisasi, tipe data yang tepat, penggunaan indeks, pengarsipan data lama, dan salah satu praktik terbaik yang dapat Anda pikirkan.
Desain database yang baik bekerja secara sinergis dengan perangkat keras yang tepat dan pengaturan SQL Server. Apakah Anda mendesainnya agar berjalan lancar selama beberapa tahun dan masih terasa baru? Itu adalah mimpi besar, tetapi kami hanya memiliki waktu (biasanya – singkat) tertentu untuk memikirkannya.
Itu tidak akan sempurna pada hari pertama dalam produksi, tetapi kita seharusnya sudah membahas dasarnya. Kami akan meminimalkan utang teknis. Jika Anda bekerja dengan tim, itu bagus dibandingkan dengan pertunjukan satu orang. Anda dapat menutupi banyak lonceng dan peluit.
Namun, bagaimana jika database berjalan langsung dan Anda menemui hambatan kinerja? Berikut adalah beberapa tip dan trik pengoptimalan kueri SQL.
2. Temukan Pertanyaan Bermasalah dengan Laporan Standar SQL Server
Saat Anda membuat kode, mudah untuk menemukan rangkaian kode yang panjang atau prosedur tersimpan. Anda dapat men-debug-nya baris demi baris. Garis yang tertinggal adalah yang harus diperbaiki.
Tetapi bagaimana jika helpdesk Anda melemparkan selusin tiket karena lambat? Pengguna tidak dapat menentukan lokasi yang tepat dalam kode, begitu juga dengan helpdesk. Waktu adalah musuh terburuk Anda.
Salah satu solusi yang tidak memerlukan pengkodean adalah memeriksa laporan standar SQL Server. Klik kanan server yang diperlukan di SQL Server Management Studio> Laporan> Laporan Standar . Tempat menarik kami mungkin Dasbor Kinerja atau Kinerja – Kueri Teratas menurut Total I/O . Pilih kueri pertama yang berkinerja buruk. Kemudian mulai pengoptimalan kueri SQL atau penyetelan kinerja SQL dari sana.
3. Penyesuaian Kueri SQL dengan STATISTICS IO
Setelah menentukan kueri yang dimaksud, Anda dapat mulai memeriksa pembacaan logis di STATISTICS IO. Ini adalah salah satu alat pengoptimalan kueri SQL.
Ada beberapa poin I/O, tetapi Anda harus fokus pada pembacaan logis. Semakin tinggi pembacaan logisnya, semakin bermasalah kinerja kuerinya.
Dengan mengurangi 3 faktor berikut, Anda dapat mempercepat kueri penyetelan kinerja di SQL:
- pembacaan logis tinggi,
- pembacaan logika LOB tinggi,
- atau pembacaan logis WorkTable/WorkFile tinggi.
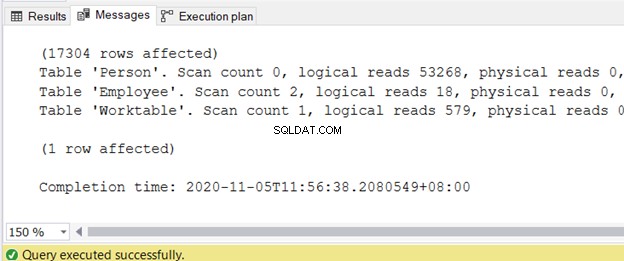
Untuk mendapatkan informasi tentang pembacaan logis, aktifkan STATISTICS IO di jendela kueri SQL Server Management Studio.
AKTIFKAN STATISTIK IO
Anda bisa mendapatkan output di tab Pesan setelah kueri selesai. Gambar 2 menampilkan contoh keluaran:
Saya telah menulis artikel terpisah tentang mengurangi pembacaan logis dalam 3 Statistik I/O Buruk yang Lag Kinerja Kueri SQL. Lihat untuk langkah-langkah yang tepat dan contoh kode dengan pembacaan logis yang tinggi dan cara untuk menguranginya.
4. Penyesuaian Kueri SQL dengan Paket Eksekusi
Pembacaan logis saja tidak akan memberi Anda gambaran utuh. Serangkaian langkah yang dipilih oleh pengoptimal kueri akan menceritakan kisah kumpulan hasil Anda. Bagaimana semuanya dimulai setelah Anda menjalankan kueri?
Gambar 3 di bawah ini adalah diagram dari apa yang terjadi setelah Anda memicu eksekusi hingga saat Anda mendapatkan hasil yang ditetapkan.
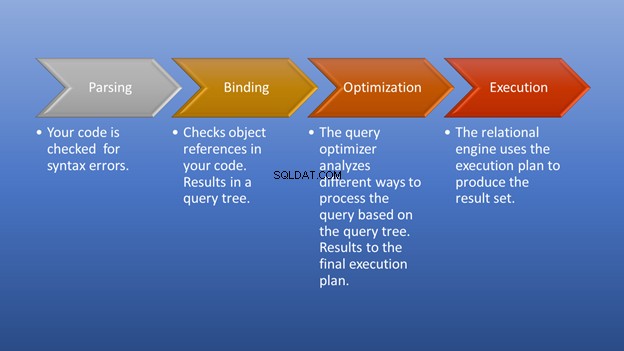
Parsing dan binding akan terjadi dalam sekejap. Bagian yang mengagumkan adalah tahap pengoptimalan, yang menjadi fokus kami. Pada tahap ini, pengoptimal kueri memainkan peran penting dalam memilih rencana eksekusi terbaik. Meskipun bagian ini membutuhkan beberapa sumber daya, ini menghemat banyak waktu ketika memilih rencana eksekusi yang efisien. Ini terjadi secara dinamis, karena basis data berubah seiring waktu. Dengan cara ini, programmer dapat fokus pada bagaimana membentuk hasil akhir.
Setiap paket yang dianggap pengoptimal kueri memiliki biaya kuerinya sendiri. Di antara banyak opsi, pengoptimal akan memilih paket dengan biaya paling masuk akal. Catatan :Biaya yang wajar tidak sama dengan biaya terkecil. Itu juga perlu mempertimbangkan rencana mana yang akan menghasilkan hasil tercepat. Paket dengan biaya paling sedikit tidak selalu yang tercepat. Misalnya, pengoptimal dapat memilih untuk menggunakan beberapa inti prosesor. Kami menyebutnya eksekusi paralel. Ini akan menghabiskan lebih banyak sumber daya tetapi berjalan lebih cepat dibandingkan dengan eksekusi serial.
Hal lain yang perlu dipertimbangkan adalah statistik. Pengoptimal kueri mengandalkannya untuk membuat rencana eksekusi. Jika statistik sudah usang, jangan mengharapkan keputusan terbaik dari pengoptimal kueri.
Ketika rencana diputuskan dan eksekusi berlangsung, Anda akan melihat hasilnya. Apa sekarang?
Periksa Rencana Eksekusi Kueri di SQL Server
Saat Anda membentuk kueri, Anda ingin melihat hasilnya terlebih dahulu. Hasilnya harus benar. Jika sudah, Anda selesai.
Begitukah?
Jika Anda kekurangan waktu, dan pekerjaan dipertaruhkan, Anda dapat menyetujuinya. Selain itu, Anda selalu dapat kembali. Namun, jika masalah lain muncul, Anda bisa melupakannya lagi dan lagi. Dan kemudian, hantu masa lalu akan memburumu.
Sekarang, apa hal terbaik yang harus dilakukan setelah mendapatkan hasil yang benar?
Periksa Rencana Eksekusi Aktual atau Statistik Kueri Langsung !
Yang terakhir bagus jika kueri Anda berjalan lambat dan Anda ingin melihat apa yang terjadi setiap detik saat baris diproses.
Kadang-kadang, situasi akan memaksa Anda untuk segera memeriksa rencana tersebut. Untuk memulai, tekan Control-M atau klik Sertakan Rencana Eksekusi Aktual dari toolbar SQL Server Management Studio. Jika Anda lebih suka dbForge Studio untuk SQL Server, buka Query Profiler – memberikan info yang sama + beberapa lonceng dan peluit yang tidak dapat Anda temukan di SSMS.
Kami telah melihat Rencana Eksekusi Aktual . Mari kita lanjutkan lebih jauh.
Apakah Ada Indeks yang Hilang atau Rekomendasi Indeks?
Indeks yang hilang mudah dikenali – Anda akan segera mendapatkan peringatan.
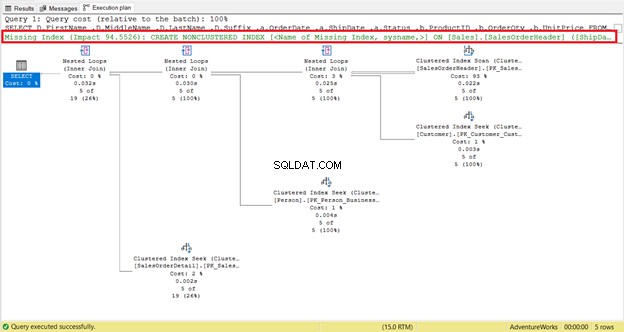
Untuk mendapatkan kode instan untuk membuat indeks, klik kanan Indeks yang Tidak Ada pesan (dikotak merah). Kemudian pilih Rincian Indeks Tidak Ada . Jendela kueri baru dengan kode untuk membuat indeks yang hilang akan muncul. Buat indeks.
Bagian ini mudah diikuti. Ini adalah titik awal yang baik untuk mencapai eksekusi yang lebih cepat. Tetapi dalam beberapa kasus, tidak akan berpengaruh. Mengapa? Beberapa kolom yang diperlukan oleh kueri Anda tidak ada dalam indeks. Oleh karena itu, ini akan kembali ke Pemindaian Indeks Berkelompok.
Anda perlu memeriksa ulang rencana eksekusi setelah membuat indeks untuk melihat apakah kolom yang disertakan diperlukan. Kemudian, sesuaikan indeks yang sesuai dan jalankan kembali kueri Anda. Setelah itu, periksa kembali rencana eksekusi.
Tapi bagaimana jika tidak ada indeks yang hilang?
Baca Rencana Eksekusi
Anda perlu mengetahui beberapa hal dasar untuk memulai:
- Operator
- Properti
- Arah membaca
- Peringatan
OPERATOR
Pengoptimal kueri menggunakan semacam program mini yang disebut operator. Anda telah melihat beberapa di antaranya pada Gambar 4 – Pencarian Indeks Berkelompok , Pemindaian Indeks Berkelompok , Loop Bersarang , dan Pilih .
Untuk mendapatkan daftar lengkap dengan nama, ikon, dan deskripsi, Anda dapat memeriksa referensi ini dari Microsoft.
PROPERTI
Diagram grafis tidak cukup untuk memahami apa yang terjadi di balik layar. Anda perlu menggali lebih dalam properti masing-masing operator. Misalnya, Pemindaian Indeks Berkelompok pada Gambar 4 memiliki Properties berikut:
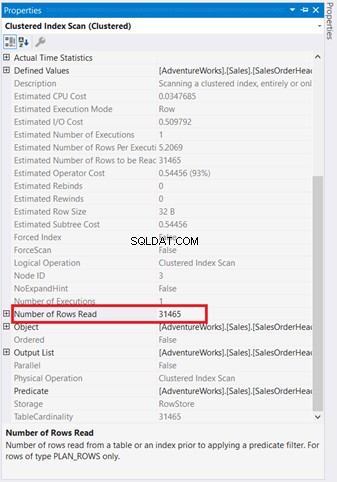
Jika Anda akan memeriksanya dengan cermat, Pemindaian Indeks Berkelompok operatornya mengerikan. Seperti yang ditunjukkan Gambar 5, ia membaca 31.465 baris, tetapi hasil akhir yang ditetapkan hanya 5 baris. Karena itulah ada rekomendasi indeks pada Gambar 4 untuk mengurangi jumlah baris yang dibaca. Pembacaan logis dari kueri juga tinggi dan ini menjelaskan alasannya.
Untuk mengetahui lebih banyak tentang properti ini, lihat daftar properti operator umum dan properti rencana.
CARA MEMBACA
Secara umum, ini seperti membaca manga Jepang – dari kanan ke kiri. Ikuti panah yang mengarah ke kiri. Berikut adalah contoh sederhana dari dbForge Studio untuk SQL Server.
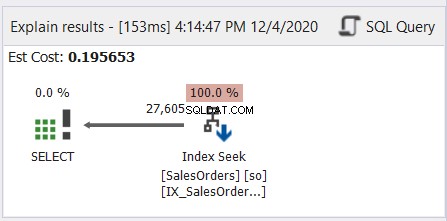
Seperti yang ditunjukkan Gambar 6, panah menunjuk ke kiri dari operator Index Seek ke operator SELECT.
Namun, membaca dari kanan ke kiri mungkin tidak selalu benar. Lihat Gambar 7 dengan contoh dari SSMS:
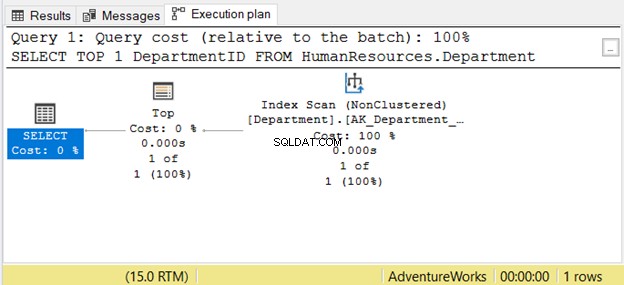
Jika Anda membacanya dari kanan ke kiri, Anda akan melihat bahwa Pemindaian Indeks keluaran operator adalah 1 dari 1 baris. Bagaimana dia bisa tahu hanya 1 baris yang harus diambil? Itu karena Atas operator. Ini akan membingungkan kita jika kita membacanya dari kanan ke kiri.
Untuk memahami kasus ini dengan lebih baik, bacalah sebagai “operator SELECT menggunakan Top untuk mengambil 1 baris menggunakan Pemindaian Indeks”. Itu dari kiri ke kanan.
Apa yang harus kita gunakan? Kanan ke kiri atau kiri ke kanan?
Ini semacam keduanya – mana saja yang membantu Anda memahami rencana tersebut.
Sementara panah memberi kita arah aliran data, ketebalannya memberi kita beberapa petunjuk tentang ukuran data. Mari kita lihat Gambar 4 lagi.
Pemindaian Indeks Berkelompok pergi ke Loop Bersarang memiliki panah yang lebih tebal dibandingkan dengan yang lain. Properti detail Pemindaian Indeks pada Gambar 5 beri tahu kami mengapa tebal (31.465 baris dibaca untuk hasil akhir 5 baris).
PERINGATAN
Ikon peringatan yang muncul di operator rencana eksekusi memberi tahu kita bahwa sesuatu yang buruk telah terjadi di operator itu. Ini dapat menghambat pengoptimalan kueri SQL Anda dengan menghabiskan lebih banyak sumber daya.
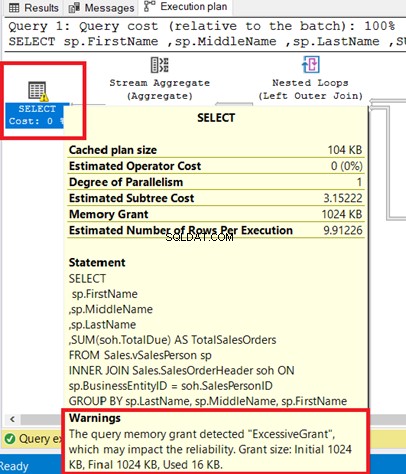
Anda dapat melihat peringatan di operator SELECT. Mengarahkan kursor ke operator tersebut akan menampilkan pesan peringatan. Hibah Berlebihan telah menyebabkan peringatan ini.
Hibah Berlebihan terjadi ketika lebih sedikit memori yang digunakan daripada yang dicadangkan untuk kueri. Untuk informasi lebih lanjut, lihat dokumentasi Microsoft ini.
Gambar 8 menunjukkan kueri yang digunakan sebagai INNER JOIN dari tampilan ke tabel. Anda dapat menghapus peringatan dengan menggabungkan tabel dasar alih-alih tampilan.
Sekarang setelah Anda memiliki ide dasar untuk membaca rencana eksekusi, bagaimana cara menentukan apa yang membuat kueri Anda lambat?
Ketahui 5 Penipu Operator Paket Umum
Jeda dalam eksekusi kueri Anda seperti kejahatan. Anda harus mengejar dan menangkap bajingan ini.
1. Pemindaian Indeks Clustered atau Non-Clustered
Penjahat pertama yang dipelajari semua orang adalah Berkelompok atau Pemindaian Indeks Non-Clustered . Pengetahuan umumnya dalam pengoptimalan kueri SQL bahwa pemindaian buruk dan pencarian baik. Kami telah melihatnya di Gambar 4. Karena indeks yang hilang, Pemindaian Indeks Berkelompok membaca 31.465 untuk mendapatkan 5 baris.
Namun, tidak selalu demikian. Pertimbangkan 2 kueri pada tabel yang sama pada Gambar 9. Satu akan memiliki pencarian dan yang lain memiliki pemindaian.
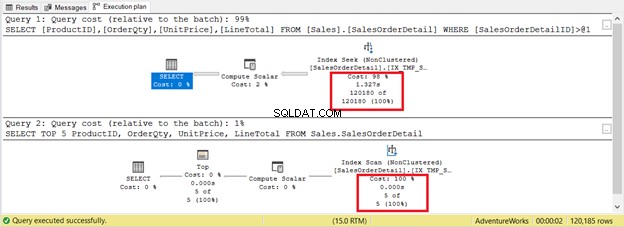
Jika Anda hanya mendasarkan kriteria pada jumlah catatan, pemindaian indeks menang dengan hanya 5 catatan vs. 120.180. Pencarian indeks akan memakan waktu lebih lama untuk dieksekusi.
Inilah contoh lain di mana pemindaian atau pencarian hampir tidak menjadi masalah. Mereka mengembalikan 6 catatan yang sama dari tabel yang sama. Pembacaan logis adalah sama dan waktu yang berlalu adalah nol dalam kedua kasus. Tabel sangat kecil dengan 6 catatan saja. Sertakan Rencana Eksekusi Aktual dan jalankan pernyataan di bawah ini.
-- Run this with Include Actual Execution Plan
USE AdventureWorks
GO
SET STATISTICS IO ON
GO
SELECT AddressTypeID, Name
FROM Person.AddressType
WHERE AddressTypeID >= 1
ORDER BY AddressTypeID DESC
Kemudian, simpan rencana eksekusi untuk perbandingan nanti. Klik kanan rencana eksekusi> Simpan Rencana Eksekusi Sebagai .
Sekarang, jalankan kueri di bawah ini.
SELECT AddressTypeID, Name
FROM Person.AddressType
ORDER BY AddressTypeID DESC
SET STATISTICS IO OFF
GO
Selanjutnya, klik kanan Execution Plan dan pilih Compare Showplan . Kemudian, pilih file yang Anda simpan tadi. Anda harus memiliki output yang sama seperti pada Gambar 10 di bawah ini.
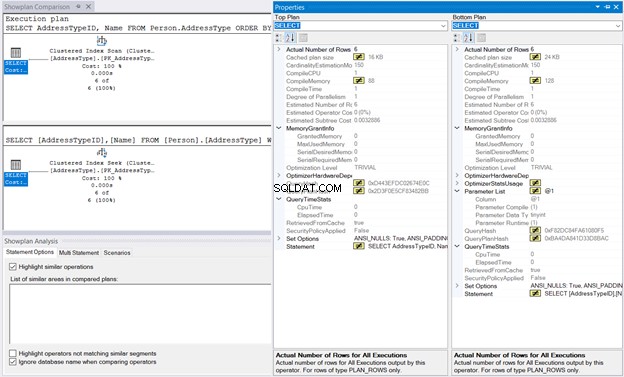
MemoryGrant dan QueryTimeStats adalah sama. Memori Kompilasi 128 KB digunakan dalam Pencarian Indeks Terkelompok dibandingkan dengan 88KB dari Pemindaian Indeks Berkelompok hampir dapat diabaikan. Tanpa perbandingan angka-angka ini, eksekusinya akan terasa sama.
2. Menghindari Pemindaian Tabel
Ini terjadi ketika Anda tidak memiliki file index. Alih-alih mencari nilai menggunakan indeks, SQL Server akan memindai baris satu per satu hingga mendapatkan apa yang Anda butuhkan dalam kueri Anda. Ini akan banyak tertinggal di meja besar. Solusi sederhananya adalah dengan menambahkan indeks yang sesuai.
Berikut adalah contoh rencana eksekusi dengan Scan Tabel operator pada Gambar 11.
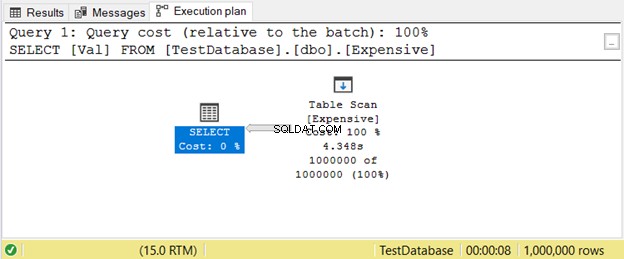
3. Mengelola Kinerja Sortir
Karena berasal dari namanya, itu mengubah urutan baris. Ini bisa menjadi operasi yang mahal.
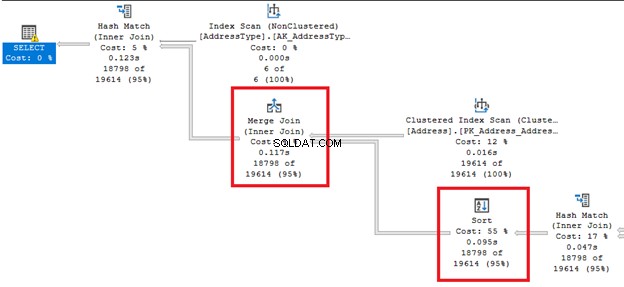
Lihat garis panah gemuk dari kanan dan kiri Urut operator. Karena pengoptimal kueri memutuskan untuk melakukan Gabung gabung , Urutan Dibutuhkan. Perhatikan juga bahwa ia memiliki persentase biaya tertinggi dari semua operator (55%).
Sortir bisa lebih merepotkan jika SQL Server perlu memesan baris beberapa kali. Anda dapat menghindari operator ini jika tabel Anda telah diurutkan sebelumnya berdasarkan persyaratan kueri. Atau Anda dapat memecah satu kueri menjadi beberapa kueri.
4. Hilangkan Pencarian Kunci
Pada Gambar 4 sebelumnya, SQL Server merekomendasikan menambahkan indeks lain. Saya melakukannya, tetapi itu tidak memberi saya apa yang saya inginkan. Sebaliknya, itu memberi saya Pencarian Indeks ke indeks baru yang dipasangkan dengan Pencarian Kunci operator.
Jadi, indeks baru menambahkan langkah ekstra.
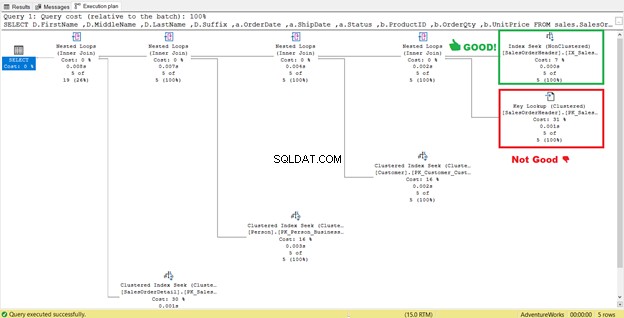
Apa Pencarian Kunci ini operator lakukan?
Pemroses kueri menggunakan indeks non-clustered baru yang diberi kotak hijau pada Gambar 13. Karena kueri kami memerlukan kolom yang tidak ada dalam indeks baru, kueri perlu mendapatkan data tersebut dengan bantuan Pencarian Kunci dari indeks berkerumun. Bagaimana kita tahu ini? Arahkan mouse Anda ke Pencarian Kunci mengungkapkan beberapa propertinya dan membuktikan pendapat kami.
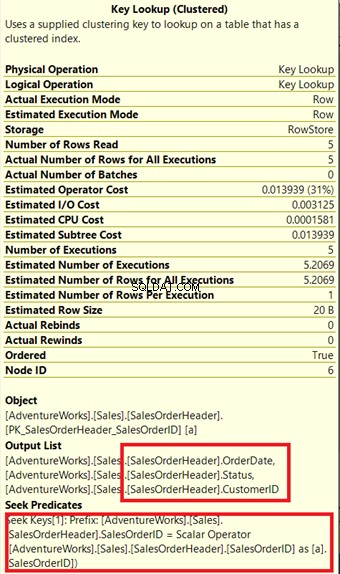
Pada Gambar 14, perhatikan Daftar Keluaran. Kita perlu mengambil 3 kolom menggunakan PK_SalesOrderHeader_SalesOrderID indeks berkerumun. Untuk menghapus ini, Anda harus menyertakan kolom ini di file index. Ini paket baru setelah kolom ini disertakan.
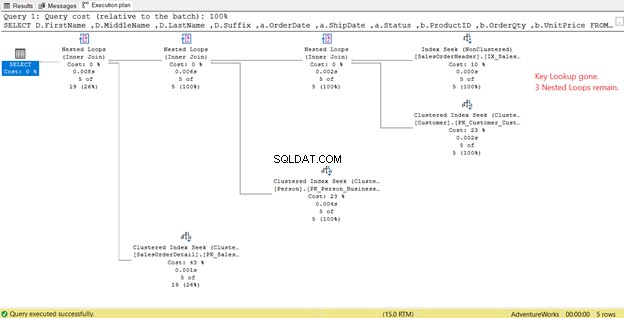
Pada Gambar 14, kita melihat 4 Loop Bersarang . Yang keempat diperlukan untuk Pencarian Kunci added yang ditambahkan . Namun setelah menambahkan 3 kolom sebagai kolom yang Disertakan ke dalam indeks baru, hanya 3 Loop Bersarang tetap, dan Pencarian Kunci dihapus. Kami tidak memerlukan langkah tambahan.
5. Paralelisme dalam Rencana Eksekusi SQL Server
Sejauh ini, Anda melihat rencana eksekusi dalam eksekusi serial. Tapi inilah rencana yang memanfaatkan eksekusi paralel. Ini berarti bahwa lebih dari 1 prosesor digunakan oleh pengoptimal kueri untuk menjalankan kueri. Saat kami menggunakan eksekusi paralel, kami melihat Paralelisme operator dalam paket, dan perubahan lainnya juga.
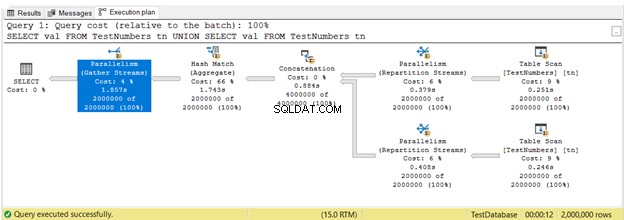
Pada Gambar 16, 3 Paralelisme operator digunakan. Perhatikan juga bahwa Scan Tabel ikon operator sedikit berbeda. Ini terjadi ketika eksekusi paralel digunakan.
Paralelisme pada dasarnya tidak buruk. Ini meningkatkan kecepatan kueri dengan memanfaatkan lebih banyak inti prosesor. Namun, ia menggunakan lebih banyak sumber daya CPU. Ketika banyak kueri Anda menggunakan paralelisme, itu memperlambat server. Anda mungkin ingin memeriksa ambang biaya untuk pengaturan paralelisme di SQL Server Anda.
5. Praktik Terbaik untuk pengoptimalan Kueri SQL
Sejauh ini, kami telah menangani pengoptimalan kueri SQL dengan metode yang mengungkap masalah yang sulit dikenali. Tetapi ada cara untuk menemukannya dalam kode. Berikut adalah beberapa bau kode dalam SQL.
Menggunakan SELECT *
terburu-buru? Kemudian mengetik * bisa lebih mudah daripada menentukan nama kolom. Namun, ada tangkapan. Kolom yang tidak Anda perlukan akan membuat kueri Anda tertinggal.
Ada bukti. Contoh kueri yang saya gunakan untuk Gambar 15 adalah ini:
USE AdventureWorks
GO
SELECT
d.FirstName
,d.MiddleName
,d.LastName
,d.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = d.BusinessEntityID
WHERE a.ShipDate = '07/11/2011'
Kami sudah mengoptimalkannya. Tapi mari kita ubah ke SELECT *
USE AdventureWorks
GO
SELECT *
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = d.BusinessEntityID
WHERE a.ShipDate = '07/11/2011'
Ini lebih pendek, tapi periksa Rencana Eksekusi di bawah ini:
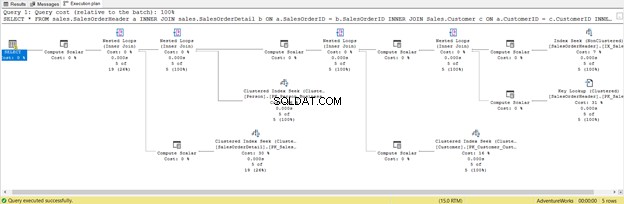
Ini adalah konsekuensi dari memasukkan semua kolom, bahkan yang tidak Anda butuhkan. Itu mengembalikan Pencarian Kunci dan banyak Compute Scalar . Singkatnya, kueri ini memiliki beban yang berat dan akibatnya akan tertinggal. Perhatikan juga peringatan di operator SELECT. Itu tidak ada sebelumnya. Sia-sia!
Fungsi dalam Klausa WHERE atau JOIN
Bau kode lain memiliki fungsi dalam klausa WHERE. Pertimbangkan 2 pernyataan SELECT berikut yang memiliki kumpulan hasil yang sama. Perbedaannya terletak pada klausa WHERE.
SELECT
D.FirstName
,D.MiddleName
,D.LastName
,D.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = D.BusinessEntityID
WHERE YEAR(a.ShipDate) = 2011
AND MONTH(a.ShipDate) = 7
SELECT
D.FirstName
,D.MiddleName
,D.LastName
,D.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = D.BusinessEntityID
WHERE a.ShipDate BETWEEN '07/1/2011' AND '07/31/2011'
SELECT pertama menggunakan fungsi tanggal YEAR dan MONTH untuk menunjukkan tanggal pengiriman dalam Juli 2011. Pernyataan SELECT kedua menggunakan operator BETWEEN dengan literal tanggal.
Pernyataan SELECT pertama akan memiliki rencana eksekusi yang mirip dengan Gambar 4 tetapi tanpa rekomendasi indeks. Yang kedua akan memiliki rencana eksekusi yang lebih baik seperti Gambar 15.
Yang dioptimalkan lebih baik sudah jelas.
Penggunaan Wildcard
Seberapa liar wildcard dapat memengaruhi pengoptimalan kueri SQL kami? Mari kita beri contoh.
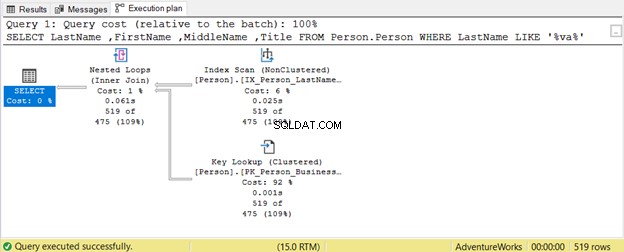
Kueri mencoba mencari keberadaan string dalam Nama Belakang dalam posisi apapun. Oleh karena itu, Nama belakang LIKE '%va%' . Ini tidak efisien pada tabel besar karena baris akan diperiksa satu per satu untuk keberadaan string itu. Itulah mengapa Pemindaian Indeks digunakan. Karena tidak ada indeks yang menyertakan Judul kolom, Pencarian Kunci juga digunakan.
Ini dapat diperbaiki dengan desain.
Apakah aplikasi panggilan memerlukan itu? Atau apakah cukup menggunakan LIKE 'va%'?
LIKE 'va%' menggunakan Index Seek karena tabel memiliki indeks pada nama belakang , nama depan , dan nama tengah .
Bisakah Anda juga menambahkan lebih banyak filter di klausa WHERE untuk mengurangi pembacaan catatan?
Jawaban Anda atas pertanyaan ini akan membantu Anda memperbaiki kueri ini.
Konversi Tersirat
SQL Server melakukan konversi implisit di belakang layar untuk merekonsiliasi tipe data saat membandingkan nilai. Misalnya, lebih mudah untuk menetapkan nomor ke kolom string tanpa tanda kutip. Tapi ada tangkapan. Efeknya serupa ketika Anda menggunakan fungsi dalam klausa WHERE.
SELECT
NationalIDNumber
,JobTitle
,HireDate
FROM HumanResources.Employee
WHERE NationalIDNumber = 56920285
NationalIDNumner adalah NVARCHAR(15) tetapi disamakan dengan angka. Ini akan berjalan dengan sukses karena konversi implisit. Tapi perhatikan rencana eksekusi pada Gambar 19 di bawah ini.
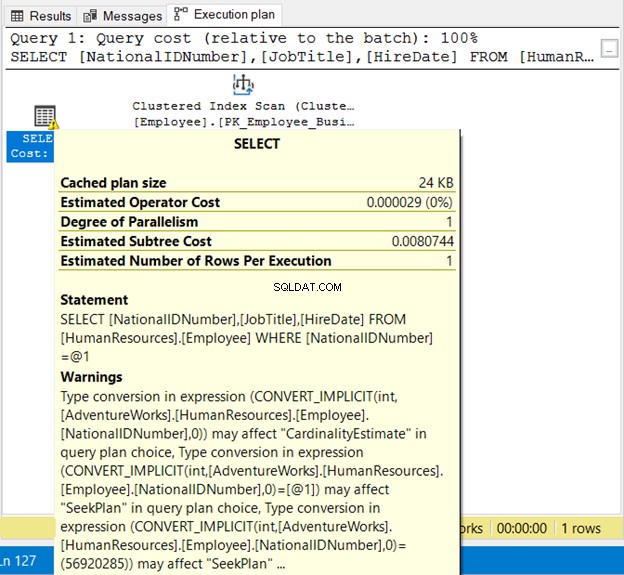
Kami melihat 2 hal buruk di sini. Pertama, peringatan. Kemudian, Pemindaian Indeks . Pemindaian indeks terjadi karena konversi implisit. Jadi, pastikan untuk menyertakan string dalam tanda kutip atau uji nilai literal dengan tipe data yang sama dengan kolom.
Hasil Pengoptimalan Kueri SQL
Itu dia. Apakah dasar-dasar pengoptimalan kueri SQL membuat Anda merasa sedikit siap untuk kueri Anda? Mari kita rekap.
- Jika Anda ingin kueri Anda dioptimalkan, mulailah dengan desain database yang baik.
- Jika database sudah dalam produksi, temukan kueri bermasalah menggunakan laporan standar SQL Server.
- Pelajari seberapa besar dampak kueri lambat dengan pembacaan logis dari STATISTICS IO.
- Menggali lebih dalam kisah kueri lambat Anda dengan Rencana Eksekusi.
- Tonton 4 bau kode yang memperlambat kueri Anda.
Ada tips pengoptimalan kueri SQL lainnya untuk membuat kueri lambat berjalan cepat. Seperti yang saya katakan di awal, ini adalah topik besar. Jadi, beri tahu kami di bagian Komentar apa lagi yang kami lewatkan.
Dan jika Anda menyukai postingan ini, bagikan ke platform media sosial favorit Anda.
Lebih Banyak Pengoptimalan Kueri SQL dari Artikel Sebelumnya
Jika Anda membutuhkan lebih banyak contoh, berikut adalah beberapa posting berguna yang terkait dengan teknik pengoptimalan kueri di SQL Server.
- Apakah kinerja subkueri buruk? Lihat Panduan Mudah tentang Cara Menggunakan Subqueries di SQL Server .
- Menggunakan HierarchyID vs. desain induk/anak – mana yang lebih cepat? Kunjungi Cara Menggunakan SQL Server HierarchyID Melalui Contoh Mudah .
- Dapatkah kueri basis data grafik mengungguli persamaan relasionalnya dalam sistem rekomendasi waktu nyata? Lihat Cara Memanfaatkan Fitur Database Grafik SQL Server .
- Mana yang lebih cepat:COALESCE atau ISNULL? Cari tahu di Jawaban Teratas untuk 5 Pertanyaan Pembakaran pada Fungsi SQL COALESCE .
- SELECT FROM View vs. SELECT FROM Base Tables – Mana yang Akan Berjalan Lebih Cepat? Kunjungi 3 Tips Teratas yang Perlu Anda Ketahui untuk Menulis Tampilan SQL Lebih Cepat .
- CTE vs. Tabel Sementara vs. Subkueri. Ketahui mana yang akan menang di Semua yang Perlu Anda Ketahui Tentang SQL CTE di Satu Tempat .
- Menggunakan SQL SUBSTRING dalam Klausa WHERE – Jebakan Performa? Lihat apakah itu benar dengan contoh di Bagaimana Mengurai String Seperti Seorang Profesional Menggunakan Fungsi SQL SUBSTRING()?
- SQL UNION ALL Lebih Cepat Dari UNION. Ketahui alasannya di SQL UNION Cheat Sheet dengan 10 Tips Mudah dan Berguna .