Di Bagian 1 seri ini, Anda menggunakan Flask dan Connexion untuk membuat REST API yang menyediakan operasi CRUD ke struktur dalam memori sederhana yang disebut PEOPLE . Itu berhasil untuk mendemonstrasikan bagaimana modul Connexion membantu Anda membangun REST API yang bagus bersama dengan dokumentasi interaktif.
Seperti yang dicatat beberapa orang dalam komentar untuk Bagian 1, PEOPLE struktur diinisialisasi ulang setiap kali aplikasi dimulai ulang. Dalam artikel ini, Anda akan mempelajari cara menyimpan PEOPLE struktur, dan tindakan yang disediakan API, ke database menggunakan SQLAlchemy dan Marshmallow.
SQLAlchemy menyediakan Object Relational Model (ORM), yang menyimpan objek Python ke representasi database dari data objek. Itu dapat membantu Anda terus berpikir dengan cara Pythonic dan tidak peduli dengan bagaimana data objek akan direpresentasikan dalam database.
Marshmallow menyediakan fungsionalitas untuk membuat serial dan deserialize objek Python saat mereka mengalir keluar dan masuk ke REST API berbasis JSON kami. Marshmallow mengonversi instance kelas Python menjadi objek yang dapat dikonversi ke JSON.
Anda dapat menemukan kode Python untuk artikel ini di sini.
Bonus Gratis: Klik di sini untuk mengunduh salinan Panduan "Contoh REST API" dan mendapatkan pengenalan langsung tentang prinsip-prinsip Python + REST API dengan contoh yang dapat ditindaklanjuti.
Untuk Siapa Artikel Ini
Jika Anda menikmati Bagian 1 dari seri ini, artikel ini akan memperluas sabuk alat Anda lebih jauh. Anda akan menggunakan SQLAlchemy untuk mengakses database dengan cara yang lebih Pythonic daripada SQL langsung. Anda juga akan menggunakan Marshmallow untuk membuat serial dan deserialize data yang dikelola oleh REST API. Untuk melakukan ini, Anda akan memanfaatkan fitur Pemrograman Berorientasi Objek dasar yang tersedia di Python.
Anda juga akan menggunakan SQLAlchemy untuk membuat database serta berinteraksi dengannya. Ini diperlukan untuk mengaktifkan dan menjalankan REST API dengan PEOPLE data yang digunakan di Bagian 1.
Aplikasi web yang disajikan di Bagian 1 akan memiliki file HTML dan JavaScript yang dimodifikasi dengan cara kecil untuk mendukung perubahan juga. Anda dapat meninjau versi final kode dari Bagian 1 di sini.
Ketergantungan Tambahan
Sebelum Anda mulai membangun fungsionalitas baru ini, Anda harus memperbarui virtualenv yang Anda buat untuk menjalankan kode Bagian 1, atau membuat yang baru untuk proyek ini. Cara termudah untuk melakukannya setelah Anda mengaktifkan virtualenv Anda adalah dengan menjalankan perintah ini:
$ pip install Flask-SQLAlchemy flask-marshmallow marshmallow-sqlalchemy marshmallow
Ini menambahkan lebih banyak fungsionalitas ke virtualenv Anda:
-
Flask-SQLAlchemymenambahkan SQLAlchemy, bersama dengan beberapa ikatan ke Flask, memungkinkan program untuk mengakses database. -
flask-marshmallowmenambahkan bagian Flask dari Marshmallow, yang memungkinkan program mengonversi objek Python ke dan dari struktur serial. -
marshmallow-sqlalchemymenambahkan beberapa pengait Marshmallow ke SQLAlchemy untuk memungkinkan program membuat serial dan deserialize objek Python yang dihasilkan oleh SQLAlchemy. -
marshmallowmenambahkan sebagian besar fungsi Marshmallow.
Data Orang
Seperti disebutkan di atas, PEOPLE struktur data pada artikel sebelumnya adalah kamus Python di dalam memori. Dalam kamus itu, Anda menggunakan nama belakang orang tersebut sebagai kunci pencarian. Struktur data terlihat seperti ini dalam kode:
# Data to serve with our API
PEOPLE = {
"Farrell": {
"fname": "Doug",
"lname": "Farrell",
"timestamp": get_timestamp()
},
"Brockman": {
"fname": "Kent",
"lname": "Brockman",
"timestamp": get_timestamp()
},
"Easter": {
"fname": "Bunny",
"lname": "Easter",
"timestamp": get_timestamp()
}
}
Modifikasi yang Anda buat pada program akan memindahkan semua data ke tabel database. Ini berarti data akan disimpan ke disk Anda dan akan ada di antara menjalankan server.py program.
Karena nama belakang adalah kunci kamus, kode tersebut membatasi pengubahan nama belakang seseorang:hanya nama depan yang dapat diubah. Selain itu, pindah ke database akan memungkinkan Anda untuk mengubah nama belakang karena tidak lagi digunakan sebagai kunci pencarian untuk seseorang.
Secara konseptual, tabel database dapat dianggap sebagai array dua dimensi di mana baris adalah catatan, dan kolom adalah bidang dalam catatan tersebut.
Tabel database biasanya memiliki nilai integer yang bertambah secara otomatis sebagai kunci pencarian untuk baris. Ini disebut kunci utama. Setiap record dalam tabel akan memiliki kunci utama yang nilainya unik di seluruh tabel. Memiliki kunci utama yang independen dari data yang disimpan dalam tabel membebaskan Anda untuk mengubah bidang lain di baris.
Catatan:
Kunci utama yang bertambah secara otomatis berarti bahwa database menangani:
- Menambahkan bidang kunci utama terbesar yang ada setiap kali catatan baru dimasukkan ke dalam tabel
- Menggunakan nilai tersebut sebagai kunci utama untuk data yang baru dimasukkan
Ini menjamin kunci utama yang unik saat tabel berkembang.
Anda akan mengikuti konvensi database penamaan tabel sebagai singular, sehingga tabel akan disebut person . Menerjemahkan PEOPLE our kami struktur di atas menjadi tabel database bernama person memberi Anda ini:
| person_id | lnama | namanama | stempel waktu |
|---|---|---|---|
| 1 | Farrell | Doug | 08-08-2018 21:16:01.888444 |
| 2 | Brockman | Kent | 08-08-2018 21:16:01.889060 |
| 3 | Paskah | Kelinci | 08-08-2018 21:16:01.886834 |
Setiap kolom dalam tabel memiliki nama field sebagai berikut:
person_id: bidang kunci utama untuk setiap oranglname: nama belakang orang tersebutfname: nama depan orang tersebuttimestamp: stempel waktu yang terkait dengan tindakan penyisipan/pembaruan
Interaksi Basis Data
Anda akan menggunakan SQLite sebagai mesin database untuk menyimpan PEOPLE data. SQLite adalah database yang paling banyak didistribusikan di dunia, dan dilengkapi dengan Python secara gratis. Cepat, melakukan semua pekerjaannya menggunakan file, dan cocok untuk banyak proyek. Ini adalah RDBMS (Sistem Manajemen Basis Data Relasional) lengkap yang mencakup SQL, bahasa dari banyak sistem basis data.
Untuk saat ini, bayangkan person tabel sudah ada dalam database SQLite. Jika Anda pernah memiliki pengalaman dengan RDBMS, Anda mungkin mengetahui SQL, Bahasa Kueri Terstruktur yang digunakan sebagian besar RDBMS untuk berinteraksi dengan database.
Tidak seperti bahasa pemrograman seperti Python, SQL tidak mendefinisikan bagaimana untuk mendapatkan data:ini menjelaskan apa data yang diinginkan, meninggalkan bagaimana hingga mesin database.
Kueri SQL yang mendapatkan semua data di person our kami tabel, diurutkan berdasarkan nama belakang, akan terlihat seperti ini:
SELECT * FROM person ORDER BY 'lname';
Kueri ini memberi tahu mesin database untuk mendapatkan semua bidang dari tabel orang dan mengurutkannya secara default, urutan menaik menggunakan lname bidang.
Jika Anda menjalankan kueri ini terhadap database SQLite yang berisi person tabel, hasilnya akan menjadi satu set catatan yang berisi semua baris dalam tabel, dengan setiap baris berisi data dari semua bidang yang membentuk satu baris. Di bawah ini adalah contoh menggunakan alat baris perintah SQLite yang menjalankan kueri di atas terhadap person tabel basis data:
sqlite> SELECT * FROM person ORDER BY lname;
2|Brockman|Kent|2018-08-08 21:16:01.888444
3|Easter|Bunny|2018-08-08 21:16:01.889060
1|Farrell|Doug|2018-08-08 21:16:01.886834
Output di atas adalah daftar semua baris di person tabel database dengan karakter pipa (‘|’) memisahkan bidang dalam baris, yang dilakukan untuk tujuan tampilan oleh SQLite.
Python sepenuhnya mampu berinteraksi dengan banyak mesin basis data dan mengeksekusi kueri SQL di atas. Hasilnya kemungkinan besar adalah daftar tupel. Daftar luar berisi semua catatan di person meja. Setiap tupel dalam individu akan berisi semua data yang mewakili setiap bidang yang ditentukan untuk baris tabel.
Mendapatkan data dengan cara ini tidak terlalu Pythonic. Daftar catatan boleh saja, tetapi setiap catatan individu hanyalah kumpulan data. Terserah program untuk mengetahui indeks setiap bidang untuk mengambil bidang tertentu. Kode Python berikut menggunakan SQLite untuk mendemonstrasikan cara menjalankan kueri di atas dan menampilkan datanya:
1import sqlite3
2
3conn = sqlite3.connect('people.db')
4cur = conn.cursor()
5cur.execute('SELECT * FROM person ORDER BY lname')
6people = cur.fetchall()
7for person in people:
8 print(f'{person[2]} {person[1]}')
Program di atas melakukan hal berikut:
-
Baris 1 mengimpor
sqlite3modul. -
Baris 3 membuat koneksi ke file database.
-
Baris 4 membuat kursor dari koneksi.
-
Baris 5 menggunakan kursor untuk menjalankan
SQLkueri yang dinyatakan sebagai string. -
Baris 6 mendapatkan semua catatan yang dikembalikan oleh
SQLkueri dan menetapkannya kepersonvariabel. -
Baris 7 &8 ulangi
persondaftar variabel dan cetak nama depan dan belakang setiap orang.
person variabel dari Baris 6 di atas akan terlihat seperti ini dengan Python:
people = [
(2, 'Brockman', 'Kent', '2018-08-08 21:16:01.888444'),
(3, 'Easter', 'Bunny', '2018-08-08 21:16:01.889060'),
(1, 'Farrell', 'Doug', '2018-08-08 21:16:01.886834')
]
Output dari program di atas terlihat seperti ini:
Kent Brockman
Bunny Easter
Doug Farrell
Dalam program di atas, Anda harus tahu bahwa nama depan seseorang ada di indeks 2 , dan nama belakang seseorang ada di indeks 1 . Lebih buruk lagi, struktur internal person juga harus diketahui setiap kali Anda melewatkan variabel iterasi person sebagai parameter untuk fungsi atau metode.
Akan jauh lebih baik jika apa yang Anda dapatkan kembali untuk person adalah objek Python, di mana masing-masing bidang adalah atribut objek. Ini adalah salah satu hal yang dilakukan SQLAlchemy.
Meja Bobby Kecil
Dalam program di atas, pernyataan SQL adalah string sederhana yang diteruskan langsung ke database untuk dieksekusi. Dalam hal ini, itu bukan masalah karena SQL adalah string literal sepenuhnya di bawah kendali program. Namun, kasus penggunaan untuk REST API Anda akan mengambil input pengguna dari aplikasi web dan menggunakannya untuk membuat kueri SQL. Ini dapat membuka aplikasi Anda untuk menyerang.
Anda akan ingat dari Bagian 1 bahwa REST API untuk mendapatkan satu person dari PEOPLE datanya seperti ini:
GET /api/people/{lname}
Ini berarti API Anda mengharapkan sebuah variabel, lname , di jalur titik akhir URL, yang digunakannya untuk menemukan satu person . Memodifikasi kode Python SQLite dari atas untuk melakukan ini akan terlihat seperti ini:
1lname = 'Farrell'
2cur.execute('SELECT * FROM person WHERE lname = \'{}\''.format(lname))
Cuplikan kode di atas melakukan hal berikut:
-
Baris 1 menyetel
lnamevariabel ke'Farrell'. Ini akan berasal dari jalur titik akhir URL REST API. -
Baris 2 menggunakan pemformatan string Python untuk membuat string SQL dan menjalankannya.
Untuk mempermudah, kode di atas menyetel lname variabel ke konstanta, tetapi sebenarnya itu akan berasal dari jalur titik akhir URL API dan bisa berupa apa saja yang disediakan oleh pengguna. SQL yang dihasilkan oleh pemformatan string terlihat seperti ini:
SELECT * FROM person WHERE lname = 'Farrell'
Ketika SQL ini dieksekusi oleh database, ia mencari person tabel untuk catatan di mana nama belakang sama dengan 'Farrell' . Inilah yang dimaksudkan, tetapi program apa pun yang menerima input pengguna juga terbuka untuk pengguna jahat. Pada program di atas, di mana lname variabel diatur oleh input yang disediakan pengguna, ini membuka program Anda untuk apa yang disebut serangan injeksi SQL. Inilah yang dikenal sebagai Little Bobby Tables:
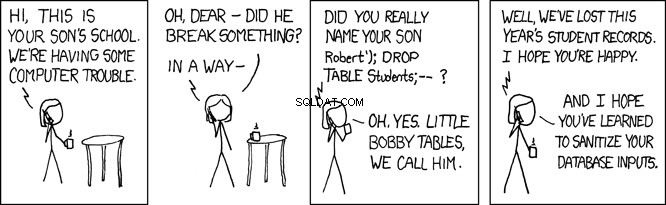
Misalnya, bayangkan pengguna jahat memanggil REST API Anda dengan cara ini:
GET /api/people/Farrell');DROP TABLE person;
Permintaan REST API di atas menyetel lname variabel ke 'Farrell');DROP TABLE person;' , yang dalam kode di atas akan menghasilkan pernyataan SQL ini:
SELECT * FROM person WHERE lname = 'Farrell');DROP TABLE person;
Pernyataan SQL di atas valid, dan ketika dijalankan oleh database akan menemukan satu record di mana lname cocok dengan 'Farrell' . Kemudian, ia akan menemukan karakter pembatas pernyataan SQL ; dan akan pergi ke depan dan menjatuhkan seluruh meja. Ini pada dasarnya akan merusak aplikasi Anda.
Anda dapat melindungi program Anda dengan membersihkan semua data yang Anda dapatkan dari pengguna aplikasi Anda. Membersihkan data dalam konteks ini berarti meminta program Anda memeriksa data yang diberikan pengguna dan memastikannya tidak mengandung sesuatu yang berbahaya bagi program. Ini mungkin sulit dilakukan dengan benar dan harus dilakukan di mana pun data pengguna berinteraksi dengan database.
Ada cara lain yang jauh lebih mudah:gunakan SQLAlchemy. Ini akan membersihkan data pengguna untuk Anda sebelum membuat pernyataan SQL. Ini adalah keuntungan dan alasan besar lainnya untuk menggunakan SQLAlchemy saat bekerja dengan database.
Memodelkan Data Dengan SQLAlchemy
SQLAlchemy adalah proyek besar dan menyediakan banyak fungsi untuk bekerja dengan database menggunakan Python. Salah satu hal yang disediakannya adalah ORM, atau Object Relational Mapper, dan inilah yang akan Anda gunakan untuk membuat dan bekerja dengan person tabel basis data. Ini memungkinkan Anda untuk memetakan deretan bidang dari tabel database ke objek Python.
Pemrograman Berorientasi Objek memungkinkan Anda untuk menghubungkan data bersama dengan perilaku, fungsi yang beroperasi pada data tersebut. Dengan membuat kelas SQLAlchemy, Anda dapat menghubungkan bidang dari baris tabel database ke perilaku, memungkinkan Anda untuk berinteraksi dengan data. Berikut definisi kelas SQLAlchemy untuk data di person tabel basis data:
class Person(db.Model):
__tablename__ = 'person'
person_id = db.Column(db.Integer,
primary_key=True)
lname = db.Column(db.String)
fname = db.Column(db.String)
timestamp = db.Column(db.DateTime,
default=datetime.utcnow,
onupdate=datetime.utcnow)
Kelas Person mewarisi dari db.Model , yang akan Anda dapatkan saat mulai membuat kode program. Untuk saat ini, itu berarti Anda mewarisi dari kelas dasar yang disebut Model , menyediakan atribut dan fungsionalitas umum untuk semua kelas yang diturunkan darinya.
Definisi lainnya adalah atribut tingkat kelas yang didefinisikan sebagai berikut:
-
__tablename__ = 'person'menghubungkan definisi kelas kepersontabel basis data. -
person_id = db.Column(db.Integer, primary_key=True)membuat kolom database yang berisi bilangan bulat yang bertindak sebagai kunci utama untuk tabel. Ini juga memberi tahu database bahwaperson_idakan menjadi nilai Integer otomatis. -
lname = db.Column(db.String)membuat bidang nama belakang, kolom database yang berisi nilai string. -
fname = db.Column(db.String)membuat bidang nama depan, kolom database yang berisi nilai string. -
timestamp = db.Column(db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)membuat bidang stempel waktu, kolom basis data yang berisi nilai tanggal/waktu.default=datetime.utcnowparameter default nilai cap waktu keutcnowsaat ini nilai saat record dibuat.onupdate=datetime.utcnowparameter memperbarui stempel waktu denganutcnowsaat ini nilai saat catatan diperbarui.
Catatan:Stempel Waktu UTC
Anda mungkin bertanya-tanya mengapa stempel waktu di kelas di atas default dan diperbarui oleh datetime.utcnow() metode, yang mengembalikan UTC, atau Waktu Universal Terkoordinasi. Ini adalah cara menstandardisasi sumber stempel waktu Anda.
Sumber, atau waktu nol, adalah garis yang membentang ke utara dan selatan dari kutub utara bumi ke selatan melalui Inggris. Ini adalah zona waktu nol dari mana semua zona waktu lainnya diimbangi. Dengan menggunakan ini sebagai sumber waktu nol, stempel waktu Anda diimbangi dari titik referensi standar ini.
Jika aplikasi Anda diakses dari zona waktu yang berbeda, Anda memiliki cara untuk melakukan perhitungan tanggal/waktu. Yang Anda butuhkan hanyalah stempel waktu UTC dan zona waktu tujuan.
Jika Anda menggunakan zona waktu lokal sebagai sumber stempel waktu Anda, maka Anda tidak dapat melakukan penghitungan tanggal/waktu tanpa informasi tentang zona waktu lokal yang diimbangi dari waktu nol. Tanpa informasi sumber cap waktu, Anda tidak dapat melakukan perbandingan tanggal/waktu atau matematika sama sekali.
Bekerja dengan stempel waktu berdasarkan UTC adalah standar yang baik untuk diikuti. Berikut adalah situs toolkit untuk bekerja dengan dan lebih memahami mereka.
Ke mana tujuan Anda dengan Person ini definisi kelas? Tujuan akhirnya adalah untuk dapat menjalankan kueri menggunakan SQLAlchemy dan mendapatkan kembali daftar instance dari Person kelas. Sebagai contoh, mari kita lihat pernyataan SQL sebelumnya:
SELECT * FROM people ORDER BY lname;
Tampilkan program contoh kecil yang sama dari atas, tetapi sekarang menggunakan SQLAlchemy:
1from models import Person
2
3people = Person.query.order_by(Person.lname).all()
4for person in people:
5 print(f'{person.fname} {person.lname}')
Mengabaikan baris 1 untuk saat ini, yang Anda inginkan hanyalah person catatan diurutkan dalam urutan menaik berdasarkan lname bidang. Apa yang Anda dapatkan kembali dari pernyataan SQLAlchemy Person.query.order_by(Person.lname).all() adalah daftar Person objek untuk semua record dalam person tabel database dalam urutan itu. Pada program di atas, people variabel berisi daftar Person objek.
Program berulang pada person variabel, mengambil setiap person pada gilirannya dan mencetak nama depan dan belakang orang tersebut dari database. Perhatikan bahwa program tidak harus menggunakan indeks untuk mendapatkan fname atau lname values:ia menggunakan atribut yang ditentukan pada Person objek.
Menggunakan SQLAlchemy memungkinkan Anda untuk berpikir dalam kerangka objek dengan perilaku daripada SQL mentah . Ini menjadi lebih bermanfaat ketika tabel database Anda menjadi lebih besar dan interaksi lebih kompleks.
Serializing/Deserializing Data Model
Bekerja dengan data model SQLAlchemy di dalam program Anda sangat nyaman. Ini sangat nyaman dalam program yang memanipulasi data, mungkin membuat perhitungan atau menggunakannya untuk membuat presentasi di layar. Aplikasi Anda adalah REST API yang pada dasarnya menyediakan operasi CRUD pada data, dan karena itu tidak melakukan banyak manipulasi data.
REST API bekerja dengan data JSON, dan di sini Anda dapat mengalami masalah dengan model SQLAlchemy. Karena data yang dikembalikan oleh SQLAlchemy adalah instance kelas Python, Connexion tidak dapat membuat serial instance kelas ini ke data berformat JSON. Ingat dari Bagian 1 bahwa Connexion adalah alat yang Anda gunakan untuk merancang dan mengonfigurasi REST API menggunakan file YAML, dan menghubungkan metode Python ke sana.
Dalam konteks ini, serialisasi berarti mengubah objek Python, yang dapat berisi objek Python lain dan tipe data kompleks, menjadi struktur data yang lebih sederhana yang dapat diuraikan menjadi tipe data JSON, yang tercantum di sini:
string: jenis stringnumber: angka yang didukung oleh Python (bilangan bulat, float, long)object: objek JSON, yang kira-kira setara dengan kamus Pythonarray: kira-kira setara dengan Daftar Pythonboolean: direpresentasikan dalam JSON sebagaitrueataufalse, tetapi dengan Python sebagaiTrueatauFalsenull: dasarnya adalahNonedengan Python
Sebagai contoh, Person . Anda kelas berisi stempel waktu, yang merupakan DateTime Python . Tidak ada definisi tanggal/waktu di JSON, jadi stempel waktu harus diubah menjadi string agar ada dalam struktur JSON.
Person . Anda class cukup sederhana sehingga mendapatkan atribut data darinya dan membuat kamus secara manual untuk kembali dari titik akhir URL REST kami tidak akan terlalu sulit. Dalam aplikasi yang lebih kompleks dengan banyak model SQLAlchemy yang lebih besar, ini tidak akan terjadi. Solusi yang lebih baik adalah dengan menggunakan modul bernama Marshmallow untuk melakukan pekerjaan untuk Anda.
Marshmallow membantu Anda membuat PersonSchema kelas, yang seperti SQLAlchemy Person kelas yang kita buat. Namun di sini, alih-alih memetakan tabel database dan nama bidang ke kelas dan atributnya, PersonSchema class mendefinisikan bagaimana atribut kelas akan diubah menjadi format ramah-JSON. Berikut definisi kelas Marshmallow untuk data di person kami tabel:
class PersonSchema(ma.ModelSchema):
class Meta:
model = Person
sqla_session = db.session
Kelas PersonSchema mewarisi dari ma.ModelSchema , yang akan Anda dapatkan saat mulai membuat kode program. Untuk saat ini, ini berarti PersonSchema mewarisi dari kelas dasar Marshmallow yang disebut ModelSchema , menyediakan atribut dan fungsionalitas umum untuk semua kelas yang diturunkan darinya.
Definisi selanjutnya adalah sebagai berikut:
-
class Metamendefinisikan kelas bernamaMetadalam kelas Anda.ModelSchemakelas yangPersonSchemaclass mewarisi dari pencarianMetainternal ini class dan menggunakannya untuk menemukan model SQLAlchemyPersondandb.session. Beginilah cara Marshmallow menemukan atribut diPersonclass dan jenis atribut tersebut sehingga ia tahu cara membuat serial/deserialisasi mereka. -
modelmemberi tahu kelas model SQLAlchemy apa yang akan digunakan untuk membuat serial/deserialisasi data ke dan dari. -
db.sessionmemberi tahu kelas sesi database apa yang digunakan untuk mengintrospeksi dan menentukan tipe data atribut.
Ke mana tujuan Anda dengan definisi kelas ini? Anda ingin dapat membuat serial sebuah instance dari Person kelas menjadi data JSON, dan untuk deserialize data JSON dan membuat Person instance kelas darinya.
Buat Basis Data yang Diinisialisasi
SQLAlchemy menangani banyak interaksi khusus untuk database tertentu dan memungkinkan Anda fokus pada model data serta cara menggunakannya.
Sekarang Anda benar-benar akan membuat database, seperti yang disebutkan sebelumnya, Anda akan menggunakan SQLite. Anda melakukan ini karena beberapa alasan. Itu datang dengan Python dan tidak harus diinstal sebagai modul terpisah. Ini menyimpan semua informasi database dalam satu file dan karena itu mudah diatur dan digunakan.
Menginstal server database terpisah seperti MySQL atau PostgreSQL akan berfungsi dengan baik tetapi akan memerlukan menginstal sistem tersebut dan menjalankannya, yang berada di luar cakupan artikel ini.
Karena SQLAlchemy menangani database, dalam banyak hal tidak masalah apa database yang mendasarinya.
Anda akan membuat program utilitas baru bernama build_database.py untuk membuat dan menginisialisasi people.db SQLite file database yang berisi person . Anda tabel basis data. Sepanjang jalan, Anda akan membuat dua modul Python, config.py dan models.py , yang akan digunakan oleh build_database.py dan server.py . yang dimodifikasi dari Bagian 1.
Di sinilah Anda dapat menemukan kode sumber untuk modul yang akan Anda buat, yang diperkenalkan di sini:
-
config.pymendapatkan modul yang diperlukan diimpor ke dalam program dan dikonfigurasi. Ini termasuk Flask, Connexion, SQLAlchemy, dan Marshmallow. Karena akan digunakan olehbuild_database.pydanserver.py, beberapa bagian dari konfigurasi hanya akan berlaku untukserver.pyaplikasi. -
models.pyadalah modul tempat Anda akan membuatPersonSQLAlchemy danPersonSchemaDefinisi kelas Marshmallow dijelaskan di atas. Modul ini bergantung padaconfig.pyuntuk beberapa objek yang dibuat dan dikonfigurasi di sana.
Modul Konfigurasi
config.py modul, seperti namanya, adalah tempat semua informasi konfigurasi dibuat dan diinisialisasi. Kami akan menggunakan modul ini untuk build_database.py kami file program dan server.py yang akan segera diperbarui file dari artikel Bagian 1. Ini berarti kita akan mengkonfigurasi Flask, Connexion, SQLAlchemy, dan Marshmallow di sini.
Meskipun build_database.py Program tidak menggunakan Flask, Connexion, atau Marshmallow, tetapi menggunakan SQLAlchemy untuk membuat koneksi kita ke database SQLite. Berikut adalah kode untuk config.py modul:
1import os
2import connexion
3from flask_sqlalchemy import SQLAlchemy
4from flask_marshmallow import Marshmallow
5
6basedir = os.path.abspath(os.path.dirname(__file__))
7
8# Create the Connexion application instance
9connex_app = connexion.App(__name__, specification_dir=basedir)
10
11# Get the underlying Flask app instance
12app = connex_app.app
13
14# Configure the SQLAlchemy part of the app instance
15app.config['SQLALCHEMY_ECHO'] = True
16app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:////' + os.path.join(basedir, 'people.db')
17app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
18
19# Create the SQLAlchemy db instance
20db = SQLAlchemy(app)
21
22# Initialize Marshmallow
23ma = Marshmallow(app)
Inilah yang dilakukan kode di atas:
-
Baris 2 – 4 impor Connexion seperti yang Anda lakukan di
server.pyprogram dari Bagian 1. Ini juga mengimporSQLAlchemydariflask_sqlalchemymodul. Ini memberikan akses database program Anda. Terakhir, ia mengimporMarshmallowdariflask_marshamllowmodul. -
Baris 6 membuat variabel
basedirmenunjuk ke direktori tempat program dijalankan. -
Baris 9 menggunakan
basedirvariabel untuk membuat instance aplikasi Connexion dan memberikannya jalur keswagger.ymlberkas. -
Baris 12 membuat variabel
app, yang merupakan instance Flask yang diinisialisasi oleh Connexion. -
Baris 15 menggunakan
appvariabel untuk mengonfigurasi nilai yang digunakan oleh SQLAlchemy. Pertama setSQLALCHEMY_ECHOkeTrue. Ini menyebabkan SQLAlchemy menggemakan pernyataan SQL yang dijalankannya ke konsol. Ini sangat berguna untuk men-debug masalah saat membangun program database. Setel ini keFalseuntuk lingkungan produksi. -
Baris 16 set
SQLALCHEMY_DATABASE_URIkesqlite:////' + os.path.join(basedir, 'people.db'). Ini memberitahu SQLAlchemy untuk menggunakan SQLite sebagai database, dan sebuah file bernamapeople.dbdi direktori saat ini sebagai file database. Mesin database yang berbeda, seperti MySQL dan PostgreSQL, akan memilikiSQLALCHEMY_DATABASE_URIyang berbeda string untuk mengonfigurasinya. -
Baris 17 set
SQLALCHEMY_TRACK_MODIFICATIONSmenjadiFalse, mematikan sistem peristiwa SQLAlchemy, yang diaktifkan secara default. Sistem peristiwa menghasilkan peristiwa yang berguna dalam program yang digerakkan oleh peristiwa tetapi menambahkan overhead yang signifikan. Karena Anda tidak membuat program berdasarkan peristiwa, nonaktifkan fitur ini. -
Baris 19 membuat
dbvariabel dengan memanggilSQLAlchemy(app). Ini menginisialisasi SQLAlchemy dengan meneruskanappinformasi konfigurasi baru saja diatur.dbvariabel adalah apa yang diimpor kebuild_database.pyprogram untuk memberikan akses ke SQLAlchemy dan database. Ini akan melayani tujuan yang sama diserver.pyprogram danpeople.pymodul. -
Baris 23 membuat
mavariabel dengan memanggilMarshmallow(app). Ini menginisialisasi Marshmallow dan memungkinkannya untuk mengintrospeksi komponen SQLAlchemy yang dilampirkan ke aplikasi. Inilah mengapa Marshmallow diinisialisasi setelah SQLAlchemy.
Modul Model
models.py modul dibuat untuk menyediakan Person dan PersonSchema kelas persis seperti yang dijelaskan pada bagian di atas tentang pemodelan dan serialisasi data. Berikut adalah kode untuk modul tersebut:
1from datetime import datetime
2from config import db, ma
3
4class Person(db.Model):
5 __tablename__ = 'person'
6 person_id = db.Column(db.Integer, primary_key=True)
7 lname = db.Column(db.String(32), index=True)
8 fname = db.Column(db.String(32))
9 timestamp = db.Column(db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)
10
11class PersonSchema(ma.ModelSchema):
12 class Meta:
13 model = Person
14 sqla_session = db.session
Inilah yang dilakukan kode di atas:
-
Baris 1 mengimpor
datetimeobjek daridatetimemodul yang disertakan dengan Python. Ini memberi Anda cara untuk membuat stempel waktu diPersonkelas. -
Baris 2 mengimpor
dbdanmavariabel instan yang didefinisikan dalamconfig.pymodul. Ini memberi modul akses ke atribut dan metode SQLAlchemy yang dilampirkan kedbvariabel, dan atribut dan metode Marshmallow yang dilampirkan kemavariabel. -
Baris 4 – 9 tentukan
Personkelas seperti yang dibahas di bagian pemodelan data di atas, tetapi sekarang Anda tahu di manadb.Modelbahwa kelas mewarisi dari berasal. Ini memberikanPersonfitur kelas SQLAlchemy, seperti koneksi ke database dan akses ke tabelnya. -
Baris 11 – 14 tentukan
PersonSchemakelas seperti yang telah dibahas pada bagian serialisasi data di atas. Kelas ini mewarisi darima.ModelSchemadan memberikanPersonSchemaclass Marshmallow features, like introspecting thePersonclass to help serialize/deserialize instances of that class.
Creating the Database
You’ve seen how database tables can be mapped to SQLAlchemy classes. Now use what you’ve learned to create the database and populate it with data. You’re going to build a small utility program to create and build the database with the People data. Here’s the build_database.py program:
1import os
2from config import db
3from models import Person
4
5# Data to initialize database with
6PEOPLE = [
7 {'fname': 'Doug', 'lname': 'Farrell'},
8 {'fname': 'Kent', 'lname': 'Brockman'},
9 {'fname': 'Bunny','lname': 'Easter'}
10]
11
12# Delete database file if it exists currently
13if os.path.exists('people.db'):
14 os.remove('people.db')
15
16# Create the database
17db.create_all()
18
19# Iterate over the PEOPLE structure and populate the database
20for person in PEOPLE:
21 p = Person(lname=person['lname'], fname=person['fname'])
22 db.session.add(p)
23
24db.session.commit()
Here’s what the above code is doing:
-
Line 2 imports the
dbinstance from theconfig.pymodul. -
Line 3 imports the
Personclass definition from themodels.pymodul. -
Lines 6 – 10 create the
PEOPLEdata structure, which is a list of dictionaries containing your data. The structure has been condensed to save presentation space. -
Lines 13 &14 perform some simple housekeeping to delete the
people.dbfile, if it exists. This file is where the SQLite database is maintained. If you ever have to re-initialize the database to get a clean start, this makes sure you’re starting from scratch when you build the database. -
Line 17 creates the database with the
db.create_all()panggilan. This creates the database by using thedbinstance imported from theconfigmodul.dbinstance is our connection to the database. -
Lines 20 – 22 iterate over the
PEOPLElist and use the dictionaries within to instantiate aPersonkelas. After it is instantiated, you call thedb.session.add(p)fungsi. This uses the database connection instancedbto access thesessionobyek. The session is what manages the database actions, which are recorded in the session. In this case, you are executing theadd(p)method to add the newPersoninstance to thesessionobjek. -
Line 24 calls
db.session.commit()to actually save all the person objects created to the database.
Catatan: At Line 22, no data has been added to the database. Everything is being saved within the session obyek. Only when you execute the db.session.commit() call at Line 24 does the session interact with the database and commit the actions to it.
In SQLAlchemy, the session is an important object. It acts as the conduit between the database and the SQLAlchemy Python objects created in a program. The session helps maintain the consistency between data in the program and the same data as it exists in the database. It saves all database actions and will update the underlying database accordingly by both explicit and implicit actions taken by the program.
Now you’re ready to run the build_database.py program to create and initialize the new database. You do so with the following command, with your Python virtual environment active:
python build_database.py
When the program runs, it will print SQLAlchemy log messages to the console. These are the result of setting SQLALCHEMY_ECHO to True in the config.py mengajukan. Much of what’s being logged by SQLAlchemy is the SQL commands it’s generating to create and build the people.db SQLite database file. Here’s an example of what’s printed out when the program is run:
2018-09-11 22:20:29,951 INFO sqlalchemy.engine.base.Engine SELECT CAST('test plain returns' AS VARCHAR(60)) AS anon_1
2018-09-11 22:20:29,951 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,952 INFO sqlalchemy.engine.base.Engine SELECT CAST('test unicode returns' AS VARCHAR(60)) AS anon_1
2018-09-11 22:20:29,952 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,956 INFO sqlalchemy.engine.base.Engine PRAGMA table_info("person")
2018-09-11 22:20:29,956 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,959 INFO sqlalchemy.engine.base.Engine
CREATE TABLE person (
person_id INTEGER NOT NULL,
lname VARCHAR,
fname VARCHAR,
timestamp DATETIME,
PRIMARY KEY (person_id)
)
2018-09-11 22:20:29,959 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,975 INFO sqlalchemy.engine.base.Engine COMMIT
2018-09-11 22:20:29,980 INFO sqlalchemy.engine.base.Engine BEGIN (implicit)
2018-09-11 22:20:29,983 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,983 INFO sqlalchemy.engine.base.Engine ('Farrell', 'Doug', '2018-09-12 02:20:29.983143')
2018-09-11 22:20:29,984 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine ('Brockman', 'Kent', '2018-09-12 02:20:29.984821')
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine ('Easter', 'Bunny', '2018-09-12 02:20:29.985462')
2018-09-11 22:20:29,986 INFO sqlalchemy.engine.base.Engine COMMIT
Using the Database
Once the database has been created, you can modify the existing code from Part 1 to make use of it. All of the modifications necessary are due to creating the person_id primary key value in our database as the unique identifier rather than the lname nilai.
Update the REST API
None of the changes are very dramatic, and you’ll start by re-defining the REST API. The list below shows the API definition from Part 1 but is updated to use the person_id variable in the URL path:
| Action | HTTP Verb | URL Path | Deskripsi |
|---|---|---|---|
| Create | POST | /api/people | Defines a unique URL to create a new person |
| Read | GET | /api/people | Defines a unique URL to read a collection of people |
| Read | GET | /api/people/{person_id} | Defines a unique URL to read a particular person by person_id |
| Update | PUT | /api/people/{person_id} | Defines a unique URL to update an existing person by person_id |
| Delete | DELETE | /api/orders/{person_id} | Defines a unique URL to delete an existing person by person_id |
Where the URL definitions required an lname value, they now require the person_id (primary key) for the person record in the people meja. This allows you to remove the code in the previous app that artificially restricted users from editing a person’s last name.
In order for you to implement these changes, the swagger.yml file from Part 1 will have to be edited. For the most part, any lname parameter value will be changed to person_id , and person_id will be added to the POST and PUT responses. You can check out the updated swagger.yml file.
Update the REST API Handlers
With the swagger.yml file updated to support the use of the person_id identifier, you’ll also need to update the handlers in the people.py file to support these changes. In the same way that the swagger.yml file was updated, you need to change the people.py file to use the person_id value rather than lname .
Here’s part of the updated person.py module showing the handler for the REST URL endpoint GET /api/people :
1from flask import (
2 make_response,
3 abort,
4)
5from config import db
6from models import (
7 Person,
8 PersonSchema,
9)
10
11def read_all():
12 """
13 This function responds to a request for /api/people
14 with the complete lists of people
15
16 :return: json string of list of people
17 """
18 # Create the list of people from our data
19 people = Person.query \
20 .order_by(Person.lname) \
21 .all()
22
23 # Serialize the data for the response
24 person_schema = PersonSchema(many=True)
25 return person_schema.dump(people).data
Here’s what the above code is doing:
-
Lines 1 – 9 import some Flask modules to create the REST API responses, as well as importing the
dbinstance from theconfig.pymodul. In addition, it imports the SQLAlchemyPersonand MarshmallowPersonSchemaclasses to access thepersondatabase table and serialize the results. -
Line 11 starts the definition of
read_all()that responds to the REST API URL endpointGET /api/peopleand returns all the records in thepersondatabase table sorted in ascending order by last name. -
Lines 19 – 22 tell SQLAlchemy to query the
persondatabase table for all the records, sort them in ascending order (the default sorting order), and return a list ofPersonPython objects as the variablepeople. -
Line 24 is where the Marshmallow
PersonSchemaclass definition becomes valuable. You create an instance of thePersonSchema, passing it the parametermany=True. This tellsPersonSchemato expect an interable to serialize, which is what thepeoplevariable is. -
Line 25 uses the
PersonSchemainstance variable (person_schema), calling itsdump()method with thepeopledaftar. The result is an object having adataattribute, an object containing apeoplelist that can be converted to JSON. This is returned and converted by Connexion to JSON as the response to the REST API call.
Catatan: The people list variable created on Line 24 above can’t be returned directly because Connexion won’t know how to convert the timestamp field into JSON. Returning the list of people without processing it with Marshmallow results in a long error traceback and finally this Exception:
TypeError: Object of type Person is not JSON serializable
Here’s another part of the person.py module that makes a request for a single person from the person basis data. Here, read_one(person_id) function receives a person_id from the REST URL path, indicating the user is looking for a specific person. Here’s part of the updated person.py module showing the handler for the REST URL endpoint GET /api/people/{person_id} :
1def read_one(person_id):
2 """
3 This function responds to a request for /api/people/{person_id}
4 with one matching person from people
5
6 :param person_id: ID of person to find
7 :return: person matching ID
8 """
9 # Get the person requested
10 person = Person.query \
11 .filter(Person.person_id == person_id) \
12 .one_or_none()
13
14 # Did we find a person?
15 if person is not None:
16
17 # Serialize the data for the response
18 person_schema = PersonSchema()
19 return person_schema.dump(person).data
20
21 # Otherwise, nope, didn't find that person
22 else:
23 abort(404, 'Person not found for Id: {person_id}'.format(person_id=person_id))
Here’s what the above code is doing:
-
Lines 10 – 12 use the
person_idparameter in a SQLAlchemy query using thefiltermethod of the query object to search for a person with aperson_idattribute matching the passed-inperson_id. Rather than using theall()query method, use theone_or_none()method to get one person, or returnNoneif no match is found. -
Line 15 determines whether a
personwas found or not. -
Line 17 shows that, if
personwas notNone(a matchingpersonwas found), then serializing the data is a little different. You don’t pass themany=Trueparameter to the creation of thePersonSchema()contoh. Instead, you passmany=Falsebecause only a single object is passed in to serialize. -
Line 18 is where the
dumpmethod ofperson_schemais called, and thedataattribute of the resulting object is returned. -
Line 23 shows that, if
personwasNone(a matching person wasn’t found), then the Flaskabort()method is called to return an error.
Another modification to person.py is creating a new person in the database. This gives you an opportunity to use the Marshmallow PersonSchema to deserialize a JSON structure sent with the HTTP request to create a SQLAlchemy Person obyek. Here’s part of the updated person.py module showing the handler for the REST URL endpoint POST /api/people :
1def create(person):
2 """
3 This function creates a new person in the people structure
4 based on the passed-in person data
5
6 :param person: person to create in people structure
7 :return: 201 on success, 406 on person exists
8 """
9 fname = person.get('fname')
10 lname = person.get('lname')
11
12 existing_person = Person.query \
13 .filter(Person.fname == fname) \
14 .filter(Person.lname == lname) \
15 .one_or_none()
16
17 # Can we insert this person?
18 if existing_person is None:
19
20 # Create a person instance using the schema and the passed-in person
21 schema = PersonSchema()
22 new_person = schema.load(person, session=db.session).data
23
24 # Add the person to the database
25 db.session.add(new_person)
26 db.session.commit()
27
28 # Serialize and return the newly created person in the response
29 return schema.dump(new_person).data, 201
30
31 # Otherwise, nope, person exists already
32 else:
33 abort(409, f'Person {fname} {lname} exists already')
Here’s what the above code is doing:
-
Line 9 &10 set the
fnameandlnamevariables based on thePersondata structure sent as thePOSTbody of the HTTP request. -
Lines 12 – 15 use the SQLAlchemy
Personclass to query the database for the existence of a person with the samefnameandlnameas the passed-inperson. -
Line 18 addresses whether
existing_personisNone. (existing_personwas not found.) -
Line 21 creates a
PersonSchema()instance calledschema. -
Line 22 uses the
schemavariable to load the data contained in thepersonparameter variable and create a new SQLAlchemyPersoninstance variable callednew_person. -
Line 25 adds the
new_personinstance to thedb.session. -
Line 26 commits the
new_personinstance to the database, which also assigns it a new primary key value (based on the auto-incrementing integer) and a UTC-based timestamp. -
Line 33 shows that, if
existing_personis notNone(a matching person was found), then the Flaskabort()method is called to return an error.
Update the Swagger UI
With the above changes in place, your REST API is now functional. The changes you’ve made are also reflected in an updated swagger UI interface and can be interacted with in the same manner. Below is a screenshot of the updated swagger UI opened to the GET /people/{person_id} section. This section of the UI gets a single person from the database and looks like this:
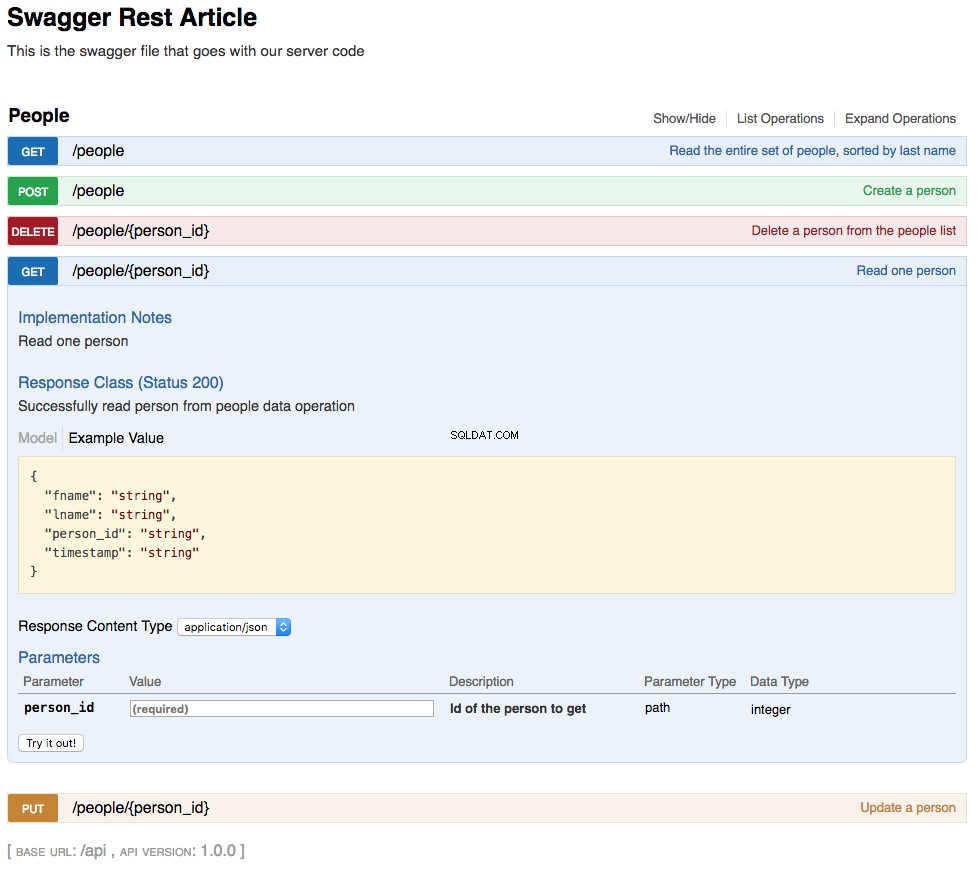
As shown in the above screenshot, the path parameter lname has been replaced by person_id , which is the primary key for a person in the REST API. The changes to the UI are a combined result of changing the swagger.yml file and the code changes made to support that.
Update the Web Application
The REST API is running, and CRUD operations are being persisted to the database. So that it is possible to view the demonstration web application, the JavaScript code has to be updated.
The updates are again related to using person_id instead of lname as the primary key for person data. In addition, the person_id is attached to the rows of the display table as HTML data attributes named data-person-id , so the value can be retrieved and used by the JavaScript code.
This article focused on the database and making your REST API use it, which is why there’s just a link to the updated JavaScript source and not much discussion of what it does.
Example Code
All of the example code for this article is available here. There’s one version of the code containing all the files, including the build_database.py utility program and the server.py modified example program from Part 1.
Kesimpulan
Congratulations, you’ve covered a lot of new material in this article and added useful tools to your arsenal!
You’ve learned how to save Python objects to a database using SQLAlchemy. You’ve also learned how to use Marshmallow to serialize and deserialize SQLAlchemy objects and use them with a JSON REST API. The things you’ve learned have certainly been a step up in complexity from the simple REST API of Part 1, but that step has given you two very powerful tools to use when creating more complex applications.
SQLAlchemy and Marshmallow are amazing tools in their own right. Using them together gives you a great leg up to create your own web applications backed by a database.
In Part 3 of this series, you’ll focus on the R part of RDBMS :relationships, which provide even more power when you are using a database.