IRI sekarang juga memberikan fungsi pencarian fuzzy, baik dalam database gratis dan alat profil file datar, dan sebagai perpustakaan fungsi bidang yang tersedia di IRI CoSort, FieldShield, dan Voracity untuk meningkatkan kualitas data, keamanan, dan kemampuan MDM. Ini adalah yang pertama dari serangkaian artikel tentang solusi penelusuran fuzzy IRI yang membahas aplikasinya pada peningkatan kualitas data.
Pengantar
Kebenaran atau keandalan data dari salah satu kata 'V' besar (bersama dengan volume, variasi, kecepatan, dan nilai) yang dibicarakan IRI dkk dalam konteks data dan manajemen informasi perusahaan. Secara umum, IRI mendefinisikan data yang diragukan memiliki satu atau lebih atribut berikut:
- Kualitas rendah, karena tidak konsisten, tidak akurat, atau tidak lengkap
- Ambigu (pikirkan MDM), tidak tepat (tidak terstruktur), atau menipu (media sosial)
- Bias (pertanyaan survei), berisik (berlebihan atau terkontaminasi), atau abnormal (pencilan)
- Tidak valid karena alasan lain (apakah data benar dan akurat untuk tujuan penggunaannya?)
- Tidak aman – apakah berisi PII atau rahasia, dan apakah itu tertutup dengan benar, dapat dibalik, dll.?
Artikel ini hanya berfokus pada solusi pencarian fuzzy baru untuk masalah pertama, kualitas data. Artikel lain di blog ini membahas bagaimana perangkat lunak IRI mengatasi empat masalah kejujuran lainnya; minta bantuan untuk menemukannya jika Anda tidak bisa.
Tentang Pencarian Fuzzy
Penelusuran kabur menemukan kata atau frasa (nilai) yang mirip, tetapi tidak harus identik, dengan kata atau frasa (nilai) lainnya. Jenis pencarian ini memiliki banyak kegunaan, seperti menemukan kesalahan urutan, kesalahan ejaan, karakter yang dialihkan, dan lainnya yang akan kita bahas nanti.
Melakukan penelusuran kabur untuk perkiraan kata atau frasa dapat membantu menemukan data yang mungkin merupakan duplikat dari data yang disimpan sebelumnya. Namun, masukan pengguna atau koreksi otomatis mungkin telah mengubah data dalam beberapa cara untuk membuat rekaman tampak independen.
Artikel selanjutnya akan membahas empat fungsi penelusuran kabur yang kini didukung IRI, cara menggunakannya untuk menjelajahi data Anda, dan mengembalikan catatan tersebut yang mendekati nilai penelusuran.
1. Levenshtein
Algoritme Levenshtein bekerja dengan mengambil dua kata atau frasa, dan menghitung berapa banyak langkah pengeditan yang diperlukan untuk mengubah satu kata atau frasa menjadi kata atau frasa lainnya. Semakin sedikit langkah yang diambil, semakin besar kemungkinan kata atau frasa tersebut cocok. Langkah-langkah yang dapat dilakukan oleh fungsi Levenshtein adalah:
- Penyisipan karakter ke dalam kata atau frasa
- Penghapusan karakter dari kata atau frasa
- Penggantian satu karakter dalam kata atau frasa dengan karakter lainnya
Berikut adalah program CoSort SortCL (skrip pekerjaan) yang menunjukkan cara menggunakan fungsi penelusuran fuzzy Levenshtein:
/INFILE=LevenshteinSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=LevenshteinOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(FS_RESULT=fs_levenshtein(NAME, "Barney Oakley"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE FS_RESULT GT 50
Ada dua bagian yang harus digunakan untuk menghasilkan output yang diinginkan.
FS_Result=fs_levenshtein(NAME, "Barney Oakley")
Baris ini memanggil fungsi fs_levenshtein, dan menyimpan hasilnya di bidang FS_RESULT. Fungsi ini mengambil dua parameter masukan:
- Bidang untuk menjalankan pencarian fuzzy (NAMA dalam contoh kita)
- String yang akan dibandingkan dengan bidang input (“Barney Oakley” dalam contoh kita).
/INCLUDE WHERE FS_RESULT GT 50
Baris ini membandingkan bidang FS_RESULT dan memeriksa apakah lebih besar dari 50, maka hanya catatan dengan FS_RESULT lebih dari 50 yang dihasilkan. Berikut ini menunjukkan output dari contoh kita.

Seperti yang ditunjukkan oleh output, jenis pencarian ini berguna untuk menemukan:
- Nama gabungan
- Kebisingan
- Kesalahan ejaan
- Karakter yang dialihkan
- Kesalahan transkripsi
- Kesalahan pengetikan
Dengan demikian, fungsi Levenshtein juga berguna untuk mengidentifikasi kesalahan entri data umum. Namun, dibutuhkan waktu paling lama untuk menjalankan dari empat algoritma, karena membandingkan setiap karakter dalam satu string dengan setiap karakter di string lainnya.
2. Koefisien Dadu
Koefisien dadu, atau algoritme dadu, memecah kata atau frasa menjadi pasangan karakter, membandingkan pasangan tersebut, dan menghitung kecocokan. Semakin banyak kata yang cocok, semakin besar kemungkinan kata itu cocok.
Skrip SortCL berikut menunjukkan fungsi pencarian fuzzy koefisien dadu.
/INFILE=DiceSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=DiceOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(FS_RESULT=fs_dice(NAME, "Robert Thomas Smith"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE FS_RESULT GT 50
Ada dua bagian yang harus digunakan untuk memberikan hasil yang diinginkan.
FS_Result=fs_dice(NAME, "Robert Thomas Smith")
Baris ini memanggil fungsi fs_dice, dan menyimpan hasilnya di bidang FS_RESULT. Fungsi ini mengambil dua parameter masukan:
- Bidang untuk menjalankan pencarian fuzzy (NAME dalam contoh kita).
- String yang akan dibandingkan dengan bidang input (“Robert Thomas Smith” dalam contoh kita).
/INCLUDE WHERE FS_RESULT GT 50
Baris ini membandingkan bidang FS_RESULT dan memeriksa apakah lebih besar dari 50, maka hanya catatan dengan FS_RESULT lebih dari 50 yang dihasilkan. Berikut ini menunjukkan output dari contoh kita.
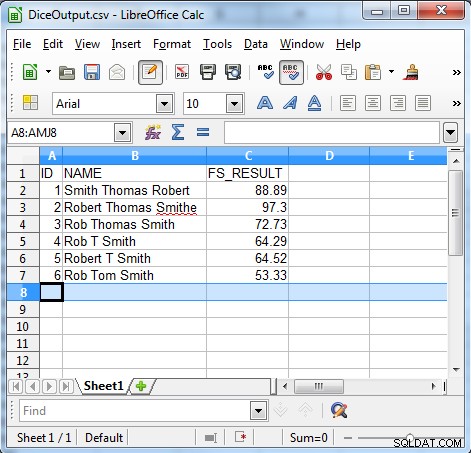
Seperti yang ditunjukkan output, algoritme koefisien dadu berguna untuk menemukan data yang tidak konsisten seperti:
- Kesalahan urutan
- Koreksi yang tidak disengaja
- Nama panggilan
- Inisial dan nama panggilan
- Penggunaan inisial yang tidak terduga
- Lokalisasi
Algoritme dadu lebih cepat daripada Levenshtein, tetapi bisa menjadi kurang akurat jika ada banyak kesalahan sederhana seperti salah ketik.
3. Metafon dan 4. Soundex
algoritme Metaphone dan Soundex membandingkan kata atau frasa berdasarkan bunyi fonetiknya. Soundex melakukannya dengan membaca kata atau frasa dan melihat karakter individu, sementara Metaphone melihat karakter individu dan kelompok karakter. Kemudian keduanya memberi kode berdasarkan ejaan dan pengucapan kata tersebut.
Skrip SortCL berikut menunjukkan fungsi pencarian Soundex dan Metasphone:
/INFILE=SoundexSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=SoundexOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(SE_RESULT=fs_soundex(NAME, "John"), POSITION=3, SEPARATOR=",") /FIELD=(MP_RESULT=fs_metaphone(NAME, "John"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE (SE_RESULT GT 0) OR (MP_RESULT GT 0)
Dalam setiap kasus, ada tiga bagian yang harus digunakan untuk memberikan hasil yang diinginkan.
SE_RESULT=fs_soundex(NAME, "John") MP_RESULT=fs_metaphone(NAME, "John")
Baris memanggil fungsi, dan menyimpan hasilnya di bidang RESULT. Kedua fungsi tersebut mengambil dua parameter masukan:
- Bidang untuk menjalankan pencarian fuzzy (NAMA dalam contoh kita)
- String x yang akan dibandingkan dengan bidang masukan (“John” dalam contoh kita)
/INCLUDE WHERE (SE_RESULT GT 0) OR (MP_RESULT GT 0)
Baris ini membandingkan bidang SE_RESULT dan MP_RESULT, serta memeriksa dan menampilkan baris jika salah satu lebih besar dari 0.
Soundex mengembalikan 100 untuk kecocokan, atau 0 jika tidak cocok. Metaphone memiliki hasil yang lebih spesifik, dan mengembalikan 100 untuk pertandingan kuat, 66 untuk pertandingan normal, dan 33 untuk pertandingan kecil.
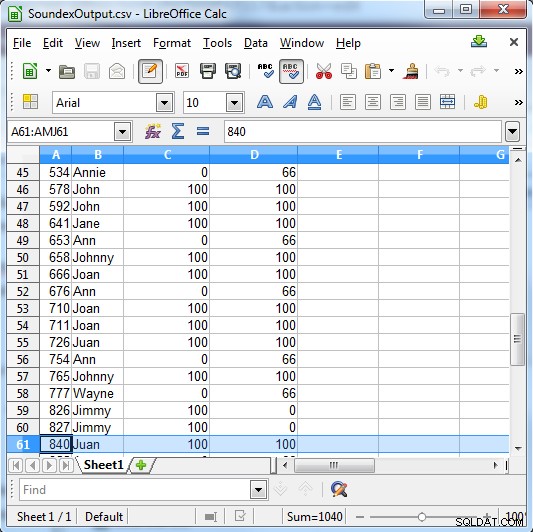
Kolom C menunjukkan hasil Soundex. Ckolom D menunjukkan hasil Metafon
Seperti yang ditunjukkan oleh output, jenis pencarian ini berguna untuk menemukan:
- Kesalahan fonetik
Kirimkan masukan tentang artikel di bawah ini, dan jika Anda tertarik untuk menggunakan fungsi ini, harap hubungi perwakilan IRI Anda. Lihat artikel kami berikutnya tentang penggunaan algoritme ini di wizard konsolidasi (kualitas) data Workbench IRI.