Pengantar
Sudah menjadi rahasia umum di lingkaran basis data bahwa indeks meningkatkan kinerja kueri baik dengan memenuhi kumpulan hasil yang diperlukan seluruhnya (Meliputi Indeks) atau bertindak sebagai pencarian yang dengan mudah mengarahkan Mesin Kueri ke lokasi yang tepat dari kumpulan data yang diperlukan. Namun, seperti yang diketahui oleh DBA berpengalaman, seseorang tidak boleh terlalu antusias membuat indeks di lingkungan OLTP tanpa memahami sifat beban kerja. Menggunakan Query Store di SQL Server 2019 instance (Query Store diperkenalkan di SQL Server 2016), cukup mudah untuk menunjukkan efek indeks pada sisipan.
Sisipkan Tanpa Indeks
Kita mulai dengan memulihkan database Contoh WideWorldImporters dan kemudian membuat salinan file Sales. Tabel faktur menggunakan skrip dalam Daftar 1. Perhatikan bahwa database sampel telah mengaktifkan Penyimpanan Kueri dalam mode baca-tulis.
-- Listing 1 Make a Copy Of Invoices SELECT * INTO [SALES].[INVOICES1] FROM [SALES].[INVOICES] WHERE 1=2;
Perhatikan bahwa tidak ada indeks sama sekali dalam tabel yang baru saja kita buat. Yang kita miliki hanyalah struktur tabel. Setelah selesai, kami melakukan penyisipan di tabel baru menggunakan data dari induknya seperti yang ditunjukkan pada Listing 2.
-- Listing 2 Populate Invoices1 -- TRUNCATE TABLE [SALES].[INVOICES1] INSERT INTO [SALES].[INVOICES1] SELECT * FROM [SALES].[INVOICES]; GO 100
Selama operasi ini, penyimpanan kueri menangkap rencana eksekusi kueri. Gambar 1 menunjukkan secara singkat apa yang terjadi di bawah tenda. Membaca dari kiri ke kanan, kita melihat bahwa SQL Server mengeksekusi penyisipan menggunakan Plan ID 563 – Pemindaian Indeks pada Kunci Utama tabel sumber untuk mengambil data dan kemudian Sisipan Tabel pada tabel tujuan. (Membaca dari kiri ke kanan). Perhatikan bahwa dalam kasus ini, sebagian besar biaya ada di Sisipan Tabel – 99% dari biaya kueri.
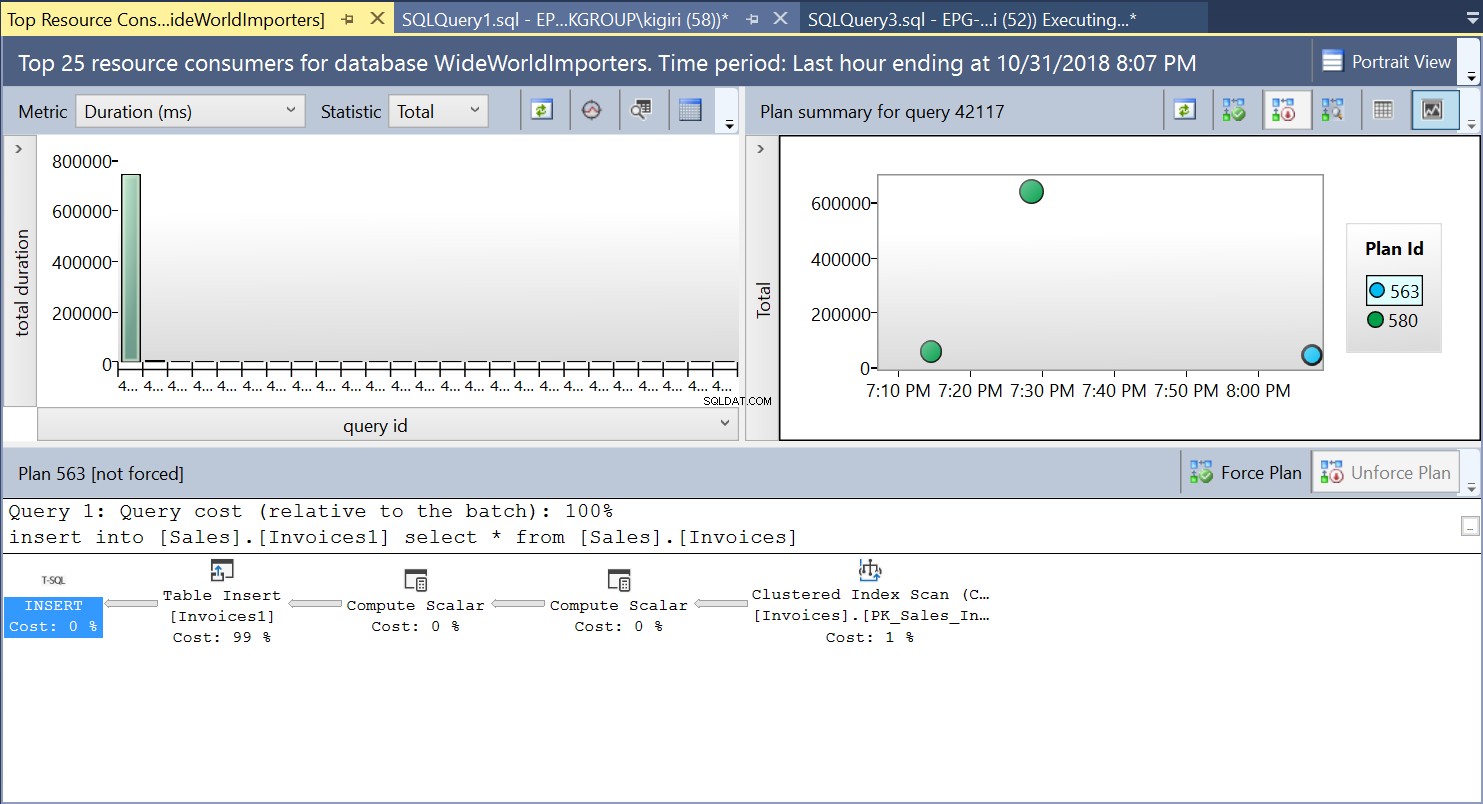
Gambar 1 Rencana Eksekusi 563
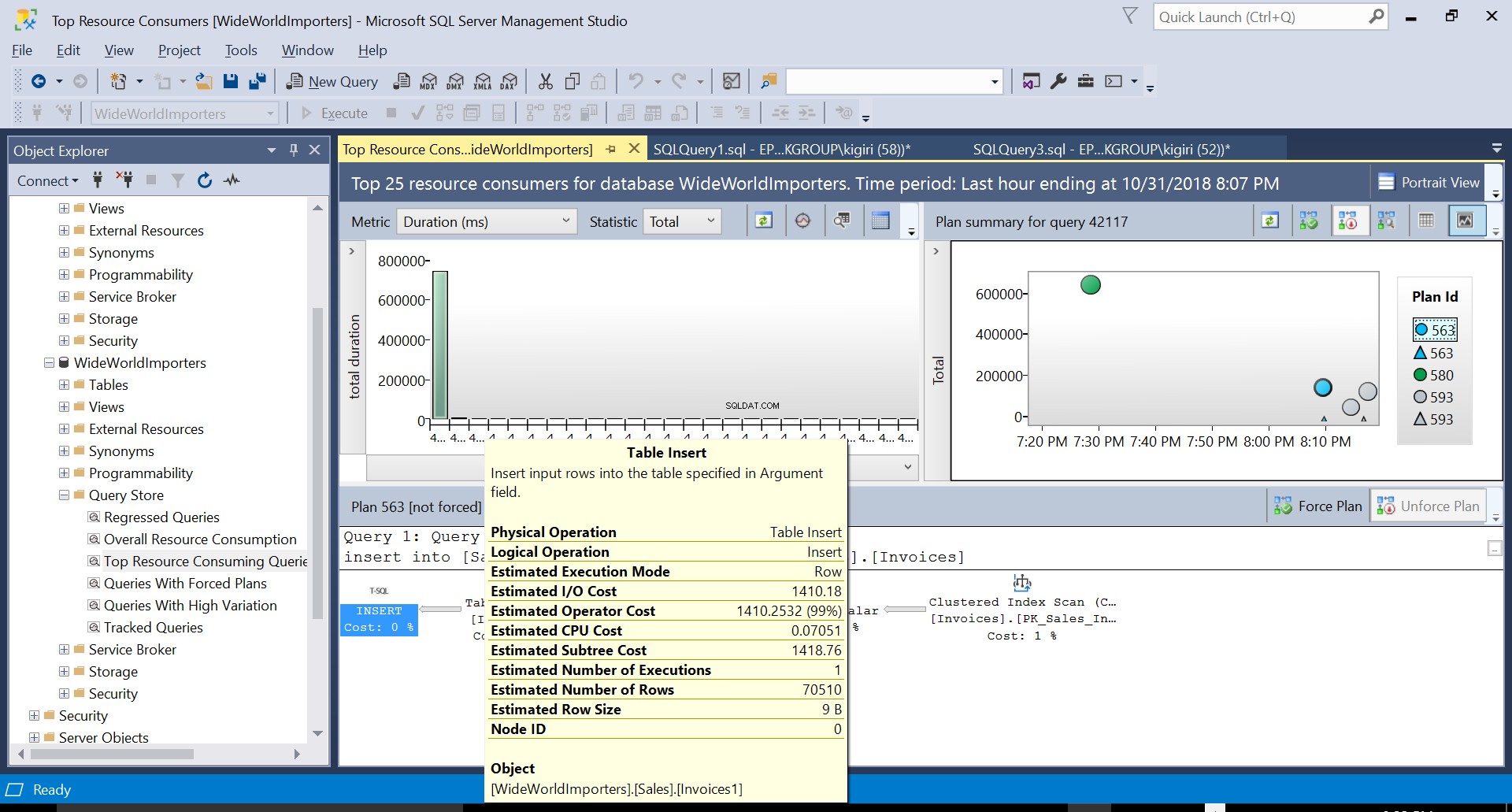
Gambar 2 Sisipan Tabel di Tujuan
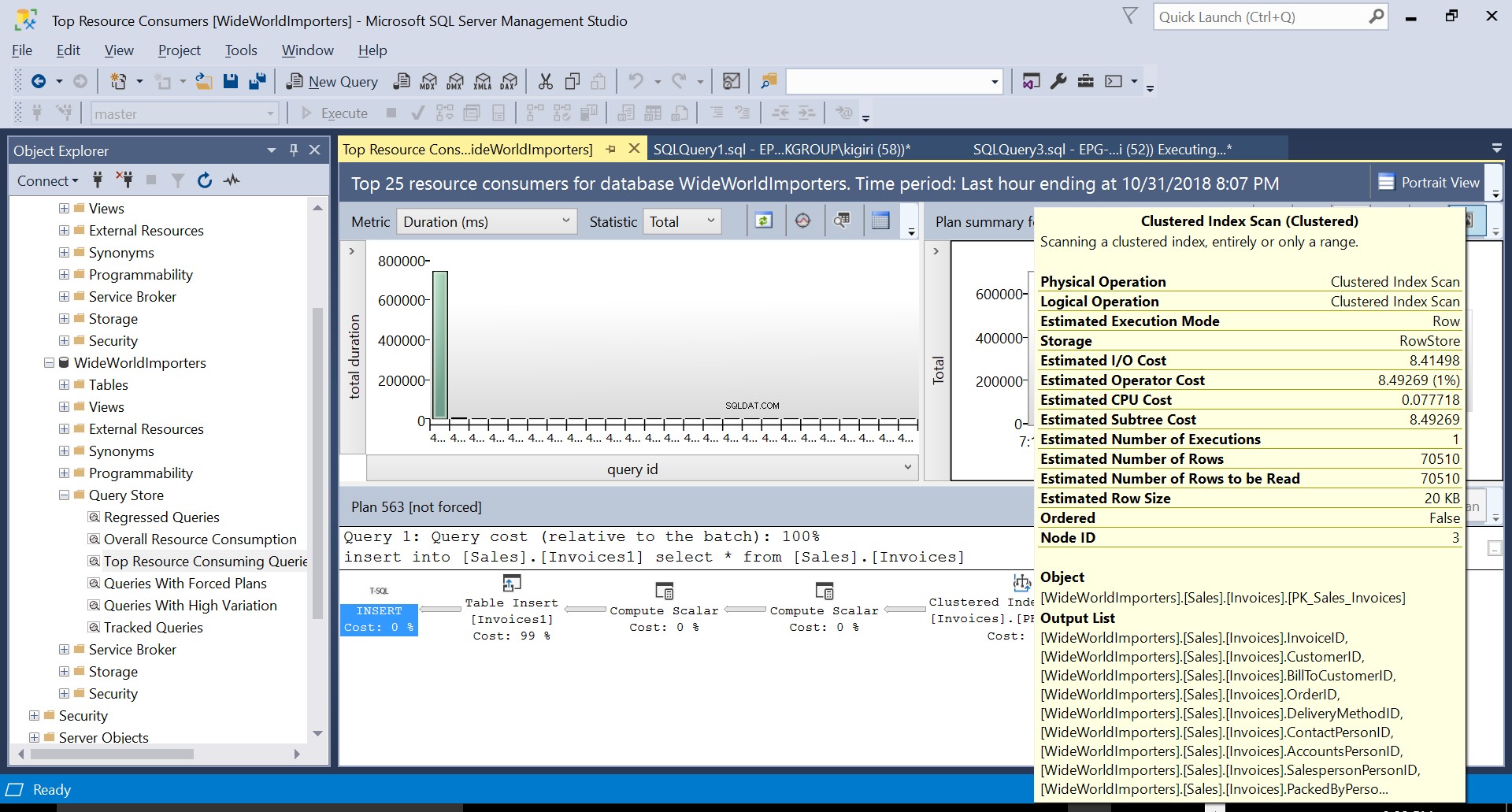
Gbr. 3 Pemindaian Indeks Berkelompok pada Tabel Sumber
Sisipkan Dengan Indeks
Kami kemudian membuat indeks pada tabel tujuan menggunakan DDL di Listing 3. Ketika kami mengulangi pernyataan di Listing 2 setelah memotong tabel tujuan, kami melihat rencana eksekusi yang sedikit berbeda (Plan ID 593 ditunjukkan pada Gambar 4). Kami masih melihat Sisipan Tabel tetapi hanya berkontribusi 58% untuk biaya kueri. Dinamika eksekusi sedikit miring dengan pengenalan semacam dan Sisipan Indeks. Pada dasarnya apa yang terjadi adalah bahwa SQL Server harus memperkenalkan baris yang sesuai pada indeks saat catatan baru diperkenalkan di tabel.
-- LISTING 3 Create Index on Destination Table CREATE NONCLUSTERED INDEX [IX_Sales_Invoices_ConfirmedDeliveryTime] ON [Sales].[Invoices1] ( [ConfirmedDeliveryTime] ASC ) INCLUDE ( [ConfirmedReceivedBy]) WITH (PAD_INDEX = OFF , STATISTICS_NORECOMPUTE = OFF , SORT_IN_TEMPDB = OFF , DROP_EXISTING = OFF , ONLINE = OFF , ALLOW_ROW_LOCKS = ON , ALLOW_PAGE_LOCKS = ON) ON [USERDATA] GO
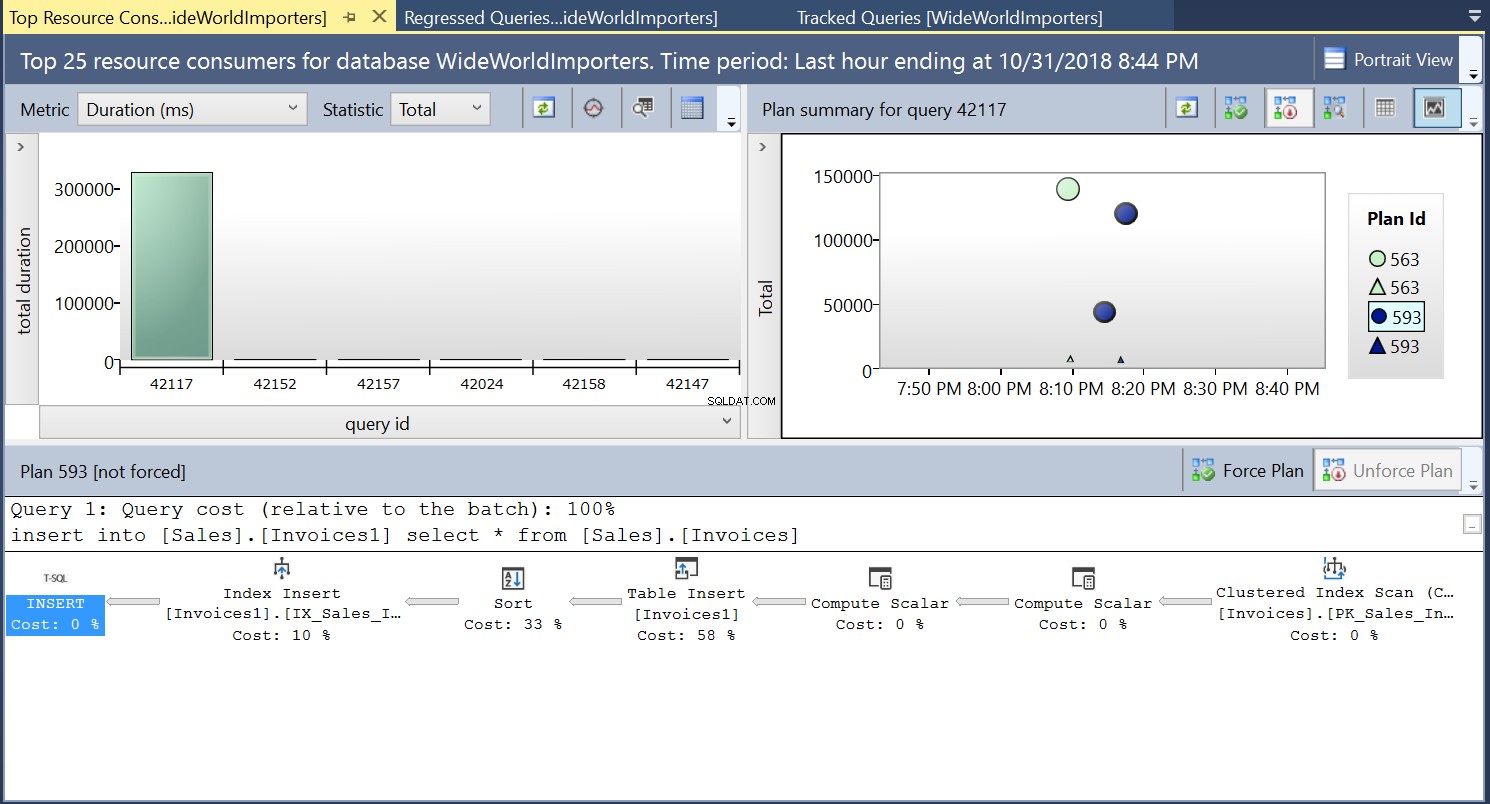
Gambar. 4 Rencana Eksekusi 593
Melihat Lebih Dalam
Kami dapat memeriksa detail kedua rencana dan melihat bagaimana faktor-faktor baru ini meningkatkan waktu pelaksanaan pernyataan. Paket 593 menambahkan 300 ms tambahan atau lebih ke Durasi Rata-rata pernyataan. Di bawah beban kerja yang berat di lingkungan produksi, perbedaan ini bisa menjadi signifikan.
Mengaktifkan STATISTICS IO saat mengeksekusi pernyataan penyisipan hanya sekali dalam kedua kasus – dengan Indeks pada tabel tujuan dan tanpa indeks pada tabel Tujuan – juga menunjukkan bahwa lebih banyak pekerjaan yang dilakukan dalam hal IO logis saat menyisipkan baris dalam tabel dengan indeks.
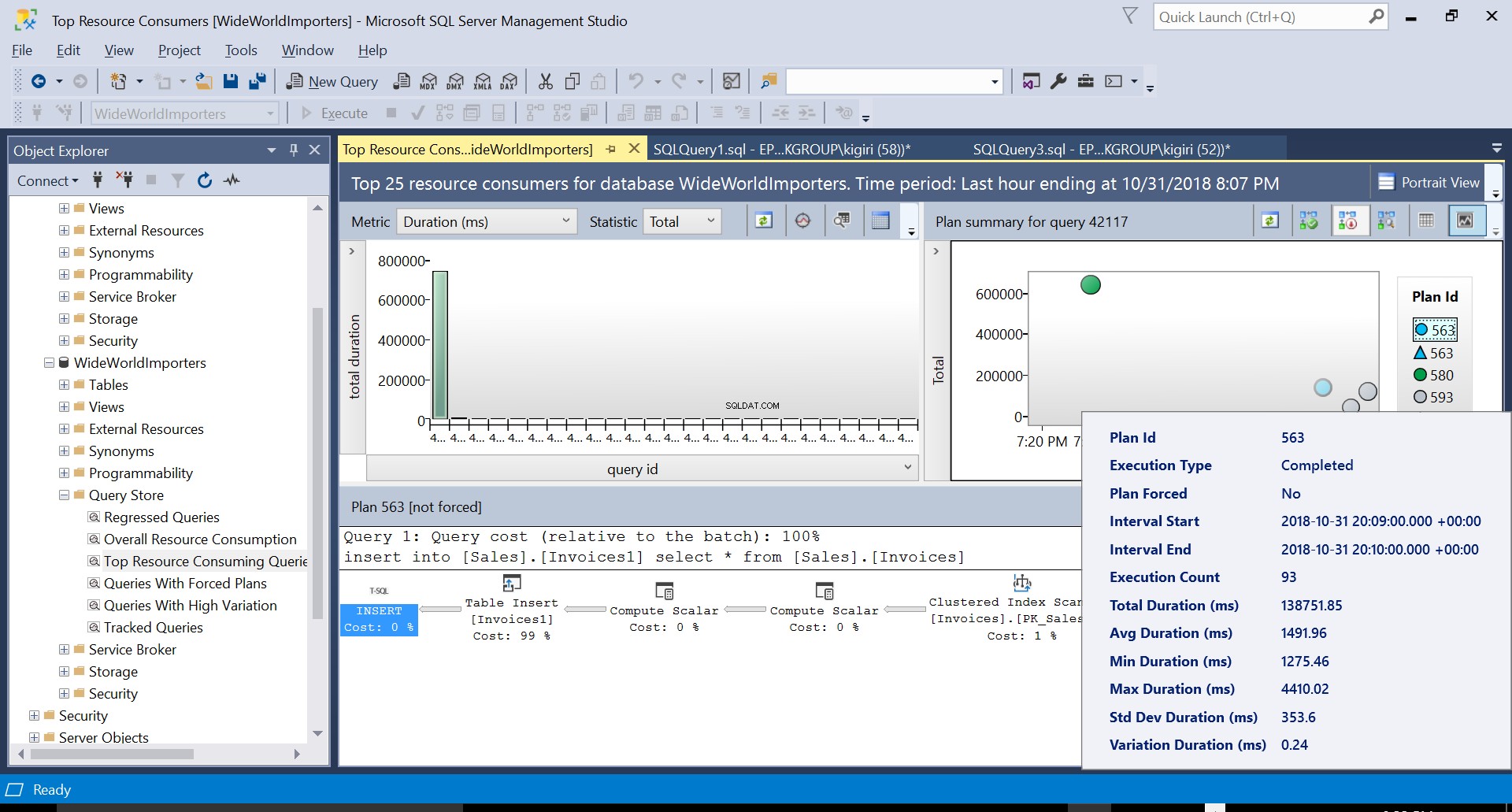
Gambar 5 Rincian Rencana Eksekusi 563
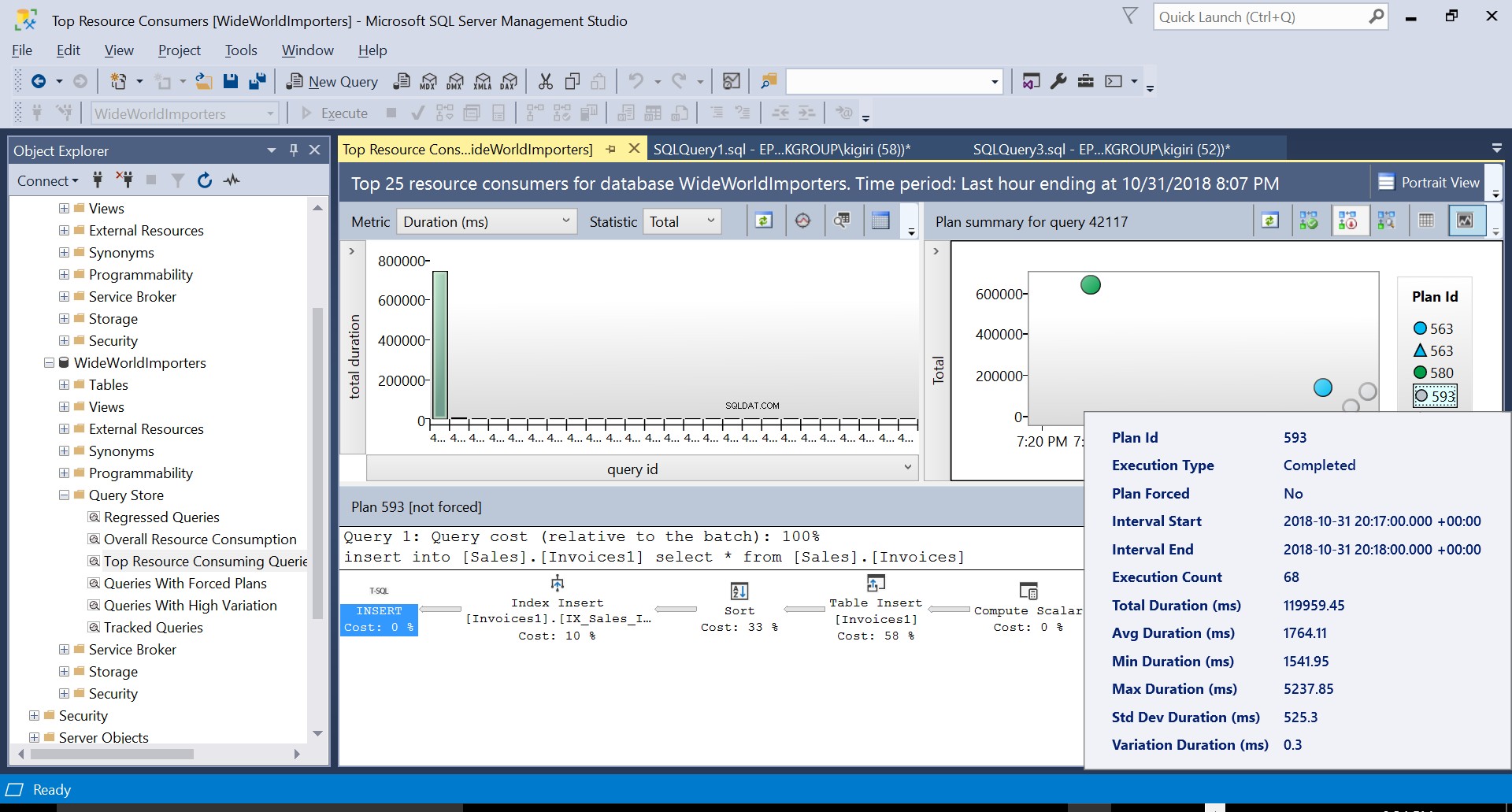
Gbr. 4 Rincian Rencana Eksekusi 593
Tidak Ada Indeks:Keluaran dengan STATISTICS IO Dinyalakan:
Tabel 'Faktur1'. Hitungan pindai 0, pembacaan logis 78372 , pembacaan fisik 0, pembacaan depan membaca 0, pembacaan logika lob 0, pembacaan fisik lob 0, pembacaan depan pembacaan lob 0.
Tabel 'Faktur'. Hitungan pindai 1, pembacaan logis 11400, pembacaan fisik 0, pembacaan depan pembacaan 0, pembacaan logika lob 0, pembacaan fisik lob 0, pembacaan depan pembacaan lob 0.
(70510 baris terpengaruh)
Indeks:Keluaran dengan STATISTICS IO Diaktifkan:
Tabel 'Faktur1'. Hitungan pindai 0, pembacaan logis 81119 , pembacaan fisik 0, pembacaan depan membaca 0, pembacaan logika lob 0, pembacaan fisik lob 0, pembacaan depan pembacaan lob 0.
Tabel 'Meja Kerja'. Hitungan pemindaian 0, pembacaan logis 0, pembacaan fisik 0, pembacaan ke depan 0, pembacaan logika lob 0, pembacaan fisik lob 0, pembacaan pembacaan ke depan lob 0.
Tabel 'Faktur'. Hitungan pindai 1, pembacaan logis 11400 , pembacaan fisik 0, pembacaan depan membaca 0, pembacaan logika lob 0, pembacaan fisik lob 0, pembacaan depan pembacaan lob 0.
(70510 baris terpengaruh)
Informasi Tambahan
Microsoft dan sumber lain menyediakan skrip untuk memeriksa lingkungan produksi indeks dan mengidentifikasi situasi seperti:
- Indeks Redundan – Indeks yang digandakan
- Indeks Tidak Ada – Indeks yang dapat meningkatkan kinerja berdasarkan beban kerja
- Tumpukan – Tabel tanpa Indeks Clustered
- Tabel yang diindeks berlebihan – Tabel dengan indeks lebih dari kolom
- Penggunaan Indeks – Hitungan pencarian, pemindaian, dan pencarian pada indeks
Butir 2, 3, dan 5 lebih terkait dengan dampak kinerja sehubungan dengan membaca, sedangkan butir 1 dan 4 terkait dengan dampak kinerja sehubungan dengan menulis. Daftar 4 dan 5 adalah dua contoh kueri yang tersedia untuk umum ini.
-- LISTING 4 Check Redundant Indexes
;WITH INDEXCOLUMNS AS(
SELECT DISTINCT
SCHEMA_NAME (O.SCHEMA_ID) AS 'SCHEMANAME'
, OBJECT_NAME(O.OBJECT_ID) AS TABLENAME
,I.NAME AS INDEXNAME, O.OBJECT_ID,I.INDEX_ID,I.TYPE
,(SELECT CASE KEY_ORDINAL WHEN 0 THEN NULL ELSE '['+COL_NAME(K.OBJECT_ID,COLUMN_ID) +']' END AS [DATA()]
FROM SYS.INDEX_COLUMNS AS K WHERE K.OBJECT_ID = I.OBJECT_ID AND K.INDEX_ID = I.INDEX_ID
ORDER BY KEY_ORDINAL, COLUMN_ID FOR XML PATH('')) AS COLS
FROM SYS.INDEXES AS I INNER JOIN SYS.OBJECTS O ON I.OBJECT_ID =O.OBJECT_ID
INNER JOIN SYS.INDEX_COLUMNS IC ON IC.OBJECT_ID =I.OBJECT_ID AND IC.INDEX_ID =I.INDEX_ID
INNER JOIN SYS.COLUMNS C ON C.OBJECT_ID = IC.OBJECT_ID AND C.COLUMN_ID = IC.COLUMN_ID
WHERE I.OBJECT_ID IN (SELECT OBJECT_ID FROM SYS.OBJECTS WHERE TYPE ='U') AND I.INDEX_ID <>0 AND I.TYPE <>3 AND I.TYPE <>6
GROUP BY O.SCHEMA_ID,O.OBJECT_ID,I.OBJECT_ID,I.NAME,I.INDEX_ID,I.TYPE
)
SELECT
IC1.SCHEMANAME,IC1.TABLENAME,IC1.INDEXNAME,IC1.COLS AS INDEXCOLS,IC2.INDEXNAME AS REDUNDANTINDEXNAME, IC2.COLS AS REDUNDANTINDEXCOLS
FROM INDEXCOLUMNS IC1
JOIN INDEXCOLUMNS IC2 ON IC1.OBJECT_ID = IC2.OBJECT_ID
AND IC1.INDEX_ID <> IC2.INDEX_ID
AND IC1.COLS <> IC2.COLS
AND IC2.COLS LIKE REPLACE(IC1.COLS,'[','[[]') + ' %'
ORDER BY 1,2,3,5;
-- LISTING 5 Check Indexes Usage
SELECT O.NAME AS TABLE_NAME
, I.NAME AS INDEX_NAME
, S.USER_SEEKS
, S.USER_SCANS
, S.USER_LOOKUPS
, S.USER_UPDATES
FROM SYS.DM_DB_INDEX_USAGE_STATS S
INNER JOIN SYS.INDEXES I
ON I.INDEX_ID=S.INDEX_ID
AND S.OBJECT_ID = I.OBJECT_ID
INNER JOIN SYS.OBJECTS O
ON S.OBJECT_ID = O.OBJECT_ID
INNER JOIN SYS.SCHEMAS C
ON O.SCHEMA_ID = C.SCHEMA_ID;
Kesimpulan
Kami telah menunjukkan, menggunakan Query Store, bahwa beban kerja tambahan dengan indeks dapat diperkenalkan dalam rencana eksekusi pernyataan penyisipan sampel. Dalam produksi, indeks yang berlebihan dan berlebihan dapat berdampak negatif pada kinerja, terutama dalam basis data yang dimaksudkan untuk beban kerja OLTP. Penting untuk menggunakan skrip dan alat yang tersedia untuk memeriksa indeks dan menentukan apakah mereka benar-benar membantu atau mengganggu kinerja.
Alat yang berguna:
dbForge Index Manager – add-in SSMS yang berguna untuk menganalisis status indeks SQL dan memperbaiki masalah dengan fragmentasi indeks.