Dalam posting blog sebelumnya, kita telah membahas dasar-dasar penskalaan - apa itu, apa jenisnya, apa yang harus dimiliki jika kita ingin menskala. Postingan blog ini akan berfokus pada tantangan dan cara yang dapat kami lakukan untuk meningkatkannya.
Menantang Scaling Out
Menskalakan basis data bukanlah tugas yang paling mudah karena berbagai alasan. Mari sedikit fokus pada tantangan yang terkait dengan penskalaan infrastruktur database Anda.
Layanan stateful
Kami dapat membedakan dua jenis layanan yang berbeda:stateless dan stateful. Layanan stateless adalah layanan yang tidak bergantung pada data apa pun yang ada. Anda bisa melanjutkan, memulai layanan seperti itu dan itu akan dengan senang hati bekerja. Anda tidak perlu khawatir tentang status data atau layanan. Jika sudah aktif, ini akan berfungsi dengan baik dan Anda dapat dengan mudah menyebarkan lalu lintas ke beberapa instance layanan hanya dengan menambahkan lebih banyak klon atau salinan VM yang ada, penampung, atau sejenisnya. Contoh dari layanan tersebut dapat berupa aplikasi web - disebarkan dari repo, memiliki server web yang dikonfigurasi dengan benar, layanan tersebut akan mulai dan bekerja dengan benar.
Masalah dengan database adalah bahwa database adalah segalanya kecuali stateless. Data harus dimasukkan ke dalam database, harus diproses dan dipertahankan. Gambar database tidak lebih dari hanya beberapa paket yang diinstal di atas gambar OS dan, tanpa data dan konfigurasi yang tepat, itu agak tidak berguna. Ini menambah kompleksitas penskalaan basis data. Untuk layanan stateless, itu hanya untuk menyebarkannya dan mengonfigurasi beberapa penyeimbang beban untuk menyertakan instans baru dalam beban kerja. Untuk database yang menyebarkan database, instance hanyalah titik awal. Lebih jauh lagi adalah manajemen data - Anda harus mentransfer data dari instans database yang ada ke yang baru. Ini bisa menjadi bagian penting dari masalah dan waktu yang diperlukan untuk instance baru untuk mulai menangani lalu lintas. Hanya setelah data ditransfer, kami dapat mengatur node baru untuk menjadi bagian dari topologi replikasi yang ada - data harus diperbarui secara real time, berdasarkan lalu lintas yang menjangkau node lain.
Waktu yang dibutuhkan untuk meningkatkan
Fakta bahwa database adalah layanan stateful adalah alasan langsung untuk tantangan kedua yang kita hadapi ketika kita ingin memperluas infrastruktur database. Layanan tanpa kewarganegaraan - Anda baru saja memulainya dan hanya itu. Ini adalah proses yang cukup cepat. Untuk database, Anda harus mentransfer data. Berapa lama waktu yang dibutuhkan, itu tergantung pada banyak faktor. Berapa besar kumpulan datanya? Seberapa cepat penyimpanannya? Seberapa cepat jaringannya? Apa langkah lain yang diperlukan untuk menyediakan node baru dengan data baru? Apakah data dikompresi/didekompresi atau dienkripsi/didekripsi dalam proses? Di dunia nyata, mungkin diperlukan beberapa menit hingga beberapa jam untuk menyediakan data pada node baru. Ini sangat membatasi kasus di mana Anda dapat meningkatkan lingkungan database Anda. Tiba-tiba, lonjakan beban sementara? Tidak juga, mereka mungkin sudah lama hilang sebelum Anda dapat memulai node database tambahan. Peningkatan beban yang tiba-tiba dan konsisten? Ya, mungkin untuk mengatasinya dengan menambahkan lebih banyak node tetapi mungkin perlu waktu berjam-jam untuk memunculkannya dan membiarkannya mengambil alih lalu lintas dari node database yang ada.
Beban tambahan yang disebabkan oleh proses peningkatan skala
Sangat penting untuk diingat bahwa waktu yang dibutuhkan untuk meningkatkan skala hanyalah satu sisi dari masalah. Sisi lain adalah beban yang disebabkan oleh proses penskalaan. Seperti yang kami sebutkan sebelumnya, Anda harus mentransfer seluruh kumpulan data ke node yang baru ditambahkan. Ini bukan sesuatu yang dapat Anda abaikan, lagipula, ini mungkin memakan waktu berjam-jam untuk membaca data dari disk, mengirimkannya melalui jaringan dan menyimpannya di lokasi baru. Jika donor, node tempat Anda membaca data, kelebihan beban, Anda perlu mempertimbangkan bagaimana perilakunya jika akan dipaksa untuk melakukan aktivitas I/O berat tambahan? Apakah klaster Anda dapat menerima beban kerja tambahan jika sudah berada di bawah tekanan berat dan tersebar tipis? Jawabannya mungkin tidak mudah didapat karena beban pada node mungkin datang dalam bentuk yang berbeda. Beban terikat CPU akan menjadi skenario kasus terbaik karena aktivitas I/O harus rendah dan operasi disk tambahan akan dapat dikelola. Beban terikat I/O, di sisi lain, dapat memperlambat transfer data secara signifikan, yang berdampak serius pada kemampuan klaster untuk menskalakan.
Tulis penskalaan
Proses penskalaan yang kami sebutkan sebelumnya cukup terbatas pada pembacaan penskalaan. Sangat penting untuk memahami bahwa penskalaan menulis adalah cerita yang sama sekali berbeda. Anda dapat menskalakan pembacaan hanya dengan menambahkan lebih banyak node dan menyebarkan pembacaan di lebih banyak node backend. Menulis tidak semudah itu untuk diukur. Sebagai permulaan, Anda tidak dapat memperkecil penulisan begitu saja. Setiap node yang berisi seluruh kumpulan data, jelas, diperlukan untuk menangani semua penulisan yang dilakukan di suatu tempat di cluster karena hanya dengan menerapkan semua modifikasi pada kumpulan data, konsistensi dapat dipertahankan. Jadi, ketika Anda memikirkannya, tidak peduli bagaimana Anda mendesain cluster Anda dan teknologi apa yang Anda gunakan, setiap anggota cluster harus mengeksekusi setiap penulisan. Baik itu replika, mereplikasi semua penulisan dari master atau node-nya dalam cluster multi-master seperti Galera atau Cluster InnoDB yang mengeksekusi semua perubahan pada kumpulan data yang dilakukan pada semua node lain dari cluster, hasilnya tetap sama. Penulisan tidak diperkecil hanya dengan menambahkan lebih banyak node ke cluster.
Bagaimana kita bisa Memperbesar Basis Data?
Jadi, kita tahu tantangan seperti apa yang kita hadapi. Apa saja pilihan yang kita miliki? Bagaimana kita bisa memperbesar basis data?
Dengan menambahkan replika
Pertama dan terpenting, kami akan memperbesar skala hanya dengan menambahkan lebih banyak node. Tentu, itu akan memakan waktu dan tentu saja, itu bukan proses yang dapat Anda harapkan terjadi segera. Tentu, Anda tidak akan dapat memperkecil penulisan seperti itu. Di sisi lain, masalah paling umum yang akan Anda hadapi adalah beban CPU yang disebabkan oleh kueri SELECT dan, seperti yang telah kita diskusikan, pembacaan dapat diskalakan dengan hanya menambahkan lebih banyak node ke cluster. Lebih banyak node untuk dibaca berarti beban pada masing-masing node akan berkurang. Ketika Anda berada di awal perjalanan Anda ke dalam siklus hidup aplikasi Anda, anggap saja ini yang akan Anda hadapi. Beban CPU, bukan kueri yang efisien. Sangat kecil kemungkinannya Anda perlu meningkatkan penulisan hingga lebih jauh dalam siklus hidup, ketika aplikasi Anda telah matang dan Anda harus berurusan dengan jumlah pelanggan.
Dengan membagi
Menambahkan node tidak akan menyelesaikan masalah penulisan, itulah yang kami buat. Yang harus Anda lakukan adalah sharding - membagi kumpulan data di seluruh cluster. Dalam hal ini setiap node hanya berisi sebagian data, bukan semuanya. Ini memungkinkan kami untuk akhirnya mulai menskalakan penulisan. Katakanlah kita memiliki empat node, masing-masing berisi setengah dari kumpulan data.
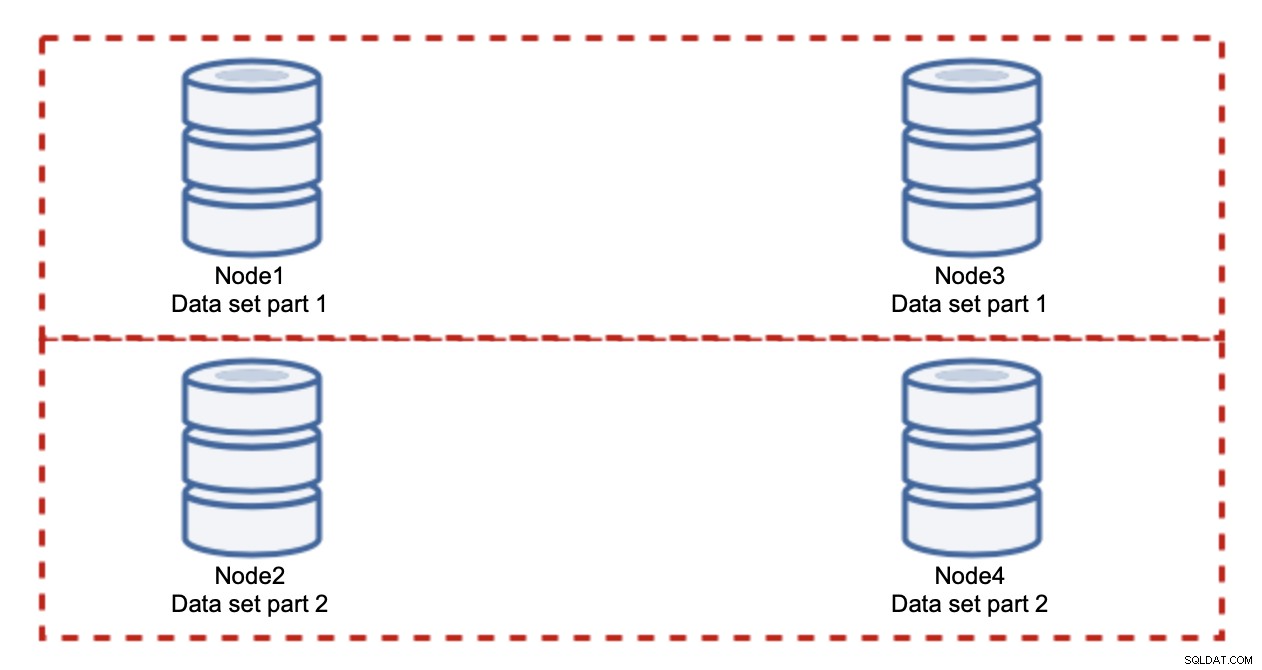
Seperti yang Anda lihat, idenya sederhana. Jika penulisan terkait dengan bagian 1 dari kumpulan data, itu akan dieksekusi pada node1 dan node3. Jika terkait dengan bagian 2 dari kumpulan data, itu akan dieksekusi pada node2 dan node4. Anda dapat menganggap node database sebagai disk dalam RAID. Di sini kita memiliki contoh RAID10, dua pasang cermin, untuk redundansi. Dalam implementasi nyata mungkin lebih kompleks, Anda mungkin memiliki lebih dari satu replika data untuk meningkatkan ketersediaan tinggi. Intinya adalah, dengan asumsi pemisahan data yang sangat adil, setengah dari penulisan akan mencapai node1 dan node3 dan setengah lainnya node 2 dan 4. Jika Anda ingin membagi beban lebih jauh, Anda dapat memperkenalkan pasangan node ketiga:
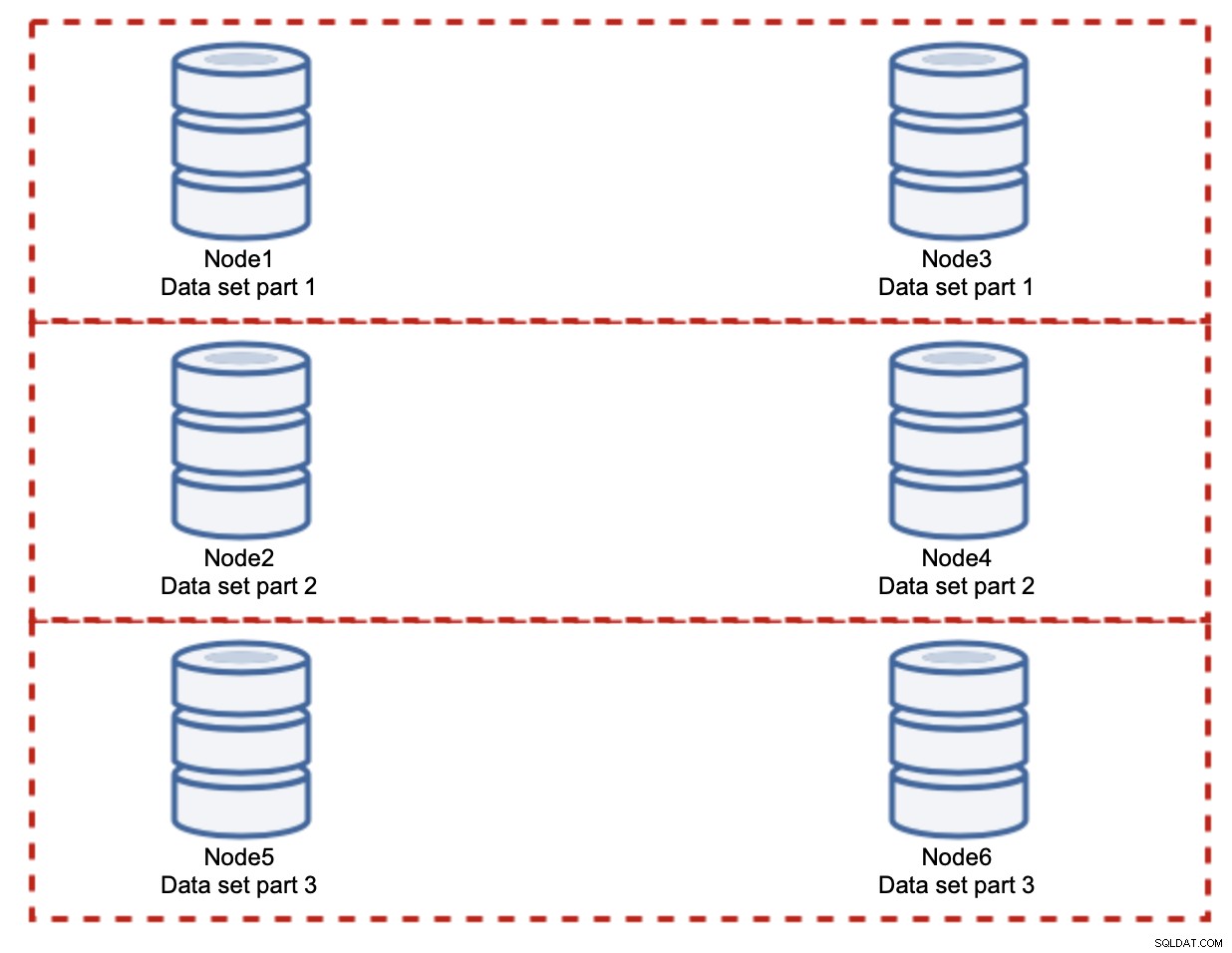
Dalam kasus ini, sekali lagi, dengan asumsi pembagian yang benar-benar adil, setiap pasangan akan bertanggung jawab atas 33% dari semua penulisan ke cluster.
Ini cukup meringkas ide sharding. Dalam contoh kita, dengan menambahkan lebih banyak shard, kita dapat mengurangi aktivitas tulis pada node database menjadi 33% dari beban I/O asli. Seperti yang Anda bayangkan, ini bukan tanpa kekurangan.
Bagaimana cara menemukan di shard mana data saya berada? Detail berada di luar cakupan panggilan ini tetapi singkatnya, Anda dapat mengimplementasikan semacam fungsi pada kolom tertentu (modulo atau hash pada kolom 'id') atau Anda dapat membangun basis data terpisah tempat Anda akan menyimpan detailnya tentang bagaimana data didistribusikan.
Kami harap Anda menganggap seri blog singkat ini informatif dan Anda mendapatkan pemahaman yang lebih baik tentang berbagai tantangan yang kami hadapi saat kami ingin memperluas lingkungan basis data. Jika Anda memiliki komentar atau saran tentang topik ini, jangan ragu untuk berkomentar di bawah posting ini dan bagikan pengalaman Anda