Pada artikel ini, kami akan fokus pada analitik operasional waktu nyata dan bagaimana menerapkan pendekatan ini ke database OLTP. Ketika kita melihat model analitik tradisional, kita dapat melihat OLTP dan lingkungan analitik adalah struktur yang terpisah. Pertama-tama, lingkungan model analitik tradisional perlu membuat tugas ETL (Ekstrak, Transformasi, dan Muat). Karena kita perlu mentransfer data transaksional ke data warehouse. Jenis arsitektur ini memiliki beberapa kelemahan. Mereka adalah biaya, kompleksitas, dan latensi data. Untuk menghilangkan kelemahan ini, kita membutuhkan pendekatan yang berbeda.
Analisis Operasional Waktu Nyata
Microsoft mengumumkan Real-Time Operational Analytics di SQL Server 2016. Kemampuan fitur ini adalah untuk menggabungkan database transaksional dan beban kerja kueri analitik tanpa masalah kinerja. Analisis Operasional Waktu Nyata menyediakan:
- struktur hibrida
- kueri transaksional dan analitik dapat dijalankan secara bersamaan
- tidak menyebabkan masalah kinerja dan latensi.
- implementasi sederhana.
Fitur ini dapat mengatasi kelemahan lingkungan analitik tradisional. Tema utama dari fitur ini adalah bahwa indeks penyimpanan kolom menyimpan salinan data tanpa mempengaruhi kinerja sistem transaksional. Tema ini memungkinkan kueri analitik untuk dieksekusi tanpa memengaruhi kinerja. Jadi ini meminimalkan dampak kinerja. Batasan utama fitur ini adalah kami tidak dapat mengumpulkan data dari sumber data yang berbeda.
Indeks Toko Kolom Tidak Tergugus
SQL Server 2016 memperkenalkan “Non-Clustered Column Store Index” yang dapat diperbarui. Indeks Penyimpanan Kolom yang Tidak Berkelompok adalah indeks berbasis kolom yang memberikan manfaat kinerja untuk kueri analitik. Fitur ini memungkinkan kami membuat kerangka kerja analitik operasional waktu nyata. Itu berarti kami dapat menjalankan transaksi dan kueri analitik pada saat yang bersamaan. Pertimbangkan bahwa kita membutuhkan total penjualan bulanan. Dalam model tradisional, kita harus mengembangkan tugas ETL, data mart, dan gudang data. Namun dalam analitik operasional waktu nyata, kami dapat melakukannya tanpa memerlukan gudang data apa pun atau perubahan apa pun pada struktur OLTP. Kita hanya perlu membuat indeks penyimpanan kolom non-cluster yang sesuai.
Arsitektur indeks toko kolom non-clustered
Mari kita segera melihat arsitektur indeks toko kolom non-cluster dan mekanisme yang berjalan. Indeks penyimpanan kolom yang tidak berkerumun berisi salinan sebagian atau semua baris dan kolom dalam tabel yang mendasarinya. Tema utama indeks penyimpanan kolom non-clustered adalah untuk memelihara salinan data dan menggunakan salinan data ini. Jadi mekanisme ini meminimalkan dampak kinerja database transaksional. Indeks penyimpanan kolom yang tidak berkerumun dapat membuat satu atau lebih dari satu kolom dan dapat menerapkan filter ke kolom.
Saat kita menyisipkan baris baru ke dalam tabel yang memiliki indeks penyimpanan kolom non-cluster, pertama-tama, SQL Server membuat "rowgroup". Rowgroup adalah struktur logis yang mewakili satu set baris. Kemudian SQL Server menyimpan baris-baris ini dalam penyimpanan sementara. Nama penyimpanan sementara ini adalah “deltastore”. SQL Server menggunakan area penyimpanan sementara ini karena mekanisme ini meningkatkan rasio kompresi dan mengurangi fragmentasi indeks. Ketika jumlah baris mencapai 1.048.577, SQL Server menutup status grup baris. SQL Server mengompresi grup baris ini dan mengubah statusnya menjadi "terkompresi".
Sekarang, kita akan membuat tabel dan menambahkan indeks toko kolom yang tidak berkerumun.
DROP TABLE JIKA ADA Analysis_TableTestCREATE TABLE Analysis_TableTest(ID INT PRIMARY KEY IDENTITY(1,1),Continent_Name VARCHAR(20),Country_Name VARCHAR(20),City_Name VARCHAR(20),Sales_Amnt INT,Profit_Amnt INT)GO>BUAT INDEKS NONCLUSTERED COLUMNSTORE [NonClusteredColumnStoreIndex] ON [dbo].[Analysis_TableTest]( [Country_Name], [City_Name] , Sales_Amnt)DENGAN (DROP_EXISTING =OFF, COMPRESSION_DELAY =0)Pada langkah ini, kita akan menyisipkan beberapa baris dan melihat properti dari indeks penyimpanan kolom non-cluster.
INSERT INTO Analysis_TableTest VALUES('Europe','Germany','Munich','100','12')INSERT INTO Analysis_TableTest VALUES('Europe','Turkey','Istanbul','200',' 24')INSERT INTO Analysis_TableTest VALUES('Europe','France','Paris','190','23')INSERT INTO Analysis_TableTest VALUES('America','USA','Newyork','180',' 19')INSERT INTO Analysis_TableTest VALUES('Asia','Japan','Tokyo','190','17')GOKueri ini akan menampilkan status grup baris, jumlah total ukuran baris, dan nilai lainnya.
PILIH i.object_id, object_name(i.object_id) AS TableName, i.name AS IndexName, i.index_id, i.type_desc, CSRowGroups.*, 100*(total_rows - ISNULL(deleted_rows,0))/total_rows AS PersenPenuh DARI sys.indexes AS i GABUNG sys.column_store_row_groups SEBAGAI CSRowGroups PADA i.object_id =CSRowGroups.object_id DAN i.index_id =CSRowGroups.index_id ORDER BY object_name(i.object_id), i.id;
Gambar di atas menunjukkan kepada kita status deltastore dan jumlah total baris yang tidak dikompresi. Sekarang kita akan mengisi lebih banyak data ke tabel dan ketika jumlah baris mencapai 1.048.577, SQL Server akan menutup grup baris pertama dan membuka grup baris baru.
INSERT INTO Analysis_TableTest VALUES('Europe','Germany','Munich','100','12')INSERT INTO Analysis_TableTest VALUES('Europe','Turkey','Istanbul','200',' 24')INSERT INTO Analysis_TableTest VALUES('Europe','France','Paris','190','23')INSERT INTO Analysis_TableTest VALUES('America','USA','Newyork','180',' 19')INSERT INTO Analysis_TableTest VALUES('Asia','Japan','Tokyo','190','17')GO 2000000
SQL Server akan memampatkan grup baris ini dan membuat grup baris baru. Opsi “COMPRESSION_DELAY” memungkinkan kita untuk mengontrol berapa lama rowgroup menunggu dalam status tertutup.
Saat kita menjalankan perintah pemeliharaan indeks (mengatur ulang, membangun kembali) baris yang dihapus secara fisik dihapus dan indeks didefrag.
Saat kami memperbarui (menghapus + menyisipkan) beberapa baris dalam tabel ini, baris yang dihapus ditandai sebagai "dihapus" dan baris baru yang diperbarui dimasukkan ke dalam deltastore.
Tolok ukur kinerja kueri analitik
Dalam judul ini, kami akan mengisi data ke tabel Analysis_TableTest. Saya memasukkan 4 juta catatan. (Anda harus menguji langkah ini dan langkah selanjutnya di lingkungan pengujian Anda. Masalah kinerja dapat terjadi dan juga perintah DBCC DROPCLEANBUFFERS dapat merusak kinerja. Perintah ini akan menghapus semua data buffer di kumpulan buffer.)
Sekarang kita akan menjalankan kueri analitik berikut dan memeriksa nilai kinerjanya.
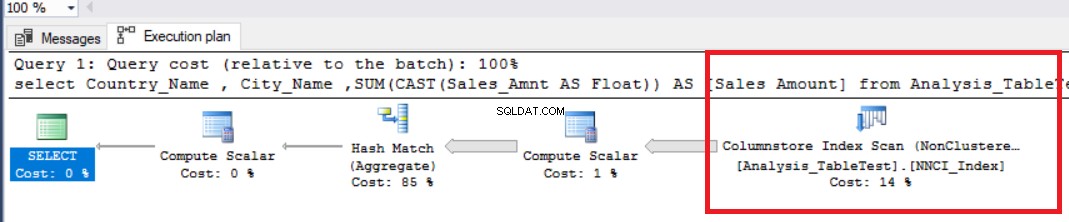
SET STATISTICS WAKTU ONSET STATISTICS IO ONDBCC DROPCLEANBUFFERSpilih Country_Name , City_Name ,SUM(CAST(Sales_Amnt AS Float)) AS [Jumlah Penjualan]dari grup Analysis_TableTest berdasarkanCountry_Name ,City_Name
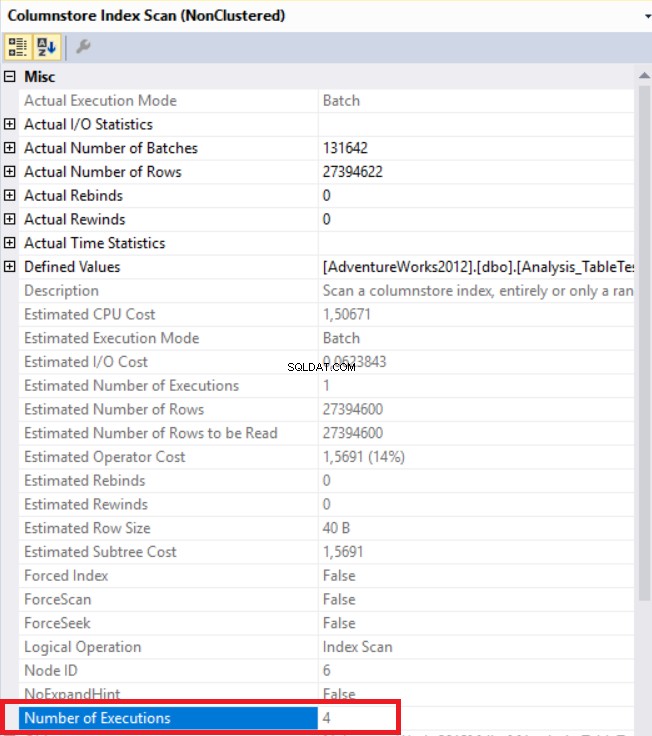
Pada gambar di atas, kita dapat melihat operator pemindaian indeks toko kolom non-cluster. Tabel di bawah ini menunjukkan CPU dan waktu eksekusi. Kueri ini menghabiskan 1,765 milidetik dalam CPU dan selesai dalam 0,791 milidetik. Waktu CPU lebih besar dari waktu yang telah berlalu karena rencana eksekusi menggunakan prosesor paralel dan mendistribusikan tugas ke 4 prosesor. Kita bisa melihatnya di properti operator “Columnstore Index Scan”. Nilai “Jumlah eksekusi” menunjukkan hal ini.
Sekarang kita akan menambahkan petunjuk ke kueri untuk mengurangi jumlah prosesor. Kami tidak akan melihat operator paralelisme.
SET STATISTICS WAKTU ONSET STATISTICS IO ONDBCC DROPCLEANBUFFERSpilih Country_Name , City_Name ,SUM(CAST(Sales_Amnt AS Float)) AS [Jumlah Penjualan]dari grup Analysis_TableTest menurutCountry_Name ,City_NameOPTION (MAXDOP 1)
Tabel di bawah ini mendefinisikan waktu eksekusi. Pada grafik ini, kita dapat melihat waktu yang berlalu lebih besar dari waktu CPU karena SQL Server hanya menggunakan satu prosesor.
Sekarang kita akan menonaktifkan indeks penyimpanan kolom non-cluster dan menjalankan kueri yang sama.
ALTER INDEX [NNCI_Index] AKTIF [dbo].[Analysis_TableTest] DISABLEGOSET STATISTICS WAKTU ONSET STATISTICS IO ONDBCC DROPCLEANBUFFERSpilih Country_Name , City_Name ,SUM(CAST(Sales_Amnt AS Float)) AS dari [Jumlah_Penjualan_TOP] AS [Jumlah_Penjualan] 1)
Tabel di atas menunjukkan kepada kita indeks penyimpanan kolom non-clustered memberikan kinerja luar biasa dalam kueri analitik. Kira-kira, kueri yang diindeks penyimpanan kolom lima kali lebih baik dari yang lain.
Kesimpulan
Analisis Operasional Real-Time memberikan fleksibilitas luar biasa karena kami dapat menjalankan kueri analitik dalam sistem OLTP tanpa latensi data apa pun. Pada saat yang sama, kueri analitik ini tidak memengaruhi kinerja database OLTP. Fitur ini memberi kami kemampuan untuk mengelola data transaksional dan kueri analitik di lingkungan yang sama.
Referensi
Indeks penyimpanan kolom – Panduan pemuatan data
Mulai dengan Toko kolom untuk analisis operasional waktu nyata
Analisis Operasional Waktu Nyata
Bacaan Lebih Lanjut:
Pemindaian Mundur Indeks SQL Server:Memahami, Menyetel
Menggunakan Indeks di Tabel yang Dioptimalkan Memori SQL Server