“Tapi itu berjalan dengan baik di server pengembangan kami!”
Berapa kali saya mendengarnya ketika masalah kinerja kueri SQL terjadi di sana-sini? Saya mengatakannya sendiri pada hari itu. Saya berasumsi bahwa kueri yang berjalan dalam waktu kurang dari satu detik akan berjalan dengan baik di server produksi. Tapi saya salah.
Bisakah Anda mengaitkan pengalaman ini? Jika Anda masih berada di kapal ini hari ini untuk alasan apa pun, posting ini untuk Anda. Ini akan memberi Anda metrik yang lebih baik untuk menyempurnakan kinerja kueri SQL Anda. Kita akan berbicara tentang tiga tokoh paling kritis di STATISTICS IO.
Sebagai contoh, kita akan menggunakan database sampel AdventureWorks.
Sebelum Anda mulai menjalankan kueri di bawah, aktifkan STATISTICS IO. Berikut cara melakukannya di jendela kueri:
USE AdventureWorks
GO
SET STATISTICS IO ONSetelah Anda menjalankan kueri dengan STATISTICS IO ON, pesan yang berbeda akan muncul. Anda dapat melihat ini di tab Pesan dari jendela kueri di SQL Server Management Studio (lihat Gambar 1):
Sekarang setelah kita selesai dengan intro singkat, mari kita gali lebih dalam.
1. Pembacaan Logis Tinggi
Poin pertama dalam daftar kami adalah penyebab paling umum – pembacaan logis yang tinggi.
Pembacaan logis adalah jumlah halaman yang dibaca dari cache data. Sebuah halaman berukuran 8KB. Cache data, di sisi lain, mengacu pada RAM yang digunakan oleh SQL Server.
Pembacaan logis sangat penting untuk penyetelan kinerja. Faktor ini menentukan seberapa banyak SQL Server perlu menghasilkan kumpulan hasil yang diperlukan. Oleh karena itu, satu-satunya hal yang perlu diingat adalah:semakin tinggi pembacaan logis, semakin lama SQL Server perlu bekerja. Ini berarti permintaan Anda akan lebih lambat. Kurangi jumlah pembacaan logis, dan Anda akan meningkatkan kinerja kueri Anda.
Tetapi mengapa menggunakan pembacaan logis alih-alih waktu yang telah berlalu?
- Waktu yang berlalu bergantung pada hal lain yang dilakukan oleh server, bukan hanya kueri Anda saja.
- Waktu yang berlalu dapat berubah dari server pengembangan ke server produksi. Hal ini terjadi jika kedua server memiliki kapasitas dan konfigurasi perangkat keras dan perangkat lunak yang berbeda.
Mengandalkan waktu yang telah berlalu akan menyebabkan Anda berkata, "Tapi itu berjalan dengan baik di server pengembangan kami!" cepat atau lambat.
Mengapa menggunakan pembacaan logis daripada pembacaan fisik?
- Pembacaan fisik adalah jumlah halaman yang dibaca dari disk ke cache data (di memori). Setelah halaman yang diperlukan dalam kueri berada di cache data, tidak perlu membacanya ulang dari disk.
- Saat kueri yang sama dijalankan ulang, pembacaan fisik akan menjadi nol.
Pembacaan logis adalah pilihan logis untuk menyempurnakan kinerja kueri SQL.
Untuk melihat ini beraksi, mari kita lanjutkan ke sebuah contoh.
Contoh Pembacaan Logis
Misalkan Anda perlu mendapatkan daftar pelanggan dengan pesanan yang dikirim 11 Juli 2011 lalu. Anda mendapatkan kueri yang cukup sederhana di bawah ini:
SELECT
d.FirstName
,d.MiddleName
,d.LastName
,d.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM Sales.SalesOrderHeader a
INNER JOIN Sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = D.BusinessEntityID
WHERE a.ShipDate = '07/11/2011'Ini mudah. Kueri ini akan memiliki output berikut:

Kemudian, Anda memeriksa hasil STATISTICS IO dari kueri ini:

Output menunjukkan pembacaan logis dari masing-masing dari empat tabel yang digunakan dalam kueri. Secara total, jumlah pembacaan logis adalah 729. Anda juga dapat melihat pembacaan fisik dengan jumlah total 21. Namun, coba jalankan kembali kueri, dan hasilnya akan menjadi nol.
Lihat lebih dekat pembacaan logis SalesOrderHeader . Apakah Anda bertanya-tanya mengapa ia memiliki 689 pembacaan logis? Mungkin, Anda berpikir untuk memeriksa rencana eksekusi kueri di bawah ini:
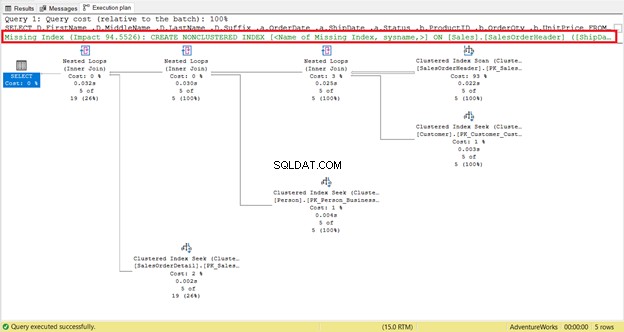
Untuk satu hal, ada pemindaian indeks yang terjadi di SalesOrderHeader dengan biaya 93%. Apa yang bisa terjadi? Asumsikan Anda memeriksa propertinya:
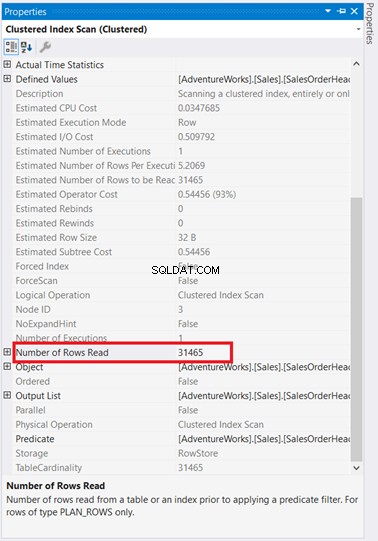
Wah! 31.465 baris dibaca hanya untuk 5 baris yang dikembalikan? Tidak masuk akal!
Mengurangi Jumlah Pembacaan Logis
Tidak terlalu sulit untuk mengurangi 31.465 baris yang dibaca. SQL Server sudah memberi kami petunjuk. Lanjutkan ke berikut ini:
LANGKAH 1:Ikuti Rekomendasi SQL Server dan Tambahkan Indeks yang Hilang
Apakah Anda memperhatikan rekomendasi indeks yang hilang dalam rencana eksekusi (Gambar 4)? Apakah itu akan menyelesaikan masalah?
Ada satu cara untuk mengetahuinya:
CREATE NONCLUSTERED INDEX [IX_SalesOrderHeader_ShipDate]
ON [Sales].[SalesOrderHeader] ([ShipDate])Jalankan kembali kueri dan lihat perubahan dalam pembacaan logika STATISTICS IO.

Seperti yang Anda lihat di STATISTICS IO (Gambar 6), ada penurunan yang luar biasa dalam pembacaan logis dari 689 menjadi 17. Pembacaan logis keseluruhan yang baru adalah 57, yang merupakan peningkatan signifikan dari 729 pembacaan logis. Tapi untuk memastikannya, mari kita periksa lagi rencana eksekusinya.
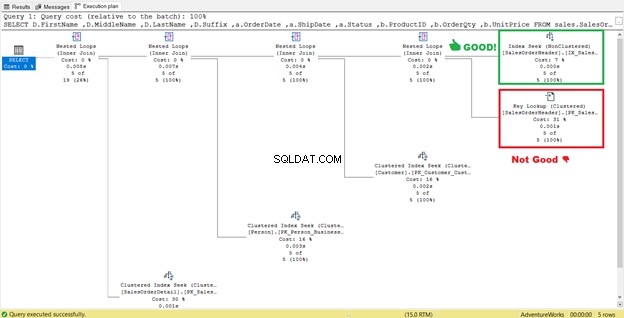
Sepertinya ada peningkatan dalam rencana yang mengakibatkan berkurangnya pembacaan logis. Pemindaian indeks sekarang menjadi pencarian indeks. SQL Server tidak perlu lagi memeriksa baris demi baris untuk mendapatkan catatan dengan Shipdate='07/11/2011′ . Tapi ada sesuatu yang masih mengintai dalam rencana itu, dan itu tidak benar.
Anda memerlukan langkah 2.
LANGKAH 2:Ubah Indeks dan Tambahkan ke Kolom yang Disertakan:OrderDate, Status, dan CustomerID
Apakah Anda melihat operator Pencarian Kunci dalam rencana eksekusi (Gambar 7)? Artinya indeks non-clustered yang dibuat tidak cukup – prosesor kueri perlu menggunakan indeks clustered lagi.
Mari kita periksa propertinya.
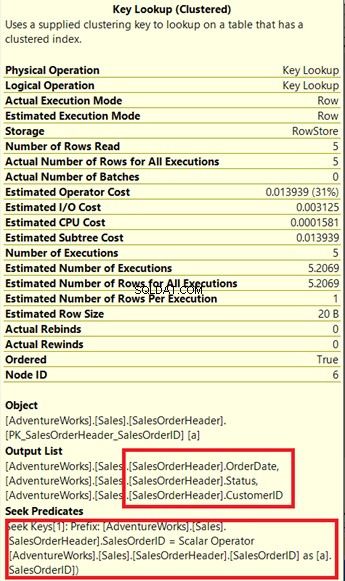
Perhatikan kotak tertutup di bawah Daftar Output . Kebetulan kami membutuhkan OrderDate , Status , dan IDPelanggan dalam himpunan hasil. Untuk mendapatkan nilai tersebut, pemroses kueri menggunakan indeks berkerumun (Lihat Mencari Predikat ) untuk menuju ke meja.
Kita perlu menghapus Pencarian Kunci itu. Solusinya adalah dengan menyertakan OrderDate , Status , dan IDPelanggan kolom ke dalam indeks yang dibuat sebelumnya.
- Klik kanan IX_SalesOrderHeader_ShipDate di SSMS.
- Pilih Properti .
- Klik Kolom yang disertakan tab.
- Tambahkan TanggalPesanan , Status , dan IDPelanggan .
- Klik Oke .
Setelah membuat ulang indeks, jalankan kembali kueri. Apakah ini akan menghapus Pencarian Kunci dan mengurangi pembacaan logis?

Itu berhasil! Dari 17 pembacaan logis hingga 2 (Gambar 9).
Dan Pencarian Kunci ?
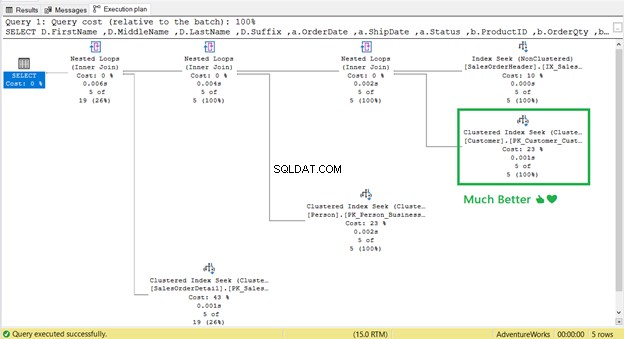
Itu hilang! Pencarian Indeks Terkelompok telah menggantikan Pencarian Kunci.
Bawa Pulang
Jadi, apa yang telah kita pelajari?
Salah satu cara utama untuk mengurangi pembacaan logis dan meningkatkan kinerja kueri SQL adalah dengan membuat indeks yang sesuai. Tapi ada tangkapan. Dalam contoh kami, ini mengurangi pembacaan logis. Terkadang, kebalikannya akan benar. Ini juga dapat memengaruhi kinerja kueri terkait lainnya.
Oleh karena itu, selalu periksa STATISTICS IO dan rencana eksekusi setelah membuat indeks.
2. Pembacaan Logika Lob Tinggi
Ini hampir sama dengan poin #1, tetapi akan berurusan dengan tipe data teks , nteks , gambar , varchar (maks ), nvarchar (maks ), varbiner (maks ), atau toko kolom halaman indeks.
Mari kita lihat sebuah contoh:menghasilkan pembacaan logis lob.
Contoh Lob Logical Reads
Asumsikan Anda ingin menampilkan produk dengan harga, warna, gambar mini, dan gambar yang lebih besar di halaman web. Jadi, Anda datang dengan permintaan awal seperti yang ditunjukkan di bawah ini:
SELECT
a.ProductID
,a.Name AS ProductName
,a.ListPrice
,a.Color
,b.Name AS ProductSubcategory
,d.ThumbNailPhoto
,d.LargePhoto
FROM Production.Product a
INNER JOIN Production.ProductSubcategory b ON a.ProductSubcategoryID = b.ProductSubcategoryID
INNER JOIN Production.ProductProductPhoto c ON a.ProductID = c.ProductID
INNER JOIN Production.ProductPhoto d ON c.ProductPhotoID = d.ProductPhotoID
WHERE b.ProductCategoryID = 1 -- Bikes
ORDER BY ProductSubcategory, ProductName, a.ColorKemudian, Anda menjalankannya dan melihat output seperti di bawah ini:

Karena Anda adalah pria (atau wanita) yang berpikiran tinggi, Anda segera memeriksa STATISTICS IO. Ini dia:

Rasanya seperti ada kotoran di matamu. 665 lob pembacaan logis? Anda tidak dapat menerima ini. Belum lagi 194 pembacaan logis masing-masing dari ProductPhoto dan FotoProdukProduk tabel. Anda memang berpikir kueri ini perlu beberapa perubahan.
Mengurangi Pembacaan Logika Lob
Kueri sebelumnya memiliki 97 baris yang dikembalikan. Semua 97 sepeda. Menurut Anda apakah ini bagus untuk ditampilkan di halaman web?
Indeks dapat membantu, tetapi mengapa tidak menyederhanakan kueri terlebih dahulu? Dengan cara ini, Anda dapat selektif pada apa yang akan dikembalikan oleh SQL Server. Anda dapat mengurangi pembacaan logika lob.
- Tambahkan filter untuk Subkategori Produk dan biarkan pelanggan memilih. Kemudian sertakan ini dalam klausa WHERE.
- Hapus Subkategori Produk kolom karena Anda akan menambahkan filter untuk Subkategori Produk.
- Hapus Foto Besar kolom. Buat kueri ini saat pengguna memilih produk tertentu.
- Gunakan halaman. Pelanggan tidak akan dapat melihat 97 sepeda sekaligus.
Berdasarkan operasi yang dijelaskan di atas, kami mengubah kueri sebagai berikut:
- Hapus Subkategori Produk dan Foto Besar kolom dari kumpulan hasil.
- Gunakan OFFSET dan FETCH untuk mengakomodasi paging dalam kueri. Kueri hanya 10 produk sekaligus.
- Tambahkan IDSubkategori Produk dalam klausa WHERE berdasarkan pilihan pelanggan.
- Hapus Subkategori Produk kolom dalam klausa ORDER BY.
Kueri sekarang akan mirip dengan ini:
DECLARE @pageNumber TINYINT
DECLARE @noOfRows TINYINT = 10 -- each page will display 10 products at a time
SELECT
a.ProductID
,a.Name AS ProductName
,a.ListPrice
,a.Color
,d.ThumbNailPhoto
FROM Production.Product a
INNER JOIN Production.ProductSubcategory b ON a.ProductSubcategoryID = b.ProductSubcategoryID
INNER JOIN Production.ProductProductPhoto c ON a.ProductID = c.ProductID
INNER JOIN Production.ProductPhoto d ON c.ProductPhotoID = d.ProductPhotoID
WHERE b.ProductCategoryID = 1 -- Bikes
AND a.ProductSubcategoryID = 2 -- Road Bikes
ORDER BY ProductName, a.Color
OFFSET (@pageNumber-1)*@noOfRows ROWS FETCH NEXT @noOfRows ROWS ONLY
-- change the OFFSET and FETCH values based on what page the user is.Dengan perubahan yang dilakukan, apakah pembacaan logika lob akan meningkat? STATISTICS IO sekarang melaporkan:

Foto Produk tabel sekarang memiliki 0 pembacaan logika lob – dari 665 pembacaan logika lob hingga tidak ada. Itu adalah beberapa peningkatan.
Bawa pulang
Salah satu cara untuk mengurangi pembacaan logika lob adalah dengan menulis ulang kueri untuk menyederhanakannya.
Hapus kolom yang tidak dibutuhkan dan kurangi baris yang dikembalikan ke yang paling tidak diperlukan. Bila perlu, gunakan OFFSET dan FETCH untuk paging.
Untuk memastikan bahwa perubahan kueri telah meningkatkan pembacaan logika lob dan kinerja kueri SQL, selalu periksa STATISTICS IO.
3. Pembacaan Logika Worktable/Workfile Tinggi
Akhirnya, ini adalah pembacaan logis dari Meja Kerja dan File kerja . Tapi apa tabel ini? Mengapa mereka muncul saat Anda tidak menggunakannya dalam kueri Anda?
Memiliki Meja Kerja dan File kerja muncul di STATISTICS IO berarti SQL Server membutuhkan lebih banyak pekerjaan untuk mendapatkan hasil yang diinginkan. Itu menggunakan tabel sementara di tempdb , yaitu Meja Kerja dan File kerja . Tidak selalu berbahaya untuk memilikinya dalam output STATISTICS IO, selama pembacaan logis adalah nol, dan tidak menyebabkan masalah pada server.
Tabel ini mungkin muncul saat ada ORDER BY, GROUP BY, CROSS JOIN, atau DISTINCT, di antara yang lainnya.
Contoh Pembacaan Logika Worktable/Workfile
Asumsikan bahwa Anda perlu menanyakan semua toko tanpa penjualan produk tertentu.
Anda awalnya datang dengan yang berikut:
SELECT DISTINCT
a.SalesPersonID
,b.ProductID
,ISNULL(c.OrderTotal,0) AS OrderTotal
FROM Sales.Store a
CROSS JOIN Production.Product b
LEFT JOIN (SELECT
b.SalesPersonID
,a.ProductID
,SUM(a.LineTotal) AS OrderTotal
FROM Sales.SalesOrderDetail a
INNER JOIN Sales.SalesOrderHeader b ON a.SalesOrderID = b.SalesOrderID
WHERE b.SalesPersonID IS NOT NULL
GROUP BY b.SalesPersonID, a.ProductID, b.OrderDate) c ON a.SalesPersonID
= c.SalesPersonID
AND b.ProductID = c.ProductID
WHERE c.OrderTotal IS NULL
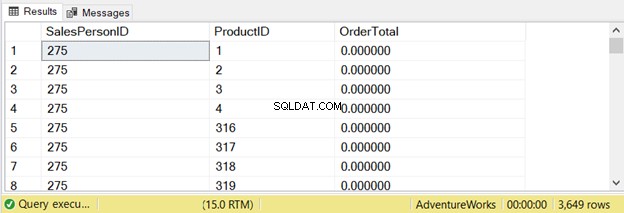
ORDER BY a.SalesPersonID, b.ProductIDKueri ini mengembalikan 3649 baris:
Mari kita periksa apa yang dikatakan STATISTICS IO:

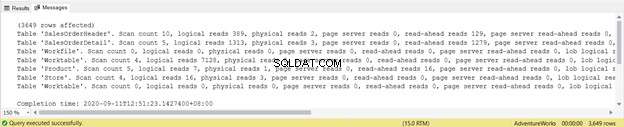
Perlu diperhatikan bahwa Meja Kerja pembacaan logis adalah 7128. Pembacaan logis keseluruhan adalah 8853. Jika Anda memeriksa rencana eksekusi, Anda akan melihat banyak paralelisme, pencocokan hash, spool, dan pemindaian indeks.
Mengurangi Pembacaan Logika Worktable/Workfile
Saya tidak dapat membuat satu pernyataan SELECT dengan hasil yang memuaskan. Jadi satu-satunya pilihan adalah memecah pernyataan SELECT menjadi beberapa kueri. Lihat di bawah:
SELECT DISTINCT
a.SalesPersonID
,b.ProductID
INTO #tmpStoreProducts
FROM Sales.Store a
CROSS JOIN Production.Product b
SELECT
b.SalesPersonID
,a.ProductID
,SUM(a.LineTotal) AS OrderTotal
INTO #tmpProductOrdersPerSalesPerson
FROM Sales.SalesOrderDetail a
INNER JOIN Sales.SalesOrderHeader b ON a.SalesOrderID = b.SalesOrderID
WHERE b.SalesPersonID IS NOT NULL
GROUP BY b.SalesPersonID, a.ProductID
SELECT
a.SalesPersonID
,a.ProductID
FROM #tmpStoreProducts a
LEFT JOIN #tmpProductOrdersPerSalesPerson b ON a.SalesPersonID = b.SalesPersonID AND
a.ProductID = b.ProductID
WHERE b.OrderTotal IS NULL
ORDER BY a.SalesPersonID, a.ProductID
DROP TABLE #tmpProductOrdersPerSalesPerson
DROP TABLE #tmpStoreProductsIni beberapa baris lebih panjang, dan menggunakan tabel sementara. Sekarang, mari kita lihat apa yang diungkapkan STATISTICS IO:
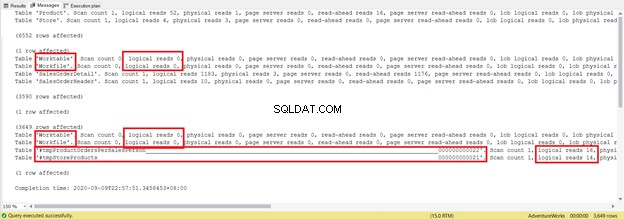
Cobalah untuk tidak fokus pada panjang laporan statistik ini – ini hanya membuat frustrasi. Sebagai gantinya, tambahkan pembacaan logis dari setiap tabel.
Dengan total 1279, ini merupakan penurunan yang signifikan, karena 8853 pembacaan logis dari satu pernyataan SELECT.
Kami belum menambahkan indeks apa pun ke tabel sementara. Anda mungkin memerlukannya jika lebih banyak catatan ditambahkan ke SalesOrderHeader dan Detail PesananPenjualan . Tapi Anda mengerti maksudnya.
Bawa pulang
Terkadang 1 pernyataan SELECT tampak bagus. Namun, di balik layar, yang terjadi justru sebaliknya. Meja kerja dan File Kerja dengan pembacaan logis yang tinggi memperlambat kinerja kueri SQL Anda.
Jika Anda tidak dapat memikirkan cara lain untuk merekonstruksi kueri, dan indeks tidak berguna, coba pendekatan "bagi dan taklukkan". Meja Kerja dan File kerja mungkin masih muncul di tab Pesan SSMS, tetapi pembacaan logis akan menjadi nol. Oleh karena itu, hasil keseluruhan pembacaan akan menjadi kurang logis.
Inti dari Kinerja Kueri SQL dan STATISTICS IO
Apa masalahnya dengan 3 statistik I/O yang buruk ini?
Perbedaan kinerja kueri SQL akan seperti siang dan malam jika Anda memperhatikan angka-angka ini dan menurunkannya. Kami hanya menyajikan beberapa cara untuk mengurangi pembacaan logis seperti:
- membuat indeks yang sesuai;
- menyederhanakan kueri – menghapus kolom yang tidak perlu dan meminimalkan kumpulan hasil;
- mengurai kueri menjadi beberapa kueri.
Ada lagi seperti memperbarui statistik, defragmenting indeks, dan pengaturan FILLFACTOR yang tepat. Bisakah Anda menambahkan lebih banyak tentang ini di bagian komentar?
Jika Anda menyukai postingan ini, silakan bagikan ke media sosial favorit Anda.