Parsing data dari XML menggunakan XQuery adalah praktik rutin. Untuk melakukan ini dengan paling efektif, diperlukan sedikit usaha.
Misalkan kita perlu mengurai data dari file disk dengan struktur berikut:
<tables> <table name="Accounting" schema="Production" object="Accounting"> <column name="Date" order="3" visible="1" /> <column name="DateFrom" order="5" visible="1" /> <column name="DateTo" order="6" visible="1" /> <column name="Description" order="4" visible="1" /> <column name="DocumentUID" order="1" visible="0" /> <column name="Number" order="2" visible="1" /> <column name="Warehouse" order="7" visible="1" /> </table> </tables>
Gunakan BULK INSERT, jika Anda perlu membaca data dari file:
SELECT BulkColumn FROM OPENROWSET(BULK 'D:\data.xml', SINGLE_BLOB) x sample xml file
Contoh file xml ada di sini.
Namun, ingatlah satu hal khusus… Cobalah untuk tidak membaca data secara langsung:
;WITH cte AS
(
SELECT x = CAST(BulkColumn AS XML)
FROM OPENROWSET(BULK 'D:\data.xml', SINGLE_BLOB) x
)
SELECT t.c.value('@name', 'VARCHAR(100)')
FROM cte
CROSS APPLY x.nodes('tables/table') t(c) Tetapkan data ke variabel. Dengan cara ini Anda bisa mendapatkan rencana eksekusi yang lebih efisien:
DECLARE @xml XML
SELECT @xml = BulkColumn
FROM OPENROWSET(BULK 'D:\data.xml', SINGLE_BLOB) x
SELECT t.c.value('@name', 'VARCHAR(100)')
FROM @xml.nodes('tables/table') t(c) Bandingkan hasilnya:
Table 'Worktable'. Scan count 0, logical reads 729, physical reads 0, read-ahead reads 0, lob logical reads 62655,... SQL Server Execution Times: CPU time = 1203 ms, elapsed time = 1214 ms. Table 'Worktable'. Scan count 0, logical reads 7, physical reads 0, read-ahead reads 0, lob logical reads 202,.... SQL Server Execution Times: CPU time = 16 ms, elapsed time = 4 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 3 ms.
Seperti yang Anda lihat, opsi kedua jauh lebih cepat.
Fitur penting lainnya dari SQL Server saat bekerja dengan XQuery adalah membaca elemen induk dapat menghasilkan kinerja yang buruk. Perhatikan contoh berikut:
SET STATISTICS PROFILE OFF
DECLARE @xml XML
SELECT @xml = BulkColumn
FROM OPENROWSET(BULK 'D:\data.xml', SINGLE_BLOB) x
SET STATISTICS PROFILE ON
SELECT
t.c.value('@name', 'SYSNAME')
, t.c.value('@order', 'INT')
, t.c.value('@visible', 'BIT')
, t.c.value('../@name', 'SYSNAME')
, t.c.value('../@schema', 'SYSNAME')
, t.c.value('../@object', 'SYSNAME')
FROM @xml.nodes('tables/table/*') t(c) Mari kita lihat jumlah baris sebenarnya yang diterima dari operator. Nilainya sangat besar:
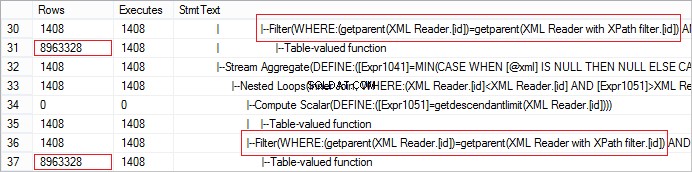
Permintaan dapat dengan mudah dioptimalkan menggunakan CROSS APPLY:
SELECT
t2.c2.value('@name', 'SYSNAME')
, t2.c2.value('@order', 'INT')
, t2.c2.value('@visible', 'BIT')
, t.c.value('@name', 'SYSNAME')
, t.c.value('@schema', 'SYSNAME')
, t.c.value('@object', 'SYSNAME')
FROM @xml.nodes('tables/table') t(c)
CROSS APPLY t.c.nodes('column') t2(c2) Mari kita bandingkan waktu eksekusi:
(1408 row(s) affected) SQL Server Execution Times: CPU time = 10125 ms, elapsed time = 10135 ms. (1408 row(s) affected) SQL Server Execution Times: CPU time = 78 ms, elapsed time = 156 ms.
Seperti yang Anda lihat dari contoh, permintaan dengan CROSS APPLY langsung bekerja.
Terima kasih atas perhatian Anda. Saya harap artikel ini bermanfaat. Jangan ragu untuk mengajukan pertanyaan, tinggalkan komentar dan saran Anda mengenai artikel ini.