Meskipun di masa depan sebagian besar server database (terutama yang menangani beban kerja seperti OLTP) akan menggunakan penyimpanan berbasis flash, kami belum sampai di sana – penyimpanan flash masih jauh lebih mahal daripada hard drive tradisional, dan begitu banyak sistem menggunakan campuran drive SSD dan HDD. Namun itu berarti kita perlu memutuskan bagaimana membagi database – apa yang harus digunakan pada spinning rust (HDD) dan kandidat yang baik untuk penyimpanan flash yang lebih mahal tetapi jauh lebih baik dalam menangani I/O acak.
Ada solusi yang mencoba menangani ini secara otomatis di tingkat penyimpanan dengan secara otomatis menggunakan SSD sebagai cache, secara otomatis menyimpan bagian data yang aktif di SSD. Perangkat penyimpanan / SAN sering melakukan ini secara internal, ada drive SATA/SAS hybrid dengan HDD besar dan SSD kecil dalam satu paket, dan tentu saja ada solusi untuk melakukan ini di host secara langsung – misalnya ada dm-cache di Linux, LVM juga mendapat kemampuan seperti itu (dibangun di atas dm-cache) pada tahun 2014, dan tentu saja ZFS memiliki L2ARC.
Tapi mari kita abaikan semua opsi otomatis itu, dan katakanlah kita memiliki dua perangkat yang terhubung langsung ke sistem – satu berbasis HDD, yang lain berbasis flash. Bagaimana Anda membagi database untuk mendapatkan manfaat maksimal dari flash mahal? Salah satu pola yang umum digunakan adalah melakukan ini berdasarkan jenis objek, terutama tabel vs. indeks. Yang masuk akal secara umum, tetapi kita sering melihat orang menempatkan indeks pada penyimpanan SSD, karena indeks dikaitkan dengan I/O acak. Meskipun ini mungkin tampak masuk akal, ternyata ini justru kebalikan dari apa yang seharusnya Anda lakukan.
Biarkan saya menunjukkan tolok ukur …
Biarkan saya mendemonstrasikan ini pada sistem dengan penyimpanan HDD (RAID10 dibangun dari drive SAS 4x 10k) dan satu perangkat SSD (Intel S3700). Sistem ini memiliki RAM 16GB, jadi mari kita gunakan pgbench dengan skala 300 (=4.5GB) dan 3000 (=45GB), yaitu yang mudah masuk ke dalam RAM dan kelipatan RAM. Kemudian mari kita tempatkan tabel dan indeks pada sistem penyimpanan yang berbeda (dengan menggunakan tablespace), dan ukur kinerjanya. Cluster basis data dikonfigurasi secara wajar (buffer bersama, batas WAL, dll.) sehubungan dengan sumber daya perangkat keras. WAL ditempatkan pada perangkat SSD terpisah, terpasang ke pengontrol RAID yang digunakan bersama dengan drive SAS.
Pada kumpulan data kecil (4,5 GB), hasilnya terlihat seperti ini (perhatikan sumbu y dimulai pada 3000 tps):
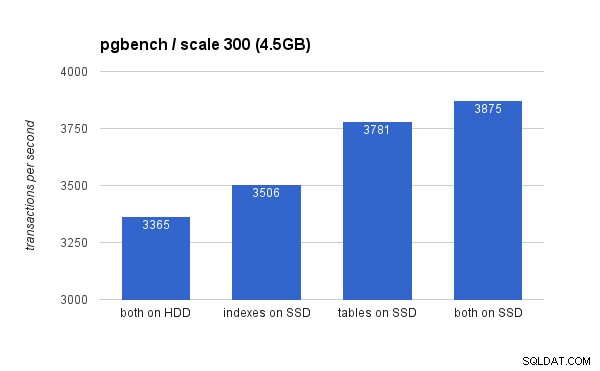
Jelas, menempatkan indeks pada SSD memberikan manfaat yang lebih rendah dibandingkan dengan menggunakan SSD untuk tabel. Sementara dataset dengan mudah masuk ke dalam RAM, perubahan pada akhirnya harus ditulis ke disk pada akhirnya, dan sementara pengontrol RAID memiliki cache tulis, itu tidak dapat benar-benar bersaing dengan penyimpanan flash. Pengontrol RAID baru mungkin akan bekerja sedikit lebih baik, begitu juga dengan drive SSD baru.
Pada kumpulan data besar, perbedaannya jauh lebih signifikan (kali ini sumbu y dimulai dari 0):
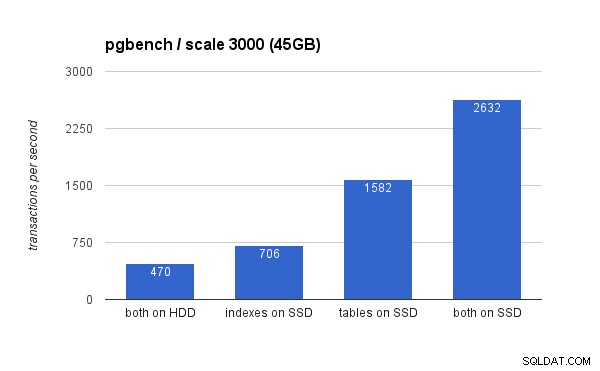
Menempatkan indeks pada SSD menghasilkan peningkatan kinerja yang signifikan (hampir 50%, menggunakan penyimpanan HDD sebagai dasar), tetapi memindahkan tabel ke SSD dengan mudah mengalahkannya dengan memperoleh lebih dari 200%. Tentu saja, jika Anda menempatkan tabel dan indeks pada SSD, Anda akan meningkatkan kinerja lebih jauh – tetapi jika Anda dapat melakukannya, Anda tidak perlu khawatir tentang kasus lainnya.
Tapi kenapa?
Mendapatkan kinerja yang lebih baik dari menempatkan tabel pada SSD mungkin tampak sedikit kontra-intuitif, jadi mengapa berperilaku seperti ini? Yah, itu mungkin kombinasi dari beberapa faktor:
- indeks biasanya jauh lebih kecil daripada tabel, sehingga lebih mudah masuk ke memori
- halaman dalam tingkat indeks (dalam pohon) biasanya cukup panas, dan dengan demikian tetap berada di memori
- saat memindai dan mengindeks, banyak I/O yang sebenarnya bersifat sekuensial (khususnya untuk halaman daun)
Konsekuensinya adalah jumlah I/O yang mengejutkan terhadap indeks tidak terjadi sama sekali (berkat caching) atau berurutan. Di sisi lain, indeks adalah sumber yang bagus untuk I/O acak terhadap tabel.
Ini lebih rumit, meskipun ...
Tentu saja, ini hanya contoh sederhana, dan kesimpulannya mungkin berbeda untuk beban kerja yang berbeda secara substansial, misalnya. Demikian pula, karena SSD lebih mahal, sistem cenderung memiliki lebih banyak ruang disk pada drive HDD daripada pada drive SSD, sehingga tabel mungkin tidak muat ke SSD sementara indeks bisa. Dalam kasus tersebut, penempatan yang lebih rumit diperlukan – misalnya dengan mempertimbangkan tidak hanya jenis objek, tetapi juga seberapa sering objek tersebut digunakan (dan hanya memindahkan tabel yang sering digunakan ke SSD), atau bahkan subset tabel (mis. data dari SSD ke HDD).



