Vakum adalah salah satu fitur terpenting untuk mendapatkan kembali tupel yang dihapus dalam tabel dan indeks. Tanpa ruang hampa, tabel dan indeks akan terus bertambah ukurannya tanpa batas. Posting blog ini menjelaskan opsi PARALLEL untuk perintah VACUUM, yang baru diperkenalkan ke PostgreSQL13.
Fase Pemrosesan Vakum
Sebelum membahas opsi baru secara mendalam, mari kita tinjau detail cara kerja vakum.
Vakum (tanpa opsi LENGKAP) terdiri dari lima fase. Misalnya, untuk tabel dengan dua indeks, cara kerjanya sebagai berikut:
- Fase pemindaian tumpukan
- Pindai tabel dari atas dan kumpulkan tupel sampah di memori.
- Indeks fase vakum
- Mengosongkan kedua indeks satu per satu.
- Fase vakum tumpukan
- Mengosongkan tumpukan (tabel).
- Fase pembersihan indeks
- Bersihkan kedua indeks satu per satu.
- Fase pemotongan tumpukan
- Memotong halaman kosong di akhir tabel.
Dalam fase pemindaian heap, vakum dapat menggunakan Peta Visibilitas untuk melewati pemrosesan halaman yang diketahui tidak memiliki sampah apa pun, sementara dalam fase vakum indeks dan fase pembersihan indeks, bergantung pada metode akses indeks, pemindaian seluruh indeks diperlukan.
Misalnya, indeks btree, jenis indeks paling populer, memerlukan pemindaian indeks keseluruhan untuk menghapus tupel sampah dan melakukan pembersihan indeks. Karena vakum selalu dilakukan oleh satu proses, indeks diproses satu per satu. Waktu eksekusi vakum yang lebih lama terutama pada meja besar sering mengganggu pengguna.
Opsi PARALEL
Untuk mengatasi masalah ini, saya mengusulkan patch untuk memparalelkan vakum pada tahun 2016. Setelah proses peninjauan yang panjang dan banyak reformasi, opsi PARALEL telah diperkenalkan ke PostgreSQL 13. Dengan opsi ini, vakum dapat melakukan fase vakum Indeks dan fase pembersihan indeks dengan pekerja paralel. Pekerja vakum paralel diluncurkan sebelum masuk ke fase vakum indeks atau fase pembersihan indeks dan keluar di akhir fase. Seorang pekerja individu ditugaskan ke indeks. Vakum paralel selalu dinonaktifkan di autovacuum.
Opsi PARALLEL tanpa opsi argumen integer akan secara otomatis menghitung derajat paralel berdasarkan jumlah indeks pada tabel.
VACUUM (PARALLEL) tbl;
Karena proses leader selalu memproses satu indeks, jumlah maksimum pekerja paralel adalah (jumlah indeks dalam tabel – 1), yang selanjutnya dibatasi pada max_parallel_maintenance_workers. Indeks target harus lebih besar dari atau sama dengan min_parallel_index_scan_size.
Opsi PARALLEL memungkinkan kita untuk menentukan derajat paralel dengan melewatkan nilai integer bukan nol. Contoh berikut menggunakan tiga pekerja, dengan total empat proses secara paralel.
VACUUM (PARALLEL 3) tbl;
Opsi PARALLEL diaktifkan secara default; untuk menonaktifkan vakum paralel, setel max_parallel_maintenance_workers ke 0, atau tentukan PARALLEL 0 .
VACUUM (PARALLEL 0) tbl; -- disable parallel vacuum
Melihat output VACUUM VERBOSE, kita dapat melihat bahwa seorang pekerja sedang memproses indeks.
Informasi yang dicetak sebagai "oleh pekerja paralel" dilaporkan oleh pekerja.
VACUUM (PARALLEL, VERBOSE) tbl; INFO: vacuuming "public.tbl" INFO: launched 2 parallel vacuum workers for index vacuuming (planned: 2) INFO: scanned index "i1" to remove 112834 row versions DETAIL: CPU: user: 9.80 s, system: 3.76 s, elapsed: 23.20 s INFO: scanned index "i2" to remove 112834 row versions by parallel vacuum worker DETAIL: CPU: user: 10.64 s, system: 8.98 s, elapsed: 42.84 s INFO: scanned index "i3" to remove 112834 row versions by parallel vacuum worker DETAIL: CPU: user: 10.65 s, system: 8.98 s, elapsed: 43.96 s INFO: "tbl": removed 112834 row versions in 112834 pages DETAIL: CPU: user: 1.12 s, system: 2.31 s, elapsed: 22.01 s INFO: index "i1" now contains 150000000 row versions in 411289 pages DETAIL: 112834 index row versions were removed. 0 index pages have been deleted, 0 are currently reusable. CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s. INFO: index "i2" now contains 150000000 row versions in 411289 pages DETAIL: 112834 index row versions were removed. 0 index pages have been deleted, 0 are currently reusable. CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s. INFO: index "i3" now contains 150000000 row versions in 411289 pages DETAIL: 112834 index row versions were removed. 0 index pages have been deleted, 0 are currently reusable. CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s. INFO: "tbl": found 112834 removable, 112833240 nonremovable row versions in 553105 out of 735295 pages DETAIL: 0 dead row versions cannot be removed yet, oldest xmin: 430046 There were 444 unused item identifiers. Skipped 0 pages due to buffer pins, 0 frozen pages. 0 pages are entirely empty. CPU: user: 18.00 s, system: 8.99 s, elapsed: 91.73 s. VACUUM
Metode Akses Indeks Vs derajat paralelisme
Vakum tidak selalu harus melakukan fase vakum indeks dan fase pembersihan indeks secara paralel. Jika ukuran indeks kecil, atau jika diketahui bahwa proses dapat diselesaikan dengan cepat, biaya peluncuran dan pengelolaan pekerja paralel untuk paralelisasi menyebabkan overhead. Bergantung pada metode akses indeks dan ukurannya, lebih baik tidak melakukan fase ini dengan proses pekerja vakum paralel.
Misalnya pada penyedotan indeks btree yang cukup besar, fase vakum indeks indeks dapat dilakukan oleh pekerja vakum paralel karena selalu memerlukan pemindaian indeks secara keseluruhan, sedangkan fase pembersihan indeks dilakukan oleh pekerja vakum paralel jika indeks vakum tidak dilakukan (mis., Tidak ada sampah di atas meja). Ini karena apa yang dibutuhkan indeks btree dalam fase pembersihan indeks adalah mengumpulkan statistik indeks, yang juga dikumpulkan selama fase vakum indeks. Di sisi lain, indeks hash selalu tidak memerlukan pemindaian indeks pada fase pembersihan indeks.
Untuk mendukung berbagai jenis strategi vakum indeks, pengembang metode akses indeks dapat menentukan perilaku ini dengan menyetel tanda ke amparallelvacuumoptions bidang IndexAmRoutine struktur. Bendera yang tersedia adalah sebagai berikut:
- VACUUM_OPTION_NO_PARALLEL (default)
- vakum paralel dinonaktifkan di kedua fase.
- VACUUM_OPTION_PARALLEL_BULKDEL
- fase vakum indeks dapat dilakukan secara paralel.
- VACUUM_OPTION_PARALLEL_COND_CLEANUP
- fase pembersihan indeks dapat dilakukan secara paralel jika fase vakum indeks belum dilakukan.
- VACUUM_OPTION_PARALLEL_CLEANUP
- fase pembersihan indeks dapat dilakukan secara paralel meskipun fase vakum indeks telah memproses indeks.
Tabel di bawah ini menunjukkan bagaimana indeks AM built-in PostgreSQL mendukung vakum paralel.
| nbtree | hash | gin | inti | spgist | brin | mekar | |
| VACUUM_OPTION_PARALLEL_BULKDEL | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| VACUUM_OPTION_PARALLEL_COND_CLEANUP | ✓ | ✓ | ✓ | ||||
| VACUUM_OPTION_CLEANUP | ✓ | ✓ | ✓ |
Lihat ‘src/include/command/vacuum.h‘ untuk detail lebih lanjut.
Verifikasi Kinerja
Saya telah mengevaluasi kinerja vakum paralel di laptop saya (Core i7 2.6GHz, RAM 16GB, SSD 512GB). Ukuran tabel adalah 6GB dan memiliki delapan indeks 3GB. Hubungan totalnya adalah 30GB, yang tidak sesuai dengan RAM mesin. Untuk setiap evaluasi, saya membuat beberapa persen meja kotor secara merata setelah menyedot debu, kemudian melakukan penyedotan sambil mengubah derajat paralel. Grafik di bawah ini menunjukkan waktu eksekusi vakum.
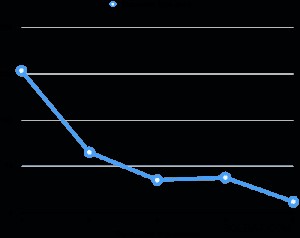
Dalam semua evaluasi waktu eksekusi indeks vakum menyumbang lebih dari 95% dari total waktu eksekusi. Oleh karena itu, paralelisasi fase vakum indeks sangat membantu mengurangi waktu eksekusi vakum.
Terima kasih
Terima kasih khusus kepada Amit Kapila karena telah meninjau, memberikan saran, dan memberikan fitur ini ke PostgreSQL 13. Saya menghargai semua pengembang yang terlibat dalam fitur ini untuk meninjau, menguji, dan berdiskusi.