Beberapa tahun yang lalu (di pgconf.eu 2014 di Madrid) saya mempresentasikan ceramah yang disebut "Arkeologi Kinerja" yang menunjukkan bagaimana kinerja berubah dalam rilis PostgreSQL baru-baru ini. Saya melakukan pembicaraan itu karena menurut saya pandangan jangka panjang itu menarik dan dapat memberi kita wawasan yang mungkin sangat berharga. Untuk orang-orang yang benar-benar mengerjakan kode PostgreSQL seperti saya, ini adalah panduan yang berguna untuk pengembangan di masa mendatang, dan bagi pengguna PostgreSQL ini dapat membantu mengevaluasi peningkatan versi.
Jadi saya memutuskan untuk mengulangi latihan ini, dan menulis beberapa posting blog yang menganalisis kinerja untuk sejumlah versi PostgreSQL. Dalam pembicaraan tahun 2014 saya mulai dengan PostgreSQL 7.4, yang pada saat itu berusia sekitar 10 tahun (dirilis pada tahun 2003). Kali ini saya akan mulai dengan PostgreSQL 8.3, yang berusia sekitar 12 tahun.
Mengapa tidak memulai dengan PostgreSQL 7.4 lagi? Ada sekitar tiga alasan utama mengapa saya memutuskan untuk memulai dengan PostgreSQL 8.3. Pertama, kemalasan umum. Semakin lama versinya, semakin sulit untuk membangun menggunakan versi kompiler saat ini dll. Kedua, dibutuhkan waktu untuk menjalankan benchmark yang tepat terutama dengan jumlah data yang lebih besar, jadi menambahkan satu versi utama dapat dengan mudah menambahkan beberapa hari waktu mesin. Tampaknya tidak layak. Dan akhirnya, 8.3 memperkenalkan sejumlah perubahan penting – peningkatan autovacuum (diaktifkan secara default, proses pekerja bersamaan, ...), pencarian teks lengkap yang terintegrasi ke dalam inti, menyebarkan pos pemeriksaan, dan sebagainya. Jadi saya pikir masuk akal untuk memulai dengan PostgreSQL 8.3. Yang dirilis sekitar 12 tahun yang lalu, jadi perbandingan ini sebenarnya akan mencakup periode waktu yang lebih lama.
Saya telah memutuskan untuk membandingkan tiga jenis beban kerja dasar – OLTP, analitik, dan pencarian teks lengkap. Saya pikir OLTP dan analitik adalah pilihan yang cukup jelas, karena sebagian besar aplikasi adalah campuran dari dua tipe dasar tersebut. Pencarian teks lengkap memungkinkan saya untuk mendemonstrasikan peningkatan dalam tipe indeks khusus, yang juga digunakan untuk mengindeks tipe data populer seperti JSONB, tipe yang digunakan oleh PostGIS, dll.
Mengapa melakukan ini sama sekali?
Apakah itu benar-benar sepadan dengan usaha? Lagi pula, kami melakukan benchmark selama pengembangan sepanjang waktu untuk menunjukkan bahwa patch membantu dan/atau tidak menyebabkan regresi, bukan? Masalahnya adalah ini biasanya hanya tolok ukur "sebagian", membandingkan dua komitmen tertentu, dan biasanya dengan pilihan beban kerja yang cukup terbatas yang menurut kami mungkin relevan. Hal ini sangat masuk akal – Anda tidak dapat menjalankan baterai penuh beban kerja untuk setiap komit.
Sesekali (biasanya segera setelah rilis versi utama PostgreSQL baru) orang menjalankan tes membandingkan versi baru dengan yang sebelumnya, yang bagus dan saya mendorong Anda untuk menjalankan tolok ukur seperti itu (baik itu semacam tolok ukur standar, atau sesuatu yang spesifik untuk aplikasi Anda). Tetapi sulit untuk menggabungkan hasil ini ke dalam tampilan jangka panjang, karena pengujian tersebut menggunakan konfigurasi dan perangkat keras yang berbeda (biasanya yang lebih baru untuk versi yang lebih baru), dan seterusnya. Jadi sulit untuk membuat penilaian yang jelas tentang perubahan secara umum.
Hal yang sama berlaku untuk kinerja aplikasi, yang merupakan "benchmark utama" tentunya. Tetapi orang mungkin tidak meningkatkan ke setiap versi utama (terkadang mereka mungkin melewatkan beberapa versi, misalnya dari 9,5 hingga 12). Dan ketika mereka mengupgrade, seringkali dikombinasikan dengan upgrade hardware dll. Belum lagi aplikasi berkembang dari waktu ke waktu (fitur baru, kompleksitas tambahan), jumlah data dan jumlah pengguna secara bersamaan bertambah, dll.
Itulah yang coba ditunjukkan oleh seri blog ini – tren jangka panjang dalam kinerja PostgreSQL untuk beberapa beban kerja dasar, sehingga kami – para pengembang – mendapatkan perasaan hangat dan tidak jelas tentang pekerjaan yang baik selama bertahun-tahun. Dan untuk menunjukkan kepada pengguna bahwa meskipun PostgreSQL adalah produk yang matang pada saat ini, masih ada peningkatan yang signifikan di setiap versi utama yang baru.
Bukan tujuan saya untuk menggunakan tolok ukur ini untuk perbandingan dengan produk database lain, atau menghasilkan hasil untuk memenuhi peringkat resmi apa pun (seperti TPC-H). Tujuan saya hanyalah untuk mendidik diri saya sendiri sebagai pengembang PostgreSQL, mungkin mengidentifikasi dan menyelidiki beberapa masalah, dan berbagi temuan dengan orang lain.
Perbandingan yang adil?
Saya rasa perbandingan versi yang dirilis selama 12 tahun tidak sepenuhnya adil, karena perangkat lunak apa pun dikembangkan dalam konteks tertentu – perangkat keras adalah contoh yang baik, untuk sistem basis data. Jika Anda melihat mesin yang Anda gunakan 12 tahun yang lalu, berapa banyak inti yang mereka miliki, berapa banyak RAM? Jenis penyimpanan apa yang mereka gunakan?
Server kelas menengah pada tahun 2008 mungkin memiliki 8-12 core, 16GB RAM, dan RAID dengan beberapa drive SAS. Server kelas menengah pada umumnya saat ini mungkin memiliki beberapa lusin inti, ratusan GB RAM, dan penyimpanan SSD.
Pengembangan perangkat lunak diatur berdasarkan prioritas – selalu ada lebih banyak tugas potensial daripada waktu yang Anda miliki, jadi Anda harus memilih tugas dengan rasio biaya/manfaat terbaik untuk pengguna Anda (terutama mereka yang mendanai proyek, secara langsung atau tidak langsung). Dan pada tahun 2008 beberapa pengoptimalan mungkin belum relevan – sebagian besar mesin tidak memiliki jumlah RAM yang ekstrem sehingga mengoptimalkan buffer bersama yang besar belum sepadan, misalnya. Dan banyak hambatan CPU yang dibayangi oleh I/O, karena sebagian besar mesin memiliki penyimpanan "berkarat".
Catatan:Tentu saja, ada pelanggan yang menggunakan mesin yang cukup besar bahkan saat itu. Beberapa menggunakan Postgres komunitas dengan berbagai penyesuaian, yang lain memutuskan untuk menjalankan dengan salah satu dari berbagai garpu Postgres dengan kemampuan tambahan (mis. paralelisme masif, kueri terdistribusi, menggunakan FPGA, dll.). Dan ini juga mempengaruhi pengembangan komunitas, tentu saja.
Karena mesin yang lebih besar menjadi lebih umum selama bertahun-tahun, semakin banyak orang yang mampu membeli mesin dengan RAM dalam jumlah besar dan jumlah inti yang tinggi, menggeser rasio biaya/manfaat. Kemacetan diselidiki dan diatasi, memungkinkan versi yang lebih baru berkinerja lebih baik.
Ini berarti tolok ukur seperti ini selalu sedikit tidak adil – ini akan mendukung versi yang lebih lama atau yang lebih baru, tergantung pada pengaturan (perangkat keras, konfigurasi). Saya telah mencoba memilih parameter perangkat keras dan konfigurasi sehingga tidak terlalu buruk untuk versi yang lebih lama.
Poin yang saya coba sampaikan adalah bahwa ini tidak berarti bahwa versi PostgreSQL yang lebih lama adalah omong kosong – begitulah cara kerja pengembangan perangkat lunak. Anda mengatasi hambatan yang mungkin dihadapi pengguna Anda, bukan hambatan yang mungkin mereka hadapi dalam 10 tahun.
Perangkat Keras
Saya lebih suka melakukan benchmark pada perangkat keras fisik yang memiliki akses langsung, karena itu memungkinkan saya untuk mengontrol semua detail, saya memiliki akses ke semua detail, dan seterusnya. Jadi saya menggunakan mesin yang saya miliki di kantor kami – tidak ada yang mewah, tapi semoga cukup baik untuk tujuan ini.
- 2x E5-2620 v4 (16 core, 32 thread)
- RAM 64GB
- Intel Optane 900P 280GB NVMe SSD (data)
- 3 x 7.2k SATA RAID0 (ruang tabel sementara)
- kernel 5.6.15, ext4
- gcc 9.2.0, dentang 9.0.1
Saya juga menggunakan mesin kedua – jauh lebih kecil –, dengan hanya 4 inti dan RAM 8 GB, yang umumnya menunjukkan peningkatan/regresi yang sama, hanya kurang menonjol.
pgbench
Sebagai alat pembandingan, saya telah menggunakan pgbench yang terkenal, menggunakan versi terbaru (dari PostgreSQL 13) untuk menguji semua versi. Ini menghilangkan kemungkinan bias karena pengoptimalan yang dilakukan di pgbench dari waktu ke waktu, membuat hasilnya lebih sebanding.
Benchmark menguji sejumlah kasus yang berbeda, memvariasikan sejumlah parameter, yaitu:
skala
- kecil – data masuk ke buffer bersama, menunjukkan masalah penguncian, dll.
- medium – data lebih besar dari buffer bersama tetapi cocok dengan RAM, biasanya terikat CPU (atau mungkin I/O untuk beban kerja baca-tulis)
- besar – data lebih besar dari RAM, terutama terikat I/O
mode
- hanya-baca – pgbench -S
- baca-tulis – pgbench -N
jumlah klien
- 1, 4, 8, 16, 32, 64, 128, 256
- jumlah utas pgbench (-j) diubah sesuai kebutuhan
Hasil
Oke, mari kita lihat hasilnya. Saya akan menyajikan hasil dari penyimpanan NVMe terlebih dahulu, kemudian saya akan menunjukkan beberapa hasil menarik menggunakan penyimpanan RAID SATA.
NVMe SSD / hanya-baca
Untuk kumpulan data kecil (yang sepenuhnya sesuai dengan buffer bersama), hasil read-only terlihat seperti ini:
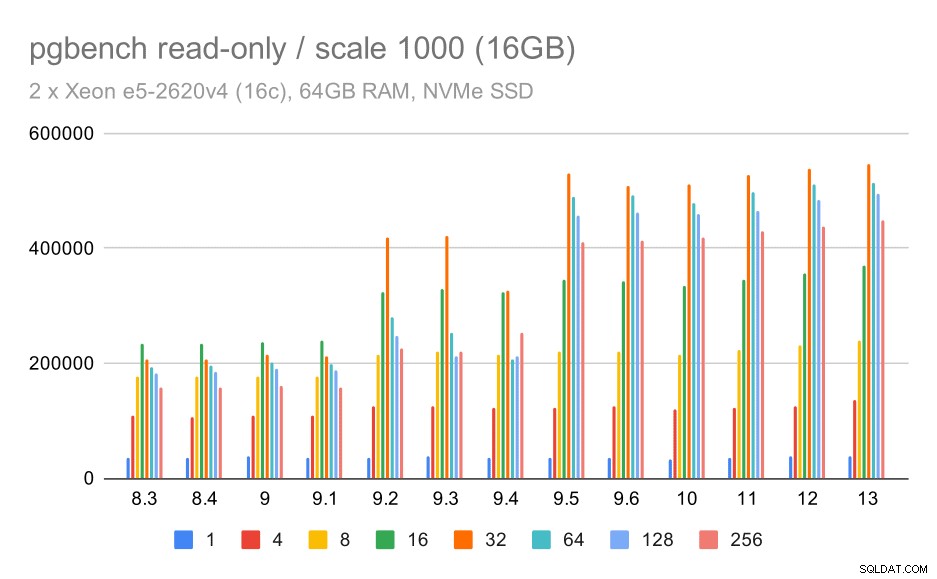
hasil pgbench / read-only pada kumpulan data kecil (skala 100, yaitu 1.6GB)
Jelas, ada peningkatan throughput yang signifikan di 9.2, yang berisi sejumlah peningkatan kinerja, misalnya jalur cepat untuk penguncian. Throughput untuk satu klien sebenarnya turun sedikit – dari 47rb tps menjadi hanya sekitar 42rb tps. Tetapi untuk jumlah klien yang lebih tinggi, peningkatan pada 9.2 cukup jelas.
hasil pgbench / read-only pada kumpulan data sedang (skala 1000, yaitu 16GB)
Untuk kumpulan data menengah (yang lebih besar dari buffer bersama tetapi masih cocok dengan RAM) tampaknya ada beberapa peningkatan pada 9.2 juga, meskipun tidak sejelas di atas, diikuti oleh peningkatan yang jauh lebih jelas pada 9.5 kemungkinan besar berkat peningkatan skalabilitas kunci .
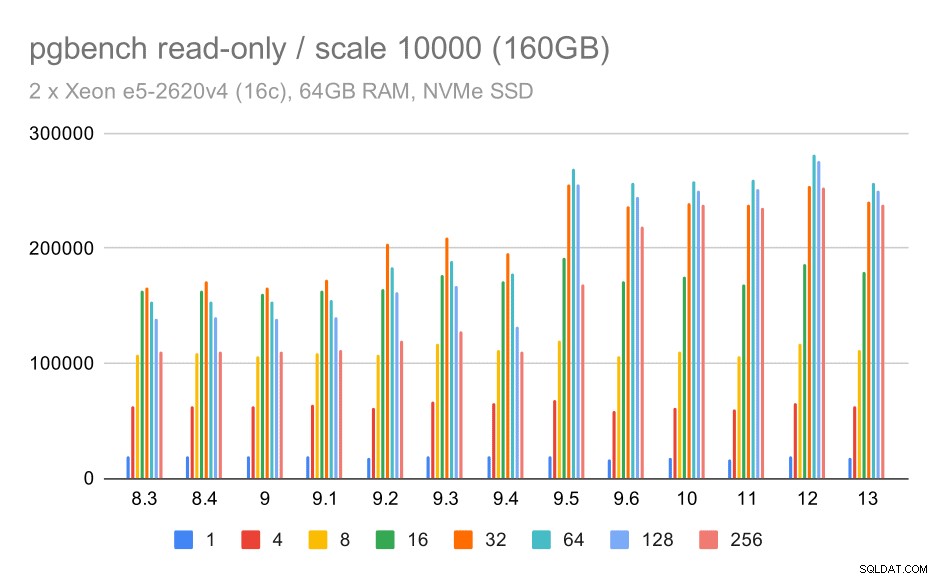
hasil pgbench / read-only pada kumpulan data besar (skala 10000, yaitu 160GB)
Pada kumpulan data terbesar, yang sebagian besar adalah tentang kemampuan untuk memanfaatkan penyimpanan secara efisien, ada beberapa percepatan juga – kemungkinan besar berkat peningkatan 9.5 juga.
NVMe SSD / baca-tulis
Hasil baca-tulis juga menunjukkan beberapa peningkatan, meski tidak begitu terasa. Pada kumpulan data kecil, hasilnya terlihat seperti ini:
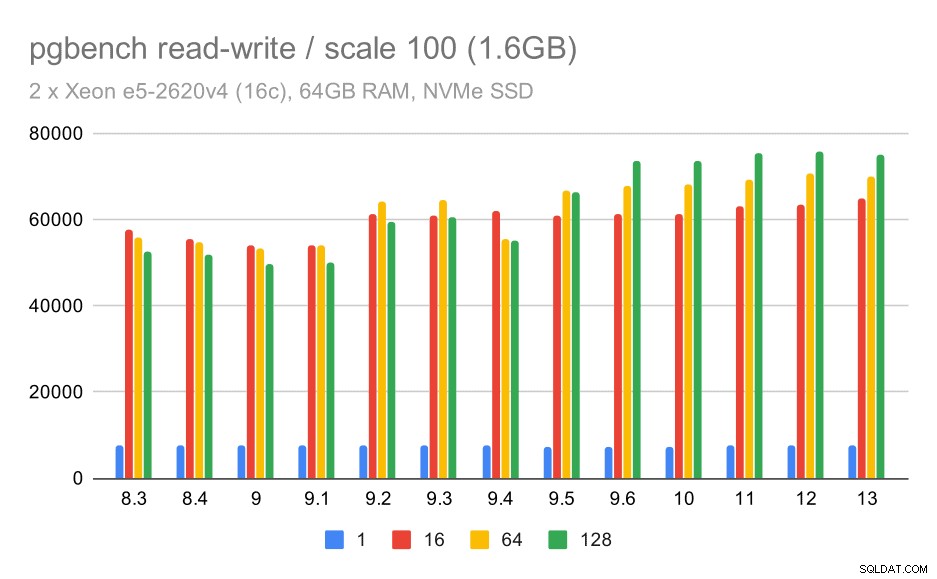
hasil pgbench / baca-tulis pada kumpulan data kecil (skala 100, yaitu 1.6GB)
Jadi sedikit peningkatan dari sekitar 52rb menjadi 75rb tps dengan jumlah klien yang cukup.
Untuk kumpulan data menengah, peningkatannya jauh lebih jelas – dari sekitar 27rb menjadi 63rb tps, yaitu throughput lebih dari dua kali lipat.
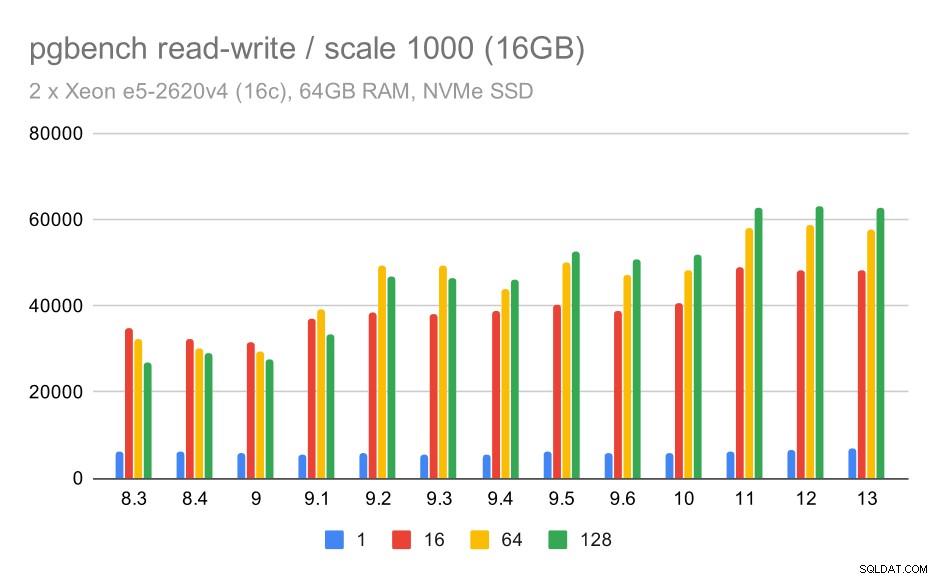
hasil pgbench / baca-tulis pada kumpulan data sedang (skala 1000, yaitu 16GB)
Untuk kumpulan data terbesar, kami melihat peningkatan keseluruhan yang serupa, tetapi tampaknya ada beberapa regresi antara 9,5 dan 11,
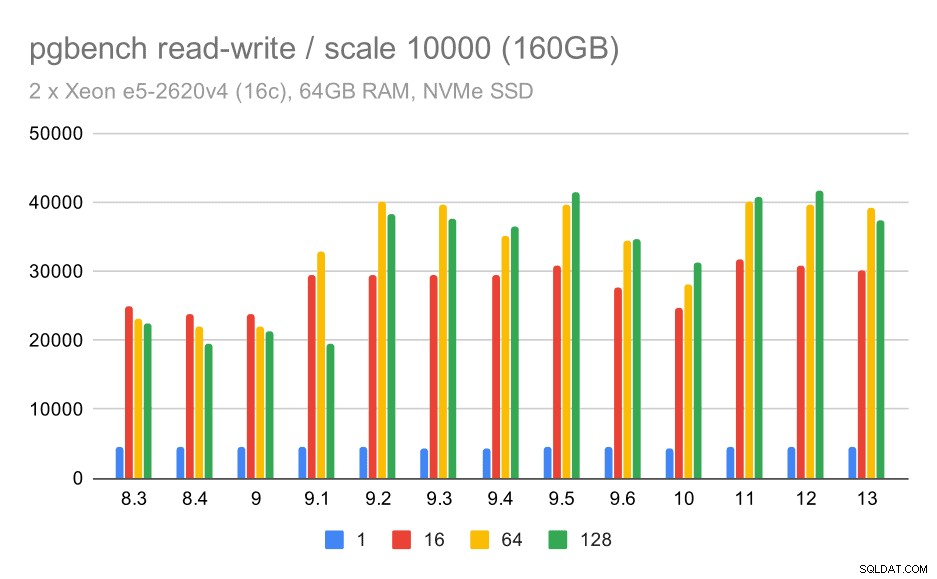
hasil pgbench / baca-tulis pada kumpulan data besar (skala 10000, yaitu 160GB)
SATA RAID / hanya-baca
Untuk penyimpanan SATA RAID, hasil read-only tidak begitu bagus. Kita dapat mengabaikan kumpulan data kecil dan menengah, yang sistem penyimpanannya tidak relevan. Untuk kumpulan data besar, throughput agak bising tetapi tampaknya benar-benar menurun seiring waktu – terutama sejak PostgreSQL 9.6. Saya tidak tahu apa alasannya (tidak ada dalam catatan rilis 9.6 yang menonjol seperti kandidat yang jelas), tetapi sepertinya semacam regresi.
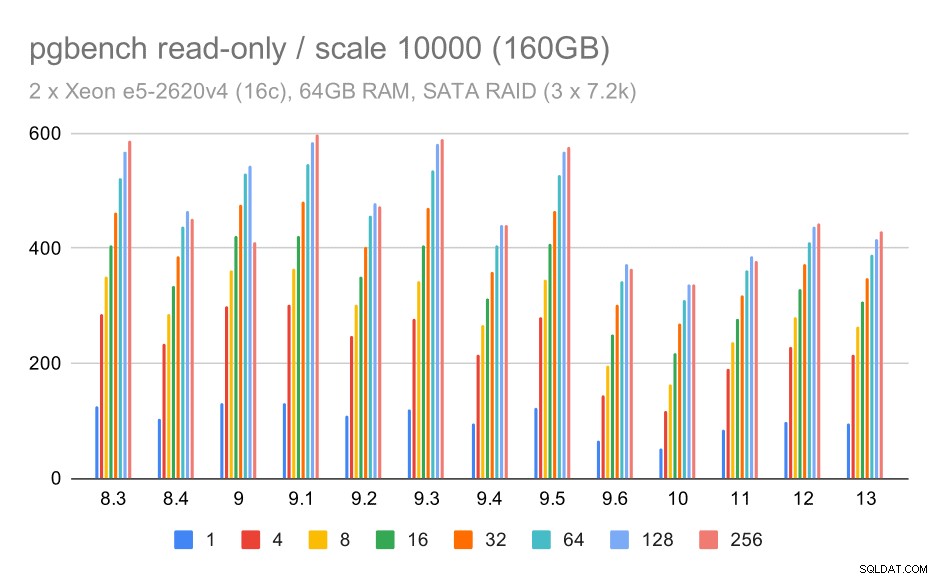
hasil pgbench pada SATA RAID / read-only pada kumpulan data besar (skala 10000, yaitu 160GB)
SATA RAID / baca-tulis
Namun, perilaku baca-tulis tampaknya jauh lebih baik. Pada kumpulan data kecil, throughput meningkat dari sekitar 600 tps menjadi lebih dari 6000 tps. Saya yakin ini berkat peningkatan komitmen grup di 9.1 dan 9.2.
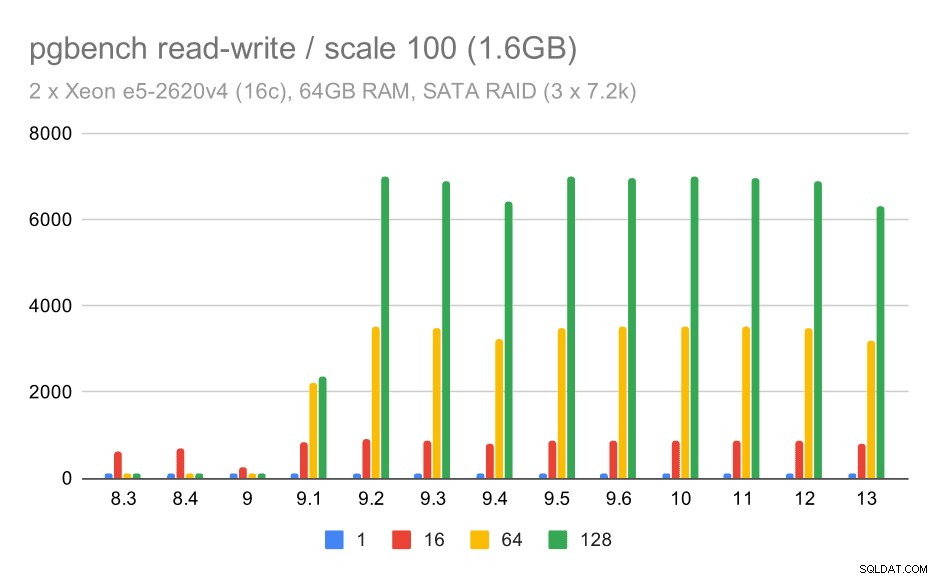
hasil pgbench pada RAID SATA / baca-tulis pada kumpulan data kecil (skala 100, yaitu 1,6GB)
Untuk skala menengah dan besar kita dapat melihat peningkatan yang serupa – tetapi lebih kecil –, karena penyimpanan juga perlu menangani permintaan I/O untuk membaca dan menulis blok data. Untuk skala menengah kita hanya perlu melakukan write (karena data masuk ke dalam RAM), untuk skala besar kita juga perlu melakukan read – sehingga throughput maksimumnya pun lebih rendah.
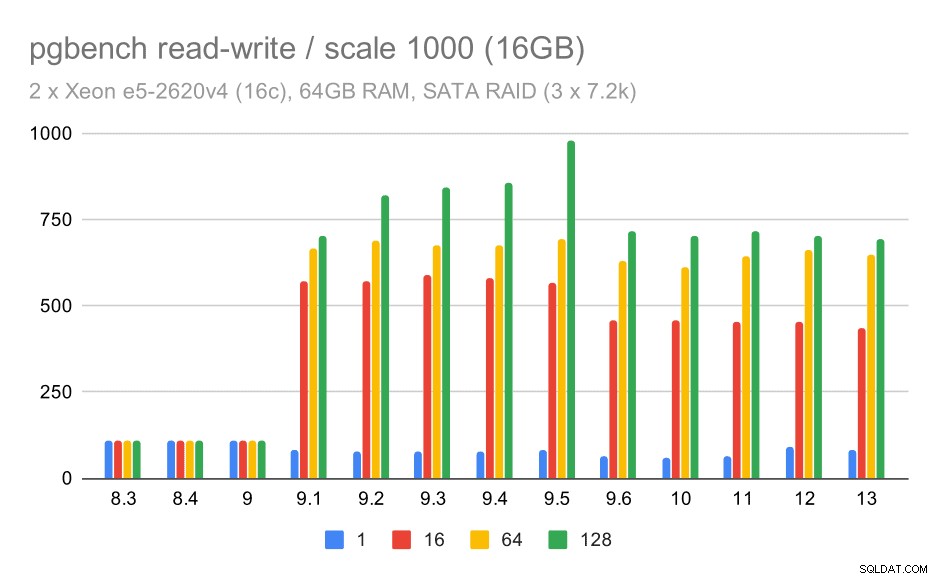
hasil pgbench pada RAID SATA / baca-tulis pada kumpulan data sedang (skala 1000, yaitu 16GB)
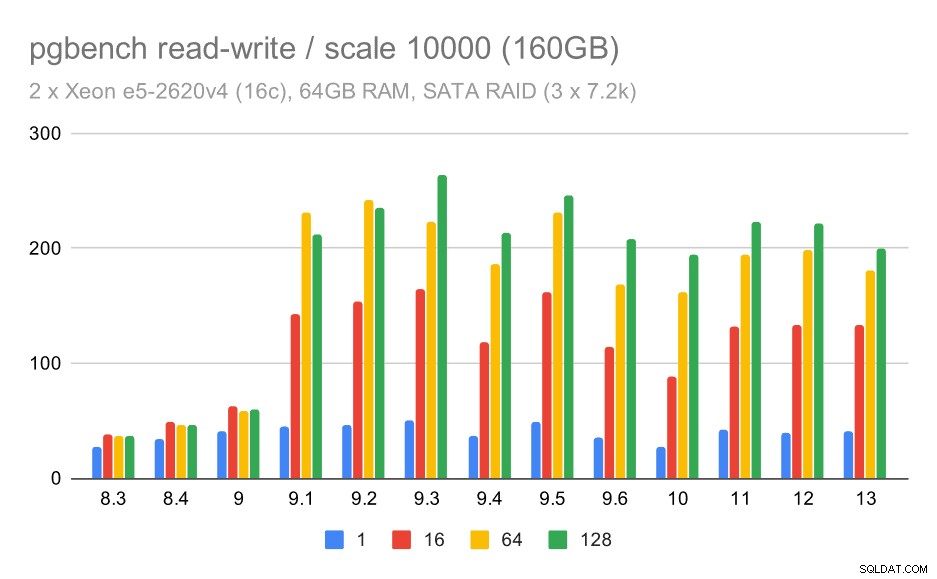
hasil pgbench pada RAID SATA / baca-tulis pada kumpulan data besar (skala 10000, yaitu 160GB)
Ringkasan dan Masa Depan
Untuk meringkas ini, untuk pengaturan NVMe kesimpulannya tampaknya cukup positif. Untuk beban kerja hanya-baca, terdapat peningkatan sedang di 9.2 dan percepatan yang signifikan di 9,5, berkat pengoptimalan skalabilitas, sedangkan untuk beban kerja baca-tulis, kinerjanya meningkat sekitar 2x dari waktu ke waktu, dalam beberapa versi/langkah.
Dengan pengaturan RAID SATA, kesimpulannya agak beragam. Dalam hal beban kerja hanya-baca, ada banyak variabilitas / noise, dan kemungkinan regresi di 9.6. Untuk beban kerja baca-tulis, ada peningkatan besar-besaran di 9.1 di mana throughput tiba-tiba meningkat dari 100 tps menjadi sekitar 600 tps.
Bagaimana dengan peningkatan di versi PostgreSQL mendatang? Saya tidak memiliki gagasan yang sangat jelas tentang peningkatan besar berikutnya – namun saya yakin peretas PostgreSQL lainnya akan muncul dengan ide-ide brilian yang membuat segalanya lebih efisien atau memungkinkan pemanfaatan sumber daya perangkat keras yang tersedia. Patch untuk meningkatkan skalabilitas dengan banyak koneksi atau patch untuk menambahkan dukungan untuk buffer WAL yang tidak mudah menguap adalah contoh peningkatan tersebut. Kami mungkin melihat beberapa peningkatan radikal pada penyimpanan PostgreSQL (format di disk yang lebih efisien, menggunakan I/O langsung, dll.), pengindeksan, dll.