Di bagian pertama dari seri blog ini, saya telah menyajikan beberapa hasil benchmark yang menunjukkan bagaimana kinerja OLTP PostgreSQL berubah sejak 8.3, dirilis pada tahun 2008. Pada bagian ini saya berencana untuk melakukan hal yang sama tetapi untuk kueri analitik / BI, pemrosesan besar jumlah data.
Ada sejumlah tolok ukur industri untuk menguji beban kerja ini, tetapi mungkin yang paling umum digunakan adalah TPC-H, jadi itulah yang akan saya gunakan untuk posting blog ini. Ada juga TPC-DS, tolok ukur TPC lain untuk menguji sistem pendukung keputusan, yang dapat dilihat sebagai evolusi atau pengganti TPC-H. Saya memutuskan untuk tetap menggunakan TPC-H karena beberapa alasan.
Pertama, TPC-DS jauh lebih kompleks, baik dari segi skema (lebih banyak tabel) dan jumlah kueri (22 vs. 99). Menyetel ini dengan benar, terutama ketika berhadapan dengan beberapa versi PostgreSQL, akan jauh lebih sulit. Kedua, beberapa kueri TPC-DS menggunakan fitur yang tidak didukung oleh versi PostgreSQL yang lebih lama (misalnya kumpulan pengelompokan), membuat kueri tersebut tidak relevan untuk beberapa versi. Dan terakhir, menurut saya orang-orang jauh lebih mengenal TPC-H dibandingkan dengan TPC-DS.
Tujuannya bukan untuk memungkinkan perbandingan dengan produk database lain, hanya untuk memberikan karakterisasi jangka panjang yang wajar tentang bagaimana kinerja PostgreSQL berkembang sejak PostgreSQL 8.3.
Catatan :Untuk analisis benchmark TPC-H yang sangat menarik, saya sangat merekomendasikan makalah “TPC-H Analyzed:Hidden Messages and Lessons Learned from a Influential Benchmark” dari Boncz, Neumann dan Erling.
Perangkat keras
Sebagian besar hasil dalam posting blog ini berasal dari "kotak yang lebih besar" yang saya miliki di kantor kami, yang memiliki parameter berikut:
- 2x E5-2620 v4 (16 core, 32 thread)
- RAM 64GB
- Intel Optane 900P 280GB NVMe SSD (data)
- 3 x 7.2k SATA RAID0 (ruang tabel sementara)
- kernel 5.6.15, sistem file ext4
Saya yakin Anda dapat membeli mesin yang jauh lebih besar, tetapi saya yakin ini cukup baik untuk memberi kami data yang relevan. Ada dua varian konfigurasi – satu dengan paralelisme dinonaktifkan, satu dengan paralelisme diaktifkan. Sebagian besar nilai parameter sama dalam kedua kasus, disetel ke sumber daya perangkat keras yang tersedia (CPU, RAM, penyimpanan). Anda dapat menemukan informasi lebih rinci tentang konfigurasi di akhir posting ini.
Tolok ukur
Saya ingin memperjelas bahwa bukan tujuan saya untuk menerapkan tolok ukur TPC-H yang valid yang dapat melewati semua kriteria yang dipersyaratkan oleh TPC. Tujuan saya adalah untuk mengevaluasi bagaimana kinerja kueri analitik yang berbeda berubah dari waktu ke waktu, bukan mengejar ukuran abstrak kinerja per dolar atau sesuatu seperti itu.
Jadi saya memutuskan untuk hanya menggunakan subset dari TPC-H – pada dasarnya hanya memuat data, dan menjalankan 22 kueri (parameter yang sama di semua versi). Tidak ada penyegaran data, kumpulan data statis setelah pemuatan awal. Saya telah memilih sejumlah faktor skala, 1, 10, dan 75, sehingga kami mendapatkan hasil untuk buffer yang cocok untuk digunakan bersama (1), cocok dengan memori (10) dan lebih banyak dari memori (75) . Saya akan memilih 100 untuk menjadikannya "urutan yang bagus", yang tidak sesuai dengan penyimpanan 280GB dalam beberapa kasus (berkat indeks, file sementara, dll.). Perhatikan bahwa faktor skala 75 bahkan tidak dikenali oleh TPC-H sebagai faktor skala yang valid.
Tetapi apakah masuk akal untuk membandingkan set data 1GB atau 10GB? Orang cenderung fokus pada database yang jauh lebih besar, jadi mungkin tampak agak bodoh untuk repot-repot mengujinya. Tapi menurut saya itu tidak berguna – sebagian besar database di alam liar cukup kecil, menurut pengalaman saya Dan bahkan ketika seluruh database besar, orang biasanya hanya bekerja dengan sebagian kecil saja – data terbaru, pesanan yang belum terselesaikan, dll. Jadi menurut saya masuk akal untuk menguji bahkan dengan kumpulan data kecil itu.
Pemuatan data
Pertama, mari kita lihat berapa lama waktu yang dibutuhkan untuk memuat data ke dalam database – tanpa dan dengan paralelisme. Saya hanya akan menampilkan hasil dari kumpulan data 75 GB, karena perilaku keseluruhannya hampir sama untuk kasus yang lebih kecil.
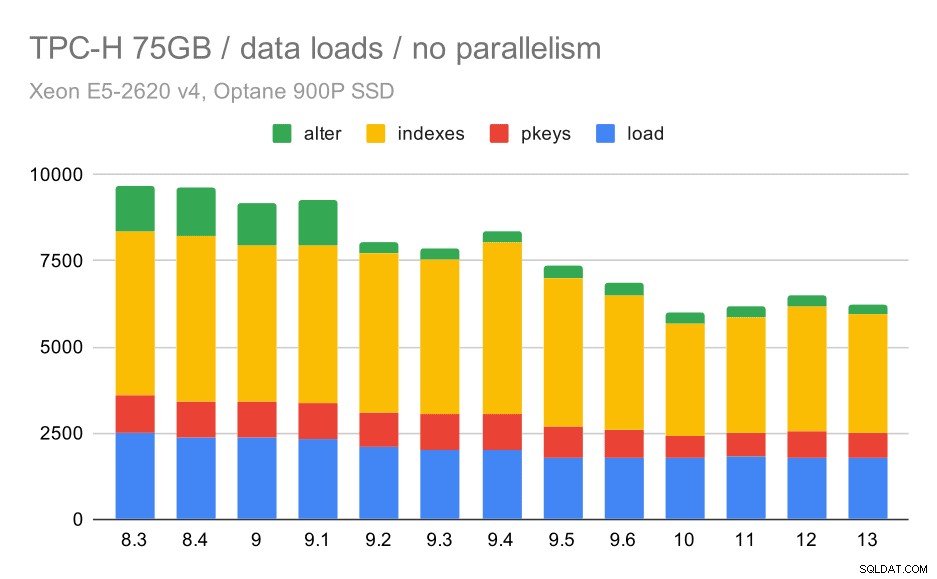
Durasi pemuatan data TPC-H – skala 75GB, tanpa paralelisme
Anda dapat dengan jelas melihat ada tren peningkatan yang stabil, mengurangi sekitar 30% dari durasi hanya dengan meningkatkan efisiensi di keempat langkah – SALIN, membuat kunci utama dan indeks, dan (terutama) menyiapkan kunci asing. Peningkatan "ubah" di 9.2 sangat jelas.
Sekarang, mari kita lihat bagaimana mengaktifkan paralelisme mengubah perilaku. Bagan berikut membandingkan hasil dengan paralelisme diaktifkan – ditandai dengan “(p)” – dengan hasil dengan paralelisme dinonaktifkan.
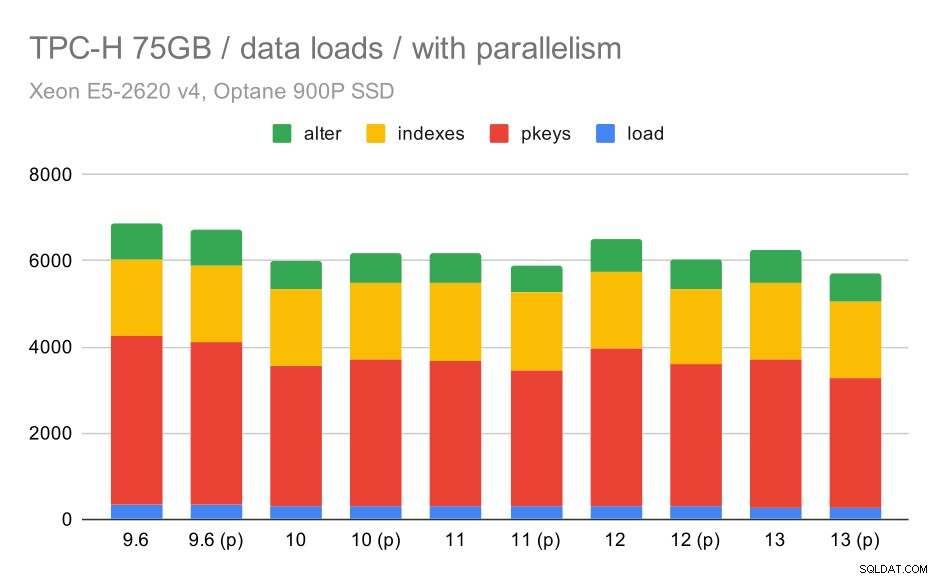
Durasi pemuatan data TPC-H – skala 75 GB, paralelisme diaktifkan.
Sayangnya, tampaknya efek paralelisme sangat terbatas dalam pengujian ini – memang sedikit membantu, tetapi perbedaannya cukup kecil. Jadi peningkatan keseluruhan tetap sekitar 30%.
Permintaan
Sekarang kita bisa melihat query. TPC-H memiliki 22 templat kueri – Saya telah membuat satu set kueri aktual, dan menjalankannya di semua versi dua kali – pertama setelah menghapus semua cache dan memulai ulang instans, lalu dengan cache pemanasan. Semua angka yang ditampilkan dalam bagan adalah yang terbaik dari dua putaran ini (dalam kebanyakan kasus, ini adalah yang kedua, tentu saja).
Tidak ada paralelisme
Tanpa paralelisme, hasil pada kumpulan data terkecil cukup jelas – setiap bilah dibagi menjadi beberapa bagian dengan warna berbeda untuk masing-masing dari 22 kueri. Sulit untuk mengatakan bagian mana yang memetakan kueri yang tepat, tetapi cukup untuk mengidentifikasi kasus ketika satu kueri meningkat atau menjadi jauh lebih buruk di antara dua proses. Misalnya di grafik pertama sangat jelas Q21 menjadi jauh lebih cepat antara 8,3 dan 8,4.
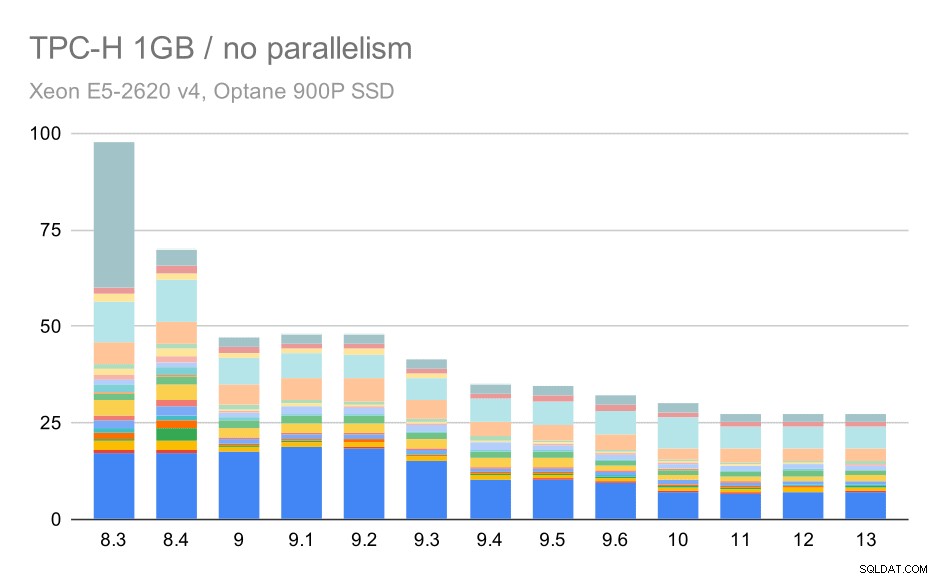
Kueri TPC-H pada kumpulan data kecil (1GB) – paralelisme dinonaktifkan
Untuk skala 10 GB, hasilnya agak sulit untuk ditafsirkan, karena pada 8.3 salah satu kueri (Q21) membutuhkan waktu yang sangat lama untuk dieksekusi sehingga mengerdilkan yang lainnya.
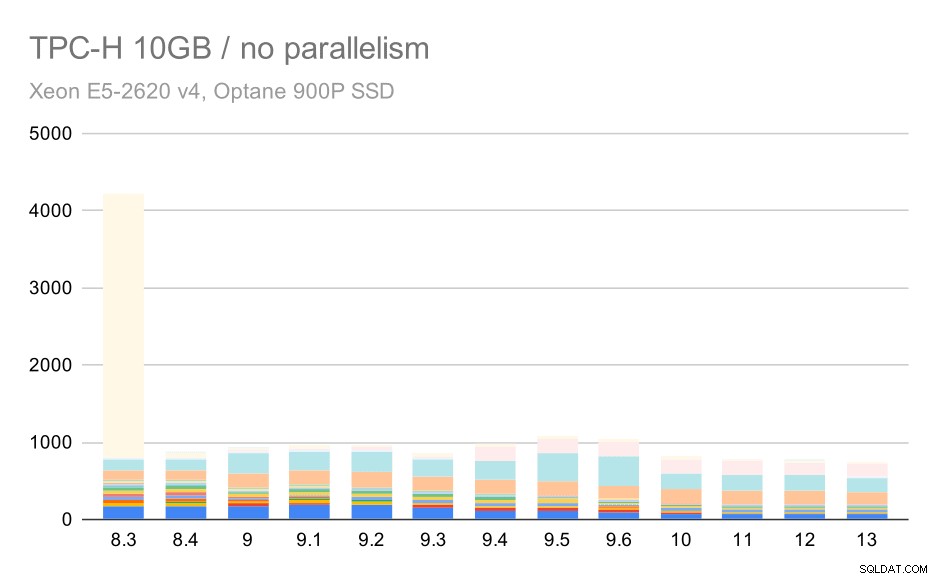
Kueri TPC-H pada kumpulan data sedang (10GB) – paralelisme dinonaktifkan
Jadi mari kita lihat bagaimana tampilan grafik tanpa Q21:
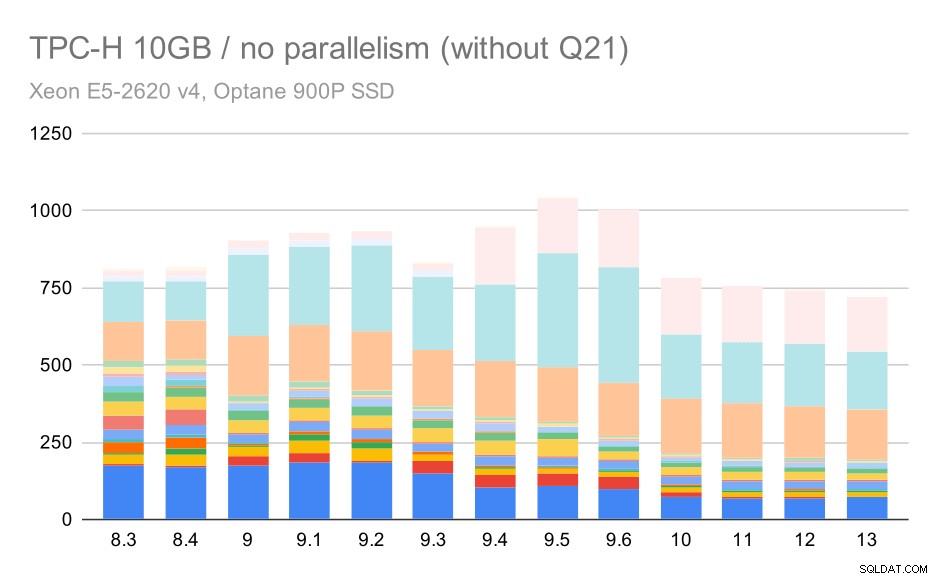
Kueri TPC-H pada kumpulan data sedang (10GB) – paralelisme dinonaktifkan, tanpa masalah Q2
Oke, itu lebih mudah dibaca. Kita dapat dengan jelas melihat bahwa sebagian besar kueri (hingga Q17) menjadi lebih cepat, tetapi kemudian dua kueri (Q18 dan Q20) menjadi agak lebih lambat. Kami akan melihat masalah serupa pada kumpulan data terbesar, jadi saya akan membahas apa yang mungkin menjadi akar masalahnya.
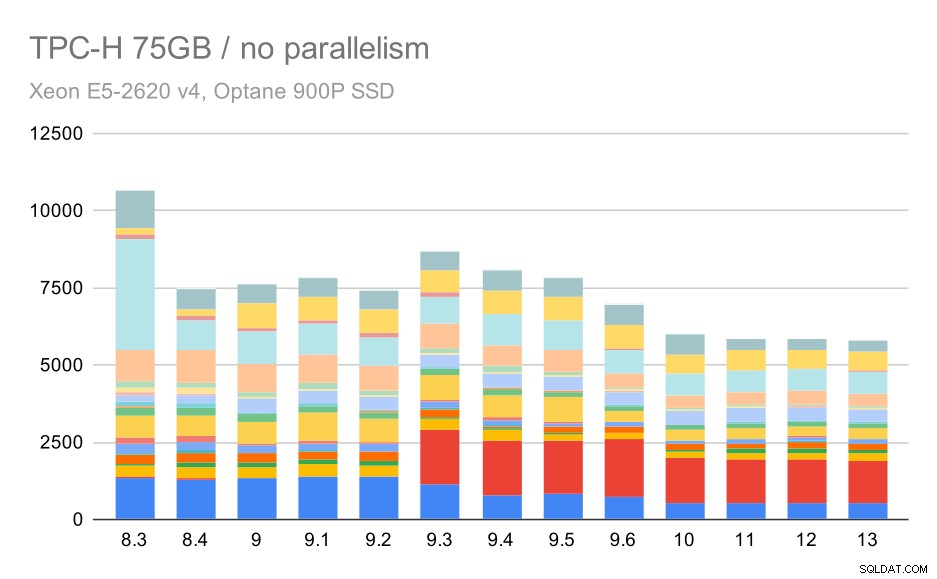
Kueri TPC-H pada kumpulan data besar (75GB) – paralelisme dinonaktifkan
Sekali lagi, kami melihat peningkatan yang tiba-tiba untuk salah satu kueri di 9.3 – kali ini Q2, yang tanpanya bagan akan terlihat seperti ini:
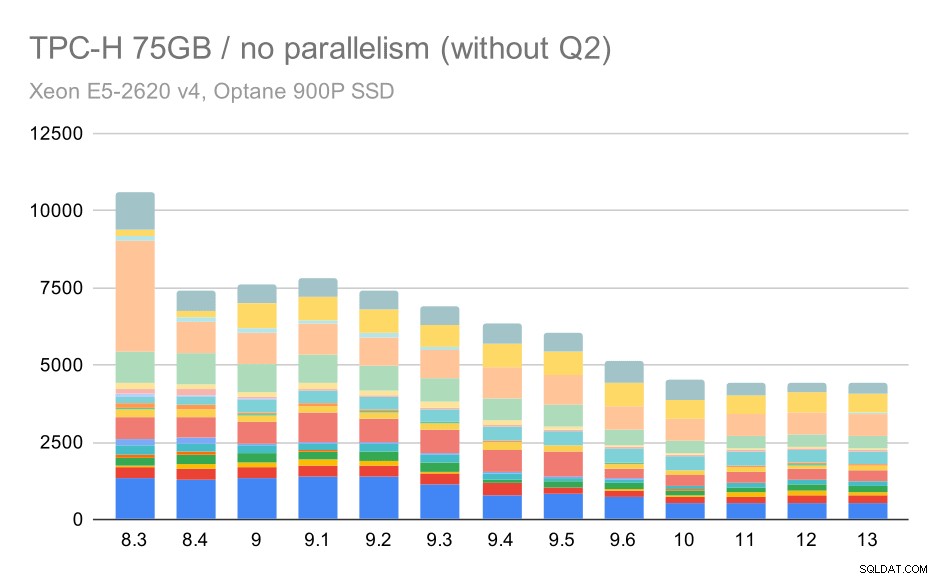
Kueri TPC-H pada kumpulan data besar (75GB) – paralelisme dinonaktifkan, tanpa masalah Q2
Itu peningkatan yang cukup bagus secara umum, mempercepat seluruh eksekusi dari ~2,7 jam menjadi hanya ~1,2 jam, hanya dengan membuat perencana dan pengoptimal lebih cerdas, dan dengan membuat pelaksana lebih efisien (ingat, paralelisme dinonaktifkan dalam proses ini) .
Jadi, apa yang bisa menjadi masalah dengan Q2, membuatnya lebih lambat di 9.3? Jawaban sederhananya adalah bahwa setiap kali Anda membuat perencana dan pengoptimal lebih cerdas – baik dengan membangun jenis jalur / rencana baru, atau dengan membuatnya bergantung pada beberapa statistik, itu juga berarti kesalahan baru dapat dibuat ketika statistik atau perkiraan salah. Di Q2, klausa WHERE mereferensikan subkueri agregat – versi kueri yang disederhanakan mungkin terlihat seperti ini:
Masalahnya adalah kita tidak mengetahui nilai rata-rata pada waktu perencanaan, sehingga tidak mungkin untuk menghitung perkiraan yang cukup baik untuk kondisi WHERE. Q2 yang sebenarnya berisi gabungan tambahan, dan perencanaannya secara mendasar bergantung pada perkiraan yang baik dari hubungan gabungan. Dalam versi yang lebih lama, pengoptimal tampaknya telah melakukan hal yang benar, tetapi kemudian di 9.3 kami membuatnya lebih pintar dalam beberapa cara, tetapi dengan perkiraan yang buruk itu gagal membuat keputusan yang tepat. Dengan kata lain, rencana bagus di versi lama hanyalah keberuntungan, berkat keterbatasan perencana.
Saya yakin regresi Q18 dan Q20 pada kumpulan data yang lebih kecil juga disebabkan oleh hal serupa, meskipun saya belum menyelidikinya secara mendetail.
Saya yakin beberapa masalah pengoptimal tersebut dapat diperbaiki dengan menyetel parameter biaya (mis. random_page_cost, dll.), tetapi saya belum mencobanya karena kendala waktu. Namun, hal itu menunjukkan bahwa pemutakhiran tidak secara otomatis meningkatkan semua kueri – terkadang pemutakhiran dapat memicu regresi, jadi pengujian yang sesuai untuk aplikasi Anda adalah ide yang bagus.
Paralelisme
Jadi mari kita lihat seberapa besar paralelisme kueri mengubah hasil. Sekali lagi, kita hanya akan melihat hasil dari rilis sejak 9.6 melabeli hasil dengan “(p)” di mana kueri paralel diaktifkan.
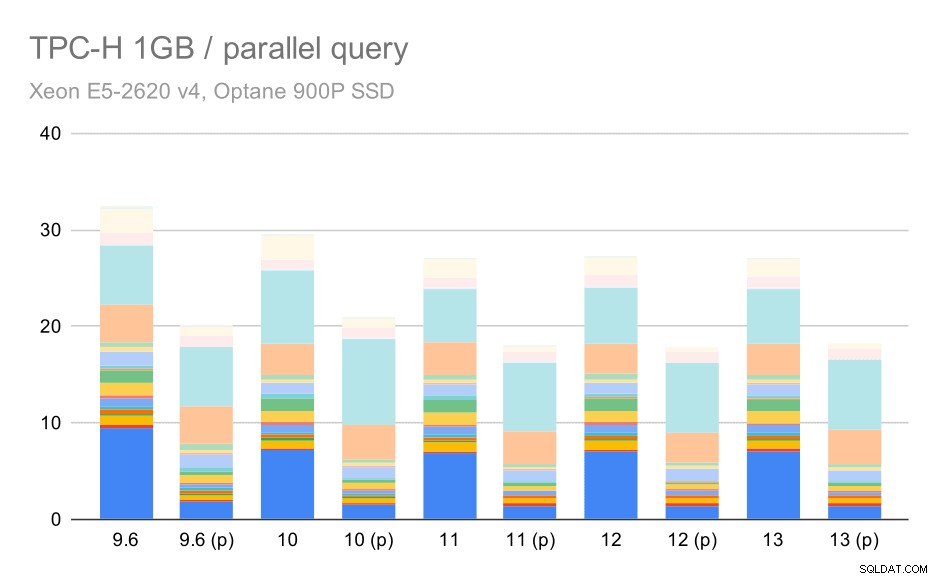
Kueri TPC-H pada kumpulan data kecil (1GB) – paralelisme diaktifkan
Jelas, paralelisme cukup membantu – ini memangkas sekitar 30% bahkan pada kumpulan data kecil ini. Pada kumpulan data menengah, tidak ada banyak perbedaan antara lari reguler dan paralel:
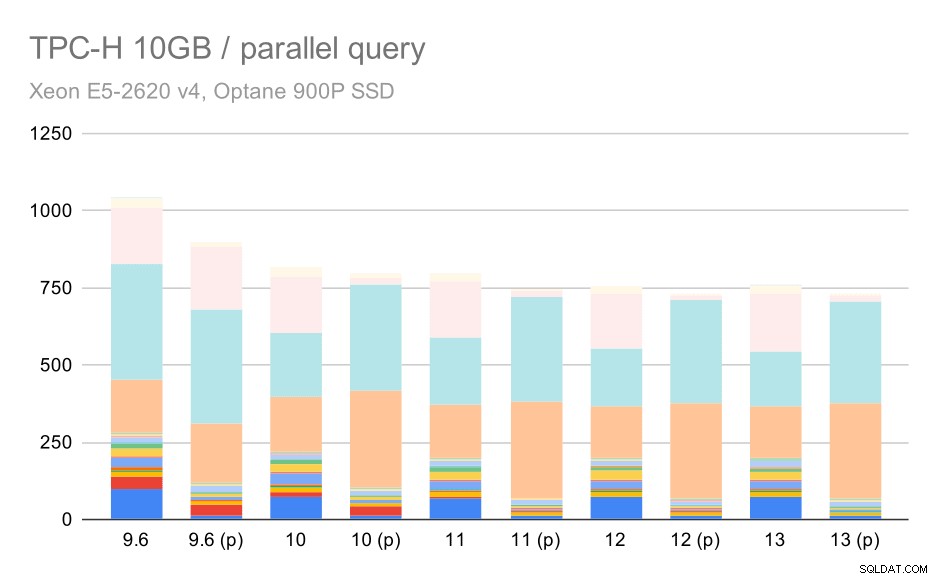
Kueri TPC-H pada kumpulan data sedang (10GB) – paralelisme diaktifkan
Ini adalah demonstrasi lain dari masalah yang sudah dibahas – memungkinkan paralelisme memungkinkan mempertimbangkan rencana kueri tambahan, dan jelas perkiraan atau penetapan biaya tidak sesuai dengan kenyataan, sehingga menghasilkan pilihan rencana yang buruk.
Dan terakhir kumpulan data besar, di mana hasil lengkapnya terlihat seperti ini:
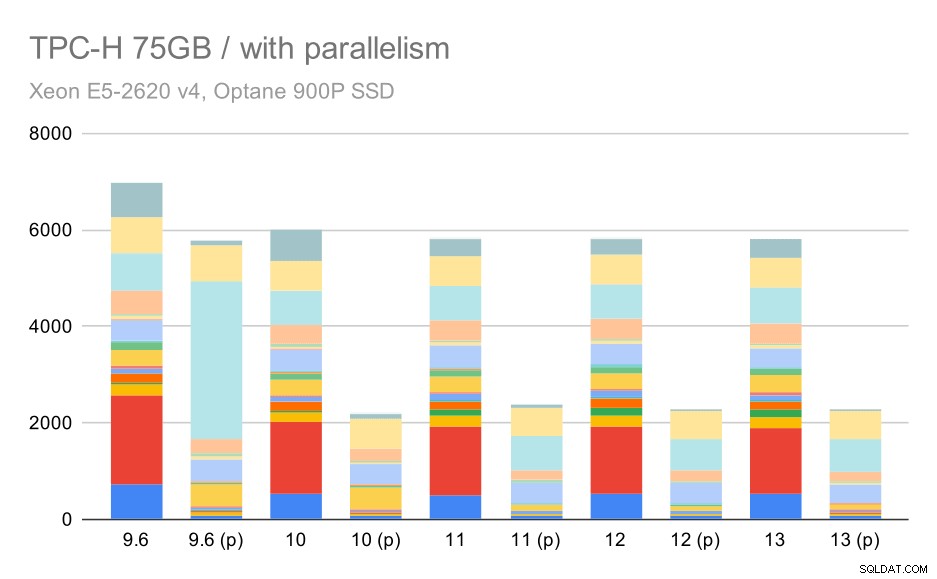
Kueri TPC-H pada kumpulan data besar (75GB) – paralelisme diaktifkan
Di sini mengaktifkan paralelisme berfungsi dalam keuntungan kami – pengoptimal berhasil membangun paket paralel yang lebih murah untuk Q2, mengesampingkan pilihan paket buruk yang diperkenalkan di 9.3. Tapi untuk kelengkapan saja, berikut adalah hasil tanpa Q2.
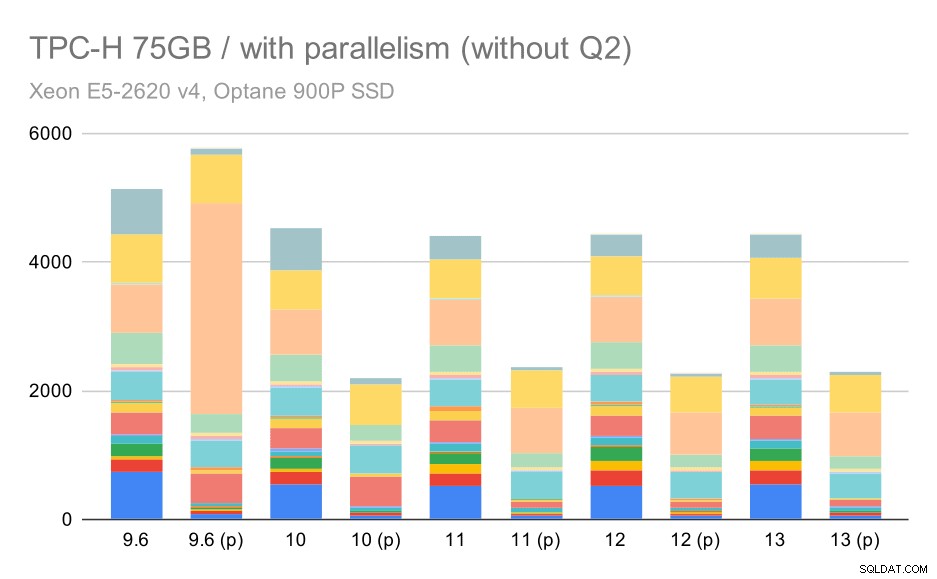
Kueri TPC-H pada kumpulan data besar (75GB) – paralelisme diaktifkan, tanpa masalah Q2
Bahkan di sini Anda dapat melihat beberapa pilihan paket paralel yang buruk – misalnya paket paralel untuk Q9 lebih buruk hingga 11 di mana ia menjadi lebih cepat – kemungkinan berkat 11 node pelaksana paralel tambahan yang mendukung. Di sisi lain, beberapa kueri paralel (Q18, Q20) menjadi lebih lambat pada 11, jadi ini bukan hanya pelangi dan unicorn.
Ringkasan dan Masa Depan
Saya pikir hasil ini dengan baik menunjukkan implementasi pengoptimalan sejak PostgreSQL 8.3. Pengujian dengan paralelisme dinonaktifkan menggambarkan peningkatan efisiensi (yaitu melakukan lebih banyak dengan jumlah sumber daya yang sama) – pemuatan data menjadi ~30% lebih cepat dan kueri menjadi ~2x lebih cepat. Memang benar saya mengalami beberapa masalah dengan rencana kueri yang tidak efisien, tetapi itu adalah risiko yang melekat saat membuat perencana kueri lebih cerdas. Kami terus berupaya membuat hasilnya lebih andal, dan saya yakin saya dapat mengurangi sebagian besar masalah ini dengan sedikit menyesuaikan konfigurasi.
Hasil dengan paralelisme yang diaktifkan menunjukkan bahwa kita dapat memanfaatkan sumber daya ekstra secara efektif (khususnya inti CPU). Pemuatan data tampaknya tidak terlalu diuntungkan – setidaknya tidak dalam tolok ukur ini, tetapi dampak pada eksekusi kueri signifikan, menghasilkan ~2x percepatan (walaupun kueri yang berbeda dipengaruhi secara berbeda, tentu saja).
Ada banyak peluang untuk meningkatkan ini di versi PostgreSQL mendatang. Misalnya ada seri patch yang menerapkan paralelisme untuk COPY, mempercepat pemuatan data. Ada berbagai tambalan yang meningkatkan eksekusi kueri analitik – dari pengoptimalan kecil yang dilokalkan hingga proyek besar seperti penyimpanan dan eksekusi kolumnar, agregat push-down, dll. Banyak yang dapat diperoleh dengan menggunakan partisi deklaratif juga – fitur yang paling sering saya abaikan saat mengerjakan ini benchmark, hanya karena itu akan meningkatkan cakupan terlalu banyak. Dan saya yakin ada banyak peluang lain yang bahkan tidak dapat saya bayangkan, tetapi orang-orang yang lebih pintar di komunitas PostgreSQL sudah mengerjakannya.
Lampiran:Konfigurasi PostgreSQL
Paralelisme dinonaktifkan
Paralelisme diaktifkan