Selamat datang di bagian ketiga – dan terakhir – dari seri blog ini, mengeksplorasi bagaimana kinerja PostgreSQL berkembang selama bertahun-tahun. Bagian pertama melihat beban kerja OLTP, yang diwakili oleh tes pgbench. Bagian kedua melihat kueri analitik / BI, menggunakan subset dari tolok ukur TPC-H tradisional (pada dasarnya sebagian dari uji kekuatan).
Dan bagian terakhir ini melihat pencarian teks lengkap, yaitu kemampuan untuk mengindeks dan mencari data teks dalam jumlah besar. Infrastruktur yang sama (terutama indeks) mungkin berguna untuk mengindeks data semi-terstruktur seperti dokumen JSONB, dll., tetapi bukan itu yang menjadi fokus tolok ukur ini.
Tapi pertama-tama, mari kita lihat riwayat pencarian teks lengkap di PostgreSQL, yang mungkin tampak seperti fitur aneh untuk ditambahkan ke RDBMS, yang biasanya ditujukan untuk menyimpan data terstruktur dalam baris dan kolom.
Riwayat pencarian teks lengkap
Ketika Postgres menjadi open-source pada tahun 1996, Postgres tidak memiliki apa pun yang kami sebut pencarian teks lengkap. Tetapi orang-orang yang mulai menggunakan Postgres ingin melakukan pencarian cerdas dalam dokumen teks, dan kueri LIKE tidak cukup baik. Mereka ingin dapat membuat lemmatisasi istilah menggunakan kamus, mengabaikan kata berhenti, mengurutkan dokumen yang cocok berdasarkan relevansi, menggunakan indeks untuk mengeksekusi kueri tersebut, dan banyak hal lainnya. Hal-hal yang tidak dapat Anda lakukan secara wajar dengan operator SQL tradisional.
Untungnya, beberapa dari orang-orang itu juga pengembang sehingga mereka mulai mengerjakan ini – dan mereka bisa, berkat PostgreSQL yang tersedia sebagai sumber terbuka di seluruh dunia. Ada banyak kontributor untuk pencarian teks lengkap selama bertahun-tahun, tetapi awalnya upaya ini dipimpin oleh Oleg Bartunov dan Teodor Sigaev, ditunjukkan pada foto berikut. Keduanya masih merupakan kontributor utama PostgreSQL, yang mengerjakan pencarian teks lengkap, pengindeksan, dukungan JSON, dan banyak fitur lainnya.

Teodor Sigaev dan Oleg Bartunov
Awalnya, fungsi ini dikembangkan sebagai modul "contrib" eksternal (sekarang kami akan mengatakan itu adalah ekstensi) yang disebut "tsearch", dirilis pada tahun 2002. Kemudian ini sudah usang oleh tsearch2, secara signifikan meningkatkan fitur dalam banyak cara, dan di PostgreSQL 8.3 (dirilis pada 2008) ini sepenuhnya terintegrasi ke dalam inti PostgreSQL (yaitu tanpa perlu menginstal ekstensi sama sekali, meskipun ekstensi masih disediakan untuk kompatibilitas mundur).
Ada banyak peningkatan sejak saat itu (dan pekerjaan berlanjut, mis. untuk mendukung tipe data seperti JSONB, kueri menggunakan jsonpath, dll.). tetapi plugin ini memperkenalkan sebagian besar fungsionalitas teks lengkap yang kami miliki di PostgreSQL sekarang – kamus, pengindeksan teks lengkap dan kemampuan kueri, dll.
Tolok ukur
Tidak seperti tolok ukur OLTP / TPC-H, saya tidak mengetahui tolok ukur teks lengkap apa pun yang dapat dianggap sebagai "standar industri" atau dirancang untuk beberapa sistem basis data. Sebagian besar tolok ukur yang saya ketahui dimaksudkan untuk digunakan dengan satu basis data/produk, dan sulit untuk mem-portingnya secara bermakna, jadi saya harus mengambil rute yang berbeda dan menulis tolok ukur teks lengkap saya sendiri.
Bertahun-tahun yang lalu saya menulis archie – beberapa skrip python yang memungkinkan pengunduhan arsip milis PostgreSQL, dan memuat pesan yang diuraikan ke dalam database PostgreSQL yang kemudian dapat diindeks dan dicari. Cuplikan saat ini dari semua arsip memiliki ~1 juta baris, dan setelah memuatnya ke dalam database, tabelnya berukuran sekitar 9,5 GB (tidak termasuk indeks).
Mengenai kueri, saya mungkin bisa menghasilkan beberapa kueri acak, tapi saya tidak yakin seberapa realistis itu. Untungnya, beberapa tahun yang lalu saya memperoleh sampel 33k pencarian aktual dari situs web PostgreSQL (yaitu hal-hal yang benar-benar dicari orang di arsip komunitas). Sepertinya saya tidak bisa mendapatkan sesuatu yang lebih realistis / representatif.
Kombinasi kedua bagian tersebut (kumpulan data + kueri) sepertinya merupakan tolok ukur yang bagus. Kita cukup memuat data, dan menjalankan pencarian dengan jenis kueri teks lengkap yang berbeda dengan jenis indeks yang berbeda.
Permintaan
Ada berbagai bentuk kueri teks lengkap – kueri dapat dengan mudah memilih semua baris yang cocok, mungkin memberi peringkat pada hasil (mengurutkannya berdasarkan relevansi), mengembalikan hanya sejumlah kecil atau hasil yang paling relevan, dll. Saya memang menjalankan benchmark dengan berbagai jenis kueri, tetapi dalam posting ini saya akan menyajikan hasil untuk dua kueri sederhana yang menurut saya mewakili keseluruhan perilaku dengan cukup baik.
- PILIH id, subjek FROM pesan WHERE body_tsvector @@ $1
- PILIH id, subjek FROM pesan WHERE body_tsvector @@ $1
ORDER BY ts_rank(body_tsvector, $1) DESC LIMIT 100
Kueri pertama hanya mengembalikan semua baris yang cocok, sedangkan yang kedua mengembalikan 100 hasil yang paling relevan (ini adalah sesuatu yang mungkin Anda gunakan untuk penelusuran pengguna).
Saya telah bereksperimen dengan berbagai jenis kueri lainnya, tetapi semuanya pada akhirnya berperilaku dengan cara yang mirip dengan salah satu dari dua jenis kueri ini.
Indeks
Setiap pesan memiliki dua bagian utama yang dapat kita cari – subjek dan isi. Masing-masing memiliki kolom tsvector terpisah, dan diindeks secara terpisah. Subjek pesan jauh lebih pendek daripada isi, sehingga indeks secara alami lebih kecil.
PostgreSQL memiliki dua jenis indeks yang berguna untuk pencarian teks lengkap – GIN dan GiST. Perbedaan utama dijelaskan dalam dokumen, tetapi singkatnya:
- Indeks GIN lebih cepat untuk penelusuran
- Indeks GiST bersifat lossy, yaitu memerlukan pemeriksaan ulang selama penelusuran (dan juga lebih lambat)
Kami dulu mengklaim indeks GiST lebih murah untuk diperbarui (terutama dengan banyak sesi bersamaan), tetapi ini telah dihapus dari dokumentasi beberapa waktu lalu, karena perbaikan dalam kode pengindeksan.
Tolok ukur ini tidak menguji perilaku dengan pembaruan – ia hanya memuat tabel tanpa indeks teks lengkap, membangunnya sekaligus, dan kemudian menjalankan 33 ribu kueri pada data. Itu berarti saya tidak dapat membuat pernyataan apa pun tentang bagaimana jenis indeks tersebut menangani pembaruan bersamaan berdasarkan tolok ukur ini, tetapi saya yakin perubahan dokumentasi mencerminkan berbagai peningkatan GIN terbaru.
Ini juga harus cocok dengan kasus penggunaan arsip milis dengan cukup baik, di mana kami hanya akan menambahkan email baru sesekali (sedikit pembaruan, hampir tidak ada konkurensi penulisan). Tetapi jika aplikasi Anda melakukan banyak pembaruan secara bersamaan, Anda harus membandingkannya sendiri.
Perangkat keras
Saya melakukan benchmark pada dua mesin yang sama seperti sebelumnya, tetapi hasil/kesimpulannya hampir sama, jadi saya hanya akan menyajikan angka dari yang lebih kecil, yaitu
- CPU i5-2500K (4 inti/utas)
- RAM 8 GB
- 6 x 100GB SSD RAID0
- kernel 5.6.15, sistem file ext4
Saya telah menyebutkan sebelumnya bahwa kumpulan data memiliki hampir 10GB saat dimuat, jadi lebih besar dari RAM. Tapi indeksnya masih lebih kecil dari RAM, itulah yang penting untuk benchmark.
Hasil
OK, waktunya untuk beberapa angka dan grafik. Saya akan menyajikan hasil untuk pemuatan data dan kueri, pertama dengan GIN dan kemudian dengan indeks GiST.
GIN / memuat data
Bebannya tidak terlalu menarik, saya pikir. Pertama, sebagian besar (bagian biru) tidak ada hubungannya dengan teks lengkap, karena itu terjadi sebelum dua indeks dibuat. Sebagian besar waktu ini dihabiskan untuk menguraikan pesan, membangun kembali utas email, memelihara daftar balasan, dan sebagainya. Beberapa dari kode ini diimplementasikan dalam pemicu PL/pgSQL, beberapa di antaranya diimplementasikan di luar database. Satu bagian yang berpotensi relevan dengan teks lengkap adalah membangun tsvectors, tetapi tidak mungkin untuk mengisolasi waktu yang dihabiskan untuk itu.
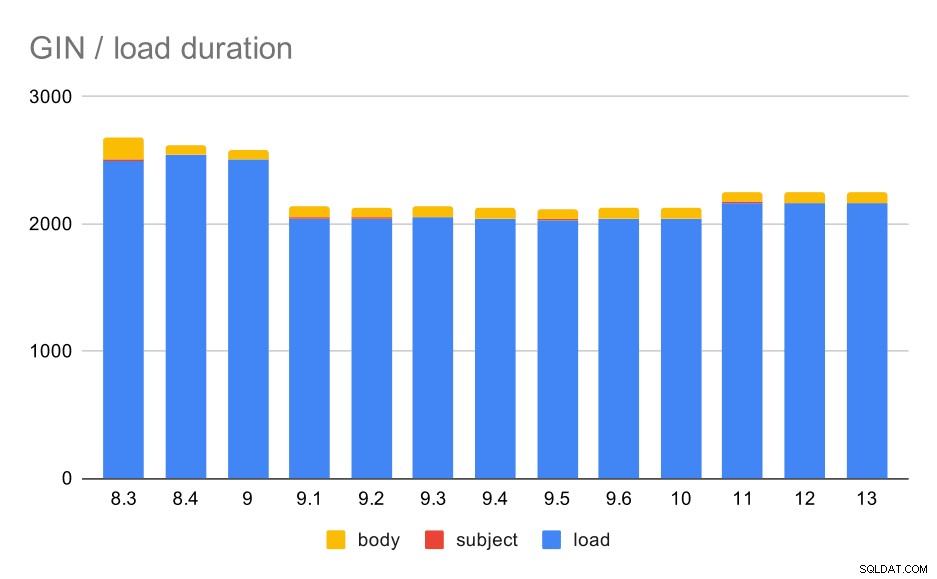
Operasi pemuatan data dengan tabel dan indeks GIN.
Tabel berikut menunjukkan data sumber untuk bagan ini – nilainya adalah durasi dalam detik. LOAD mencakup penguraian arsip mbox (dari skrip Python), memasukkan ke dalam tabel dan berbagai tugas tambahan (membangun kembali utas email, dll.). SUBJECT/BODY INDEX mengacu pada pembuatan indeks GIN teks lengkap pada kolom subject/body setelah data dimuat.
| MUAT | SUBJECT INDEX | BODY INDEX | |
| 8,3 | 2501 | 8 | 173 |
| 8.4 | 2540 | 4 | 78 |
| 9.0 | 2502 | 4 | 75 |
| 9.1 | 2046 | 4 | 84 |
| 9.2 | 2045 | 3 | 85 |
| 9.3 | 2049 | 4 | 85 |
| 9.4 | 2043 | 4 | 85 |
| 9.5 | 2034 | 4 | 82 |
| 9,6 | 2039 | 4 | 81 |
| 10 | 2037 | 4 | 82 |
| 11 | 2169 | 4 | 82 |
| 12 | 2164 | 4 | 79 |
| 13 | 2164 | 4 | 81 |
Jelas, kinerjanya cukup stabil – ada peningkatan yang cukup signifikan (sekitar 20%) antara 9,0 dan 9,1. Saya tidak yakin perubahan mana yang bertanggung jawab atas peningkatan ini – tidak ada apa pun dalam catatan rilis 9.1 yang tampak jelas relevan. Ada juga peningkatan yang jelas dalam membangun indeks GIN di 8,4, yang memangkas waktu sekitar setengahnya. Yang bagus, tentu saja. Yang cukup menarik, saya juga tidak melihat item catatan rilis terkait untuk ini.
Bagaimana dengan ukuran indeks GIN? Ada lebih banyak variabilitas, setidaknya hingga 9,4, di mana ukuran indeks turun dari ~1GB menjadi hanya sekitar 670MB (kira-kira 30%).
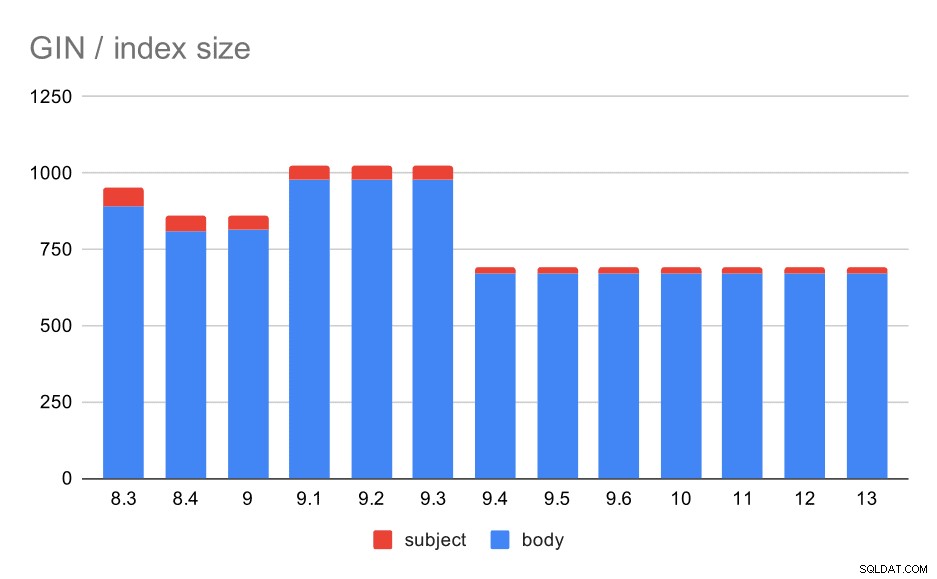
Ukuran indeks GIN pada subjek/isi pesan. Nilainya adalah megabita.
Tabel berikut menunjukkan ukuran indeks GIN pada isi dan subjek pesan. Nilainya dalam megabita.
| BODY | SUBJECT | |
| 8.3 | 890 | 62 |
| 8.4 | 811 | 47 |
| 9.0 | 813 | 47 |
| 9.1 | 977 | 47 |
| 9.2 | 978 | 47 |
| 9.3 | 977 | 47 |
| 9.4 | 671 | 20 |
| 9.5 | 671 | 20 |
| 9,6 | 671 | 20 |
| 10 | 672 | 20 |
| 11 | 672 | 20 |
| 12 | 672 | 20 |
| 13 | 672 | 20 |
Dalam hal ini, saya pikir kita dapat dengan aman berasumsi bahwa percepatan ini terkait dengan item ini dalam catatan rilis 9.4:
- Mengurangi ukuran indeks GIN (Alexander Korotkov, Heikki Linnakangas)
Variabilitas ukuran antara 8,3 dan 9,1 tampaknya disebabkan oleh perubahan lemmatisasi (bagaimana kata-kata ditransformasikan ke bentuk "dasar"). Selain perbedaan ukuran, kueri pada versi tersebut menghasilkan jumlah hasil yang sedikit berbeda, misalnya.
GIN / kueri
Sekarang, bagian utama dari tolok ukur ini – kinerja kueri. Semua angka yang disajikan di sini adalah untuk satu klien – kami telah membahas skalabilitas klien di bagian yang terkait dengan kinerja OLTP, temuan ini juga berlaku untuk kueri ini. (Selain itu, mesin khusus ini hanya memiliki 4 inti, jadi kami tidak akan terlalu jauh dalam hal pengujian skalabilitas.)
PILIH id, subjek FROM pesan WHERE tsvector @@ $1
Pertama, query mencari semua dokumen yang cocok. Untuk pencarian di kolom "subjek" kita bisa melakukan sekitar 800 kueri per detik (dan sebenarnya turun sedikit di 9.1), tetapi di 9.4 tiba-tiba menembak hingga 3000 kueri per detik. Untuk kolom “tubuh” pada dasarnya cerita yang sama – awalnya 160 kueri, turun menjadi ~90 kueri di 9.1, dan kemudian meningkat menjadi 300 di 9.4.
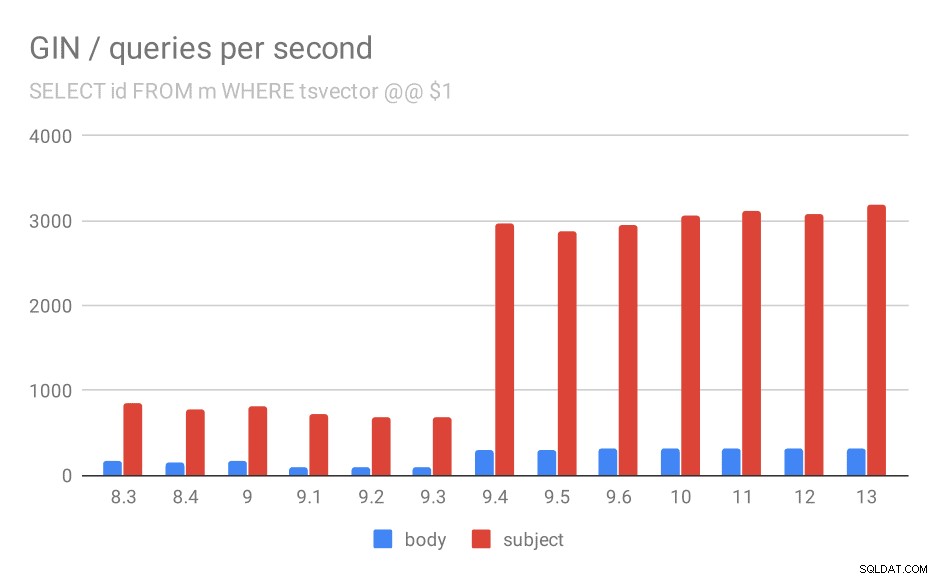
Jumlah kueri per detik untuk kueri pertama (mengambil semua baris yang cocok).
Dan lagi, data sumber – angkanya adalah throughput (kueri per detik).
| BODY | SUBJECT | |
| 8.3 | 168 | 848 |
| 8.4 | 155 | 774 |
| 9.0 | 160 | 816 |
| 9.1 | 93 | 712 |
| 9.2 | 93 | 675 |
| 9.3 | 95 | 692 |
| 9.4 | 303 | 2966 |
| 9.5 | 303 | 2871 |
| 9,6 | 310 | 2942 |
| 10 | 311 | 3066 |
| 11 | 317 | 3121 |
| 12 | 312 | 3085 |
| 13 | 320 | 3192 |
Saya pikir kita dapat dengan aman berasumsi bahwa peningkatan pada 9.4 terkait dengan item ini dalam catatan rilis:
- Meningkatkan kecepatan pencarian GIN multi-kunci (Alexander Korotkov, Heikki Linnakangas)
Jadi, peningkatan 9,4 lainnya dalam GIN dari dua pengembang yang sama – jelas, Alexander dan Heikki melakukan banyak pekerjaan bagus pada indeks GIN dalam rilis 9,4 😉
PILIH id, subjek DARI pesan WHERE tsvector @@ $1
ORDER BY ts_rank(tsvector, $2) DESC LIMIT 100
Untuk kueri yang memeringkat hasil berdasarkan relevansi menggunakan ts_rank dan LIMIT, perilaku keseluruhannya hampir sama persis, saya rasa tidak perlu mendeskripsikan bagan secara detail.
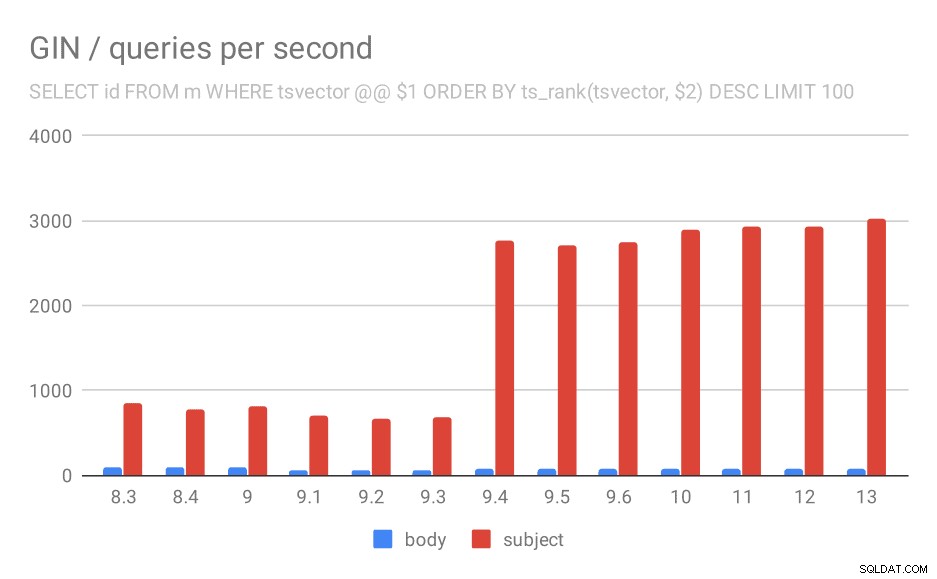
Jumlah kueri per detik untuk kueri kedua (mengambil baris yang paling relevan).
| BODY | SUBJECT | |
| 8.3 | 94 | 840 |
| 8.4 | 98 | 775 |
| 9.0 | 102 | 818 |
| 9.1 | 51 | 704 |
| 9.2 | 51 | 666 |
| 9.3 | 51 | 678 |
| 9.4 | 80 | 2766 |
| 9.5 | 81 | 2704 |
| 9,6 | 78 | 2750 |
| 10 | 78 | 2886 |
| 11 | 79 | 2938 |
| 12 | 78 | 2924 |
| 13 | 77 | 3028 |
Namun, ada satu pertanyaan – mengapa kinerja turun antara 9,0 dan 9,1? Tampaknya ada penurunan throughput yang cukup signifikan – sekitar 50% untuk pencarian isi dan 20% untuk pencarian di subjek pesan. Saya tidak memiliki penjelasan yang jelas tentang apa yang terjadi, tetapi saya memiliki dua pengamatan ...
Pertama, ukuran indeks berubah - jika Anda melihat grafik pertama "GIN / ukuran indeks" dan tabel, Anda akan melihat indeks pada badan pesan tumbuh dari 813MB menjadi sekitar 977MB. Itu peningkatan yang signifikan, dan mungkin menjelaskan beberapa perlambatan. Namun masalahnya adalah indeks pada subjek tidak tumbuh sama sekali, namun kueri juga menjadi lebih lambat.
Kedua, kita dapat melihat berapa banyak hasil yang dikembalikan oleh kueri. Kumpulan data yang diindeks persis sama, jadi tampaknya masuk akal untuk mengharapkan jumlah hasil yang sama di semua versi PostgreSQL, bukan? Nah, dalam praktiknya terlihat seperti ini:
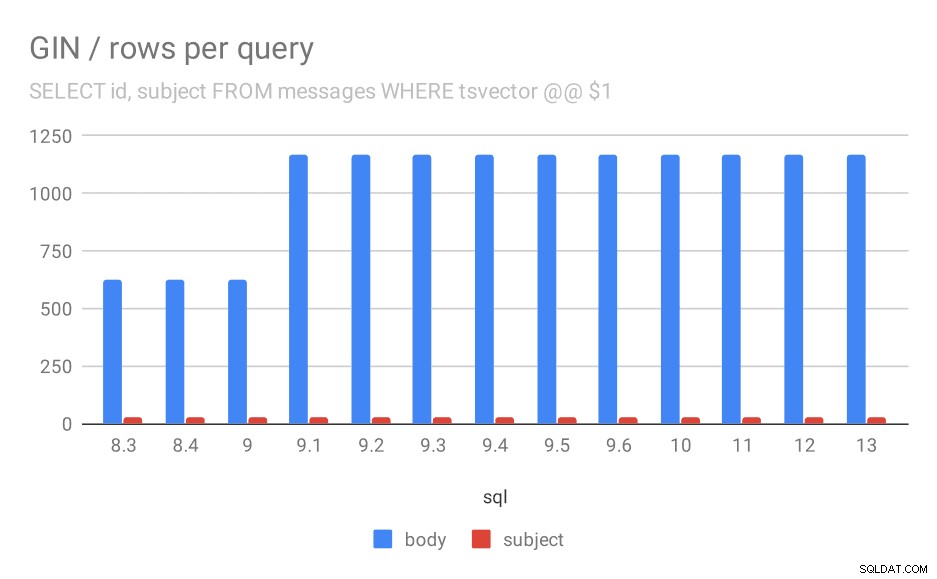
Jumlah baris yang ditampilkan rata-rata untuk kueri.
| BODY | SUBJECT | |
| 8.3 | 624 | 26 |
| 8.4 | 624 | 26 |
| 9.0 | 622 | 26 |
| 9.1 | 1165 | 26 |
| 9.2 | 1165 | 26 |
| 9.3 | 1165 | 26 |
| 9.4 | 1165 | 26 |
| 9.5 | 1165 | 26 |
| 9,6 | 1165 | 26 |
| 10 | 1165 | 26 |
| 11 | 1165 | 26 |
| 12 | 1165 | 26 |
| 13 | 1165 | 26 |
Jelas, pada 9.1 jumlah rata-rata hasil pencarian di badan pesan tiba-tiba berlipat ganda, yang hampir sebanding dengan pelambatan. Namun jumlah hasil untuk pencarian subjek tetap sama. Saya tidak memiliki penjelasan yang sangat bagus untuk ini, kecuali bahwa pengindeksan berubah dengan cara yang memungkinkan pencocokan lebih banyak pesan, tetapi membuatnya sedikit lebih lambat. Jika Anda memiliki penjelasan yang lebih baik, saya ingin mendengarnya!
GiST / pemuatan data
Sekarang, jenis lain dari indeks teks lengkap – GiST. Indeks ini lossy, yaitu memerlukan pemeriksaan ulang hasil menggunakan nilai dari tabel. Jadi kita dapat mengharapkan throughput yang lebih rendah dibandingkan dengan indeks GIN, tetapi sebaliknya, masuk akal untuk mengharapkan pola yang kurang lebih sama.
Waktu muat memang cocok dengan GIN hampir sempurna – waktu pembuatan indeks berbeda, tetapi pola keseluruhannya sama. Percepatan di 9.1, pelambatan kecil di 11.
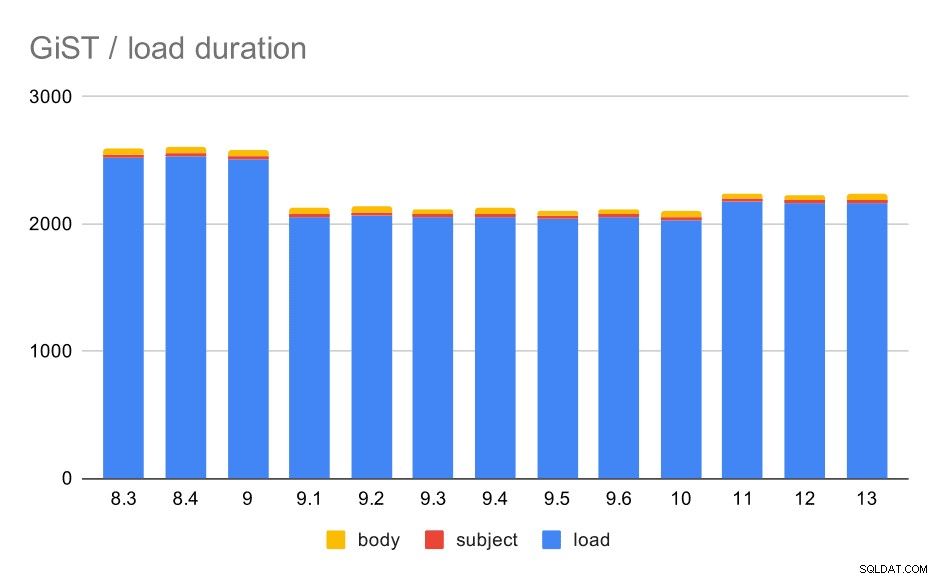
Operasi pemuatan data dengan tabel dan indeks GiST.
| MUAT | SUBJECT | BODY | |
| 8.3 | 2522 | 23 | 47 |
| 8.4 | 2527 | 23 | 49 |
| 9.0 | 2511 | 23 | 45 |
| 9.1 | 2054 | 22 | 46 |
| 9.2 | 2067 | 22 | 47 |
| 9.3 | 2049 | 23 | 46 |
| 9.4 | 2055 | 23 | 47 |
| 9.5 | 2038 | 22 | 45 |
| 9,6 | 2052 | 22 | 44 |
| 10 | 2029 | 22 | 49 |
| 11 | 2174 | 22 | 46 |
| 12 | 2162 | 22 | 46 |
| 13 | 2170 | 22 | 44 |
Namun ukuran indeks tetap hampir konstan – tidak ada peningkatan GiST yang serupa dengan GIN di 9.4, yang mengurangi ukuran hingga ~30%. Ada peningkatan di 9.1, yang merupakan tanda lain bahwa pengindeksan teks lengkap berubah dalam versi itu untuk mengindeks lebih banyak kata.
Hal ini selanjutnya didukung oleh jumlah rata-rata hasil dengan GiST yang persis sama dengan GIN (dengan peningkatan sebesar 9,1).
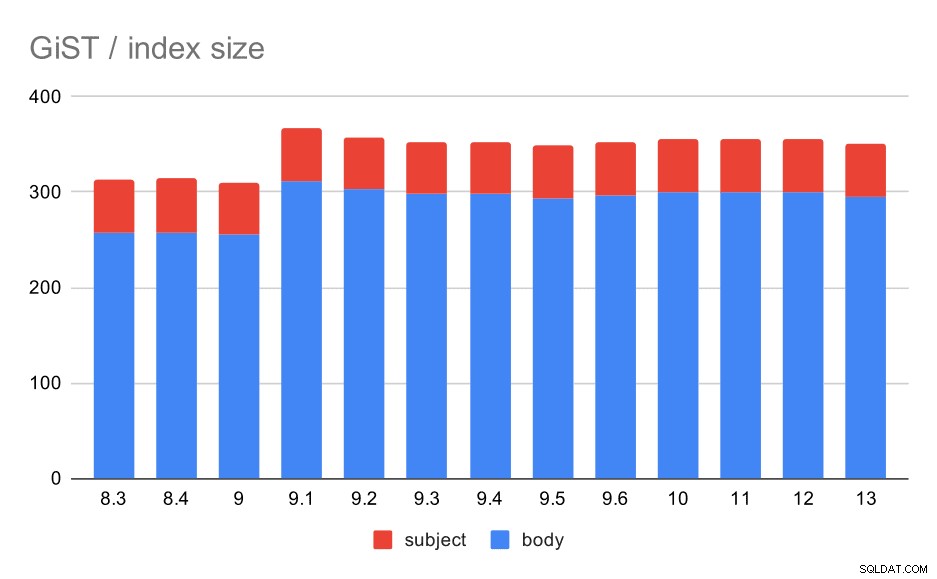
Ukuran indeks GiST pada subjek/isi pesan. Nilainya adalah megabita.
| BODY | SUBJECT | |
| 8.3 | 257 | 56 |
| 8.4 | 258 | 56 |
| 9.0 | 255 | 55 |
| 9.1 | 312 | 55 |
| 9.2 | 303 | 55 |
| 9.3 | 298 | 55 |
| 9.4 | 298 | 55 |
| 9.5 | 294 | 55 |
| 9.6 | 297 | 55 |
| 10 | 300 | 55 |
| 11 | 300 | 55 |
| 12 | 300 | 55 |
| 13 | 295 | 55 |
GiST / queries
Unfortunately, for the queries the results are nowhere as good as for GIN, where the throughput more than tripled in 9.4. With GiST indexes, we actually observe continuous degradation over the time.
SELECT id, subject FROM messages WHERE tsvector @@ $1
Even if we ignore versions before 9.1 (due to the indexes being smaller and returning fewer results faster), the throughput drops from ~270 to ~200 queries per second, with the main drop between 9.2 and 9.3.
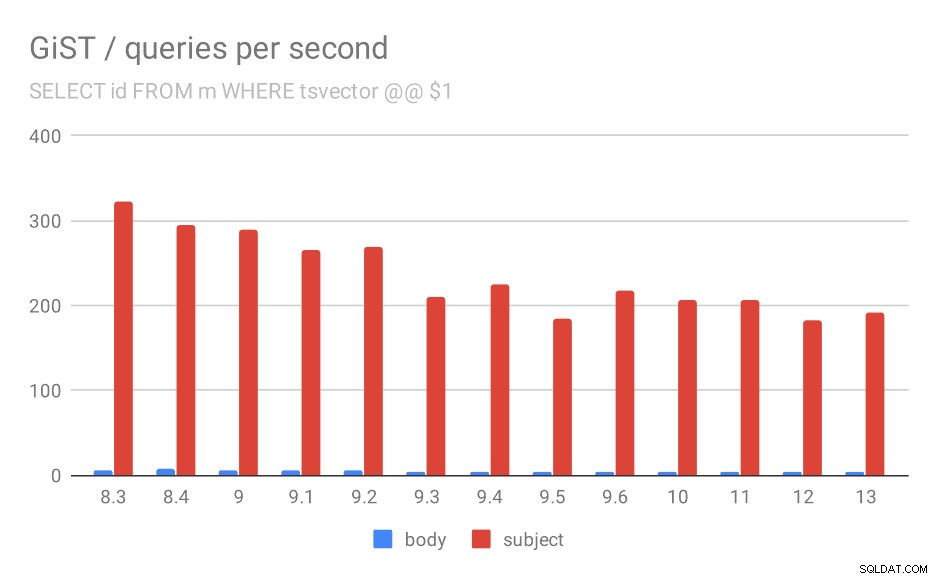
Number of queries per second for the first query (fetching all matching rows).
| BODY | SUBJECT | |
| 8.3 | 5 | 322 |
| 8.4 | 7 | 295 |
| 9.0 | 6 | 290 |
| 9.1 | 5 | 265 |
| 9.2 | 5 | 269 |
| 9.3 | 4 | 211 |
| 9.4 | 4 | 225 |
| 9.5 | 4 | 185 |
| 9.6 | 4 | 217 |
| 10 | 4 | 206 |
| 11 | 4 | 206 |
| 12 | 4 | 183 |
| 13 | 4 | 191 |
SELECT id, subject FROM messages WHERE tsvector @@ $1
ORDER BY ts_rank(tsvector, $2) DESC LIMIT 100
And for queries with ts_rank the behavior is almost exactly the same.
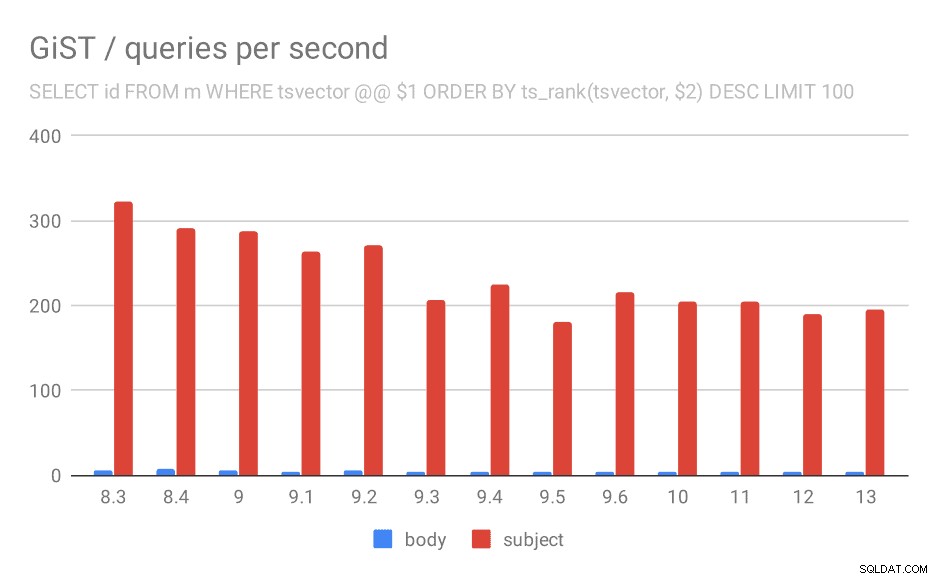
Number of queries per second for the second query (fetching the most relevant rows).
| BODY | SUBJECT | |
| 8.3 | 5 | 323 |
| 8.4 | 7 | 291 |
| 9.0 | 6 | 288 |
| 9.1 | 4 | 264 |
| 9.2 | 5 | 270 |
| 9.3 | 4 | 207 |
| 9.4 | 4 | 224 |
| 9.5 | 4 | 181 |
| 9.6 | 4 | 216 |
| 10 | 4 | 205 |
| 11 | 4 | 205 |
| 12 | 4 | 189 |
| 13 | 4 | 195 |
I’m not entirely sure what’s causing this, but it seems like a potentially serious regression sometime in the past, and it might be interesting to know what exactly changed.
It’s true no one complained about this until now – possibly thanks to upgrading to a faster hardware which masked the impact, or maybe because if you really care about speed of the searches you will prefer GIN indexes anyway.
But we can also see this as an optimization opportunity – if we identify what caused the regression and we manage to undo that, it might mean ~30% speedup for GiST indexes.
Summary and future
By now I’ve (hopefully) convinced you there were many significant improvements since PostgreSQL 8.3 (and in 9.4 in particular). I don’t know how much faster can this be made, but I hope we’ll investigate at least some of the regressions in GiST (even if performance-sensitive systems are likely using GIN). Oleg and Teodor and their colleagues were working on more powerful variants of the GIN indexing, named VODKA and RUM (I kinda see a naming pattern here!), and this will probably help at least some query types.
I do however expect to see features buil extending the existing full-text capabilities – either to better support new query types (e.g. the new index types are designed to speed up phrase search), data types and things introduced by recent revisions of the SQL standard (like jsonpath).