Metrik apa dari penerapan PostgreSQL Anda yang harus Anda pantau? Serangkaian entri blog ini bertujuan untuk menyediakan serangkaian tindakan pemantauan penting awal yang harus Anda terapkan untuk memastikan kesehatan dan stabilitas server Postgres Anda.
Bagian pertama mencakup parameter tingkat cluster.
Bagian 1:Tingkat Cluster
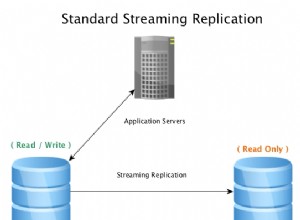
Dalam jargon Postgres, sebuah cluster adalah kumpulan database yang dikelola oleh instance server singlePostgres. Fitur seperti replikasi dan pengarsipan WAL bekerja di tingkat cluster.
1. Rentang ID Transaksi
Dari perspektif klien normal, file data dari cluster PostgreSQL akan tampak berisi snapshot data yang dimodifikasi oleh transaksi yang dilakukan terakhir. Namun, karena arsitektur MVCC Postgres, file fisik tidak hanya berisi data untuk transaksi terbaru, tetapi untuk berbagai transaksi yang diakhiri dengan transaksi terbaru. (menyedot debu biasa menghilangkan data untuk transaksi lama.)
Setiap transaksi memiliki pengidentifikasi integer 32-bit yang unik, yang disebutID transaksi . Karena berbagai alasan, perbedaan ID transaksi pertama dan terakhir harus kurang dari 2, yaitu sekitar 2 miliar. Menjaga kisaran jauh di bawah batas ini adalah harus – baca kisah nyata tentang apa yang terjadi sebaliknya.
Tindakan:Pantau terus rentang ID transaksi, beri tahu jika nilainya melebihi ambang batas yang ditetapkan.
Cara:
-- returns the first and last transactions IDs for the cluster
SELECT oldest_xid::text::int as first,
regexp_replace(next_xid, '^[0-9]+:', '')::int-1 as last
FROM pg_control_checkpoint();
-- returns the transaction ID range for each database
SELECT datname, age(datfrozenxid)
FROM pg_database;2. Jumlah Backend
Setiap backend mewakili klien yang terhubung ke server, atau proses backend sistem (seperti pekerja vakum otomatis, penulis latar belakang, dll). Setiap backend juga merupakan proses OS yang menghabiskan sumber daya OS seperti memori, membuka deskriptor file, dll. Terlalu banyak backend, biasanya karena terlalu banyak klien atau terlalu banyak kueri yang berjalan lama dapat memberi tekanan pada sumber daya OS dan memperlambat waktu respons kueri untuk setiap klien.
Tindakan:Pantau jumlah backend maksimum setiap hari/minggu, selidiki tren yang meningkat.
Cara:
-- returns the count of currently running backends
SELECT count(*)
FROM pg_stat_activity;3. Slot Replikasi Tidak Aktif
Slot replikasi ditandai sebagai 'tidak aktif' saat klien replikasi yang terhubung ke slot terputus. Slot replikasi yang tidak aktif menyebabkan file WAL dipertahankan, karena harus dikirim ke klien saat terhubung kembali dan slot menjadi aktif. Memang, hal pertama untuk memeriksa apakah jumlah file WAL Anda tidak turun adalah untuk melihat apakah Anda memiliki slot replikasi yang tidak aktif.
Seringkali slot replikasi yang tidak aktif adalah hasil dari klien cadangan yang dihapus, slave yang dihapus, promosi, failover, dan sejenisnya.
Tindakan:Terus periksa slot replikasi yang tidak aktif, beri tahu jika ada.
Cara:
-- returns the count of inactive replication slots
SELECT count(*)
FROM pg_replication_slots
WHERE NOT active;4. Backend Menunggu di Kunci
Pernyataan SQL dapat secara eksplisit atau implisit menyebabkan pernyataan SQL lain menunggu. Misalnya, menjalankan "SELECT .. FOR UPDATE" secara eksplisit mendeklarasikan kunci untuk baris yang dipilih ini, dan menjalankan "UPDATE" menempatkan kunci eksklusif baris implisit. Pernyataan SQL lainnya saat menemukan kunci harus menunggu sampai pernyataan pertama melepaskan kunci, sebelum melanjutkan eksekusinya.
Hal ini dapat bermanifestasi sebagai kinerja aplikasi yang lambat selama laporan mingguan berjalan, waktu transaksi/halaman web habis, dan sejenisnya.
Meskipun sejumlah penguncian tidak dapat dihindari, tren peningkatan backend yang menunggu penguncian biasanya memerlukan kueri atau logika aplikasi untuk direstrukturisasi.
Tindakan:Pantau jumlah maksimum backend yang menunggu penguncian setiap hari/minggu, selidiki tren yang meningkat.
Cara:
-- returns the count of backends waiting on locks
SELECT count(*)
FROM pg_stat_activity
WHERE wait_event = 'Lock';5. Backend Idling dalam Transaksi
Transaksi yang berjalan lama tidak terlalu bagus untuk dilakukan di dunia PostgreSQL. Transaksi tersebut dapat menyebabkan file WAL menumpuk, mencegah autovacuum dan vakum manual, dan menghabiskan sumber daya. Tidak banyak yang dapat dilakukan tentang transaksi asli yang membutuhkan waktu lama untuk diselesaikan, tetapi ada kasus seperti aplikasi/skrip yang salah dan klien psql sesekali yang memulai transaksi tetapi tidak menutupnya. Backend yang melayani klien seperti itu muncul sebagai “idling in transaction”.
Backend yang menganggur dalam transaksi harus dideteksi dan dimatikan sebelum mulai memengaruhi stabilitas sistem.
Tindakan:Pantau terus jumlah backend yang menganggur dalam transaksi, tinjau jika ada.
Cara:
-- returns the count of backends waiting on locks
SELECT count(*)
FROM pg_stat_activity
WHERE state = 'idle in transaction';6. Replikasi Lag untuk Koneksi Aktif
Ketika ada klien replikasi streaming aktif (seperti hot standbys) atau klien replikasi logis aktif, Postgres menjalankan backend sistem yang disebutpengirim WAL untuk setiap klien aktif (terhubung). Pengirim WAL bertanggung jawab untuk mengirimkan data catatan WAL yang dibutuhkan klien.
Klien replikasi biasanya mencoba untuk mengikuti sebanyak mungkin dengan yang utama. Namun, kadang-kadang, tingkat pembangkitan WAL di sisi utama dapat menjadi lebih tinggi daripada tingkat di mana klien dapat mengkonsumsinya. Ini mengakibatkan replikasi lag untuk setiap koneksi replikasi.
PostgreSQL menyediakan mekanisme query untuk menulis lag (jumlah byte yang dikirim tetapi tidak ditulis ke disk klien), flush lag (jumlah byte yang ditulis tetapi tidak di-flush ke disk klien) dan replay lag (jumlah byte yang dihapus tetapi tidak diputar ulang ke dalam disk klien file database) untuk setiap pengirim WAL yang aktif.
Tindakan:Terus pantau kelambatan replikasi untuk koneksi aktif, beri tahu jika nilainya melebihi ambang batas yang ditetapkan.
Cara:
-- returns the write, flush and replay lags per WAL sender, as described above
SELECT write_lsn - sent_lsn AS write_lag,
flush_lsn - write_lsn AS flush_lag,
replay_lsn - flush_lsn AS replay_lag
FROM pg_stat_replication;7. Keterlambatan Replikasi untuk Slot Replikasi
Tidak hanya klien duplikat dapat lag, mereka juga bisa hilang sama sekali karena crash, perubahan topologi atau kesalahan manusia. Mungkin juga dengan desain, di mana klien tidak selalu online.
Jika klien didukung oleh slot replikasi, maka semua file WAL yang diperlukan klien untuk melanjutkan dari titik yang ditinggalkannya akan disimpan oleh PostgreSQL. File WAL akan disimpan tanpa batas waktu – tidak ada cara untuk menetapkan batas. Ketika klien terhubung kembali, semua data yang disimpan harus dialirkan ke klien terlebih dahulu, yang dapat melibatkan banyak lalu lintas disk dan jaringan di primer. Untuk alasan ini, Anda juga harus memantau kelambatan di level slot.
(Catatan:Proses pengirim WAL hanya berjalan ketika klien terhubung, dan keluar saat klien terputus. Metode pengirim WAL untuk mengukur seberapa jauh di belakang klien tidak berfungsi saat klien terputus.)
Tindakan:Terus pantau jeda replikasi untuk slot replikasi logis, beri tahu jika nilainya melebihi ambang batas yang ditetapkan.
Cara:
-- returns the replication slot lag in bytes
-- (works only for logical replication slots)
SELECT pg_current_wal_lsn() - confirmed_flush_lsn
FROM pg_replication_slots;8. Jumlah File WAL
Mengelola file WAL bisa menjadi tugas yang menjengkelkan, terutama jika Anda memiliki pengarsipan WAL atau klien replikasi streaming. Jumlah file WAL dapat mulai meningkat tanpa alasan yang jelas, proses pengarsipan WAL dapat gagal mengikuti laju pembuatan WAL, dan total ukuran file WAL dapat mencapai terabyte.
Minimal, Anda perlu memantau jumlah file WAL yang ada di direktori basis data Anda dan memastikan jumlahnya sesuai untuk penerapan Anda.
Tindakan:Pantau terus jumlah file WAL, beri tahu jika nilainya melebihi ambang batas yang ditetapkan.
Cara:
-- returns the number of WAL files present in the pg_wal directory (v10+)
SELECT count(*)
FROM pg_ls_waldir();
-- same, for v9.x
SELECT count(*)
FROM pg_ls_dir('pg_xlog')
WHERE pg_ls_dir ~ '^[0-9A-F]{24}$';
-- can also count the files physically present in $DBDIR/pg_wal
-- /bin/ls -l $DBDIR/pg_wal | grep -c '^-'9. Jumlah file WAL yang siap diarsipkan
Saat pengarsipan WAL diaktifkan, PostgreSQL memanggil skrip pengguna setiap kali file WAL baru dibuat. Script seharusnya "mengarsipkan" file WAL tunggal yang dipanggil (biasanya menyalinnya ke server lain atau ember S3). Jika skrip terlalu lama untuk melakukan tugasnya, atau jika gagal, kumpulan file WAL ke diarsipkan menumpuk.
Tindakan:Pantau terus jumlah file WAL yang siap diarsipkan, beri tahu jika nilainya melebihi ambang batas yang ditetapkan.
Cara:
-- returns the number of WAL files ready to be archived (v12+)
SELECT count(*)
FROM pg_ls_archive_statusdir()
WHERE name ~ '^[0-9A-F]{24}.ready$';
-- same, for v10+
SELECT count(*)
FROM pg_ls_dir('pg_wal/archive_status')
WHERE pg_ls_dir ~ '^[0-9A-F]{24}.ready$';
-- same, for v9.x
SELECT count(*)
FROM pg_ls_dir('pg_xlog/archive_status')
WHERE pg_ls_dir ~ '^[0-9A-F]{24}.ready$';
-- can also count the *.ready files physically present in $DBDIR/pg_wal/archive_status
-- /bin/ls -l $DBDIR/pg_wal/archive_status | grep -c .readyMengumpulkan Metrik Ini
Bagian di atas menyediakan pernyataan SQL untuk mengekstrak metrik yang diperlukan dari server Postgres yang sedang berjalan. Jika Anda lebih suka tidak menulis skrip sendiri, lihat pgmetrics alat sumber terbuka. Itu dapat mengumpulkan metrik di atas, dan banyak lagi, dan melaporkannya dalam format teks dan JSON.
Anda dapat langsung mengirim laporan pgmetrics ke penawaran komersial kami, pgDash, yang menyimpan dan memproses laporan ini untuk menampilkan grafik dan melakukan peringatan.
Selanjutnya
Bagian selanjutnya dalam seri ini akan mencakup metrik tingkat basis data, tingkat tabel, tingkat indeks, dan tingkat sistem. Tetap disini!