Dengan Pemulihan Bencana, kami bertujuan untuk menyiapkan sistem untuk menangani apa pun yang bisa salah dengan database kami. Apa yang terjadi jika database crash? Bagaimana jika pengembang secara tidak sengaja memotong tabel? Bagaimana jika kami mengetahui beberapa data telah dihapus minggu lalu tetapi kami tidak menyadarinya sampai hari ini? Hal-hal ini terjadi, dan memiliki rencana dan sistem yang solid akan membuat DBA terlihat seperti pahlawan ketika hati semua orang telah berhenti ketika bencana muncul.
Basis data apa pun yang memiliki nilai apa pun harus memiliki cara untuk mengimplementasikan satu atau lebih opsi Pemulihan Bencana. PostgreSQL memiliki sistem replikasi yang sangat solid, dan cukup fleksibel untuk diatur dalam banyak konfigurasi untuk membantu Pemulihan Bencana, jika terjadi kesalahan. Kami akan fokus pada skenario seperti yang ditanyakan di atas, cara menyiapkan opsi Pemulihan Bencana, dan manfaat dari setiap solusi.
Ketersediaan Tinggi
Dengan replikasi streaming di PostgreSQL, Ketersediaan Tinggi mudah disiapkan dan dipelihara. Tujuannya adalah untuk menyediakan situs failover yang dapat dipromosikan menjadi master jika database utama mati karena alasan apa pun, seperti kegagalan perangkat keras, kegagalan perangkat lunak, atau bahkan pemadaman jaringan. Menghosting replika di host lain memang bagus, tetapi menghostingnya di pusat data lain jauh lebih baik.
Untuk spesifik menyiapkan replikasi streaming, Somenines memiliki detail mendalam yang tersedia di sini. Dokumentasi Replikasi Streaming PostgreSQL resmi memiliki informasi mendetail tentang protokol replikasi streaming dan cara kerjanya.
Pengaturan standar akan terlihat seperti ini, database master menerima koneksi baca / tulis, dengan database replika yang menerima semua aktivitas WAL hampir secara real-time, memutar ulang semua aktivitas perubahan data secara lokal.
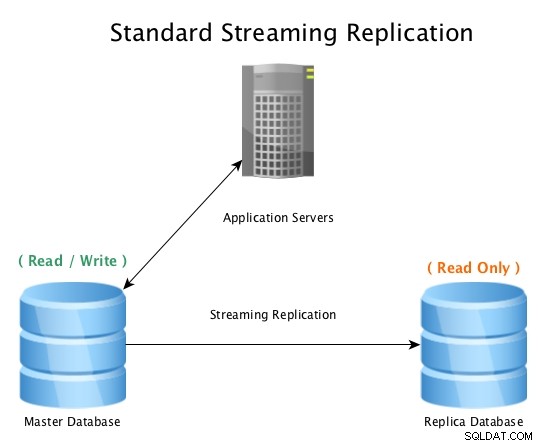 Replikasi Streaming Standar dengan PostgreSQL
Replikasi Streaming Standar dengan PostgreSQL Ketika database master menjadi tidak dapat digunakan, prosedur failover dimulai untuk membuatnya offline, dan mempromosikan database replika ke master, lalu mengarahkan semua koneksi ke host yang baru dipromosikan. Ini dapat dilakukan dengan mengonfigurasi ulang penyeimbang beban, konfigurasi aplikasi, alias IP, atau cara cerdas lainnya untuk mengalihkan lalu lintas.
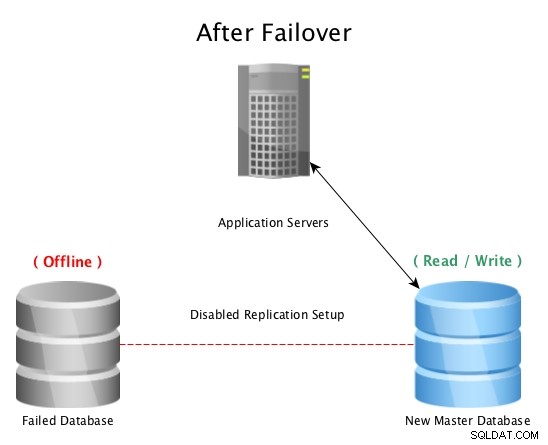 Setelah failover dengan Replikasi Streaming PostgreSQL
Setelah failover dengan Replikasi Streaming PostgreSQL Ketika bencana melanda database master (seperti kegagalan hard drive, pemadaman listrik, atau apa pun yang mencegah master bekerja sebagaimana dimaksud), gagal ke siaga panas adalah cara tercepat untuk tetap online melayani permintaan ke aplikasi atau pelanggan tanpa serius waktu henti. Perlombaan kemudian dilanjutkan untuk memperbaiki host basis data yang gagal, atau membawa replika baru secara online untuk menjaga jaring pengaman agar siaga siap digunakan. Memiliki beberapa standby akan memastikan bahwa jendela setelah kegagalan bencana juga siap untuk kegagalan sekunder, betapapun kecil kemungkinannya.
Catatan:Saat gagal beralih ke replika streaming, replika ini akan melanjutkan dari tempat yang ditinggalkan master sebelumnya, jadi ini membantu menjaga database tetap online, tetapi tidak memulihkan data yang hilang secara tidak sengaja.
Pemulihan Titik Dalam Waktu
Pilihan Disaster Recovery lainnya adalah Point in Time Recovery (PITR). Dengan PITR, salinan database dapat dikembalikan kapan saja kita inginkan, selama kita memiliki cadangan dasar dari sebelum waktu itu, dan semua segmen WAL diperlukan hingga saat itu.
Opsi Pemulihan Point In Time tidak secepat online seperti Hot Standby, namun manfaat utamanya adalah dapat memulihkan snapshot basis data sebelum peristiwa besar seperti tabel yang dihapus, data buruk yang dimasukkan, atau bahkan kerusakan data yang tidak dapat dijelaskan . Apa pun yang akan menghancurkan data sedemikian rupa di mana kita ingin mendapatkan salinannya sebelum penghancuran itu, PITR menyelamatkannya.
Point in Time Recovery bekerja dengan membuat snapshot database secara berkala, biasanya dengan menggunakan program pg_basebackup, dan menyimpan salinan arsip dari semua file WAL yang dihasilkan oleh master
Pengaturan Pemulihan Titik Dalam Waktu
Penyetelan memerlukan beberapa opsi konfigurasi yang disetel pada master, beberapa di antaranya baik untuk digunakan dengan nilai default pada versi terbaru saat ini, PostgreSQL 11. Dalam contoh ini, kita akan menyalin file 16MB langsung ke host PITR jarak jauh menggunakan rsync , dan mengompresinya di sisi lain dengan tugas cron.
Pengarsipan WAL
Kuasai postgresql.conf
wal_level = replica
archive_mode = on
archive_command = 'rsync -av -z %p example@sqldat.com:/mnt/db/wal_archive/%f'CATATAN: Pengaturan archive_command dapat berupa banyak hal, tujuan keseluruhannya adalah mengirim semua file WAL yang diarsipkan ke host lain untuk tujuan keamanan. Jika kita kehilangan file WAL, PITR melewati file WAL yang hilang menjadi tidak mungkin. Biarkan kreativitas pemrograman Anda menjadi gila, tetapi pastikan itu dapat diandalkan.
[Opsional] Kompres file WAL yang diarsipkan:
Setiap pengaturan akan sedikit berbeda, tetapi kecuali jika database yang bersangkutan sangat ringan dalam pembaruan data, penumpukan file 16MB akan mengisi ruang drive dengan cukup cepat. Skrip kompresi yang mudah, disiapkan melalui cron, dapat terlihat seperti di bawah ini.
kompres_WAL_archive.sh:
#!/bin/bash
# Compress any WAL files found that are not yet compressed
gzip /mnt/db/wal_archive/*[0-F]CATATAN: Selama metode pemulihan apa pun, file terkompresi apa pun perlu didekompresi nanti. Beberapa administrator memilih untuk hanya mengompresi file setelah mereka berumur X hari, menjaga ruang keseluruhan tetap rendah, tetapi juga menjaga file WAL yang lebih baru siap untuk pemulihan tanpa kerja ekstra. Pilih opsi terbaik untuk database yang dimaksud guna memaksimalkan kecepatan pemulihan Anda.
Cadangan Dasar
Salah satu komponen kunci untuk cadangan PITR adalah cadangan dasar, dan frekuensi pencadangan dasar. Ini bisa per jam, harian, mingguan, bulanan, tetapi memilih opsi terbaik berdasarkan kebutuhan pemulihan serta lalu lintas churn data database. Jika kami memiliki cadangan mingguan setiap hari Minggu, dan kami perlu memulihkan hingga Sabtu sore, maka kami menghadirkan cadangan dasar hari Minggu sebelumnya secara online dengan semua file WAL antara cadangan itu dan Sabtu sore. Jika proses pemulihan ini membutuhkan waktu 10 jam untuk diproses, kemungkinan ini terlalu lama, Pencadangan basis harian akan mengurangi waktu pemulihan itu, karena pencadangan basis akan dimulai dari pagi itu, tetapi juga meningkatkan jumlah pekerjaan pada host untuk pencadangan dasar sendiri.
Jika pemulihan file WAL selama seminggu hanya membutuhkan beberapa menit, karena basis data melihat churn rendah, maka pencadangan mingguan tidak masalah. Data yang sama pada akhirnya akan ada, tetapi seberapa cepat Anda dapat mengaksesnya adalah kuncinya.
Dalam contoh kami, kami akan menyiapkan cadangan basis mingguan, dan karena kami menggunakan Replikasi Streaming untuk Ketersediaan Tinggi, serta mengurangi beban pada master, kami akan membuat cadangan dasar dari database replika.
base_backup.sh:
#!/bin/bash
backup_dir="$(date +'%Y-%m-%d')_backup"
cd /mnt/db/backups
mkdir $backup_dir
pg_basebackup -h <replica host> -p <replica port> -U replication -D $backup_dir -Ft -zCATATAN: Perintah pg_basebackup mengasumsikan host ini diatur untuk akses tanpa kata sandi untuk 'replikasi' pengguna pada master, yang dapat dilakukan baik dengan 'percaya' di pg_hba untuk host cadangan PITR ini, kata sandi di file .pgpass, atau cara lain yang lebih aman . Perhatikan keamanan saat menyiapkan pencadangan.
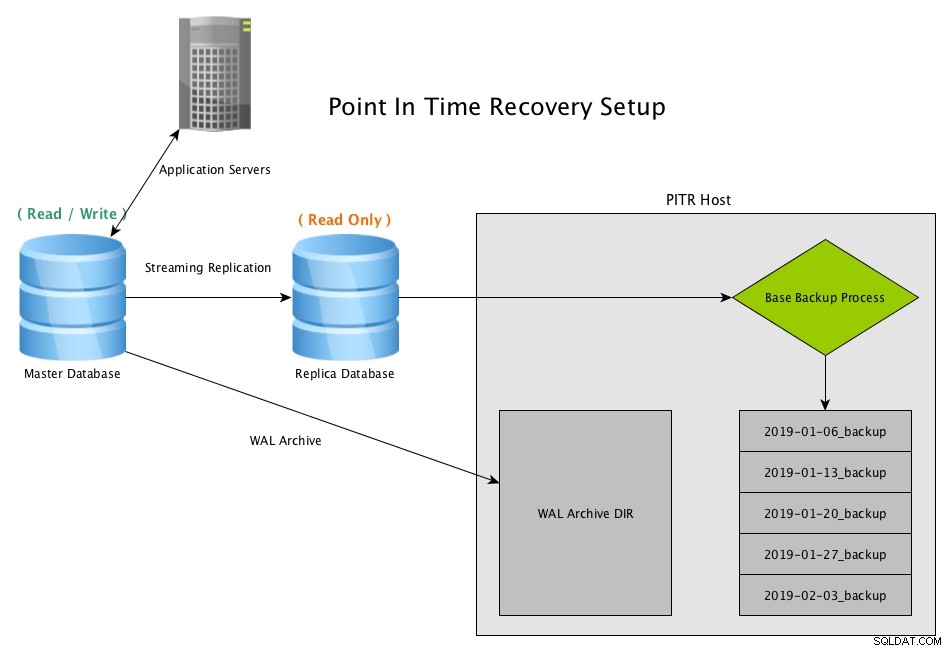 Pemulihan Titik Dalam Waktu (PITR) dari Replika Streaming dengan PostgreSQLUnduh Whitepaper Hari Ini Pengelolaan &Otomatisasi PostgreSQL dengan ClusterControlPelajari tentang apa yang perlu Anda ketahui untuk menerapkan, memantau, mengelola, dan menskalakan PostgreSQLUnduh Whitepaper
Pemulihan Titik Dalam Waktu (PITR) dari Replika Streaming dengan PostgreSQLUnduh Whitepaper Hari Ini Pengelolaan &Otomatisasi PostgreSQL dengan ClusterControlPelajari tentang apa yang perlu Anda ketahui untuk menerapkan, memantau, mengelola, dan menskalakan PostgreSQLUnduh Whitepaper Skenario Pemulihan PITR
Menyiapkan Point In Time Recovery hanyalah bagian dari pekerjaan, harus memulihkan data adalah bagian lainnya. Semoga berhasil, ini mungkin tidak akan pernah terjadi, namun sangat disarankan untuk melakukan pemulihan cadangan PITR secara berkala untuk memvalidasi bahwa sistem berfungsi, dan untuk memastikan prosesnya diketahui / ditulis dengan benar.
Dalam skenario pengujian kami, kami akan memilih titik waktu untuk memulihkan dan memulai proses pemulihan. Misalnya:Jumat pagi, pengembang mendorong perubahan kode baru ke produksi tanpa melalui tinjauan kode, dan itu menghancurkan banyak data pelanggan yang penting. Karena Siaga Panas kami selalu sinkron dengan master, gagal melakukannya tidak akan memperbaiki apa pun, karena itu akan menjadi data yang sama. Cadangan PITR adalah yang akan menyelamatkan kita.
Dorongan kode masuk pada jam 11 pagi, jadi kami perlu mengembalikan database ke tepat sebelum waktu itu, 10:59 kami memutuskan, dan untungnya kami melakukan pencadangan harian sehingga kami memiliki cadangan dari tengah malam pagi ini. Karena kami tidak tahu apa semua yang dihancurkan, kami juga memutuskan untuk melakukan pemulihan penuh database ini di host PITR kami, dan membawanya online sebagai master, karena memiliki spesifikasi perangkat keras yang sama dengan master, untuk berjaga-jaga jika ini terjadi. skenario terjadi.
Matikan Master
Karena kami memutuskan untuk memulihkan sepenuhnya dari cadangan dan mempromosikannya ke master, tidak perlu menyimpannya secara online. Kami mematikannya, tetapi menyimpannya untuk berjaga-jaga jika kami perlu mengambil sesuatu darinya nanti, untuk berjaga-jaga.
Menyiapkan Pencadangan Basis Untuk Pemulihan
Selanjutnya, pada host PITR kami, kami mengambil cadangan basis terbaru kami sebelum acara, yaitu cadangan '2018-12-21_backup'.
mkdir /var/lib/pgsql/11/data
chmod 700 /var/lib/pgsql/11/data
cd /var/lib/pgsql/11/data
tar -xzvf /mnt/db/backups/2018-12-21_backup/base.tar.gz
cd pg_wal
tar -xzvf /mnt/db/backups/2018-12-21_backup/pg_wal.tar.gz
mkdir /mnt/db/wal_archive/pitr_restore/Dengan ini, cadangan dasar, serta file WAL yang disediakan oleh pg_basebackup siap digunakan, jika kita membawanya online sekarang, itu akan pulih ke titik pencadangan terjadi, tetapi kita ingin memulihkan semua transaksi WAL antara tengah malam dan 11:59, jadi kami menyiapkan file recovery.conf kami.
Buat recovery.conf
Karena cadangan ini sebenarnya berasal dari replika streaming, kemungkinan sudah ada file recovery.conf dengan pengaturan replika. Kami akan menimpanya dengan pengaturan baru. Daftar informasi mendetail untuk semua opsi berbeda tersedia di dokumentasi PostgreSQL di sini.
Berhati-hatilah dengan file WAL, perintah pemulihan akan menyalin file terkompresi yang diperlukan ke direktori pemulihan, membuka kompresnya, lalu pindah ke tempat PostgreSQL membutuhkannya untuk pemulihan. File WAL asli akan tetap berada di tempatnya jika diperlukan karena alasan lain.
Pemulihan baru.conf:
recovery_target_time = '2018-12-21 11:59:00-07'
restore_command = 'cp /mnt/db/wal_archive/%f.gz /var/lib/pgsql/test_recovery/pitr_restore/%f.gz && gunzip /var/lib/pgsql/test_recovery/pitr_restore/%f.gz && mv /var/lib/pgsql/test_recovery/pitr_restore/%f "%p"'Mulai Proses Pemulihan
Sekarang semuanya sudah diatur, kami akan memulai proses pemulihan. Jika ini terjadi, sebaiknya Anda mengekor log database untuk memastikannya dipulihkan sebagaimana dimaksud.
Mulai DB:
pg_ctl -D /var/lib/pgsql/11/data startMengekor log:
Akan ada banyak entri log yang menunjukkan database pulih dari file arsip, dan pada titik tertentu, itu akan menampilkan baris yang mengatakan "pemulihan berhenti sebelum melakukan transaksi ..."
2018-12-22 04:21:30 UTC [20565]: [705-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000074" from archive
2018-12-22 04:21:30 UTC [20565]: [706-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000075" from archive
2018-12-22 04:21:31 UTC [20565]: [707-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000076" from archive
2018-12-22 04:21:31 UTC [20565]: [708-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000077" from archive
2018-12-22 04:21:31 UTC [20565]: [709-1] user=,db=,app=,client= LOG: recovery stopping before commit of transaction 611765, time 2018-12-21 11:59:01.45545+07Pada titik ini, proses pemulihan telah menyerap semua file WAL, tetapi juga perlu ditinjau sebelum online sebagai master. Dalam contoh ini, log mencatat bahwa transaksi berikutnya setelah waktu target pemulihan 11:59:00 adalah 11:59:01, dan tidak dipulihkan. Untuk Memverifikasi, masuk ke database dan lihat, database yang sedang berjalan harus berupa snapshot tepat pukul 11:59.
Ketika semuanya terlihat baik, saatnya untuk mempromosikan pemulihan sebagai master.
postgres=# SELECT pg_wal_replay_resume();
pg_wal_replay_resume
----------------------
(1 row)Sekarang, database sedang online, pulih ke titik yang kami putuskan, dan menerima koneksi baca / tulis sebagai node master. Pastikan semua parameter konfigurasi sudah benar dan siap untuk produksi.
Basis data sudah online, tetapi proses pemulihan belum selesai! Sekarang setelah cadangan PITR ini online sebagai master, siaga baru dan penyiapan PITR harus disiapkan, hingga master baru ini dapat online dan melayani aplikasi, tetapi tidak aman dari bencana lain hingga semuanya disiapkan kembali.
Skenario Pemulihan Titik Dalam Waktu Lainnya
Membawa kembali cadangan PITR untuk seluruh database adalah kasus ekstrem, tetapi ada skenario lain di mana hanya sebagian data yang hilang, rusak, atau buruk. Dalam kasus ini, kita bisa berkreasi dengan opsi pemulihan kita. Tanpa membuat master offline dan menggantinya dengan cadangan, kami dapat membawa cadangan PITR online ke waktu yang kami inginkan di host lain (atau port lain jika ruang tidak menjadi masalah), dan mengekspor data yang dipulihkan dari cadangan secara langsung ke dalam database induk. Ini dapat digunakan untuk memulihkan beberapa baris, beberapa tabel, atau konfigurasi data apa pun yang diperlukan.
Dengan replikasi streaming dan Pemulihan Point In Time, PostgreSQL memberi kami fleksibilitas tinggi untuk memastikan kami dapat memulihkan data apa pun yang kami butuhkan, selama kami memiliki host siaga yang siap digunakan sebagai master, atau cadangan siap untuk dipulihkan. Opsi Pemulihan Bencana yang baik dapat diperluas lebih lanjut dengan opsi cadangan lainnya, lebih banyak node replika, beberapa situs cadangan di berbagai pusat data dan benua, pg_dumps berkala di replika lain, dll.
Opsi ini dapat bertambah, tetapi pertanyaan sebenarnya adalah 'seberapa berharga data tersebut, dan berapa banyak yang ingin Anda keluarkan untuk mendapatkannya kembali?'. Banyak kasus hilangnya data adalah akhir dari bisnis, jadi opsi Pemulihan Bencana yang baik harus tersedia untuk mencegah hal terburuk terjadi.