Sebagian besar beban kerja OLTP melibatkan penggunaan I/O disk acak. Mengetahui bahwa disk (termasuk SSD) kinerjanya lebih lambat daripada menggunakan RAM, sistem basis data menggunakan caching untuk meningkatkan kinerja. Caching adalah tentang menyimpan data dalam memori (RAM) untuk akses yang lebih cepat di lain waktu.
PostgreSQL juga menggunakan caching datanya di ruang yang disebut shared_buffers. Di blog ini kami akan menjelajahi fungsi ini untuk membantu Anda meningkatkan kinerja.
Dasar-Dasar Caching PostgreSQL
Sebelum kita mempelajari lebih dalam konsep caching, mari kita pelajari dasar-dasarnya.
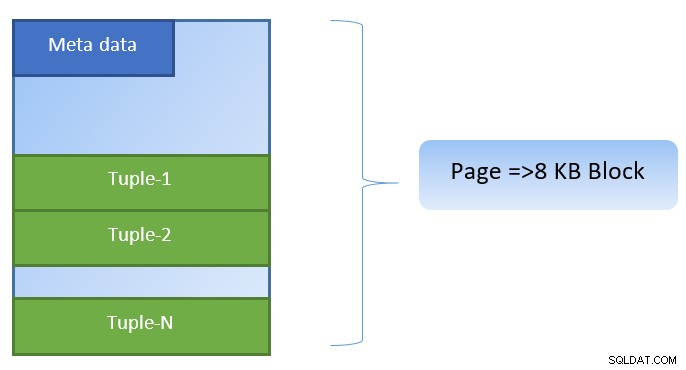
Dalam PostgreSQL, data diatur dalam bentuk halaman berukuran 8KB, dan setiap halaman tersebut dapat berisi beberapa tupel (tergantung pada ukuran tupel). Representasi sederhananya bisa seperti di bawah ini:
PostgreSQL menyimpan cache berikut untuk mempercepat akses data:
- Data dalam tabel
- Indeks
- Rencana eksekusi kueri
Sementara fokus caching rencana eksekusi kueri adalah pada penghematan siklus CPU; caching untuk data Tabel dan data Indeks difokuskan untuk menghemat operasi I/O disk yang mahal.
PostgreSQL memungkinkan pengguna menentukan berapa banyak memori yang ingin mereka simpan untuk menyimpan cache tersebut untuk data. Setelan yang relevan adalah shared_buffers di file konfigurasi postgresql.conf. Nilai terbatas shared_buffers menentukan berapa banyak halaman yang dapat di-cache setiap saat.
Saat kueri dijalankan, PostgreSQL mencari halaman pada disk yang berisi tupel yang relevan dan mendorongnya ke cache shared_buffers untuk akses lateral. Lain kali tuple yang sama (atau tuple apa pun di halaman yang sama) perlu diakses, PostgreSQL dapat menyimpan IO disk dengan membacanya di memori.
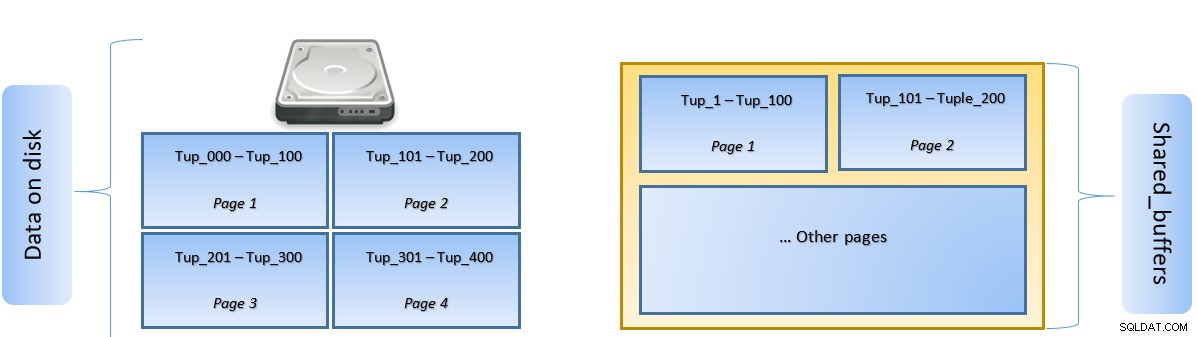
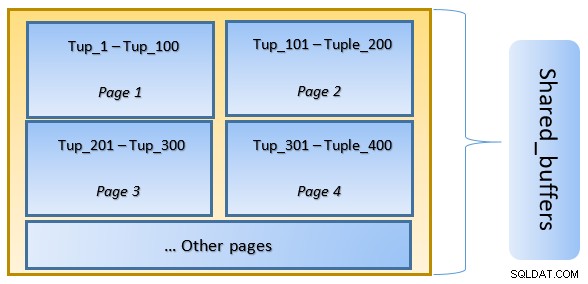
Pada gambar di atas, Halaman-1 dan Halaman-2 dari suatu tabel telah di-cache. Jika kueri pengguna perlu mengakses tupel antara Tuple-1 hingga Tuple-200, PostgreSQL dapat mengambilnya dari RAM itu sendiri.
Namun jika kueri perlu mengakses Tuples 250 hingga 350, kueri tersebut perlu melakukan I/O disk untuk Halaman 3 dan Halaman 4. Akses lebih lanjut untuk Tuple 201 hingga 400 akan diambil dari cache dan disk I/O tidak akan diperlukan – sehingga membuat kueri lebih cepat.
Pada tingkat tinggi, PostgreSQL mengikuti algoritma LRU (paling jarang digunakan) untuk mengidentifikasi halaman yang perlu dikeluarkan dari cache. Dengan kata lain, halaman yang diakses hanya sekali memiliki peluang penggusuran yang lebih tinggi (dibandingkan dengan halaman yang diakses beberapa kali), jika halaman baru perlu diambil oleh PostgreSQL ke dalam cache.
Beraksi Caching PostgreSQL
Mari kita jalankan contoh dan lihat dampak cache pada kinerja.
Mulai PostgreSQL dengan menjaga shared_buffer disetel ke default 128 MB
$ initdb -D ${HOME}/data
$ echo “shared_buffers=128MB” >> ${HOME}/data/postgresql.conf
$ pg_ctl -D ${HOME}/data startHubungkan ke server dan buat tabel dummy tblDummy dan indeks di c_id
CREATE Table tblDummy
(
id serial primary key,
p_id int,
c_id int,
entry_time timestamp,
entry_value int,
description varchar(50)
);
CREATE INDEX ON tblDummy(c_id );Mengisi data dummy dengan 200000 tupel, sehingga ada 10.000 p_id unik dan untuk setiap p_id ada 200 c_id
DO $$
DECLARE
random_value integer:= 1;
BEGIN
FOR p_id_ctr IN 1..10000 BY 1 LOOP
FOR c_id_ctr IN 1..200 BY 1 LOOP
random_value = (( random() * 75 ) + 25);
INSERT INTO tblDummy (p_id,c_id,entry_time, entry_value, description )
VALUES (p_id_ctr,c_id_ctr,'now', random_value, CONCAT('Description for :',p_id_ctr, c_id_ctr));
END LOOP ;
END LOOP ;
END $$;Mulai ulang server untuk menghapus cache. Sekarang jalankan kueri dan periksa waktu yang dibutuhkan untuk mengeksekusi yang sama
SELECT pg_stat_reset();
EXPLAIN ANAYZE SELECT count(*) from tbldummy where c_id=1;
QUERY PLAN
--------------------------------------------------------------
Aggregate (cost=17407.33..17407.34 rows=1 width=8) (actual time=160.269..160.269 rows=1 loops=1)
-> Bitmap Heap Scan on tbldummy (cost=189.52..17382.46 rows=9948 width=0) (actual time=10.627..156.275 rows=10000 loops=1)
Recheck Cond: (c_id = 1)
Heap Blocks: exact=10000
-> Bitmap Index Scan on tbldummy_c_id_idx (cost=0.00..187.04 rows=9948 width=0) (actual time=5.091..5.091 rows=10000 loops=1)
Index Cond: (c_id = 1)
Planning Time: 1.325 ms
Execution Time: 160.505 msKemudian periksa blok yang dibaca dari disk
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
---------------+---------------
10000 | 0Dalam contoh di atas, ada 1000 blok yang dibaca dari disk untuk menemukan tupel hitungan di mana c_id =1. Butuh 160 ms karena ada disk I/O yang terlibat untuk mengambil catatan tersebut dari disk.
Eksekusi lebih cepat jika kueri yang sama dieksekusi ulang, karena semua blok masih dalam cache server PostgreSQL pada tahap ini
SELECT pg_stat_reset();
EXPLAIN ANAYZE SELECT count(*) from tbldummy where c_id=1;
QUERY PLAN
-------------------------------------------------------------------------------------
Aggregate (cost=17407.33..17407.34 rows=1 width=8) (actual time=33.760..33.761 rows=1 loops=1)
-> Bitmap Heap Scan on tbldummy (cost=189.52..17382.46 rows=9948 width=0) (actual time=9.584..30.576 rows=10000 loops=1)
Recheck Cond: (c_id = 1)
Heap Blocks: exact=10000
-> Bitmap Index Scan on tbldummy_c_id_idx (cost=0.00..187.04 rows=9948 width=0) (actual time=4.314..4.314 rows=10000 loops=1)
Index Cond: (c_id = 1)
Planning Time: 0.106 ms
Execution Time: 33.990 msdan memblokir pembacaan dari disk vs dari cache
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
---------------+---------------
0 | 10000Ternyata dari atas bahwa karena semua blok dibaca dari cache dan tidak diperlukan I/O disk. Ini juga memberikan hasil yang lebih cepat.
Menyetel Ukuran Cache PostgreSQL
Ukuran cache perlu disesuaikan di lingkungan produksi sesuai dengan jumlah RAM yang tersedia serta kueri yang diperlukan untuk dieksekusi.
Sebagai contoh – shared_buffer sebesar 128MB mungkin tidak cukup untuk menyimpan semua data dalam cache, jika kuerinya untuk mengambil lebih banyak tupel:
SELECT pg_stat_reset();
SELECT count(*) from tbldummy where c_id < 150;
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
----------------+---------------
20331 | 288Ubah shared_buffer menjadi 1024MB untuk meningkatkan heap_blks_hit.
Sebenarnya, dengan mempertimbangkan kueri (berdasarkan c_id), jika data diatur ulang, rasio hit cache yang lebih baik dapat dicapai dengan shared_buffer yang lebih kecil juga.
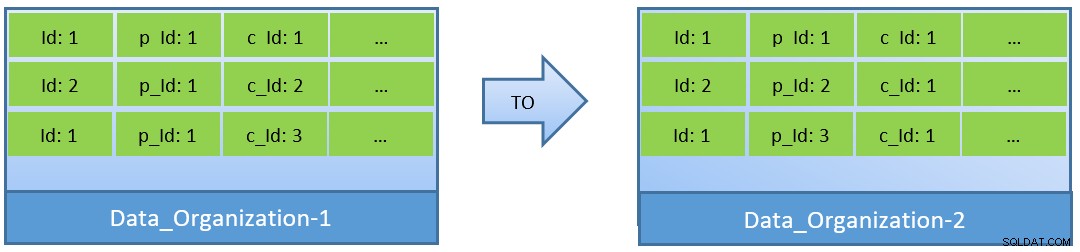
Dalam Data_Organization-1, PostgreSQL akan membutuhkan 1000 blok pembacaan (dan konsumsi cache ) untuk menemukan c_id=1. Di sisi lain, untuk Data_Organisation-2, untuk kueri yang sama, PostgreSQL hanya membutuhkan 104 blok.
Lebih sedikit blok yang diperlukan untuk kueri yang sama pada akhirnya menggunakan lebih sedikit cache dan juga menjaga waktu eksekusi kueri tetap optimal.
Kesimpulan
Sementara shared_buffer dipertahankan pada level proses PostgreSQL, cache level kernel juga dipertimbangkan untuk mengidentifikasi rencana eksekusi kueri yang dioptimalkan. Saya akan membahas topik ini di seri blog selanjutnya.