Pengantar
Saat ini, ketersediaan tinggi merupakan persyaratan bagi banyak sistem, apa pun teknologi yang Anda gunakan. Ini sangat penting untuk database, karena mereka menyimpan data yang diandalkan oleh aplikasi dan sistem penting. Strategi yang paling umum untuk mencapai ketersediaan tinggi adalah replikasi. Ada berbagai cara untuk mereplikasi data di beberapa server dan lalu lintas failover ketika, misalnya, server utama berhenti merespons.
Arsitektur Ketersediaan Tinggi untuk PostgreSQL
Ada beberapa arsitektur untuk mengimplementasikan ketersediaan tinggi di PostgreSQL, tetapi arsitektur dasarnya adalah arsitektur Primary-Standby dan Primary-Primary.
Arsitektur Siaga-Primer
Primary-Standby mungkin merupakan arsitektur HA paling dasar yang dapat Anda atur dan, seringkali, yang paling mudah untuk diterapkan dan dipelihara. Ini didasarkan pada satu database Primer dengan satu atau lebih server Siaga. Database Siaga ini akan tetap disinkronkan (atau hampir disinkronkan) dengan node Utama, tergantung pada apakah replikasi sinkron atau asinkron. Jika server Utama gagal, server Siaga berisi hampir semua data server Utama dan dapat dengan cepat diubah menjadi server basis data Utama yang baru.
Anda dapat menerapkan dua jenis database Siaga, berdasarkan sifat replikasi:
- Logical Standbys – Replikasi antara Primary dan Standby dilakukan melalui pernyataan SQL.
- Siaga Fisik – Replikasi antara Primer dan Siaga dilakukan melalui modifikasi struktur data internal.
Dalam kasus PostgreSQL, aliran catatan write-ahead log (WAL) digunakan untuk menjaga sinkronisasi database Standby. Ini bisa sinkron atau asinkron, dan seluruh server database direplikasi.
Mulai dari versi 10, PostgreSQL menyertakan opsi bawaan untuk menyiapkan replikasi logis, yang membuat aliran modifikasi data logis dari informasi di log tulis. Metode replikasi ini memungkinkan perubahan data dari tabel individu untuk direplikasi tanpa perlu menunjuk server utama. Ini juga memungkinkan data mengalir ke berbagai arah.
Sayangnya, penyiapan Utama-Siaga tidak cukup untuk memastikan ketersediaan tinggi secara efektif, karena Anda juga perlu menangani kegagalan. Untuk menangani kegagalan, Anda harus mampu mendeteksinya. Setelah Anda mengetahui ada kegagalan, misalnya, kesalahan pada node Primer atau node tidak merespons, Anda dapat memilih node siaga untuk mengganti node yang gagal dengan penundaan sesedikit mungkin. Proses ini harus seefisien mungkin untuk mengembalikan fungsionalitas penuh ke aplikasi. PostgreSQL sendiri tidak menyertakan mekanisme failover otomatis, jadi ini akan memerlukan beberapa skrip khusus atau alat pihak ketiga untuk otomatisasi ini.
Setelah failover terjadi, aplikasi Anda perlu diberi tahu untuk mulai menggunakan Primer baru. Anda juga perlu mengevaluasi status arsitektur Anda setelah failover karena Anda dapat mengalami situasi di mana hanya Primer baru yang berjalan (misalnya, Anda memiliki node Primer dan hanya satu Siaga sebelum masalah). Dalam hal ini, Anda perlu menambahkan node Siaga untuk membuat ulang penyiapan Siaga Utama yang semula Anda miliki untuk ketersediaan tinggi.
Arsitektur Primer-Primer
Arsitektur Primer-Primer menyediakan cara meminimalkan dampak kesalahan pada salah satu node, karena node lain dapat menangani semua lalu lintas, hanya berpotensi sedikit memengaruhi kinerja tetapi tidak pernah kehilangan fungsionalitas. Arsitektur Primer-Primer sering digunakan dengan tujuan ganda untuk menciptakan lingkungan ketersediaan tinggi dan penskalaan secara horizontal (dibandingkan dengan konsep skalabilitas vertikal di mana Anda menambahkan lebih banyak sumber daya ke server).
PostgreSQL belum mendukung arsitektur ini "asli", jadi Anda harus merujuk ke alat dan implementasi pihak ketiga. Saat memilih solusi, Anda harus ingat bahwa ada banyak proyek/alat, tetapi beberapa di antaranya tidak lagi didukung, sementara yang lain masih baru dan mungkin belum diuji dalam produksi.
Keseimbangan Beban
Load balancers adalah alat yang dapat digunakan untuk mengelola lalu lintas dari aplikasi Anda untuk mendapatkan hasil maksimal dari arsitektur database Anda.
Tidak hanya alat ini membantu dalam menyeimbangkan beban database Anda, tetapi juga membantu aplikasi dialihkan ke node yang tersedia/sehat dan bahkan menentukan port dengan peran yang berbeda.
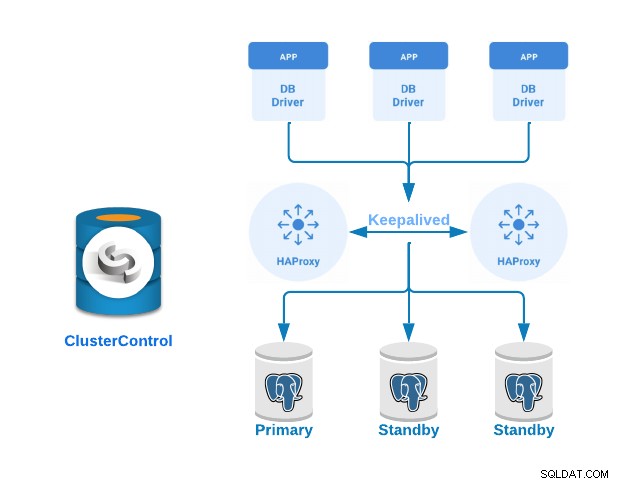
HAProxy adalah penyeimbang beban yang mendistribusikan lalu lintas dari satu asal ke satu atau beberapa tujuan dan dapat menentukan aturan dan/atau protokol khusus untuk tugas ini. Jika salah satu tujuan berhenti merespons, tujuan tersebut ditandai sebagai offline, dan lalu lintas dikirim ke tujuan lain yang tersedia.
Keepalived adalah layanan yang memungkinkan Anda mengonfigurasi alamat IP virtual dalam grup server aktif/pasif. Alamat IP virtual ini ditetapkan ke server aktif. Jika server ini gagal, alamat IP secara otomatis dimigrasikan ke server pasif “Sekunder”, memungkinkannya untuk terus bekerja dengan alamat IP yang sama secara transparan untuk sistem.
Sekarang mari kita lihat bagaimana menerapkan cluster PostgreSQL Primer-Siaga dengan server penyeimbang beban dan tetap dikonfigurasi di antara mereka. Kami akan mendemonstrasikan ini menggunakan antarmuka ClusterControl yang mudah digunakan.
Untuk contoh ini, kita akan membuat:
- 3 server PostgreSQL (satu Primer dan dua Siaga).
- 2 HAProxy Load Balancer.
- Tetap dikonfigurasi di antara server penyeimbang beban.
Penyebaran basis data
Untuk men-deploy database menggunakan ClusterControl, cukup pilih opsi “Deploy” dan ikuti petunjuk yang muncul.
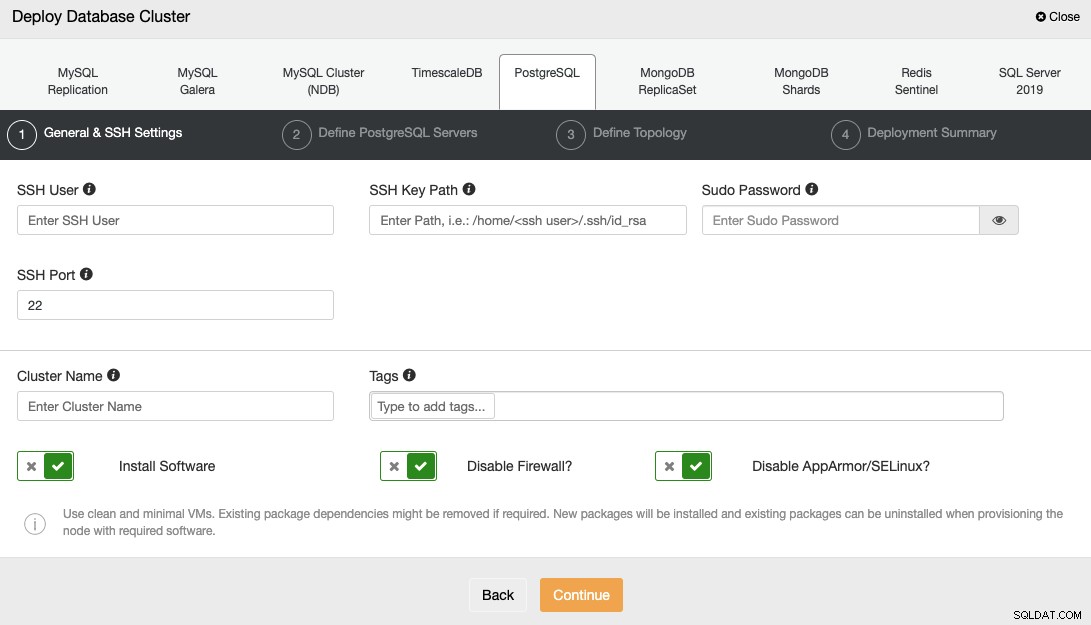
Saat memilih PostgreSQL, Anda harus menentukan Pengguna, Kunci atau Kata Sandi, dan Port untuk terhubung dengan SSH ke server Anda. Anda juga memerlukan nama untuk cluster baru Anda dan memilih apakah Anda ingin ClusterControl menginstal perangkat lunak dan konfigurasi yang sesuai untuk Anda.
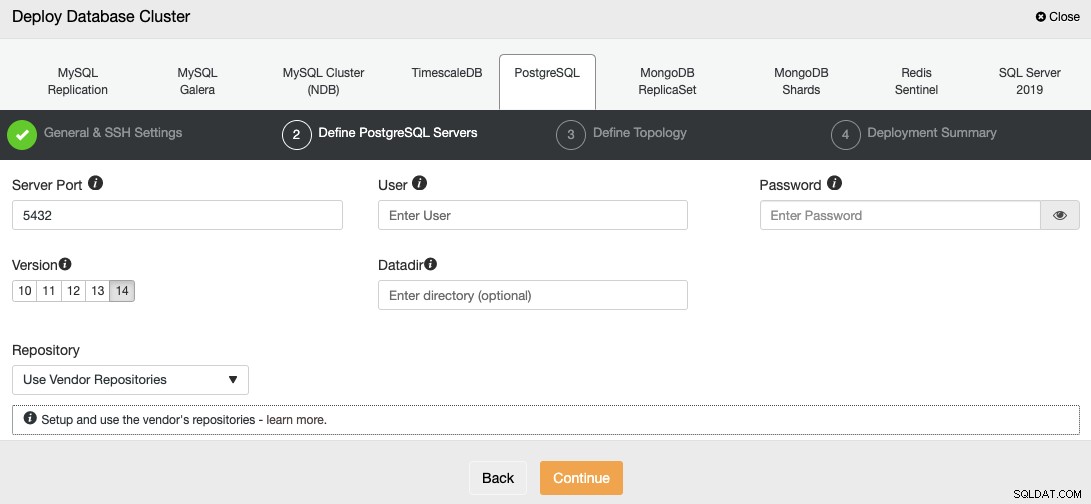
Setelah menyiapkan informasi akses SSH, Anda harus menentukan pengguna basis data, versi, dan datadir (opsional). Anda juga dapat menentukan repositori mana yang akan digunakan; repositori vendor resmi akan digunakan secara default.
Pada langkah selanjutnya, Anda perlu menambahkan server Anda ke cluster yang akan Anda buat.
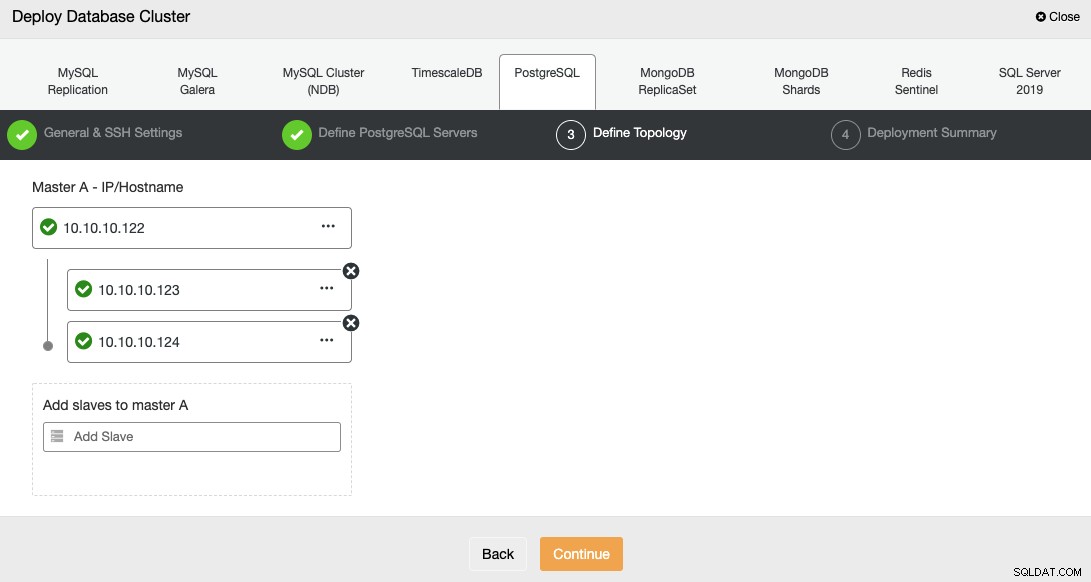
Saat menambahkan server, Anda dapat memasukkan IP atau nama host.
Pada langkah terakhir, Anda dapat memilih apakah replikasi Anda akan Sinkron atau Asinkron.
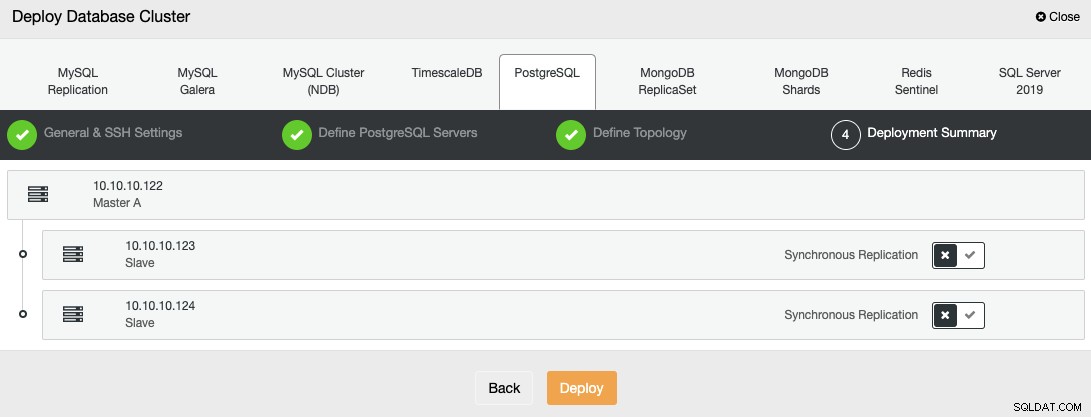
Anda dapat memantau status pembuatan cluster baru Anda dari ClusterControl pemantau aktivitas.
Setelah tugas selesai, Anda dapat melihat cluster Anda di ClusterControl utama layar.
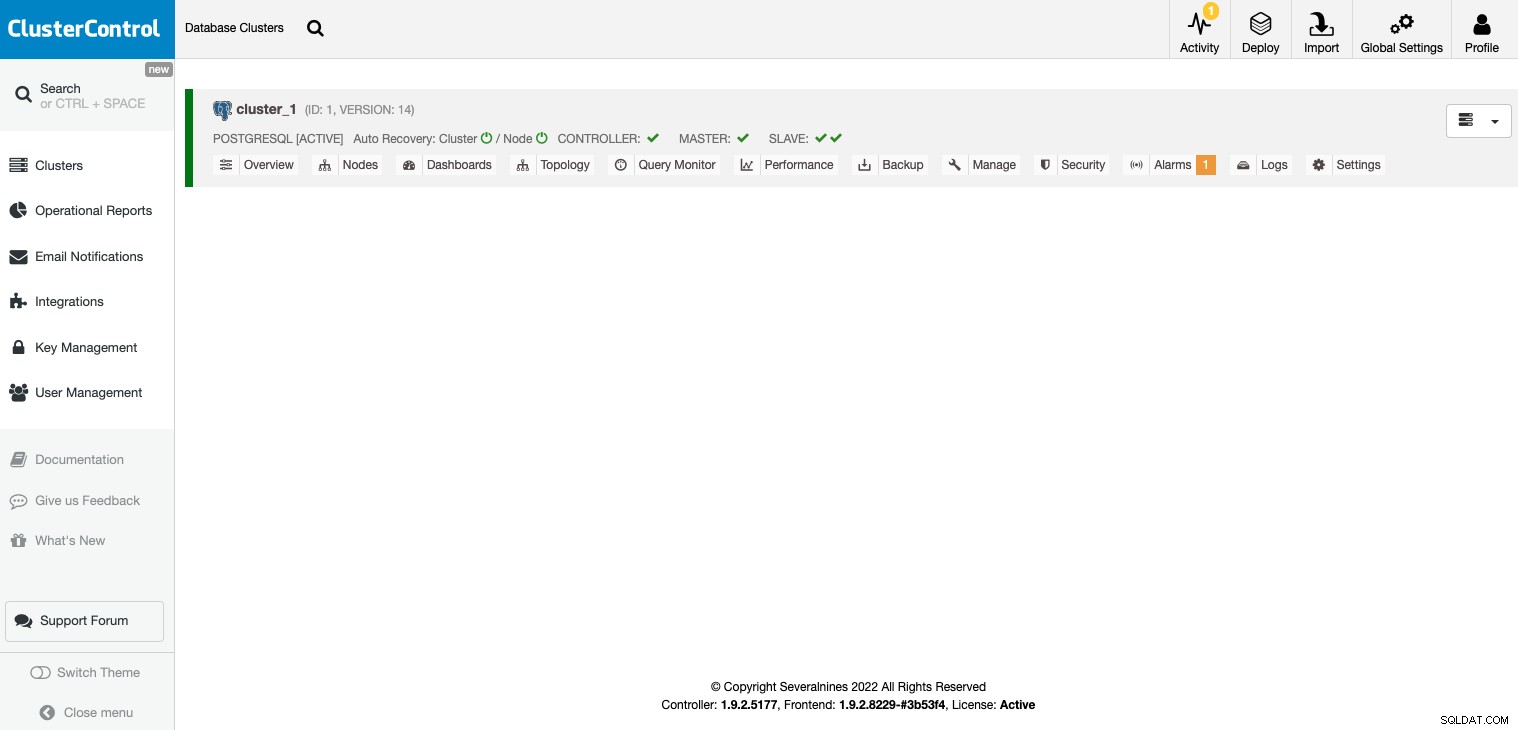
Setelah cluster Anda dibuat, Anda dapat melakukan beberapa tugas, seperti menambahkan load balancer (HAProxy) atau replika baru.
Penerapan Penyeimbang Beban
Untuk melakukan penerapan penyeimbang beban, pilih opsi “Tambahkan Penyeimbang Beban” di tindakan klaster dan isi informasi yang diminta.
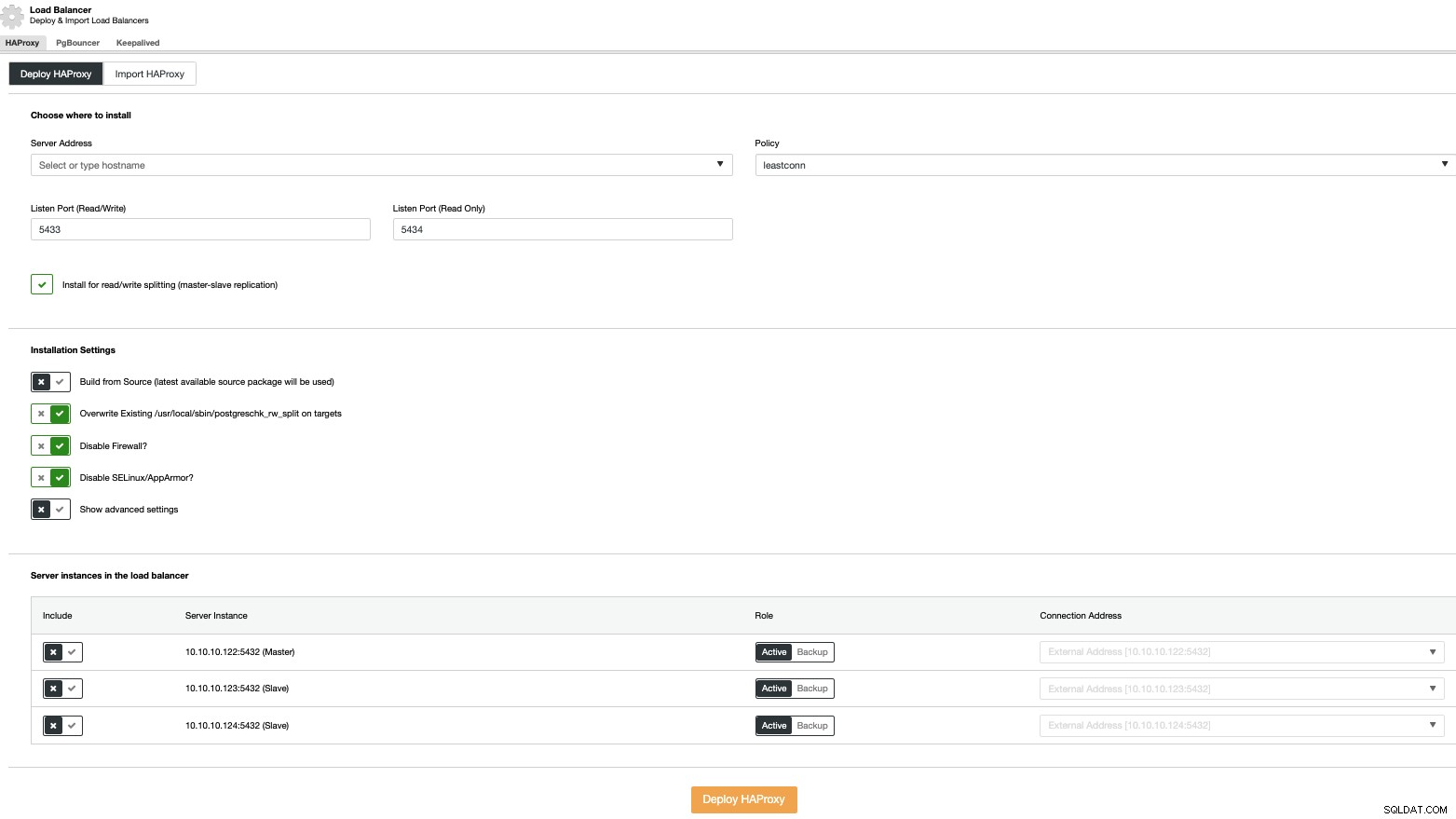
Anda hanya perlu menambahkan alamat IP atau Hostname, Port, Policy, dan node yang akan Anda konfigurasikan di load balancer Anda.
Penerapan Tetap Terjaga
Untuk melakukan penerapan keepalived, pilih cluster, buka menu “Kelola” dan bagian “Load Balancer”, lalu pilih opsi “Keepalived”.
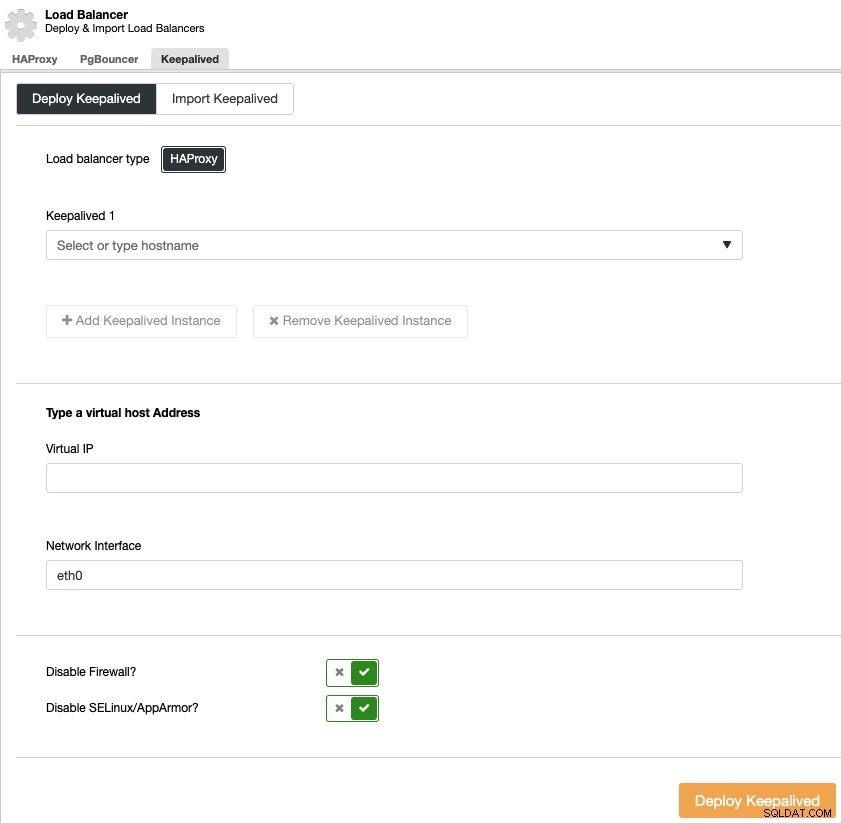
Anda harus memilih server penyeimbang beban dan alamat IP virtual untuk high lingkungan ketersediaan.
Keepalived menggunakan alamat IP virtual dan memindahkannya dari satu penyeimbang beban ke penyeimbang beban lainnya jika terjadi kegagalan, sehingga sistem Anda dapat terus berfungsi secara normal.
Jika Anda mengikuti langkah sebelumnya, Anda harus memiliki topologi berikut:
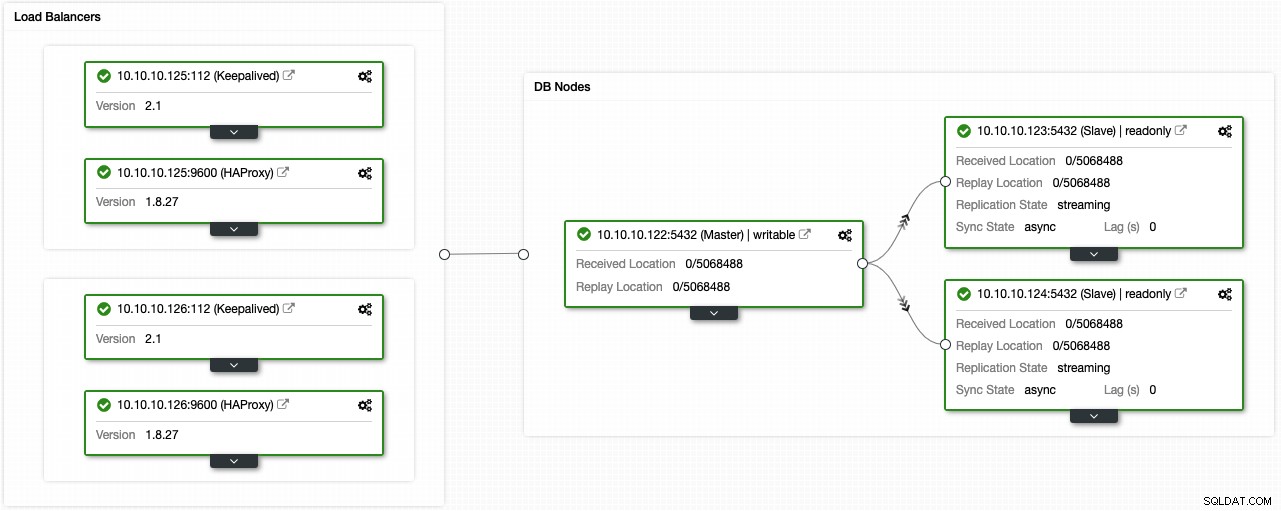
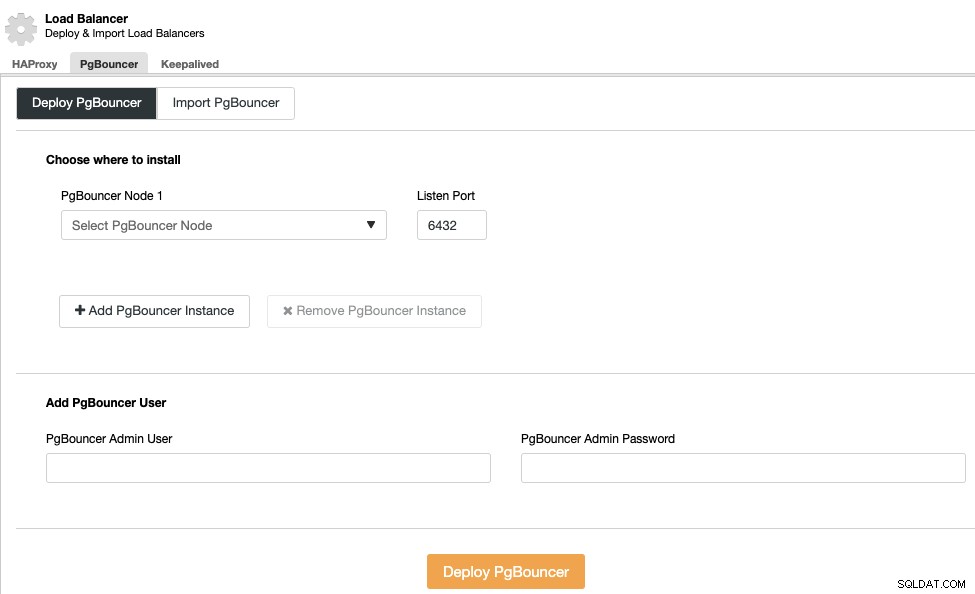
Anda dapat meningkatkan lingkungan ketersediaan tinggi ini dengan menambahkan pooler koneksi seperti PgBouncer. Ini bukan suatu keharusan tetapi dapat membantu untuk meningkatkan kinerja dan menangani koneksi aktif jika terjadi kegagalan, dan yang terbaik adalah, Anda juga dapat menerapkannya dengan menggunakan ClusterControl.
Kegagalan Kontrol Cluster
Misalkan opsi "Pemulihan Otomatis" AKTIF di server ClusterControl Anda. Jika terjadi kegagalan Utama, ClusterControl akan mempromosikan Siaga paling canggih (jika tidak ada dalam daftar hitam) ke Utama, serta memberi tahu Anda tentang masalahnya. Ini juga akan melakukan failover pada node Siaga lainnya untuk direplikasi dari Primer baru.
HAProxy dikonfigurasi secara default dengan dua port yang berbeda; port baca-tulis dan hanya-baca.
Di port baca-tulis, Anda memiliki server Primer sebagai online dan node lainnya sebagai offline, dan di port baca-saja, Anda memiliki Primer dan Siaga online.
Bila HAProxy mendeteksi bahwa salah satu node Anda, baik Utama atau Siaga, tidak dapat diakses, HAProxy secara otomatis menandainya sebagai offline. Itu tidak memperhitungkannya untuk mengirim lalu lintas ke sana. Deteksi dilakukan oleh skrip pemeriksaan kesehatan yang dikonfigurasi ClusterControl pada saat penerapan. Ini memeriksa apakah instance aktif, apakah sedang menjalani pemulihan, atau hanya-baca.
Saat ClusterControl mempromosikan Standby ke Primer, HAProxy Anda menandai Primer lama sebagai offline untuk kedua port dan menempatkan node yang dipromosikan online di port baca-tulis.
Jika HAProxy aktif Anda, yang telah menetapkan alamat IP Virtual yang terhubung dengan sistem Anda, gagal, Keepalived memigrasikan alamat IP ini ke HAProxy pasif Anda secara otomatis. Artinya, sistem Anda dapat terus berfungsi secara normal.
Dengan cara ini, sistem Anda terus beroperasi seperti yang diharapkan dan tanpa campur tangan manual Anda.
Pertimbangan
Jika Anda berhasil memulihkan node Primer lama yang gagal, node tersebut TIDAK akan diperkenalkan kembali secara otomatis ke cluster secara default. Anda perlu melakukannya secara manual. Salah satu alasannya adalah jika replika Anda tertunda pada saat kegagalan, dan ClusterControl menambahkan Primer lama ke kluster, itu berarti hilangnya informasi atau inkonsistensi data di seluruh node. Anda mungkin juga ingin menganalisis masalah secara mendetail. Jika ClusterControl baru saja memperkenalkan kembali node yang gagal ke dalam cluster, Anda mungkin akan kehilangan informasi diagnostik.
Juga, jika failover gagal, tidak ada upaya lebih lanjut yang dilakukan. Intervensi manual diperlukan untuk menganalisis masalah dan melakukan tindakan yang sesuai. Ini untuk menghindari situasi di mana ClusterControl, sebagai manajer ketersediaan tinggi, mencoba untuk mempromosikan Siaga berikutnya dan yang berikutnya. Mungkin ada masalah, dan Anda perlu memeriksanya.
Keamanan
Satu hal penting yang tidak dapat Anda lupakan sebelum masuk ke produksi dengan lingkungan ketersediaan tinggi Anda adalah memastikan keamanannya.
Beberapa aspek keamanan yang perlu dipertimbangkan termasuk enkripsi, manajemen peran, dan pembatasan akses berdasarkan alamat IP, yang telah kami bahas secara mendalam di blog sebelumnya.
Dalam database PostgreSQL, Anda memiliki file pg_hba.conf, yang menangani otentikasi klien. Anda dapat membatasi jenis koneksi, alamat IP sumber atau jaringan, basis data mana yang dapat Anda sambungkan, dan dengan pengguna mana. Oleh karena itu, file ini merupakan bagian penting untuk keamanan PostgreSQL.
Anda dapat mengonfigurasi database PostgreSQL dari file postgresql.conf, sehingga hanya mendengarkan pada antarmuka jaringan tertentu dan port yang berbeda dari port default (5432), sehingga menghindari upaya koneksi dasar dari sumber yang tidak diinginkan .
Manajemen pengguna yang tepat, baik menggunakan sandi aman atau membatasi akses dan hak istimewa, adalah bagian penting lain dari setelan keamanan Anda. Sebaiknya Anda menetapkan hak istimewa sesedikit mungkin untuk semua pengguna dan menentukan, jika mungkin, sumber koneksi.
Anda juga dapat mengaktifkan enkripsi data, baik saat transit atau saat istirahat, untuk menghindari akses ke informasi kepada orang yang tidak berwenang.
Log audit berguna untuk memahami apa yang terjadi atau telah terjadi di database Anda. PostgreSQL memungkinkan Anda untuk mengonfigurasi beberapa parameter untuk logging atau bahkan menggunakan ekstensi pgAudit untuk tugas ini.
Terakhir namun tidak kalah pentingnya, disarankan untuk selalu memperbarui database dan server Anda dengan patch terbaru untuk menghindari risiko keamanan. Untuk ini, ClusterControl memungkinkan Anda membuat laporan operasional untuk memverifikasi apakah Anda memiliki pembaruan yang tersedia dan bahkan membantu Anda memperbarui server database Anda.
Kesimpulan
Penerapan ketersediaan tinggi tampaknya sulit dicapai, terutama dalam hal memahami berbagai arsitektur dan komponen yang diperlukan untuk mengonfigurasinya dengan benar.
Jika Anda mengelola HA secara manual, pastikan untuk memeriksa Melakukan Perubahan Topologi Replikasi untuk PostgreSQL. Banyak yang akan mencari alat seperti ClusterControl untuk membantu mengelola penerapan, penyeimbang beban, failover, keamanan, dan lainnya untuk lingkungan ketersediaan tinggi yang lengkap. Anda dapat mengunduh ClusterControl secara gratis selama 30 hari untuk melihat bagaimana ClusterControl dapat meringankan beban pengelolaan infrastruktur basis data ketersediaan tinggi.
Bagaimanapun Anda memilih untuk mengelola basis data PostgreSQL dengan ketersediaan tinggi, pastikan untuk mengikuti kami di Twitter atau LinkedIn, atau berlangganan buletin kami untuk mendapatkan pembaruan terkini dan praktik terbaik untuk mengelola penyiapan basis data Anda.