Saat menggunakan cluster database di server yang berbeda, Anda akan mendapatkan keuntungan replikasi dalam meningkatkan ketersediaan data. Namun ada kebutuhan untuk melacak proses, dan melihat apakah mereka berjalan atau tidak. Salah satu program yang digunakan dalam proses ini adalah Heartbeat yang memiliki kemampuan untuk memeriksa dan memverifikasi keberadaan sumber daya pada satu atau lebih sistem dalam cluster tertentu. Selain PostgreSQL dan sistem file tempat data PostgreSQL disimpan, DRBD adalah salah satu sumber daya yang akan kita bahas dalam artikel ini tentang bagaimana program Heartbeat dapat digunakan.
HA Detak Jantung
Seperti yang dibahas sebelumnya di blog DRBD, memiliki ketersediaan data yang tinggi dicapai dengan menjalankan berbagai instance server tetapi menyajikan data yang sama. Instance server yang berjalan ini dapat didefinisikan sebagai kluster dalam kaitannya dengan Detak Jantung. Pada dasarnya, setiap instance server secara fisik mampu memberikan layanan yang sama seperti yang lain dalam cluster itu. Namun, hanya satu instans yang dapat secara aktif menyediakan layanan pada satu waktu untuk tujuan memastikan ketersediaan data yang tinggi. Oleh karena itu, kami dapat mendefinisikan mesin virtual lain sebagai 'suku cadang panas' yang dapat digunakan jika terjadi kegagalan master. Paket Heartbeat dapat diunduh dari tautan ini. Setelah menginstal paket ini, Anda dapat mengonfigurasinya agar berfungsi dengan sistem Anda dengan prosedur di bawah ini. Struktur sederhana dari konfigurasi Detak Jantung adalah:
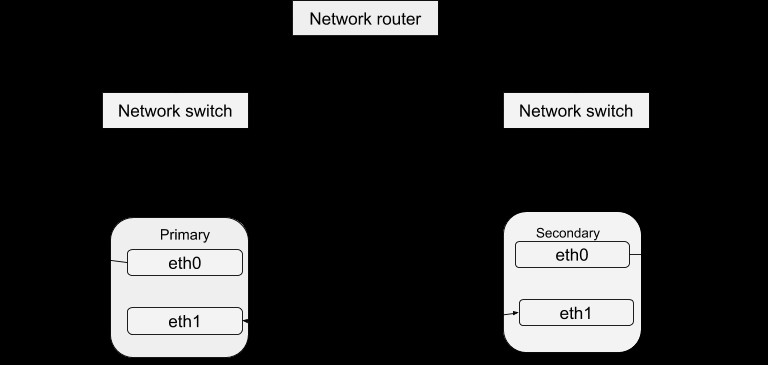
Konfigurasi Detak Jantung
Melihat ke direktori ini /etc/ha.d Anda akan menemukan beberapa file yang digunakan dalam proses konfigurasi. File ha.cf membentuk konfigurasi detak jantung utama. Ini mencakup daftar semua node dan waktu untuk mengidentifikasi kegagalan selain mengarahkan detak jantung pada jenis jalur media yang digunakan dan cara mengkonfigurasinya. Informasi keamanan untuk cluster dicatat dalam file authkeys. Informasi yang direkam dalam file ini harus identik untuk semua host di cluster dan ini dapat dengan mudah dicapai melalui sinkronisasi di semua host. Artinya, setiap perubahan informasi dalam satu host harus disalin ke semua host lainnya.
Berkas Ha.cf
Garis besar dasar file ha.cf adalah
logfacility local0
keepalive 3
Deadtime 7
warntime 3
initdead 30
mcast eth0 225.0.0.1 694 2 0
mcast eth1 225.0.0.2 694 1 0
auto_failback off
node drbd1
node drbd2
node drbd3-
Logfacility:yang ini digunakan untuk mengarahkan Detak Jantung di mana fasilitas syslog logging yang seharusnya digunakan untuk merekam pesan. Nilai yang paling umum digunakan adalah auth, authpriv, user, local0, syslog dan daemon. Anda juga dapat memutuskan untuk tidak memiliki log apa pun sehingga Anda dapat menyetel nilainya menjadi none .i.e
logfacility none - Keepalive:ini adalah waktu antara detak jantung yaitu frekuensi pengiriman sinyal detak jantung ke host lain. Pada contoh kode di atas disetel ke 3 detik.
- Deadtime:penundaan dalam hitungan detik setelah node dinyatakan gagal.
- Warntime:adalah penundaan dalam detik setelah peringatan dicatat ke log yang menunjukkan bahwa sebuah node tidak dapat dihubungi lagi.
- Initdead:ini adalah waktu dalam detik untuk menunggu selama sistem mulai sebelum host lain dianggap mati.
- Mcast:ini adalah prosedur metode yang ditentukan untuk mengirim sinyal detak jantung. Untuk kode contoh di atas, alamat jaringan multicast sedang digunakan melalui perangkat jaringan yang dibatasi. Untuk beberapa cluster, alamat multicast harus unik untuk setiap cluster. Anda juga dapat memilih koneksi serial melalui multicast atau jika Anda mengatur sedemikian rupa sehingga ada beberapa antarmuka jaringan, gunakan keduanya untuk koneksi detak jantung seperti contoh. Keuntungan menggunakan keduanya adalah untuk mengatasi kemungkinan kegagalan sementara yang akibatnya dapat menyebabkan peristiwa kegagalan yang tidak valid.
- Auto_failback:ini menghubungkan kembali server yang gagal kembali ke cluster jika tersedia. Namun hal itu dapat menyebabkan kebingungan jika server dihidupkan dan kemudian online pada waktu yang berbeda. Sehubungan dengan DRBD, jika tidak dikonfigurasi dengan baik, Anda mungkin berakhir dengan lebih dari satu kumpulan data di server yang sama. Oleh karena itu, disarankan untuk selalu menonaktifkannya.
- Node:menguraikan node dalam grup cluster Detak Jantung. Anda setidaknya harus memiliki 1 simpul untuk setiap simpul.
Konfigurasi Tambahan
Anda juga dapat mengatur informasi konfigurasi tambahan seperti:
ping 10.0.0.1
respawn hacluster /usr/lib64/heartbeat/ipfail
apiauth ipfail gid=haclient uid=hacluster
deadping 5- Ping:ini penting untuk memastikan Anda memiliki konektivitas pada antarmuka publik untuk server dan koneksi ke host lain. Penting untuk mempertimbangkan alamat IP daripada nama host untuk mesin tujuan.
- Respawn:ini adalah perintah yang dijalankan saat terjadi kegagalan.
- Apiauth:adalah otoritas untuk kegagalan. Anda perlu mengonfigurasi ID pengguna dan grup yang dengannya perintah akan dijalankan. File authkeys menyimpan informasi otorisasi untuk cluster Heartbeat dan kunci ini sangat unik untuk memverifikasi mesin dalam cluster Heartbeat tertentu.
- Deadping:menentukan batas waktu sebelum nonresponse memicu kegagalan.
Integrasi Detak Jantung Dengan Postgres dan DRBD
Seperti disebutkan sebelumnya, ketika server master gagal, server lain dengan cluster tertentu akan bertindak untuk menyediakan layanan yang sama. Detak jantung membantu dalam konfigurasi sumber daya yang meningkatkan pemilihan server jika terjadi kegagalan. Misalnya mendefinisikan server individu mana yang harus dibawa atau dibuang pada saat terjadi kegagalan. Memeriksa file haresources di direktori /etc/ha.d, kami mendapatkan garis besar sumber daya yang dapat dikelola. Jalur file sumber daya adalah /etc/ha.d/resource.d dan definisi sumber daya dalam satu baris yaitu:
drbd1 drbddisk Filesystem::/dev/drbd0::/drbd::ext3 postgres 10.0.0.1(perhatikan spasi putih).
- Drbd1:mengacu pada nama host yang lebih disukai untuk lebih memotong server yang biasanya digunakan sebagai master default untuk menangani layanan. Seperti yang disebutkan di blog DRBD, kami membutuhkan sumber daya untuk server kami dan ini didefinisikan di baris sebagai drbddisk, sistem file, dan postgres. Bidang terakhir adalah alamat IP virtual yang harus digunakan untuk berbagi layanan yaitu menghubungkan ke server Postgres. Secara default, itu akan dialokasikan ke server yang aktif saat Detak Jantung dimulai. Ketika terjadi kegagalan, sumber daya ini akan dimulai pada server cadangan dalam urutan pengaturan saat skrip koresponden dipanggil. Dalam pengaturan, skrip akan mengalihkan disk DRBD pada host sekunder ke mode utama, membuat perangkat membaca/menulis.
- Sistem file:ini akan mengelola sumber daya sistem file dan dalam hal ini DRBD telah dipilih sehingga akan dipasang selama panggilan skrip sumber daya.
- Postgres:ini akan memulai atau mengelola server Postgres
Terkadang Anda ingin mendapatkan notifikasi melalui email. Untuk melakukannya, tambahkan baris ini ke file sumber daya dengan email Anda untuk menerima teks peringatan:
MailTo:: example@sqldat.com::DRBDFailureUntuk memulai detak jantung, Anda dapat menjalankan perintah
/etc/ha.d/heartbeat startatau reboot server primer dan sekunder. Sekarang jika Anda menjalankan perintah
$ /usr/lib64/heartbeat/hb_standbyNode saat ini akan dipicu untuk melepaskan sumber dayanya secara bersih ke node lain.
Unduh Whitepaper Hari Ini Pengelolaan &Otomatisasi PostgreSQL dengan ClusterControlPelajari tentang apa yang perlu Anda ketahui untuk menerapkan, memantau, mengelola, dan menskalakan PostgreSQLUnduh WhitepaperMenangani Kesalahan Tingkat Sistem
Terkadang kernel server mungkin rusak sehingga menunjukkan potensi masalah dengan server Anda. Anda perlu mengonfigurasi server untuk menghapus dirinya sendiri dari cluster selama terjadi masalah. Masalah ini sering disebut sebagai kernel panic dan akibatnya memicu hard reboot pada mesin Anda. Anda dapat memaksa reboot dengan mengatur kernel.panic dan kernel.panic_on_oop dari file kontrol kernel /etc/sysctl.conf. Yaitu
kernel.panic_on_oops = 1
kernel.panic = 1Pilihan lain adalah melakukannya dari baris perintah menggunakan perintah sysctl yaitu:
$ sysctl -w kernel.panic=1Anda juga dapat mengedit file sysctl.conf dan memuat ulang informasi konfigurasi menggunakan perintah ini.
sysctl -pNilai tersebut menunjukkan jumlah detik untuk menunggu sebelum melakukan boot ulang. Node detak jantung kedua kemudian akan mendeteksi bahwa server sedang down dan kemudian beralih ke host failover.
Kesimpulan
Detak jantung adalah subsistem yang memungkinkan pemilihan server sekunder menjadi primer dan sistem cadangan ketika server aktif gagal. Ini juga menentukan apakah semua server lain masih hidup. Ini juga memastikan transfer sumber daya ke node utama baru