MongoDB adalah database NoSQL yang mendukung berbagai macam sumber dataset input. Itu dapat menyimpan data dalam dokumen seperti JSON yang fleksibel, artinya bidang atau metadata dapat bervariasi dari dokumen ke dokumen dan struktur data dapat diubah dari waktu ke waktu. Model dokumen membuat data mudah digunakan dengan memetakan ke objek dalam kode aplikasi. MongoDB juga dikenal sebagai basis data terdistribusi pada intinya, sehingga ketersediaan tinggi, penskalaan horizontal, dan distribusi geografis sudah ada di dalamnya dan mudah digunakan. Muncul dengan kemampuan untuk memodifikasi parameter dengan mulus untuk pelatihan model. Ilmuwan Data dapat dengan mudah menggabungkan struktur data dengan pembuatan model ini.
Apa itu Pembelajaran Mesin?
Pembelajaran Mesin adalah ilmu untuk membuat komputer belajar dan bertindak seperti yang dilakukan manusia dan meningkatkan pembelajaran mereka dari waktu ke waktu secara mandiri. Proses pembelajaran dimulai dengan pengamatan atau data, seperti contoh, pengalaman langsung, atau instruksi, untuk mencari pola dalam data dan membuat keputusan yang lebih baik di masa depan berdasarkan contoh yang kami berikan. Tujuan utamanya adalah untuk memungkinkan komputer belajar secara otomatis tanpa campur tangan atau bantuan manusia dan menyesuaikan tindakan yang sesuai.
Model Pemrograman dan Kueri yang Kaya
MongoDB menawarkan driver asli dan konektor bersertifikat untuk pengembang dan ilmuwan data yang membangun model pembelajaran mesin dengan data dari MongoDB. PyMongo adalah perpustakaan yang bagus untuk menanamkan sintaks MongoDB ke dalam kode Python. Kami dapat mengimpor semua fungsi dan metode MongoDB untuk menggunakannya dalam kode pembelajaran mesin kami. Ini adalah teknik yang bagus untuk mendapatkan fungsionalitas multi-bahasa dalam satu kode. Keuntungan tambahannya adalah Anda dapat menggunakan fitur penting dari bahasa pemrograman tersebut untuk membuat aplikasi yang efisien.
Bahasa kueri MongoDB dengan indeks sekunder yang kaya memungkinkan pengembang membangun aplikasi yang dapat melakukan kueri dan menganalisis data dalam berbagai dimensi. Data dapat diakses dengan kunci tunggal, rentang, pencarian teks, grafik, dan kueri geospasial melalui agregasi kompleks dan tugas MapReduce, mengembalikan respons dalam milidetik.
Untuk memparalelkan pemrosesan data di seluruh cluster database terdistribusi, MongoDB menyediakan jalur agregasi dan MapReduce. Pipa agregasi MongoDB dimodelkan di sepanjang konsep pipa pemrosesan data. Dokumen memasuki pipa multi-tahap yang mengubah dokumen menjadi hasil agregat menggunakan operasi asli yang dijalankan dalam MongoDB. Tahap pipa paling dasar menyediakan filter yang beroperasi seperti kueri, dan transformasi dokumen yang mengubah bentuk dokumen keluaran. Operasi pipa lainnya menyediakan alat untuk mengelompokkan dan menyortir dokumen berdasarkan bidang tertentu serta alat untuk menggabungkan konten larik, termasuk larik dokumen. Selain itu, tahapan pipseline dapat menggunakan operator untuk tugas-tugas seperti menghitung rata-rata atau standar deviasi di seluruh koleksi dokumen, dan memanipulasi string. MongoDB juga menyediakan operasi MapReduce asli dalam database, menggunakan fungsi JavaScript khusus untuk melakukan peta dan mengurangi tahapan.
Selain kerangka kueri aslinya, MongoDB juga menawarkan konektor kinerja tinggi untuk Apache Spark. Konektor memperlihatkan semua perpustakaan Spark, termasuk Python, R, Scala, dan Java. Data MongoDB diwujudkan sebagai DataFrames dan Datasets untuk analisis dengan machine learning, grafik, streaming, dan SQL API.
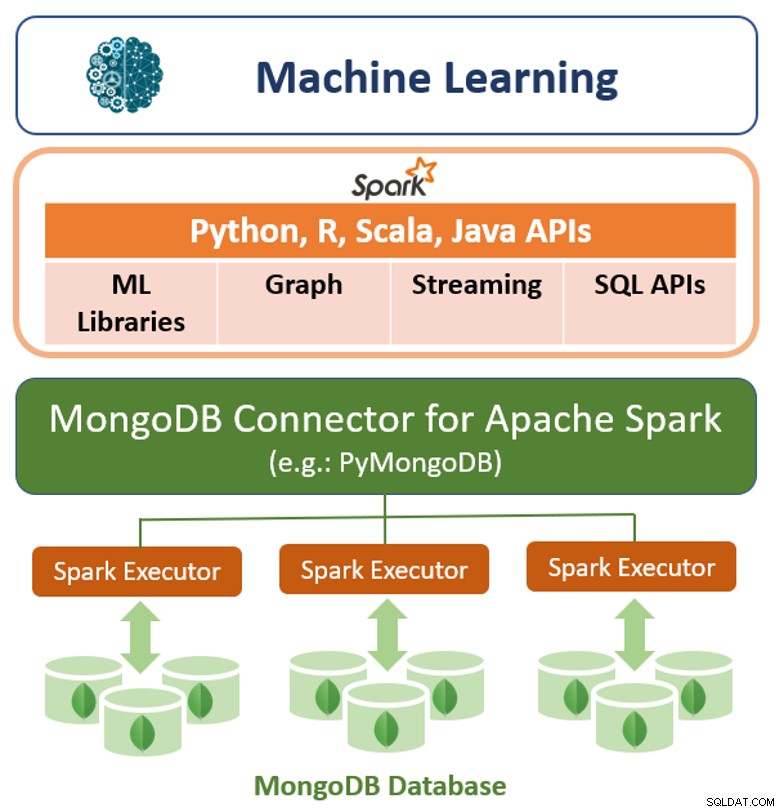
Konektor MongoDB untuk Apache Spark dapat memanfaatkan pipa agregasi MongoDB dan sekunder indeks untuk mengekstrak, memfilter, dan memproses hanya rentang data yang dibutuhkan - misalnya, menganalisis semua pelanggan yang berlokasi di geografi tertentu. Ini sangat berbeda dari penyimpanan data NoSQL sederhana yang tidak mendukung indeks sekunder atau agregasi dalam basis data. Dalam kasus ini, Spark perlu mengekstrak semua data berdasarkan kunci utama sederhana, meskipun hanya sebagian dari data tersebut yang diperlukan untuk proses Spark. Ini berarti lebih banyak overhead pemrosesan, lebih banyak perangkat keras, dan waktu lebih lama untuk memahami data scientist dan engineer. Untuk memaksimalkan kinerja di seluruh kumpulan data yang besar dan terdistribusi, Konektor MongoDB untuk Apache Spark dapat menempatkan Resilient Distributed Datasets (RDD) bersama-sama dengan node MongoDB sumber, sehingga meminimalkan pergerakan data di seluruh cluster dan mengurangi latensi.
Kinerja, Skalabilitas &Redundansi
Waktu pelatihan model dapat dikurangi dengan membangun platform pembelajaran mesin di atas lapisan database yang berkinerja dan skalabel. MongoDB menawarkan sejumlah inovasi untuk memaksimalkan throughput dan meminimalkan latensi beban kerja machine learning:
- WiredTiger dikenal sebagai mesin penyimpanan default untuk MongoDB, yang dikembangkan oleh arsitek Berkeley DB, perangkat lunak manajemen data tertanam yang paling banyak digunakan di dunia. WiredTiger berskala pada arsitektur multi-inti modern. Menggunakan berbagai teknik pemrograman seperti penunjuk bahaya, algoritme bebas kunci, penguncian cepat, dan pengiriman pesan, WiredTiger memaksimalkan kerja komputasi per inti CPU dan siklus jam. Untuk meminimalkan overhead dan I/O pada disk, WiredTiger menggunakan format file yang ringkas dan kompresi penyimpanan.
- Untuk aplikasi pembelajaran mesin yang paling sensitif terhadap latensi, MongoDB dapat dikonfigurasi dengan mesin penyimpanan Dalam-Memori. Berdasarkan WiredTiger, mesin penyimpanan ini memberi pengguna manfaat komputasi dalam memori, tanpa mengorbankan fleksibilitas kueri yang kaya, analitik waktu nyata, dan kapasitas terukur yang ditawarkan oleh basis data berbasis disk konvensional.
- Untuk memparalelkan pelatihan model dan menskalakan set data input di luar satu node, MongoDB menggunakan teknik yang disebut sharding, yang mendistribusikan pemrosesan dan data ke seluruh klaster perangkat keras komoditas. Sharding MongoDB sepenuhnya elastis, secara otomatis menyeimbangkan kembali data di seluruh cluster saat kumpulan data input bertambah, atau saat node ditambahkan dan dihapus.
- Dalam cluster MongoDB, data dari setiap shard secara otomatis didistribusikan ke beberapa replika yang dihosting di node terpisah. Kumpulan replika MongoDB menyediakan redundansi untuk memulihkan data pelatihan jika terjadi kegagalan, sehingga mengurangi overhead pemeriksaan.
Konsistensi Merdu MongoDB
MongoDB sangat konsisten secara default, memungkinkan aplikasi pembelajaran mesin untuk segera membaca apa yang telah ditulis ke database, sehingga menghindari kerumitan pengembang yang dipaksakan oleh sistem yang pada akhirnya konsisten. Konsistensi yang kuat akan memberikan hasil yang paling akurat untuk algoritme pembelajaran mesin; namun, dalam beberapa skenario dapat diterima untuk memperdagangkan konsistensi terhadap sasaran kinerja tertentu dengan mendistribusikan kueri ke seluruh kluster anggota kumpulan replika sekunder MongoDB.
Model Data Fleksibel di MongoDB
Model data dokumen MongoDB memudahkan pengembang dan ilmuwan data untuk menyimpan dan menggabungkan data dari segala bentuk struktur di dalam database, tanpa melepaskan aturan validasi yang canggih untuk mengatur kualitas data. Skema dapat dimodifikasi secara dinamis tanpa aplikasi atau database downtime yang dihasilkan dari modifikasi skema yang mahal atau desain ulang yang ditimbulkan oleh sistem database relasional.
Menyimpan model dalam database dan memuatnya, menggunakan python, juga merupakan metode yang mudah dan sangat dibutuhkan. Memilih MongoDB juga merupakan keuntungan karena merupakan database dokumen sumber terbuka dan juga database NoSQL terkemuka. MongoDB juga berfungsi sebagai konektor untuk kerangka kerja terdistribusi apache spark.
Sifat Dinamis MongoDB
Sifat dinamis MongoDB memungkinkan penggunaannya dalam tugas manipulasi database dalam mengembangkan aplikasi Machine Learning. Ini adalah cara yang sangat efisien dan mudah untuk melakukan analisis kumpulan data dan basis data. Hasil analisis dapat digunakan dalam pelatihan model machine learning. Analis data dan pemrogram Machine Learning telah direkomendasikan untuk menguasai MongoDB dan menerapkannya di banyak aplikasi berbeda. Kerangka kerja Agregasi MongoDB digunakan untuk alur kerja ilmu data untuk melakukan analisis data untuk berbagai aplikasi.
Kesimpulan
MongoDB menawarkan beberapa kemampuan berbeda seperti:model data yang fleksibel, pemrograman yang kaya, model data, model kueri, dan konsistensi yang dapat disesuaikan yang membuat pelatihan dan penggunaan algoritme pembelajaran mesin jauh lebih mudah daripada dengan database relasional tradisional. Menjalankan MongoDB sebagai database backend akan memungkinkan penyimpanan dan pengayaan data pembelajaran mesin memungkinkan kegigihan dan peningkatan efisiensi.



