Ini adalah versi tertulis dari video youtube baru saya ️
Dalam tutorial Redis ini, Anda akan mempelajari tentang Redis dan bagaimana Redis dapat digunakan sebagai database utama untuk aplikasi kompleks yang perlu menyimpan data dalam berbagai format.
Ikhtisar
- Apa itu Redis dan kegunaannya serta mengapa cocok untuk aplikasi layanan mikro modern yang kompleks?
- Bagaimana Redis mendukung penyimpanan beberapa format data untuk tujuan yang berbeda melalui modul ?
- Bagaimana Redis sebagai database dalam memori dapat menyimpan data dan memulihkan dari kehilangan data ?
- Cara menskalakan dan mereplikasi Redis ?
- Terakhir karena salah satu platform paling populer untuk menjalankan layanan mikro adalah Kubernetes dan karena menjalankan aplikasi stateful di Kubernetes agak sulit, kita akan melihat bagaimana Anda dapat dengan mudah menjalankan Redis di Kubernetes
Apa itu Redis?
Redis adalah singkatan dari re lebih banyak dic s tionary erver
Redis adalah basis data dalam memori . Jadi banyak orang telah menggunakannya sebagai cache di atas database lain untuk meningkatkan kinerja aplikasi.
Namun, yang tidak diketahui banyak orang adalah bahwa Redis adalah basis data utama yang lengkap yang dapat digunakan untuk menyimpan dan mempertahankan berbagai format data untuk aplikasi yang kompleks.
Jadi mari kita lihat kasus penggunaan untuk itu.
Mengapa Basis Data Multi-Model?
Mari kita lihat penyiapan umum untuk aplikasi layanan mikro.
Katakanlah kita memiliki aplikasi media sosial yang kompleks dengan jutaan pengguna. Untuk ini, kita mungkin perlu menyimpan format data yang berbeda dalam database yang berbeda:
- Database relasional , seperti MySQL, untuk menyimpan data kita
- ElasticSearch untuk pencarian dan pemfilteran cepat
- Basis data grafik untuk mewakili koneksi pengguna
- Database dokumen , seperti MongoDB untuk menyimpan konten media yang dibagikan oleh pengguna kami setiap hari
- Layanan cache untuk kinerja aplikasi yang lebih baik
Jelas bahwa ini adalah penyiapan yang cukup rumit.
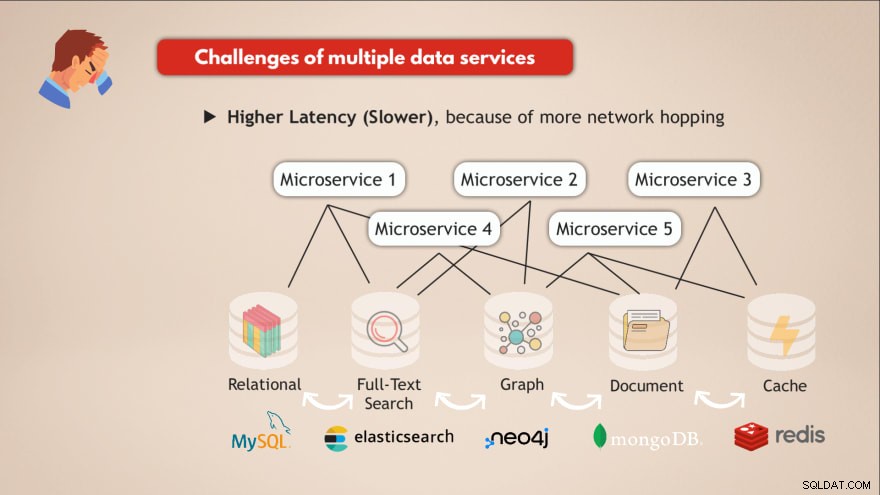
Tantangan memiliki banyak layanan data
- ❌ Setiap layanan data perlu diterapkan dan dipelihara
- ❌ Pengetahuan yang dibutuhkan untuk setiap layanan data
- ❌ Penskalaan &persyaratan infrastruktur berbeda
- ❌ Kode aplikasi yang lebih kompleks untuk berinteraksi dengan semua DB yang berbeda ini
- ❌ Latensi Lebih Tinggi (Lebih Lambat), karena lebih banyak lompatan jaringan
Memiliki Basis Data Multi-Model
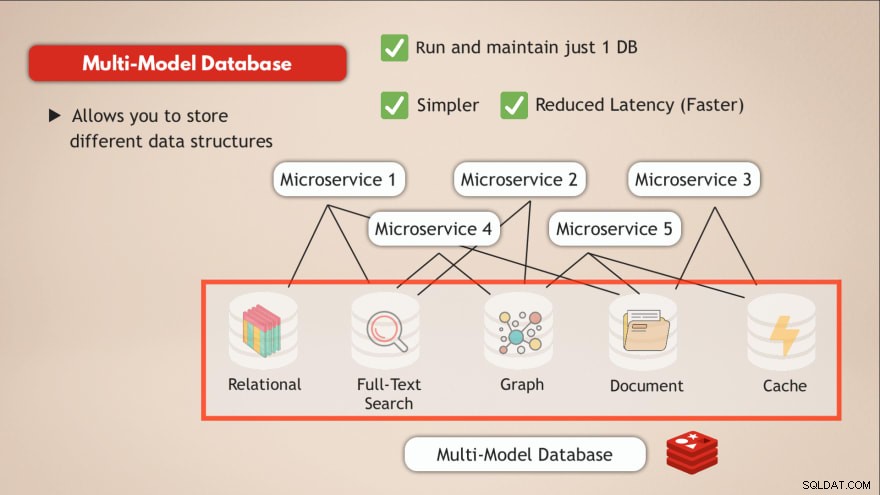
Dibandingkan dengan database multi-model, Anda menyelesaikan sebagian besar tantangan ini. Pertama-tama Anda menjalankan dan memelihara hanya 1 layanan data . Jadi aplikasi Anda juga perlu berbicara dengan satu penyimpanan data dan itu hanya membutuhkan satu antarmuka terprogram untuk layanan data tersebut.
Selain itu, latensi akan dikurangi dengan membuka titik akhir data tunggal dan menghilangkan beberapa hub jaringan internal.
Jadi memiliki satu database, seperti Redis, yang memungkinkan Anda untuk menyimpan berbagai jenis data atau pada dasarnya memungkinkan Anda untuk memiliki beberapa jenis database dalam satu serta bertindak sebagai cache memecahkan tantangan tersebut.
- ✅ Jalankan dan pertahankan hanya 1 database
- ✅ Lebih sederhana
- ✅ Latensi Berkurang (Lebih Cepat)
Bagaimana Redis bekerja?
Modul Redis
Cara kerjanya adalah Anda memiliki Redis Core, yang merupakan penyimpan nilai utama yang sudah mendukung penyimpanan beberapa jenis data dan kemudian Anda dapat memperluas inti tersebut dengan apa yang disebut modul untuk berbagai jenis data , yang dibutuhkan aplikasi Anda untuk tujuan yang berbeda. Jadi misalnya RediSearch untuk fungsi pencarian seperti ElasticSearch atau Redis Graph untuk penyimpanan data grafik dan sebagainya:

Dan hal yang hebat tentang ini adalah modular . Jadi berbagai jenis fungsionalitas basis data ini tidak terintegrasi secara erat ke dalam satu basis data, tetapi Anda dapat memilih dan memilih dengan tepat fungsionalitas layanan data mana yang Anda perlukan untuk aplikasi Anda dan kemudian pada dasarnya menambahkan modul itu.
Tembolok Luar Biasa ️
Tentu saja saat menggunakan Redis sebagai basis data utama, Anda tidak memerlukan cache tambahan, karena Anda memilikinya secara otomatis di luar kotak dengan Redis. Itu berarti lebih sedikit kerumitan dalam aplikasi Anda, karena Anda tidak perlu menerapkan logika untuk mengelola pengisian dan pembatalan cache.
Redis cepat
Sebagai basis data dalam memori (data disimpan dalam RAM), Redis sangat cepat dan berkinerja tinggi, yang tentu saja membuat aplikasi itu sendiri lebih cepat.
Tetapi pada titik ini Anda mungkin bertanya-tanya:
Bagaimana database dalam memori dapat menyimpan data?
Bagaimana Redis dapat menyimpan data dan memulihkan dari kehilangan data?
Jika proses Redis atau server yang menjalankan Redis gagal, semua data di memori hilang kan? Jadi bagaimana data bertahan dan pada dasarnya bagaimana saya bisa yakin bahwa data saya aman?
Mereplikasi Redis?
Nah, cara termudah untuk memiliki cadangan data adalah dengan mereplikasi Redis . Jadi, jika instance master Redis mati, replika akan tetap berjalan dan memiliki semua data. Jadi, jika Anda memiliki Redis yang direplikasi, replika tersebut akan memiliki datanya.
Tapi tentu saja jika semua instance Redis turun Anda akan kehilangan data, karena tidak akan ada replika yang tersisa. Jadi kita membutuhkan ketekunan yang nyata .
Pemotretan &AOF
Redis memiliki beberapa mekanisme untuk mempertahankan data dan menjaga keamanan data.
Cuplikan
Yang pertama:snapshot, yang dapat Anda konfigurasikan berdasarkan waktu, jumlah permintaan, dll. Jadi snapshot data Anda akan disimpan di disk , yang dapat Anda gunakan untuk memulihkan data Anda jika seluruh database Redis hilang.
Namun perhatikan bahwa Anda akan kehilangan data menit terakhir , karena Anda biasanya melakukan snapshotting setiap lima menit atau satu jam tergantung kebutuhan Anda.
AOF
Jadi sebagai alternatif Redis menggunakan sesuatu yang disebut AOF , yang merupakan singkatan dari A ppend O hanya B file.
Dalam hal ini setiap perubahan disimpan ke disk agar tetap bertahan . Dan saat memulai ulang Redis atau setelah pemadaman, Redis akan memutar ulang log Append Only File untuk membangun kembali status.
Jadi AOF lebih tahan lama , tetapi bisa lebih lambat daripada memotret.
Opsi Terbaik :Gunakan kombinasi AOF dan snapshot, di mana AOF menyimpan data dari memori ke disk secara terus menerus ditambah Anda memiliki snapshot reguler di antaranya untuk menyimpan status data jika Anda perlu memulihkannya:

Bagaimana cara menskalakan database Redis?
Katakanlah instans 1 Redis saya kehabisan memori, sehingga data menjadi terlalu besar untuk disimpan dalam memori atau Redis menjadi hambatan dan tidak dapat menangani permintaan lagi. Dalam kasus seperti itu bagaimana cara menambah kapasitas dan ukuran memori untuk basis data Redis saya?
Kami memiliki beberapa opsi untuk itu:
1. Pengelompokan
Pertama-tama, Redis mendukung pengelompokan . Ini berarti Anda dapat memiliki instance Redis utama atau master, yang dapat digunakan untuk membaca dan menulis data dan Anda dapat memiliki beberapa replika instance utama tersebut untuk membaca data :
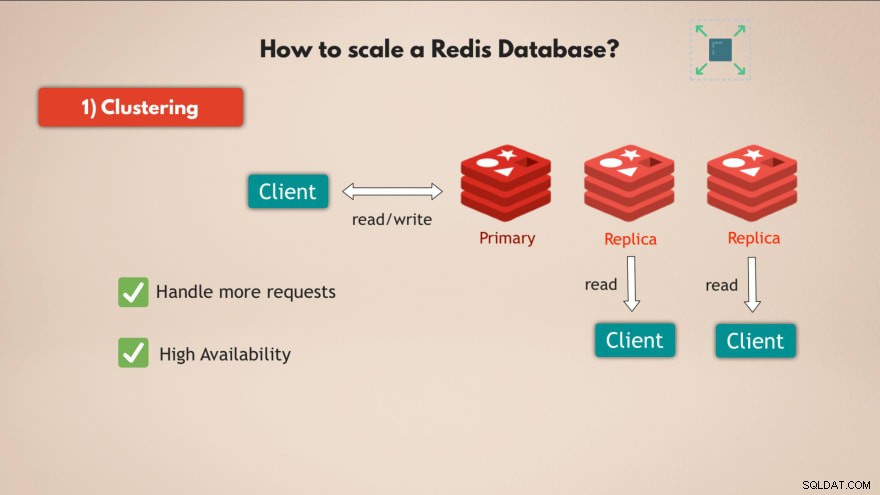
Dengan cara ini Anda dapat menskalakan Redis untuk menangani lebih banyak permintaan dan selain itu meningkatkan ketersediaan tinggi database Anda, karena jika master gagal, 1 replika dapat mengambil alih dan database Redis Anda pada dasarnya dapat terus berfungsi tanpa masalah.
2. Pecahan
Sepertinya itu cukup bagus, tapi bagaimana jika
- set data Anda bertambah terlalu besar untuk muat di memori di satu server .
- Selain itu, kami telah menskalakan pembacaan di database, jadi semua permintaan yang pada dasarnya hanya mengkueri data. Tetapi instance master kami masih sendiri dan masih harus menangani semua penulisan .
Jadi apa solusinya di sini?
Untuk itu kami menggunakan konsep sharding , yang merupakan konsep umum dalam database dan yang juga didukung oleh Redis.
Jadi berbagi pada dasarnya berarti Anda mengambil kumpulan data lengkap dan membaginya menjadi potongan atau subkumpulan data yang lebih kecil , di mana setiap pecahan bertanggung jawab atas subset datanya sendiri.
Jadi itu berarti alih-alih memiliki satu instans master yang menangani semua penulisan ke kumpulan data lengkap, Anda dapat membaginya menjadi katakanlah 4 shard, masing-masing bertanggung jawab untuk membaca dan menulis ke subset data .
Dan setiap pecahan juga membutuhkan kapasitas memori yang lebih sedikit , karena mereka hanya memiliki seperempat dari data. Ini berarti Anda dapat mendistribusikan dan menjalankan shard pada node yang lebih kecil dan pada dasarnya menskalakan cluster Anda secara horizontal:
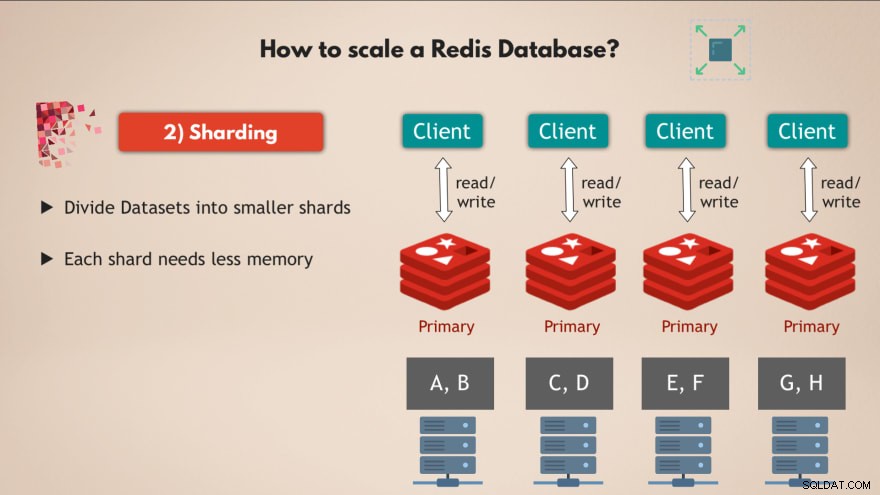
Jadi memiliki banyak node , yang menjalankan beberapa replika dari Redis yang semuanya di-sharding memberi Anda basis data Redis yang sangat berkinerja tinggi yang dapat menangani lebih banyak permintaan tanpa membuat hambatan apa pun 👍
Topik lainnya...
Lihat video saya di bawah untuk 2 topik dan skenario terakhir:
- Aplikasi yang membutuhkan ketersediaan dan kinerja yang lebih tinggi di beberapa lokasi geografis
- Standar baru untuk menjalankan layanan mikro adalah platform Kubernetes, jadi menjalankan Redis di Kubernetes adalah kasus penggunaan yang sangat menarik dan umum
Video lengkapnya ada di sini:
Semoga ini bermanfaat dan menarik bagi sebagian dari Anda! 😊
Suka, bagikan, dan ikuti saya 😍 untuk konten lainnya:
- Instagram - Memposting banyak hal di balik layar
- Grup FB pribadi
- Tertaut



