Dalam tutorial Hadoop kami sebelumnya , kami telah mempelajari Hadoop Partisi secara terperinci. Sekarang kita akan membahas InputSplit di Hadoop MapReduce.
Di sini, kita akan membahas apa itu Hadoop InputSplit, kebutuhan InputSplit di MapReduce. Kami juga akan membahas bagaimana InputSplits ini dibuat di Hadoop MapReduce dengan sangat rinci.
Pengantar InputSplit di Hadoop
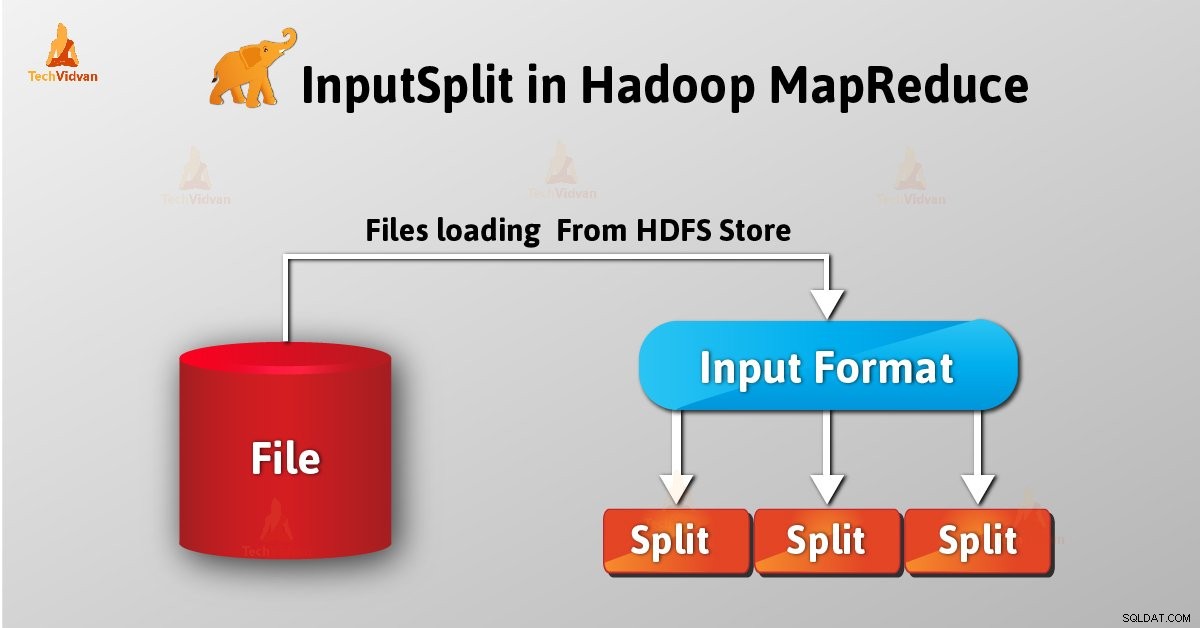
InputSplit adalah representasi logis dari data di Hadoop MapReduce. Ini mewakili data yang pemeta proses. Jadi jumlah tugas peta sama dengan jumlah InputSplits. Kerangka membagi dibagi menjadi catatan, yang proses mapper.
Panjang InputSplit MapReduce telah diukur dalam byte. Setiap InputSplit memiliki lokasi penyimpanan (string hostname). Sistem MapReduce menempatkan tugas peta sedekat mungkin dengan data split dengan menggunakan lokasi penyimpanan.
Kerangka proses Memetakan tugas dalam urutan ukuran pemisahan sehingga yang terbesar diproses terlebih dahulu (algoritma aproksimasi serakah). Ini meminimalkan waktu pengerjaan tugas.
Hal utama yang menjadi fokus adalah bahwa Inputsplit tidak berisi data input; itu hanya referensi ke data.
Bagaimana InputSplits dibuat di Hadoop MapReduce?
Sebagai pengguna, kami tidak menangani InputSplit di Hadoop secara langsung, sebagai InputFormat (karena InputFormat bertanggung jawab untuk membuat Inputsplit dan membaginya ke dalam catatan) membuatnya. FileInputFormat memecah file menjadi potongan 128MB.
Juga, dengan menyetel dipetakan .mnt .berpisah .ukuran parameter di situs yang dipetakan .xml pengguna dapat mengubah nilai sesuai kebutuhan. Juga dengan ini kita dapat mengganti parameter dalam objek Pekerjaan yang digunakan untuk mengirimkan pekerjaan MapReduce tertentu.
Dengan menulis InputFormat khusus, kami juga dapat mengontrol bagaimana file dipecah menjadi beberapa bagian.
InputSplit ditentukan pengguna. Pengguna juga dapat mengontrol ukuran split berdasarkan ukuran data dalam program MapReduce. Oleh karena itu, Dalam eksekusi pekerjaan MapReduce, jumlah tugas peta sama dengan jumlah InputSplits.
Dengan memanggil 'getSplit()' , klien menghitung pembagian untuk pekerjaan tersebut. Kemudian dikirim ke master aplikasi, yang menggunakan lokasi penyimpanannya untuk menjadwalkan tugas peta yang akan memprosesnya di cluster.
Setelah tugas peta itu meneruskan pemisahan ke createRecordReader() metode. Dari situ ia memperoleh RecordReader untuk perpecahan. Kemudian RecordReader menghasilkan catatan (pasangan nilai kunci) , yang diteruskan ke fungsi peta.
Kesimpulan
Sebagai kesimpulan, kita dapat mengatakan bahwa, InputSplit mewakili data yang diproses oleh masing-masing mapper. Untuk setiap pemisahan, satu tugas peta dibuat. Oleh karena itu, InputFormat membuat InputSplit.
Jika Anda memiliki pertanyaan tentang InputSplit di MapReduce, silakan tinggalkan komentar di bagian yang diberikan di bawah ini.



