Dalam tutorial Hadoop data besar , kami akan memberi Anda deskripsi terperinci tentang blok data Hadoop HDFS. Pertama-tama, kita akan membahas apa itu blok data di Hadoop, apa pentingnya, mengapa ukuran blok data HDFS adalah 128MB.
Kami juga akan membahas contoh blok data di hadoop dan berbagai kelebihan HDFS di Hadoop.
Pengantar Blok Data HDFS
HDFS Hadoop membagi file besar menjadi potongan-potongan kecil yang dikenal sebagai Blok . Blok adalah representasi fisik dari data. Ini berisi jumlah minimum data yang dapat dibaca atau ditulis. HDFS menyimpan setiap file sebagai blok. Klien HDFS tidak memiliki kontrol apa pun di blok seperti lokasi blok, Namenode memutuskan semua hal seperti itu.
Secara default, ukuran blok HDFS adalah 128MB yang dapat Anda ubah sesuai kebutuhan Anda. Semua blok HDFS berukuran sama kecuali blok terakhir, yang bisa berukuran sama atau lebih kecil.
Kerangka kerja Hadoop memecah file menjadi blok 128 MB dan kemudian menyimpannya ke dalam sistem file Hadoop. Aplikasi Apache Hadoop bertanggung jawab untuk mendistribusikan blok data di beberapa node.
Contoh-
Misalkan ukuran file adalah 513MB, dan kita menggunakan konfigurasi default ukuran blok 128MB. Kemudian, kerangka Hadoop akan membuat 5 blok, empat blok pertama 128MB, tetapi blok terakhir hanya 1MB.
Oleh karena itu dari contoh jelas bahwa dalam HDFS setiap file yang disimpan tidak harus merupakan kelipatan tepat dari ukuran blok yang dikonfigurasi 128mb, 256mb, dll. Oleh karena itu, blok terakhir untuk file hanya menggunakan ruang sebanyak yang diperlukan.
Mengapa Blok HDFS berukuran 128 MB?
HDFS menyimpan terabyte dan petabyte data. Jika ukuran Blok HDFS adalah 4kb seperti sistem file Linux, maka kita akan memiliki terlalu banyak blok data di Hadoop HDFS, sehingga terlalu banyak metadata.
Jadi, memelihara dan mengelola sejumlah besar blok dan metadata ini akan menciptakan overhead dan lalu lintas yang besar yang merupakan sesuatu yang tidak kita inginkan.
Ukuran blok tidak boleh terlalu besar sehingga sistem menunggu sangat lama untuk satu unit pemrosesan data terakhir untuk menyelesaikan pekerjaannya.
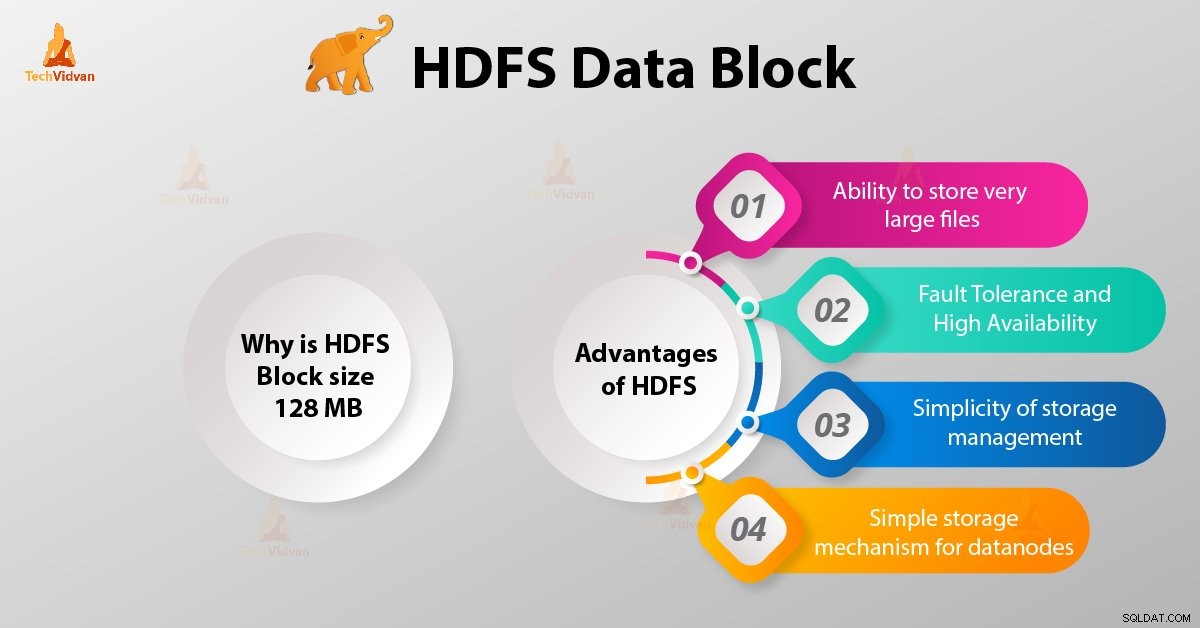
Keuntungan HDFS
Setelah mengetahui apa itu HDFS Data Block, sekarang mari kita bahas keunggulan Hadoop HDFS.
1. Kemampuan untuk menyimpan file yang sangat besar
Hadoop HDFS menyimpan file yang sangat besar yang bahkan lebih besar dari ukuran satu disk karena kerangka kerja Hadoop memecah file menjadi blok dan mendistribusikan ke berbagai node.
2. Toleransi kesalahan dan Ketersediaan HDFS yang Tinggi
Kerangka kerja Hadoop dapat dengan mudah mereplikasi Blok antara datanode. Dengan demikian, berikan toleransi kesalahan dan ketersediaan tinggi HDFS.
3. Kesederhanaan manajemen penyimpanan
Karena HDFS memiliki ukuran blok tetap (128MB), jadi sangat mudah untuk menghitung jumlah blok yang dapat disimpan di disk.
4. Mekanisme Penyimpanan sederhana untuk datanodes
Blok di HDFS menyederhanakan penyimpanan Datanodes . Node Nama memelihara metadata dari semua blok. HDFS Datanode tidak perlu khawatir tentang metadata blok seperti izin file, dll.
Kesimpulan
Oleh karena itu, blok data HDFS adalah unit data terkecil dalam sistem file. Ukuran default Blok HDFS adalah 128MB yang dapat Anda konfigurasikan sesuai kebutuhan. Blok HDFS mudah direplikasi di antara datanode. Oleh karena itu, berikan toleransi kesalahan dan ketersediaan HDFS yang tinggi.
Untuk pertanyaan atau saran apa pun yang terkait dengan blok data Hadoop HDFS, beri tahu kami dengan meninggalkan komentar di bagian yang diberikan di bawah ini.



