Menjalankan Galera Cluster di hybrid cloud harus terdiri dari setidaknya dua situs geografis yang berbeda, menghubungkan host di lokal atau cloud pribadi dengan yang ada di cloud publik. Baik Anda menggunakan cloud pribadi yang tidak dapat dipecahkan atau platform cloud publik, Pemulihan Bencana (DR) memang merupakan masalah utama. Ini bukan tentang menyalin data Anda ke situs cadangan dan dapat memulihkannya, ini tentang kelangsungan bisnis dan seberapa cepat Anda dapat memulihkan layanan saat terjadi bencana.
Dalam posting blog ini, kita akan melihat berbagai cara merancang Cluster Galera Anda untuk toleransi kesalahan dalam lingkungan cloud hybrid.
Pengaturan Aktif-Aktif
Galera Cluster harus berjalan dengan jumlah node ganjil dalam sebuah cluster, dan biasanya dimulai dengan 3 node. Ini karena Galera Cluster menggunakan kuorum untuk secara otomatis menentukan komponen utama, di mana mayoritas node yang terhubung harus dapat melayani cluster pada satu waktu, jika terjadi partisi cluster.
Untuk penyiapan hybrid cloud penyiapan aktif-aktif, Galera memerlukan setidaknya 3 situs berbeda, membentuk Galera Cluster di seluruh WAN. Umumnya, Anda memerlukan situs ketiga untuk bertindak sebagai arbiter, memberikan suara untuk kuorum dan mempertahankan "komponen utama" jika salah satu situs tidak dapat dijangkau. Ini dapat diatur sebagai minimal cluster 3-node di 3 situs berbeda (1 node per situs), mirip dengan diagram berikut:
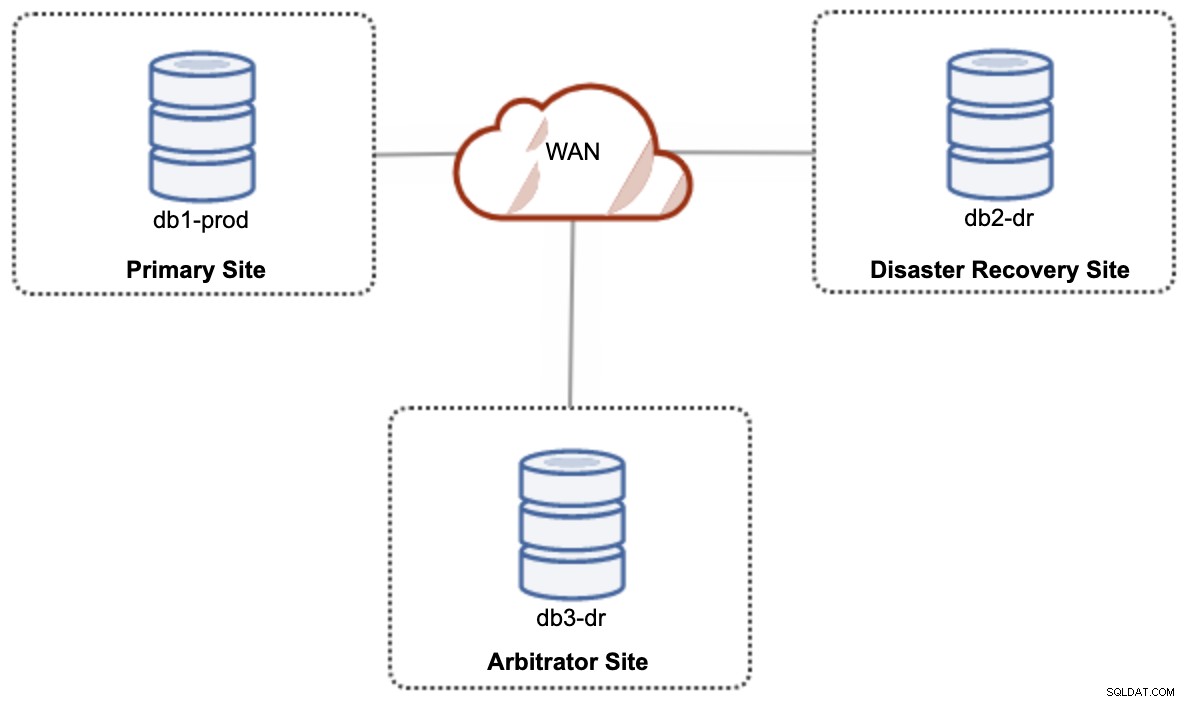
Namun, untuk tujuan kinerja dan keandalan, disarankan untuk memiliki 7 -node cluster, seperti yang ditunjukkan pada diagram berikut:
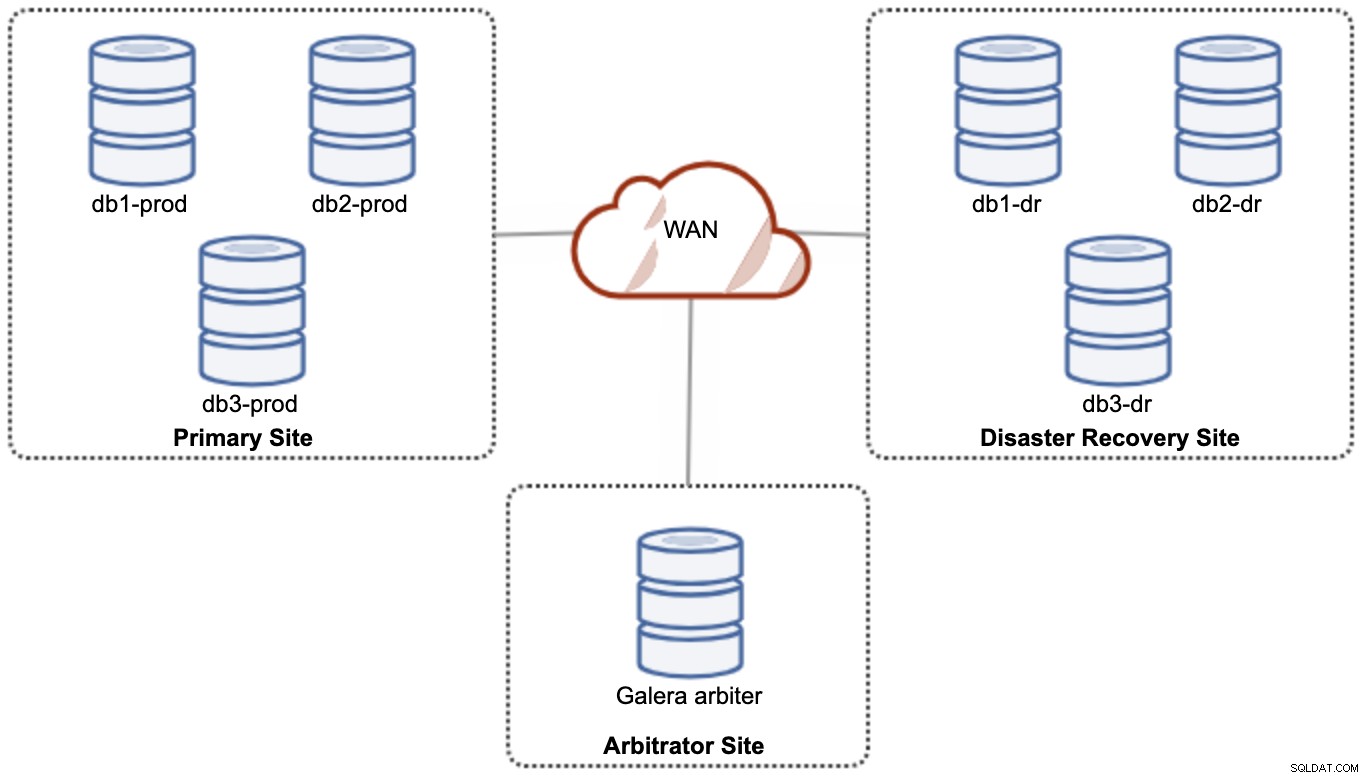
Ini dianggap sebagai topologi terbaik untuk mendukung penyiapan aktif-aktif, di mana situs DR harus segera tersedia, tanpa intervensi apa pun. Kedua situs dapat menerima pembacaan/penulisan kapan saja asalkan cluster berada dalam kuorum.
Namun, sangat mahal untuk memiliki 3 situs, dan 7 node basis data (node ke-7 dapat diganti dengan garbd karena sangat tidak mungkin digunakan untuk menyajikan data ke klien/aplikasi). Ini biasanya bukan penerapan yang populer di awal proyek karena biaya awal yang besar dan seberapa sensitif komunikasi dan replikasi grup Galera terhadap latensi jaringan.
Pengaturan Aktif-Pasif
Dalam konfigurasi aktif-pasif, minimal 2 situs diperlukan dan hanya satu situs yang aktif pada satu waktu, yang dikenal sebagai situs utama dan node di situs sekunder hanya mereplikasi data yang berasal dari primer server/kluster. Untuk Galera Cluster, kita dapat menggunakan replikasi asinkron MySQL (replikasi master-slave) atau kita juga dapat menggunakan replikasi virtual-sinkron Galera dengan beberapa penyesuaian untuk mengurangi replikasi writeset agar bertindak sebagai replikasi asinkron.
Situs sekunder harus dilindungi dari penulisan yang tidak disengaja, dengan menggunakan tanda baca-saja, firewall aplikasi, proxy terbalik, atau cara lain apa pun karena aliran data selalu datang dari situs primer ke situs sekunder kecuali failover telah memulai dan mempromosikan situs sekunder sebagai situs utama.
Menggunakan replikasi asinkron
Hal yang baik tentang replikasi asinkron adalah bahwa replikasi tidak memengaruhi server/cluster sumber, tetapi dibiarkan tertinggal di belakang master. Penyiapan ini akan membuat situs utama dan DR independen satu sama lain, terhubung secara longgar dengan replikasi asinkron. Ini dapat diatur sebagai minimal cluster 4-simpul di 2 situs yang berbeda, mirip dengan diagram berikut:
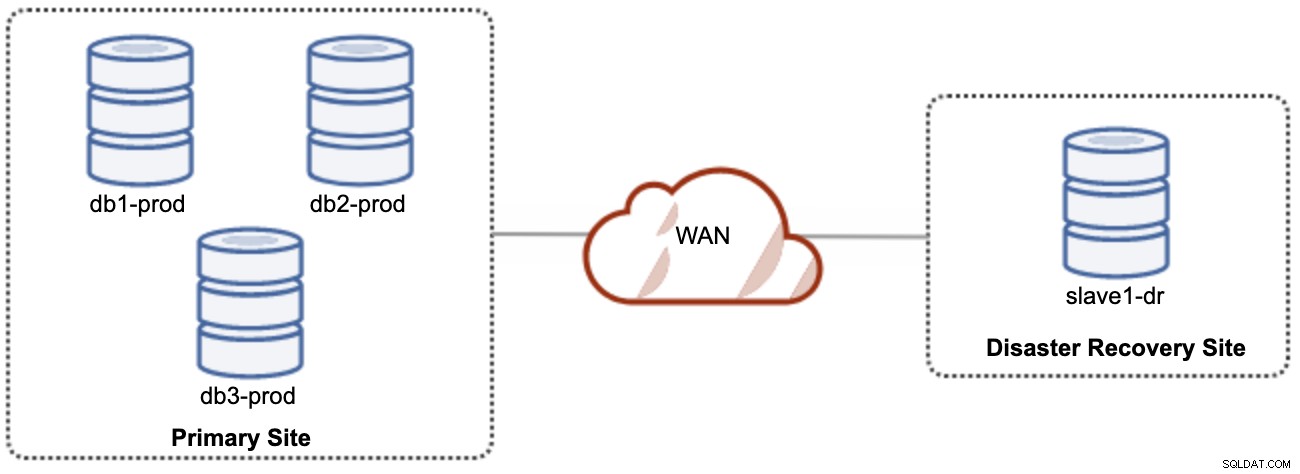
Salah satu node Galera di situs DR akan menjadi budak, yang mereplikasi dari salah satu node Galera (master) di situs utama. Kedua situs harus menghasilkan log biner dengan GTID dan log_slave_updates diaktifkan - pembaruan yang berasal dari aliran replikasi asinkron akan diterapkan ke node lain dalam cluster. Namun, untuk penggunaan produksi, kami merekomendasikan memiliki dua set cluster di kedua situs, seperti yang ditunjukkan pada diagram berikut:
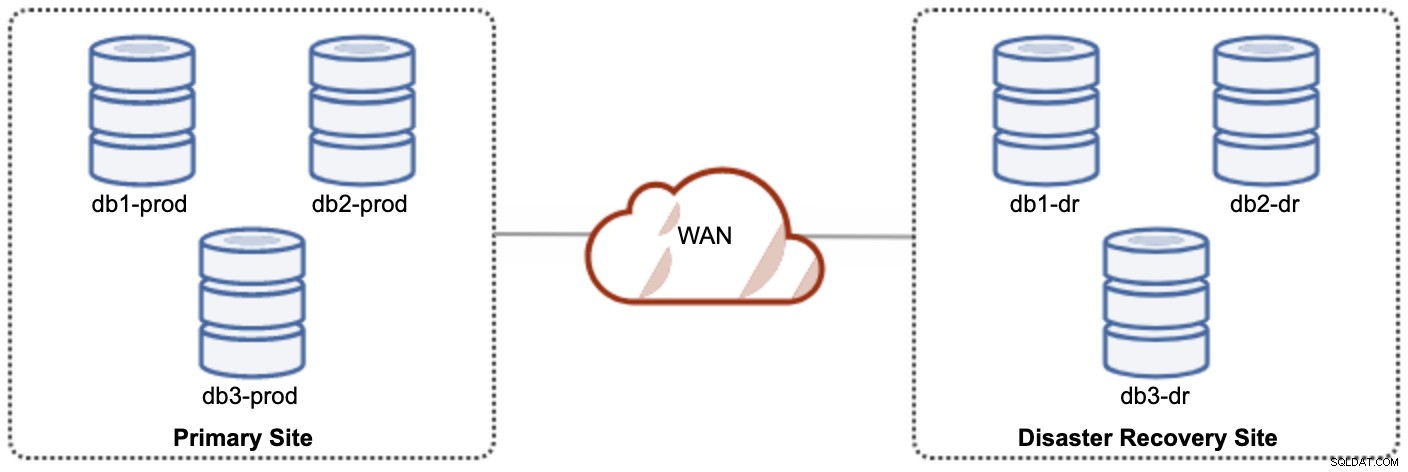
Dengan memiliki dua cluster terpisah, mereka akan digabungkan secara longgar dan tidak saling memengaruhi, mis. kegagalan cluster di situs utama tidak akan memengaruhi situs DR. Dari segi kinerja, latensi WAN tidak akan memengaruhi pembaruan pada cluster aktif. Ini dikirim secara asinkron ke situs cadangan. Cluster DR berpotensi berjalan pada instance yang lebih kecil di lingkungan cloud publik, selama mereka dapat mengikuti cluster utama. Instance dapat ditingkatkan jika diperlukan. Aplikasi harus mengirim penulisan ke situs utama, dan situs sekunder harus diatur untuk berjalan dalam mode baca-saja. Situs pemulihan bencana dapat digunakan untuk tujuan lain seperti pencadangan basis data, pencadangan log biner, dan pelaporan atau pemrosesan kueri analitis (OLAP).
Pada sisi negatifnya, ada kemungkinan kehilangan data selama failover/fallback jika slave tertinggal. Oleh karena itu, disarankan untuk mengaktifkan replikasi semi-sinkron untuk menurunkan risiko kehilangan data. Perhatikan bahwa menggunakan replikasi semi-sinkron masih tidak memberikan jaminan yang kuat terhadap kehilangan data, jika dibandingkan dengan replikasi hampir-sinkron Galera. Baca manual MySQL ini dengan seksama, misalnya kalimat berikut:
"Dengan replikasi semisinkron, jika sumber crash dan failover ke replika dilakukan, sumber yang gagal tidak boleh digunakan kembali sebagai sumber replikasi, dan harus dibuang. Ini bisa memiliki transaksi yang tidak diakui oleh replika apa pun, yang karenanya tidak dilakukan sebelum failover."
Proses failover cukup mudah. Untuk mempromosikan situs pemulihan bencana, cukup matikan tanda baca-saja dan mulai arahkan aplikasi ke node database di situs DR. Strategi fallback agak rumit, dan memerlukan beberapa keahlian dalam mengatur data di kedua situs, mengalihkan peran master/slave dari sebuah cluster, dan mengarahkan kembali aliran replikasi slave ke cara yang berlawanan.
Menggunakan Replikasi Galera
Untuk penyiapan aktif-pasif, kita dapat menempatkan sebagian besar node yang terletak di situs utama sedangkan sebagian kecil node yang terletak di situs pemulihan bencana, seperti yang ditunjukkan pada tangkapan layar berikut untuk 3- simpul Galera Cluster:
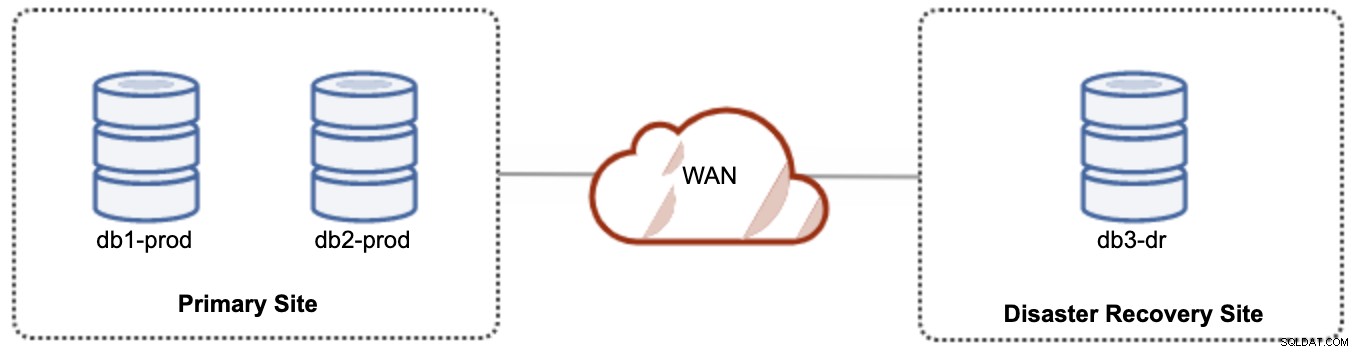
Jika situs utama tidak aktif, cluster akan gagal karena tidak memenuhi kuorum. Node Galera di situs pemulihan bencana (db3-dr) perlu di-bootstrap secara manual sebagai komponen utama node tunggal. Setelah situs utama muncul kembali, kedua node di situs utama (db1-prod dan db2-prod) perlu bergabung kembali dengan galera3 untuk disinkronkan. Memiliki gcache yang cukup besar akan membantu mengurangi risiko SST melalui WAN. Arsitektur ini mudah diatur dan dikelola serta sangat hemat biaya.
Failover bersifat manual, karena administrator perlu mempromosikan node tunggal sebagai komponen utama (bootstrap db3-dr atau gunakan set pc.bootstrap=1 dalam parameter wsrep_provider_options. Akan ada waktu henti sementara itu Performa mungkin menjadi masalah, karena situs DR akan berjalan dengan jumlah node yang lebih sedikit (karena situs DR selalu menjadi minoritas) untuk menjalankan semua beban. Dimungkinkan untuk menskalakan dengan lebih banyak node setelah beralih ke Situs DR tetapi waspadalah terhadap beban tambahan.
Perhatikan bahwa Galera Cluster sensitif terhadap jaringan karena sifatnya yang hampir sinkron. Semakin jauh node Galera berada dalam cluster tertentu, semakin tinggi latensi dan kemampuan tulisnya untuk mendistribusikan dan mensertifikasi set tulis. Juga, jika konektivitas tidak stabil, partisi cluster dapat dengan mudah terjadi, yang dapat memicu sinkronisasi cluster pada node joiner. Dalam beberapa kasus, ini dapat menyebabkan ketidakstabilan pada cluster. Ini memerlukan sedikit penyetelan pada parameter Galera, seperti yang ditunjukkan dalam posting blog ini, Menyebarkan Lingkungan Infrastruktur Hibrida untuk Cluster Percona XtraDB.
Pemikiran Terakhir
Galera Cluster adalah teknologi hebat yang dapat diterapkan dalam berbagai cara - satu cluster membentang di beberapa situs, beberapa cluster tetap sinkron melalui replikasi asinkron, campuran replikasi sinkron dan asinkron, dan seterusnya. Solusi sebenarnya akan ditentukan oleh faktor-faktor seperti latensi WAN, konsistensi data dan anggaran yang akhirnya versus yang kuat.