Di blog kami sebelumnya, kami membuat alasan mengapa Anda memerlukan failover database dan menjelaskan cara kerja mekanisme failover. Saya membagikan ini jika Anda memiliki pertanyaan tentang mengapa Anda harus mengatur mekanisme failover untuk database MySQL Anda. Jika ya, silakan baca posting blog kami sebelumnya.
Cara Menyetel Kegagalan Otomatis
Keuntungan menggunakan MySQL atau MariaDB untuk mengelola failover Anda secara otomatis adalah tersedianya alat yang dapat Anda gunakan dan terapkan di lingkungan Anda. Dari yang open source hingga solusi kelas perusahaan. Sebagian besar alat tidak hanya mampu failover, ada fitur lain seperti peralihan, pemantauan, dan fitur lanjutan yang dapat menawarkan lebih banyak kemampuan manajemen untuk cluster database MySQL Anda. Di bawah ini, kami akan membahas yang paling umum yang dapat Anda gunakan.
Menggunakan MHA (Ketersediaan Tinggi Master)
Kami telah membahas topik ini dengan MHA dengan masalah paling umum dan cara memperbaikinya. Kami juga telah membandingkan MHA dengan MRM atau dengan MaxScale.
Menyiapkan dengan MHA untuk ketersediaan tinggi mungkin tidak mudah tetapi efisien untuk digunakan dan fleksibel karena ada parameter yang dapat disesuaikan yang dapat Anda tentukan untuk menyesuaikan failover Anda. MHA telah diuji dan digunakan. Namun seiring kemajuan teknologi, MHA tertinggal karena tidak mendukung GTID untuk MariaDB dan tidak mendorong pembaruan apa pun selama 2 atau 3 tahun terakhir.
Dengan menjalankan skrip masterha_manager,
masterha_manager --conf=/etc/app1.cnfDi mana contoh /etc/app1.cnf akan terlihat seperti berikut,
[server default]
user=cmon
password=pass
ssh_user=root
# working directory on the manager
manager_workdir=/var/log/masterha/app1
# working directory on MySQL servers
remote_workdir=/var/log/masterha/app1
[server1]
hostname=node1
candidate_master=1
[server2]
hostname=node2
candidate_master=1
[server3]
hostname=node3
no_master=1Parameter seperti no_master dan Candidate_master akan sangat penting saat Anda menetapkan daftar putih node yang diinginkan menjadi master target dan node yang tidak ingin Anda jadikan master.
Setelah disetel, Anda siap untuk melakukan failover untuk database MySQL Anda jika terjadi kegagalan pada primer atau master. Skrip masterha_manager mengelola failover (otomatis atau manual), mengambil keputusan tentang kapan dan di mana failover, dan mengelola pemulihan slave selama promosi calon master untuk menerapkan log relai diferensial. Jika database master mati, MHA Manager akan berkoordinasi dengan agen MHA Node karena menerapkan log relai diferensial ke budak yang tidak memiliki peristiwa binlog terbaru dari master.
Lihat apa yang dilakukan agen MHA Node dan skripnya yang terlibat. Pada dasarnya, ini adalah skrip yang akan dipanggil oleh Manajer MHA saat terjadi failover. Itu akan menunggu mandatnya dari MHA Manager saat mencari budak terbaru yang berisi peristiwa binlog dan menyalin peristiwa yang hilang dari budak menggunakan scp dan menerapkannya ke dirinya sendiri. Seperti yang disebutkan, ini menerapkan log relai, membersihkan log relai, atau menyimpan log biner.
Jika Anda ingin tahu lebih banyak tentang parameter yang dapat disetel dan cara menyesuaikan manajemen failover Anda, periksa halaman wiki Parameter untuk MHA.
Menggunakan Orkestra
Orchestrator adalah alat manajemen replikasi dan ketersediaan tinggi MySQL dan MariaDB. Ini dirilis oleh Shlomi Noach di bawah persyaratan Lisensi Apache, versi 2.0. Ini adalah perangkat lunak open source dan menangani failover otomatis tetapi ada banyak hal yang dapat Anda sesuaikan atau lakukan untuk mengelola database MySQL/MariaDB Anda selain dari pemulihan atau failover otomatis.
Menginstal Orchestrator dapat dilakukan dengan mudah atau langsung. Setelah Anda mengunduh paket spesifik yang diperlukan untuk lingkungan target Anda, Anda kemudian siap untuk mendaftarkan cluster dan node Anda untuk dipantau oleh Orchestrator. Ini menyediakan UI yang sangat mudah untuk dikelola tetapi memiliki banyak parameter yang dapat disesuaikan atau serangkaian perintah yang dapat Anda gunakan untuk mencapai manajemen failover Anda.
Mari kita pertimbangkan bahwa Anda akhirnya telah menyiapkan dan Mendaftarkan cluster dengan menambahkan node utama atau master kami dapat dilakukan dengan perintah di bawah ini,
$ orchestrator -c discover -i pupnode21:3306
2021-01-07 12:32:31 DEBUG Hostname unresolved yet: pupnode21
2021-01-07 12:32:31 DEBUG Cache hostname resolve pupnode21 as pupnode21
2021-01-07 12:32:31 DEBUG Connected to orchestrator backend: orchestrator:example@sqldat.com(127.0.0.1:3306)/orchestrator?timeout=1s
2021-01-07 12:32:31 DEBUG Orchestrator pool SetMaxOpenConns: 128
2021-01-07 12:32:31 DEBUG Initializing orchestrator
2021-01-07 12:32:31 INFO Connecting to backend 127.0.0.1:3306: maxConnections: 128, maxIdleConns: 32
2021-01-07 12:32:31 DEBUG Hostname unresolved yet: 192.168.40.222
2021-01-07 12:32:31 DEBUG Cache hostname resolve 192.168.40.222 as 192.168.40.222
2021-01-07 12:32:31 DEBUG Hostname unresolved yet: 192.168.40.223
2021-01-07 12:32:31 DEBUG Cache hostname resolve 192.168.40.223 as 192.168.40.223
pupnode21:3306Sekarang, cluster kami telah ditambahkan.
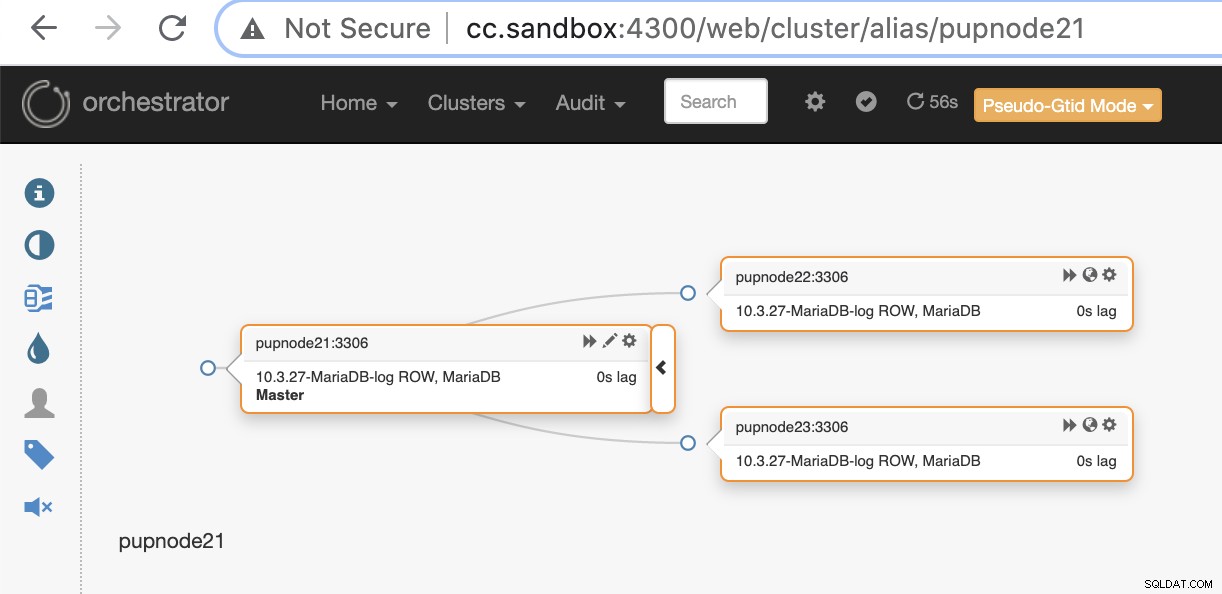
Jika node utama gagal (kegagalan perangkat keras atau mengalami crash), Orchestrator akan mendeteksi dan menemukan node paling canggih untuk dipromosikan sebagai node utama atau master.
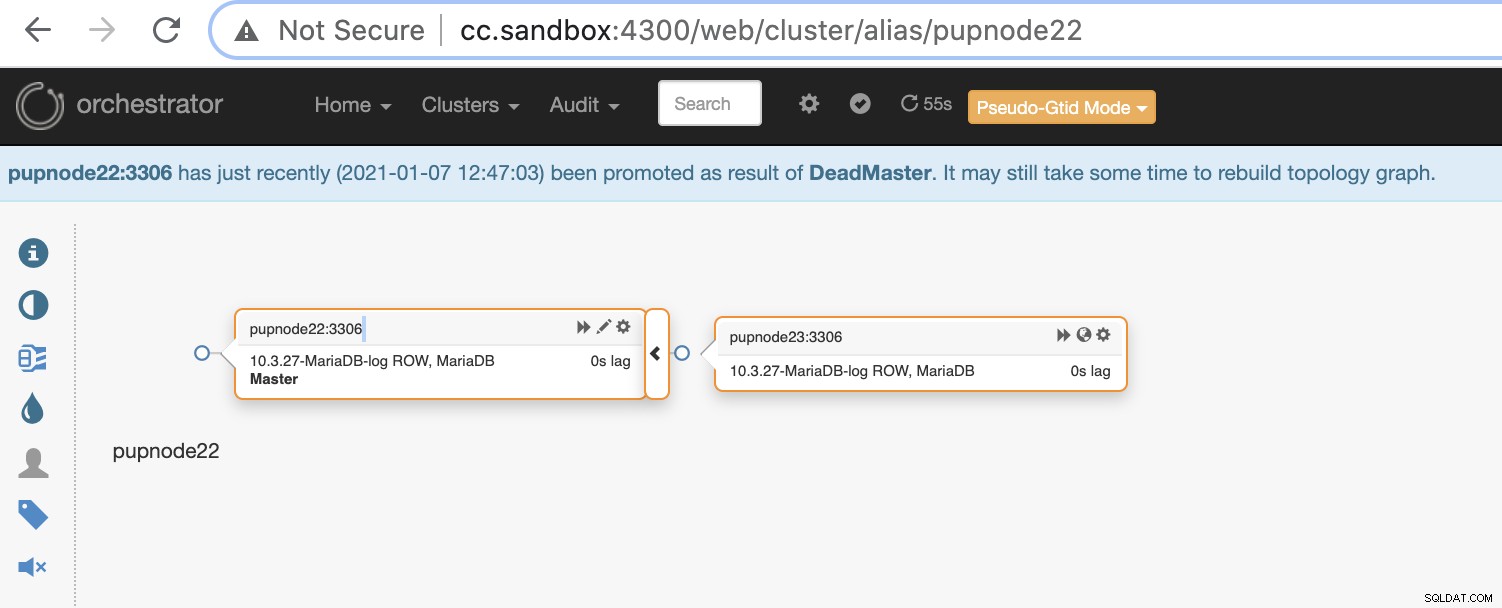
Sekarang, kami memiliki dua node yang tersisa di cluster sementara yang utama tidak aktif .
$ orchestrator-client -c topology -i pupnode21:3306
pupnode21:3306 [unknown,invalid,10.3.27-MariaDB-log,rw,ROW,>>,downtimed]
$ orchestrator-client -c topology -i pupnode22:3306
pupnode22:3306 [0s,ok,10.3.27-MariaDB-log,rw,ROW,>>]
+ pupnode23:3306 [0s,ok,10.3.27-MariaDB-log,ro,ROW,>>,GTID]Menggunakan MaxScale
MariaDB MaxScale telah didukung sebagai penyeimbang beban basis data. Selama bertahun-tahun MaxScale telah tumbuh dan matang, diperluas dengan beberapa fitur yang kaya dan itu termasuk failover otomatis. Sejak MariaDB MaxScale 2.2 dirilis, ia memperkenalkan beberapa fitur baru termasuk manajemen failover cluster replikasi. Anda dapat membaca blog kami sebelumnya mengenai mekanisme failover MaxScale.
Menggunakan MaxScale di bawah BSL meskipun perangkat lunaknya tersedia secara bebas tetapi mengharuskan Anda untuk setidaknya membeli layanan dengan MariaDB. Ini mungkin tidak cocok tetapi jika Anda telah memperoleh layanan perusahaan MariaDB, maka ini bisa menjadi keuntungan besar jika Anda memerlukan manajemen failover dan fitur lainnya.
Instalasi MaxScale itu mudah, tetapi pengaturan konfigurasi yang diperlukan dan menentukan parameternya tidak mudah, dan Anda harus memahami perangkat lunaknya. Anda dapat merujuk ke panduan konfigurasinya.
Untuk penerapan cepat dan cepat, Anda dapat menggunakan ClusterControl untuk menginstal MaxScale untuk Anda di lingkungan MySQL/MariaDB yang ada.
Setelah terinstal, pengaturan database Moodle Anda dapat dilakukan dengan mengarahkan host Anda ke IP MaxScale atau nama host dan port baca-tulis. Misalnya,
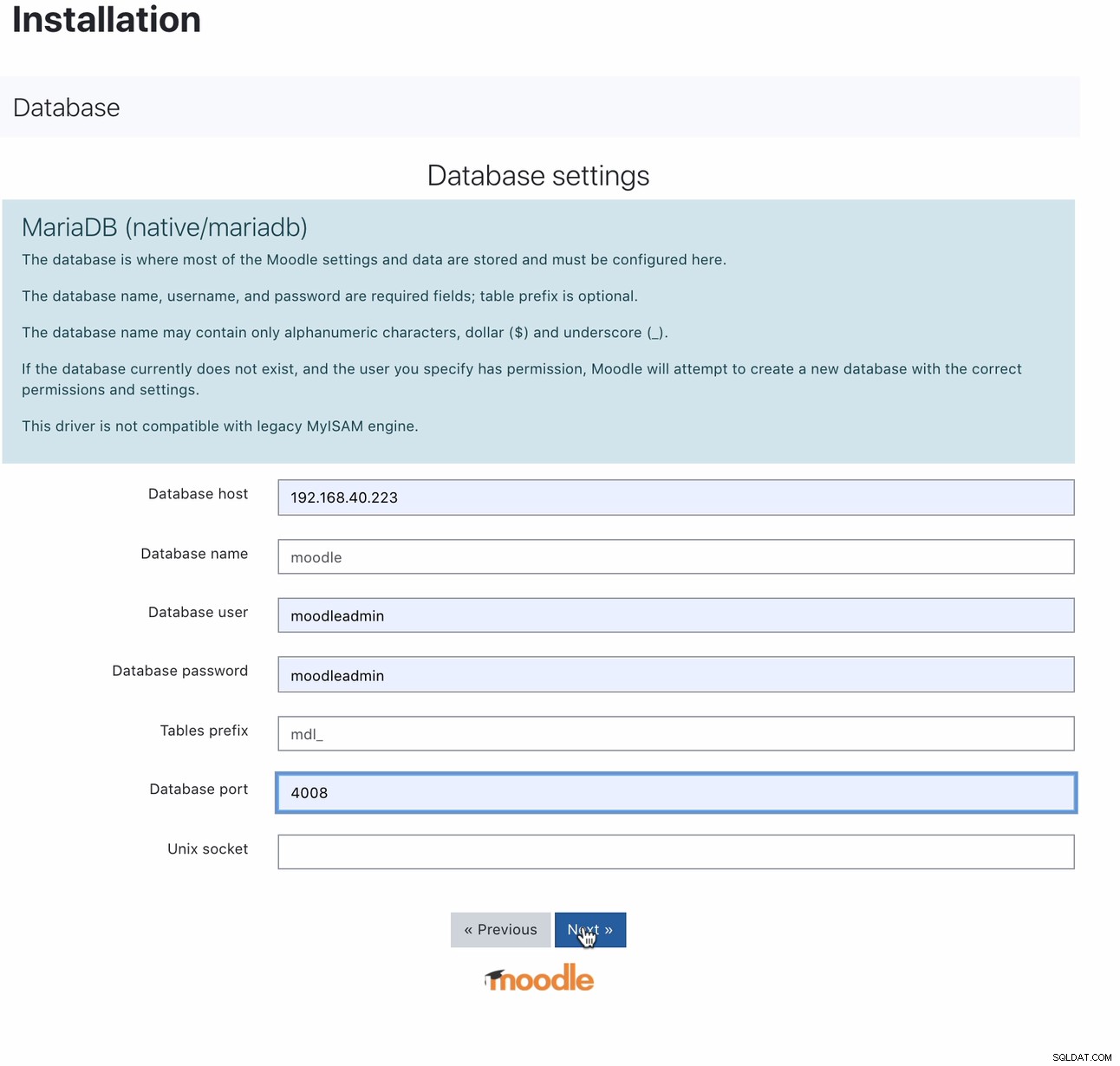
Untuk port 4008 mana yang merupakan baca-tulis Anda untuk pendengar layanan Anda. Misalnya, berikut konfigurasi layanan dan pendengar untuk MaxScale saya.
$ cat maxscale.cnf.d/rw-listener.cnf
[rw-listener]
type=listener
protocol=mariadbclient
service=rw-service
address=0.0.0.0
port=4008
authenticator=MySQLAuth
$ cat maxscale.cnf.d/rw-service.cnf
[rw-service]
type=service
servers=DB_123,DB_122,DB_124
router=readwritesplit
user=maxscale_adm
password=42BBD2A4DC1BF9BE05C41A71DEEBDB70
max_slave_connections=100%
max_sescmd_history=15000000
causal_reads=true
causal_reads_timeout=10
transaction_replay=true
transaction_replay_max_size=32Mi
delayed_retry=true
master_reconnection=true
max_connections=0
connection_timeout=0
use_sql_variables_in=master
master_accept_reads=true
disable_sescmd_history=falseSaat dalam konfigurasi monitor, Anda tidak boleh lupa untuk mengaktifkan failover otomatis atau juga mengaktifkan auto rejoin jika Anda ingin master sebelumnya gagal auto rejoin saat kembali online. Ini berjalan seperti ini,
$ egrep -r 'auto|^\[' maxscale.cnf.d/replication_monitor.cnf
[replication_monitor]
auto_failover=true
auto_rejoin=1Perhatikan bahwa variabel yang saya nyatakan tidak dimaksudkan untuk penggunaan produksi tetapi hanya untuk posting blog dan tujuan pengujian ini. Hal yang baik dengan MaxScale, setelah utama atau master turun, MaxScale cukup pintar untuk mempromosikan kandidat yang ideal atau terbaik untuk mengambil peran master. Oleh karena itu, tidak perlu mengubah IP dan port Anda karena kami telah menggunakan host/IP node MaxScale kami dan portnya sebagai titik akhir kami setelah master turun. Misalnya,
[192.168.40.223:6603] MaxScale> list servers
┌────────┬────────────────┬──────┬─────────────┬─────────────────┬──────────────────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_124 │ 192.168.40.223 │ 3306 │ 0 │ Slave, Running │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_123 │ 192.168.40.221 │ 3306 │ 0 │ Master, Running │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_122 │ 192.168.40.222 │ 3306 │ 0 │ Slave, Running │ 3-2003-876,5-2001-219541 │
└────────┴────────────────┴──────┴─────────────┴─────────────────┴──────────────────────────┘Node DB_123 yang menunjuk ke 192.168.40.221 adalah master saat ini. Mengakhiri node DB_123 akan memicu MaxScale untuk melakukan failover dan akan terlihat seperti ini,
[192.168.40.223:6603] MaxScale> list servers
┌────────┬────────────────┬──────┬─────────────┬─────────────────┬──────────────────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_124 │ 192.168.40.223 │ 3306 │ 0 │ Slave, Running │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_123 │ 192.168.40.221 │ 3306 │ 0 │ Down │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_122 │ 192.168.40.222 │ 3306 │ 0 │ Master, Running │ 3-2003-876,5-2001-219541 │
└────────┴────────────────┴──────┴─────────────┴─────────────────┴──────────────────────────┘Sementara, database Moodle kami masih aktif dan berjalan karena MaxScale kami menunjuk ke master terbaru yang dipromosikan.
$ mysql -hmaxscale.local.domain -umoodleuser -pmoodlepassword -P4008
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 9
Server version: 10.3.27-MariaDB-log MariaDB Server
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [(none)]> select @@hostname;
+------------+
| @@hostname |
+------------+
| 192.168.40.222 |
+------------+
1 row in set (0.001 sec)Menggunakan ClusterControl
ClusterControl dapat diunduh secara gratis dan menawarkan lisensi untuk Komunitas, Tingkat Lanjut, dan Perusahaan. Failover otomatis hanya tersedia di Advance dan Enterprise. Kegagalan otomatis tercakup dalam fitur Pemulihan Otomatis kami yang mencoba memulihkan kluster yang gagal atau node yang gagal. Jika Anda ingin detail lebih lanjut tentang cara melakukan ini, lihat posting kami sebelumnya Bagaimana ClusterControl Melakukan Pemulihan dan Kegagalan Basis Data Otomatis. Ini menawarkan parameter merdu yang sangat nyaman dan mudah digunakan. Silakan baca juga postingan kami sebelumnya tentang Cara Mengotomatiskan Failover Database dengan ClusterControl.
Mengelola failover otomatis untuk database Moodle Anda setidaknya harus memerlukan IP virtual (VIP) sebagai titik akhir untuk klien aplikasi Moodle yang menghubungkan backend database Anda. Untuk melakukan ini, Anda dapat menggunakan Keepalive dengan HAProxy (atau ProxySQL--tergantung pada pilihan penyeimbang beban Anda) di atasnya. Dalam hal ini, titik akhir basis data Moodle Anda akan mengarah ke IP virtual, yang pada dasarnya ditetapkan oleh Keepalive setelah Anda menerapkannya, sama seperti yang kami tunjukkan sebelumnya saat menyiapkan MaxScale. Anda juga dapat memeriksa blog ini tentang cara melakukannya.
Seperti disebutkan di atas, tersedia parameter yang dapat diatur yang dapat Anda atur melalui /etc/cmon.d/cmon_
- replication_check_binlog_filtration_bf_failover
- replication_check_external_bf_failover
- replication_failed_reslave_failover_script
- replication_failover_blacklist
- replication_failover_events
- replication_failover_wait_to_apply_timeout
- replication_failover_whitelist
- replication_onfail_failover_script
- Replication_post_failover_script
- replication_post_unsuccessful_failover_script
- replication_pre_failover_script
- replication_skip_apply_missing_txs
- replication_stop_on_error
ClusterControl sangat fleksibel saat mengelola failover sehingga Anda dapat melakukan beberapa tugas sebelum atau sesudah failover.
Kesimpulan
Ada pilihan bagus lainnya saat menyiapkan dan mengelola failover Anda secara otomatis untuk database MySQL Anda untuk Moodle. Itu tergantung pada anggaran Anda dan untuk apa Anda mungkin harus mengeluarkan uang. Menggunakan yang open source membutuhkan keahlian dan memerlukan beberapa pengujian untuk membiasakan diri karena tidak ada dukungan yang dapat Anda jalankan saat Anda membutuhkan bantuan selain komunitas. Dengan solusi perusahaan, ia datang dengan harga tetapi menawarkan dukungan dan kemudahan karena pekerjaan yang memakan waktu dapat dikurangi. Perhatikan bahwa jika failover digunakan secara keliru, dapat menyebabkan kerusakan pada database Anda jika tidak ditangani dan dikelola dengan benar. Fokus pada apa yang lebih penting dan bagaimana Anda mampu solusi yang Anda gunakan untuk mengelola failover database Moodle Anda.