Anda mungkin tahu cara menyisipkan catatan ke dalam tabel menggunakan klausa VALUES tunggal atau ganda. Anda juga tahu bagaimana melakukan penyisipan massal menggunakan SQL INSERT INTO SELECT. Tapi Anda masih mengklik artikel tersebut. Apakah ini tentang menangani duplikat?
Banyak artikel membahas SQL INSERT INTO SELECT. Google atau Bing dan pilih judul yang paling Anda sukai – itu akan berhasil. Saya juga tidak akan membahas contoh dasar tentang cara melakukannya. Sebagai gantinya, Anda akan melihat contoh cara menggunakannya DAN menangani duplikat secara bersamaan . Jadi, Anda dapat membuat pesan yang familier ini dari upaya INSERT Anda:
Msg 2601, Level 14, State 1, Line 14
Cannot insert duplicate key row in object 'dbo.Table1' with unique index 'UIX_Table1_Key1'. The duplicate key value is (value1).
Tapi hal pertama yang pertama.

[sendpulse-form id="12989″]
Siapkan Data Uji untuk SQL INSERT INTO SELECT Code Samples
Saya agak berpikir tentang pasta kali ini. Jadi, saya akan menggunakan data tentang hidangan pasta. Saya menemukan daftar hidangan pasta yang bagus di Wikipedia yang dapat kami gunakan dan ekstrak di Power BI menggunakan sumber data web. Saya memasukkan URL Wikipedia. Lalu saya menentukan data 2-tabel dari halaman. Membersihkannya sedikit dan menyalin data ke Excel.
Sekarang kami memiliki data – Anda dapat mengunduhnya dari sini. Ini mentah karena kita akan membuat 2 tabel relasional darinya. Menggunakan INSERT INTO SELECT akan membantu kami melakukan tugas ini,
Impor Data di SQL Server
Anda dapat menggunakan SQL Server Management Studio atau dbForge Studio untuk SQL Server untuk mengimpor 2 lembar ke dalam file Excel.
Buat database kosong sebelum mengimpor data. Saya menamai tabelnya dbo.ItalianPastaDishes dan dbo.NonItalianPastaDishes .
Buat 2 Tabel Lagi
Mari kita definisikan dua tabel output dengan perintah SQL Server ALTER TABLE.
CREATE TABLE [dbo].[Origin](
[OriginID] [int] IDENTITY(1,1) NOT NULL,
[Origin] [varchar](50) NOT NULL,
[Modified] [datetime] NOT NULL,
CONSTRAINT [PK_Origin] PRIMARY KEY CLUSTERED
(
[OriginID] ASC
))
GO
ALTER TABLE [dbo].[Origin] ADD CONSTRAINT [DF_Origin_Modified] DEFAULT (getdate()) FOR [Modified]
GO
CREATE UNIQUE NONCLUSTERED INDEX [UIX_Origin] ON [dbo].[Origin]
(
[Origin] ASC
)
GO
CREATE TABLE [dbo].[PastaDishes](
[PastaDishID] [int] IDENTITY(1,1) NOT NULL,
[PastaDishName] [nvarchar](75) NOT NULL,
[OriginID] [int] NOT NULL,
[Description] [nvarchar](500) NOT NULL,
[Modified] [datetime] NOT NULL,
CONSTRAINT [PK_PastaDishes_1] PRIMARY KEY CLUSTERED
(
[PastaDishID] ASC
))
GO
ALTER TABLE [dbo].[PastaDishes] ADD CONSTRAINT [DF_PastaDishes_Modified_1] DEFAULT (getdate()) FOR [Modified]
GO
ALTER TABLE [dbo].[PastaDishes] WITH CHECK ADD CONSTRAINT [FK_PastaDishes_Origin] FOREIGN KEY([OriginID])
REFERENCES [dbo].[Origin] ([OriginID])
GO
ALTER TABLE [dbo].[PastaDishes] CHECK CONSTRAINT [FK_PastaDishes_Origin]
GO
CREATE UNIQUE NONCLUSTERED INDEX [UIX_PastaDishes_PastaDishName] ON [dbo].[PastaDishes]
(
[PastaDishName] ASC
)
GO
Catatan:Ada indeks unik yang dibuat pada dua tabel. Ini akan mencegah kita memasukkan catatan duplikat nanti. Pembatasan akan membuat perjalanan ini sedikit lebih sulit tetapi mengasyikkan.
Sekarang setelah kita siap, mari selami.
5 Cara Mudah Menangani Duplikat Menggunakan SQL INSERT INTO SELECT
Cara termudah untuk menangani duplikat adalah dengan menghapus batasan unik, bukan?
Salah!
Dengan hilangnya batasan unik, mudah untuk membuat kesalahan dan memasukkan data dua kali atau lebih. Kami tidak ingin itu. Dan bagaimana jika kita memiliki antarmuka pengguna dengan daftar dropdown untuk memilih asal hidangan pasta? Apakah duplikat akan membuat pengguna Anda senang?
Oleh karena itu, menghapus batasan unik bukanlah salah satu dari lima cara untuk menangani atau menghapus rekaman duplikat di SQL. Kami memiliki opsi yang lebih baik.
1. Menggunakan INSERT INTO SELECT DISTINCT
Opsi pertama tentang cara mengidentifikasi catatan SQL dalam SQL adalah menggunakan DISTINCT di SELECT Anda. Untuk menjelajahi kasus ini, kami akan mengisi Asal meja. Tapi pertama-tama, mari kita gunakan metode yang salah:
-- This is wrong and will trigger duplicate key errors
INSERT INTO Origin
(Origin)
SELECT origin FROM NonItalianPastaDishes
GO
INSERT INTO Origin
(Origin)
SELECT ItalianRegion + ', ' + 'Italy'
FROM ItalianPastaDishes
GO
Ini akan memicu kesalahan duplikat berikut:
Msg 2601, Level 14, State 1, Line 2
Cannot insert a duplicate key row in object 'dbo.Origin' with unique index 'UIX_Origin'. The duplicate key value is (United States).
The statement has been terminated.
Msg 2601, Level 14, State 1, Line 6
Cannot insert duplicate key row in object 'dbo.Origin' with unique index 'UIX_Origin'. The duplicate key value is (Lombardy, Italy).
Ada masalah saat Anda mencoba memilih baris duplikat di SQL. Untuk memulai pemeriksaan SQL untuk duplikat yang ada sebelumnya, saya menjalankan bagian SELECT dari pernyataan INSERT INTO SELECT:
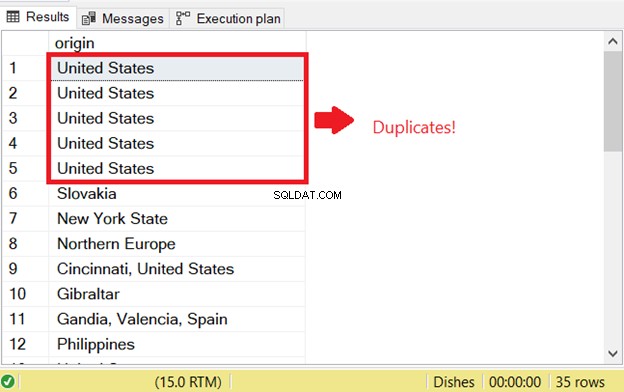
Itulah alasan kesalahan duplikat SQL pertama. Untuk mencegahnya, tambahkan kata kunci DISTINCT untuk membuat kumpulan hasil menjadi unik. Ini kode yang benar:
-- The correct way to INSERT
INSERT INTO Origin
(Origin)
SELECT DISTINCT origin FROM NonItalianPastaDishes
INSERT INTO Origin
(Origin)
SELECT DISTINCT ItalianRegion + ', ' + 'Italy'
FROM ItalianPastaDishes
Ini memasukkan catatan dengan sukses. Dan kita sudah selesai dengan Origin tabel.
Menggunakan DISTINCT akan membuat catatan unik dari pernyataan SELECT. Namun, itu tidak menjamin bahwa duplikat tidak ada di tabel target. Sebaiknya Anda yakin bahwa tabel target tidak memiliki nilai yang ingin Anda sisipkan.
Jadi, jangan jalankan pernyataan ini lebih dari sekali.
2. Menggunakan WHERE NOT IN
Selanjutnya, kami mengisi PastaDisshes meja. Untuk itu, pertama-tama kita harus menyisipkan record dari ItalianPastaDishes meja. Ini kodenya:
INSERT INTO [dbo].[PastaDishes]
(PastaDishName,OriginID, Description)
SELECT
a.DishName
,b.OriginID
,a.Description
FROM ItalianPastaDishes a
INNER JOIN Origin b ON a.ItalianRegion + ', ' + 'Italy' = b.Origin
WHERE a.DishName NOT IN (SELECT PastaDishName FROM PastaDishes)
Sejak Makanan Pasta Italia berisi data mentah, kita harus bergabung dengan Origin teks sebagai ganti OriginID . Sekarang, coba jalankan kode yang sama dua kali. Kali kedua dijalankan tidak akan ada catatan yang dimasukkan. Itu terjadi karena klausa WHERE dengan operator NOT IN. Ini menyaring catatan yang sudah ada di tabel target.
Selanjutnya, kita perlu mengisi PastaDisshes tabel dari NonItalianPastaDishes meja. Karena kami hanya berada di poin kedua dari posting ini, kami tidak akan memasukkan semuanya.
Kami memilih hidangan pasta dari Amerika Serikat dan Filipina. Ini dia:
-- Insert pasta dishes from the United States (22) and the Philippines (15) using NOT IN
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE a.PastaDishName NOT IN (SELECT PastaDishName FROM PastaDishes)
AND b.OriginID IN (15,22)
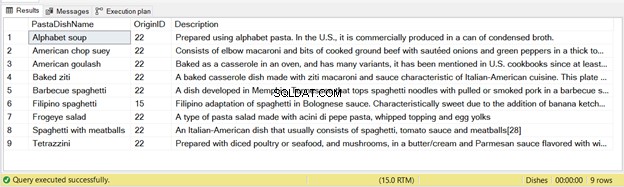
Ada 9 record yang disisipkan dari pernyataan ini – lihat Gambar 2 di bawah ini:
Sekali lagi, jika Anda menjalankan kode di atas dua kali, proses kedua tidak akan memasukkan record.
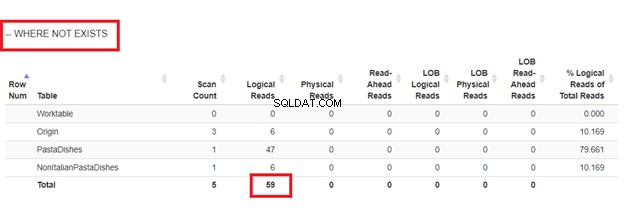
3. Menggunakan WHERE NOT EXISTS
Cara lain untuk menemukan duplikat dalam SQL adalah dengan menggunakan NOT EXISTS dalam klausa WHERE. Mari kita coba dengan kondisi yang sama dari bagian sebelumnya:
-- Insert pasta dishes from the United States (22) and the Philippines (15) using WHERE NOT EXISTS
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE NOT EXISTS(SELECT PastaDishName FROM PastaDishes pd
WHERE pd.OriginID IN (15,22))
AND b.OriginID IN (15,22)
Kode di atas akan menyisipkan 9 record yang sama dengan yang Anda lihat pada Gambar 2. Ini akan menghindari penyisipan record yang sama lebih dari satu kali.
4. Menggunakan JIKA TIDAK ADA
Terkadang Anda mungkin perlu menerapkan tabel ke database dan perlu memeriksa apakah tabel dengan nama yang sama sudah ada untuk menghindari duplikat. Dalam hal ini, perintah SQL DROP TABLE IF EXISTS dapat sangat membantu. Cara lain untuk memastikan Anda tidak memasukkan duplikat adalah menggunakan JIKA TIDAK ADA. Sekali lagi, kita akan menggunakan kondisi yang sama dari bagian sebelumnya:
-- Insert pasta dishes from the United States (22) and the Philippines (15) using IF NOT EXISTS
IF NOT EXISTS(SELECT PastaDishName FROM PastaDishes pd
WHERE pd.OriginID IN (15,22))
BEGIN
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE b.OriginID IN (15,22)
END
Kode di atas pertama-tama akan memeriksa keberadaan 9 record. Jika hasilnya benar, INSERT akan dilanjutkan.
5. Menggunakan COUNT(*) =0
Terakhir, penggunaan COUNT(*) dalam klausa WHERE juga dapat memastikan Anda tidak akan menyisipkan duplikat. Ini contohnya:
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE b.OriginID IN (15,22)
AND (SELECT COUNT(*) FROM PastaDishes pd
WHERE pd.OriginID IN (15,22)) = 0
Untuk menghindari duplikat, COUNT atau record yang dikembalikan oleh subquery di atas harus nol.
Catatan :Anda dapat mendesain kueri apa pun secara visual dalam diagram menggunakan fitur Pembuat Kueri dari dbForge Studio untuk SQL Server.
Membandingkan Berbagai Cara Menangani Duplikat dengan SQL INSERT INTO SELECT
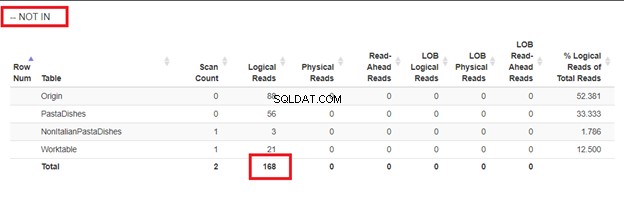
4 bagian menggunakan output yang sama tetapi pendekatan yang berbeda untuk menyisipkan catatan massal dengan pernyataan SELECT. Anda mungkin bertanya-tanya apakah perbedaannya hanya di permukaan. Kami dapat memeriksa pembacaan logis mereka dari STATISTICS IO untuk melihat betapa berbedanya mereka.
Menggunakan WHERE NOT IN:
Menggunakan NOT EXISTS:
Menggunakan JIKA TIDAK ADA:
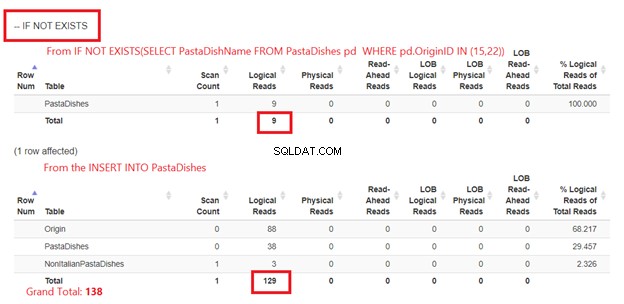
Gambar 5 sedikit berbeda. 2 pembacaan logis muncul untuk PastaDishes meja. Yang pertama dari IF NOT EXISTS(SELECT PastaDishName dari PastaDisshes DI MANA OriginID DI (15,22)). Yang kedua adalah dari pernyataan INSERT.
Akhirnya, menggunakan COUNT(*) =0
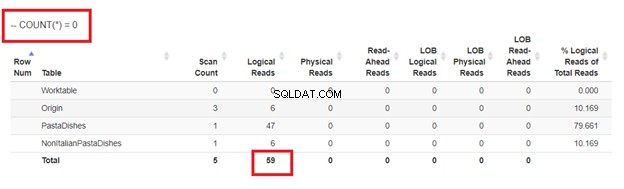
Dari pembacaan logis dari 4 pendekatan yang kami miliki, pilihan terbaik adalah WHERE NOT EXISTS atau COUNT(*) =0. Saat kami memeriksa paket Eksekusinya, kami melihat mereka memiliki QueryHashPlan yang sama . Dengan demikian, mereka memiliki rencana serupa. Sedangkan yang paling tidak efisien adalah menggunakan NOT IN.
Apakah ini berarti WHERE NOT EXIST selalu lebih baik daripada NOT IN? Tidak sama sekali.
Selalu periksa pembacaan logis dan Rencana Eksekusi pertanyaan Anda!
Tetapi sebelum kita menyimpulkan, kita harus menyelesaikan tugas yang ada. Kemudian kami akan memasukkan sisa catatan dan memeriksa hasilnya.
-- Insert the rest of the records
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE a.PastaDishName NOT IN (SELECT PastaDishName FROM PastaDishes)
GO
-- View the output
SELECT
a.PastaDishID
,a.PastaDishName
,b.Origin
,a.Description
,a.Modified
FROM PastaDishes a
INNER JOIN Origin b ON a.OriginID = b.OriginID
ORDER BY b.Origin, a.PastaDishName
Menelusuri daftar 179 hidangan pasta dari Asia hingga Eropa membuat saya lapar. Lihat bagian dari daftar dari Italia, Rusia, dan lainnya dari bawah:

Kesimpulan
Menghindari duplikat dalam SQL INSERT INTO SELECT tidak terlalu sulit. Anda memiliki operator dan fungsi untuk membawa Anda ke level itu. Ini juga merupakan kebiasaan yang baik untuk memeriksa Rencana Eksekusi dan pembacaan logis untuk membandingkan mana yang lebih baik.
Jika menurut Anda orang lain akan mendapat manfaat dari posting ini, silakan bagikan di platform media sosial favorit Anda. Dan jika Anda memiliki sesuatu untuk ditambahkan yang kami lupa, beri tahu kami di bagian Komentar di bawah.