Di bagian komentar salah satu blog kami, seorang pembaca bertanya tentang dampak wsrep_slave_threads pada kinerja dan skalabilitas I/O Galera Cluster. Saat itu, kami tidak dapat dengan mudah menjawab pertanyaan itu dan mencadangkannya dengan lebih banyak data, tetapi akhirnya kami berhasil menyiapkan lingkungan dan menjalankan beberapa pengujian.
Pembaca kami menunjukkan tolok ukur yang menunjukkan bahwa peningkatan wsrep_slave_threads tidak berdampak apa pun pada kinerja cluster Galera.
Untuk menjelaskan apa dampak dari pengaturan itu, kami menyiapkan sekelompok kecil tiga node (m5d.xlarge). Ini memungkinkan kami untuk menggunakan nvme SSD yang terpasang langsung untuk direktori data MySQL. Dengan melakukan ini, kami meminimalkan kemungkinan penyimpanan yang menjadi hambatan dalam penyiapan kami.
Kami menyiapkan kumpulan buffer InnoDB ke 8GB dan mengulang log ke dua file, masing-masing 1GB. Kami juga meningkatkan innodb_io_capacity menjadi 2000 dan innodb_io_capacity_max menjadi 10.000. Ini juga dimaksudkan untuk memastikan bahwa tidak satu pun dari setelan tersebut akan memengaruhi kinerja kami.
Seluruh masalah dengan tolok ukur seperti itu adalah bahwa ada begitu banyak hambatan sehingga Anda harus menghilangkannya satu per satu. Hanya setelah melakukan beberapa penyetelan konfigurasi dan setelah memastikan bahwa perangkat keras tidak akan menjadi masalah, orang dapat berharap bahwa beberapa batasan yang lebih halus akan muncul.
Kami menghasilkan ~90GB data menggunakan sysbench:
sysbench /usr/share/sysbench/oltp_write_only.lua --threads=16 --events=0 --time=600 --mysql-host=172.30.4.245 --mysql-user=sbtest --mysql-password=sbtest --mysql-port=3306 --tables=28 --report-interval=1 --skip-trx=off --table-size=10000000 --db-ps-mode=disable --mysql-db=sbtest_large prepareKemudian benchmark dieksekusi. Kami menguji dua pengaturan:wsrep_slave_threads=1 dan wsrep_slave_threads=16. Perangkat kerasnya tidak cukup kuat untuk mendapatkan manfaat dari peningkatan variabel ini lebih jauh. Harap diingat juga bahwa kami tidak melakukan pembandingan terperinci untuk menentukan apakah wsrep_slave_threads harus disetel ke 16, 8 atau mungkin 4 untuk kinerja terbaik. Kami tertarik untuk melihat apakah kami dapat menunjukkan dampak pada cluster. Dan ya, dampaknya terlihat jelas. Sebagai permulaan, beberapa grafik kontrol aliran.
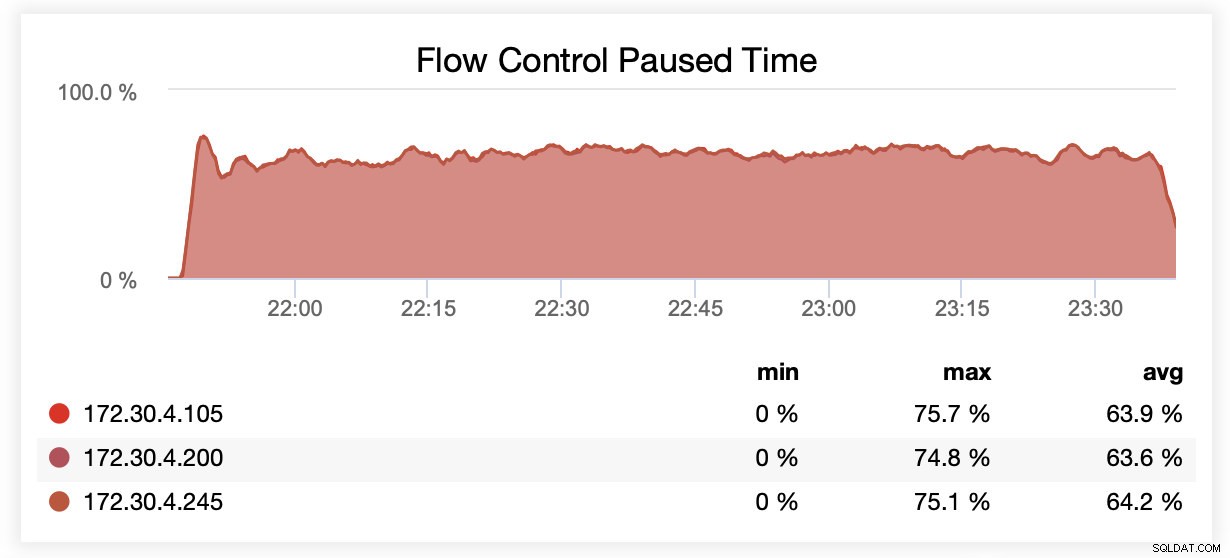
Saat berjalan dengan wsrep_slave_threads=1, rata-rata, node dijeda karena kontrol aliran ~64% dari waktu.
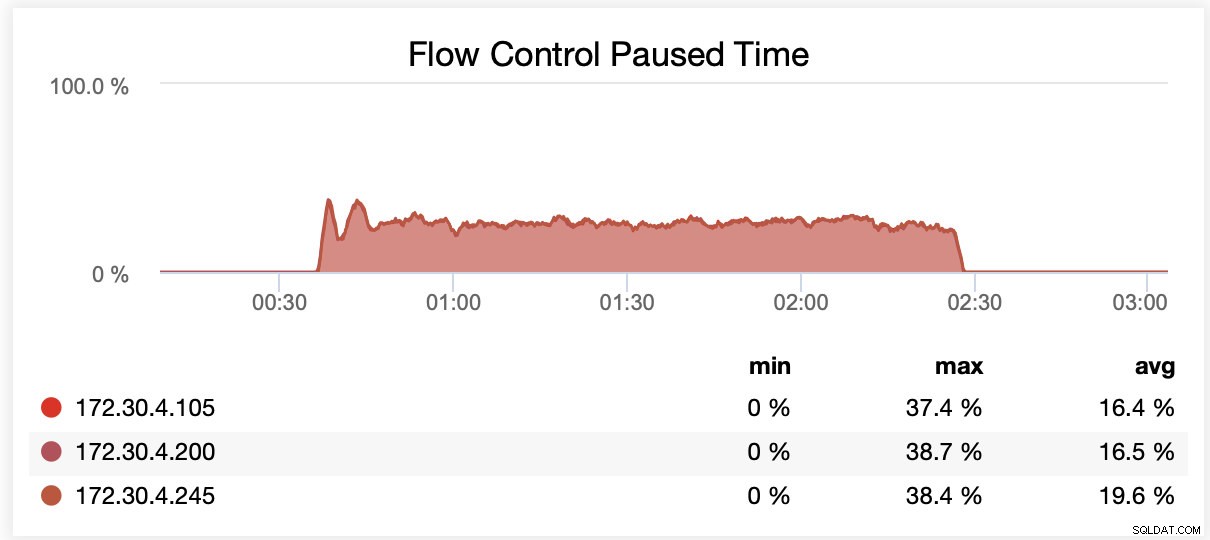
Saat berjalan dengan wsrep_slave_threads=16, rata-rata, node dijeda karena kontrol aliran ~20% dari waktu.
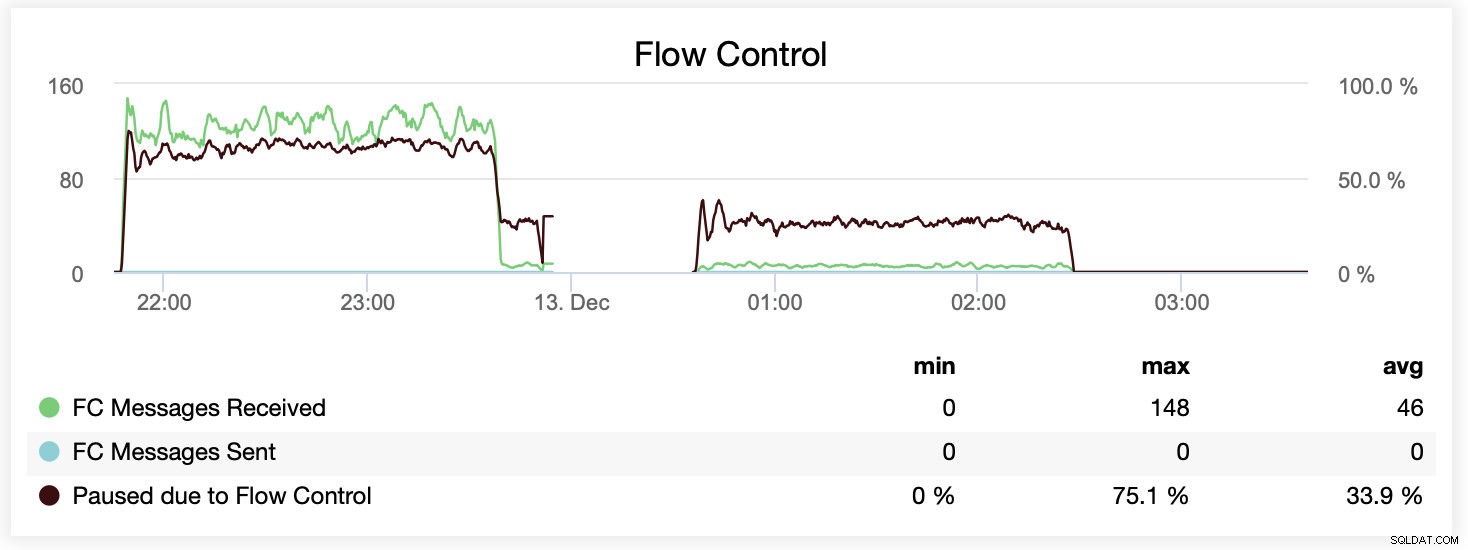
Anda juga dapat membandingkan perbedaan pada satu grafik. Penurunan di akhir bagian pertama adalah upaya pertama untuk dijalankan dengan wsrep_slave_threads=16. Server kehabisan ruang disk untuk log biner dan kami harus menjalankan kembali benchmark itu sekali lagi di lain waktu.
Bagaimana ini diterjemahkan dalam istilah kinerja? Perbedaannya terlihat meskipun jelas tidak terlalu spektakuler.
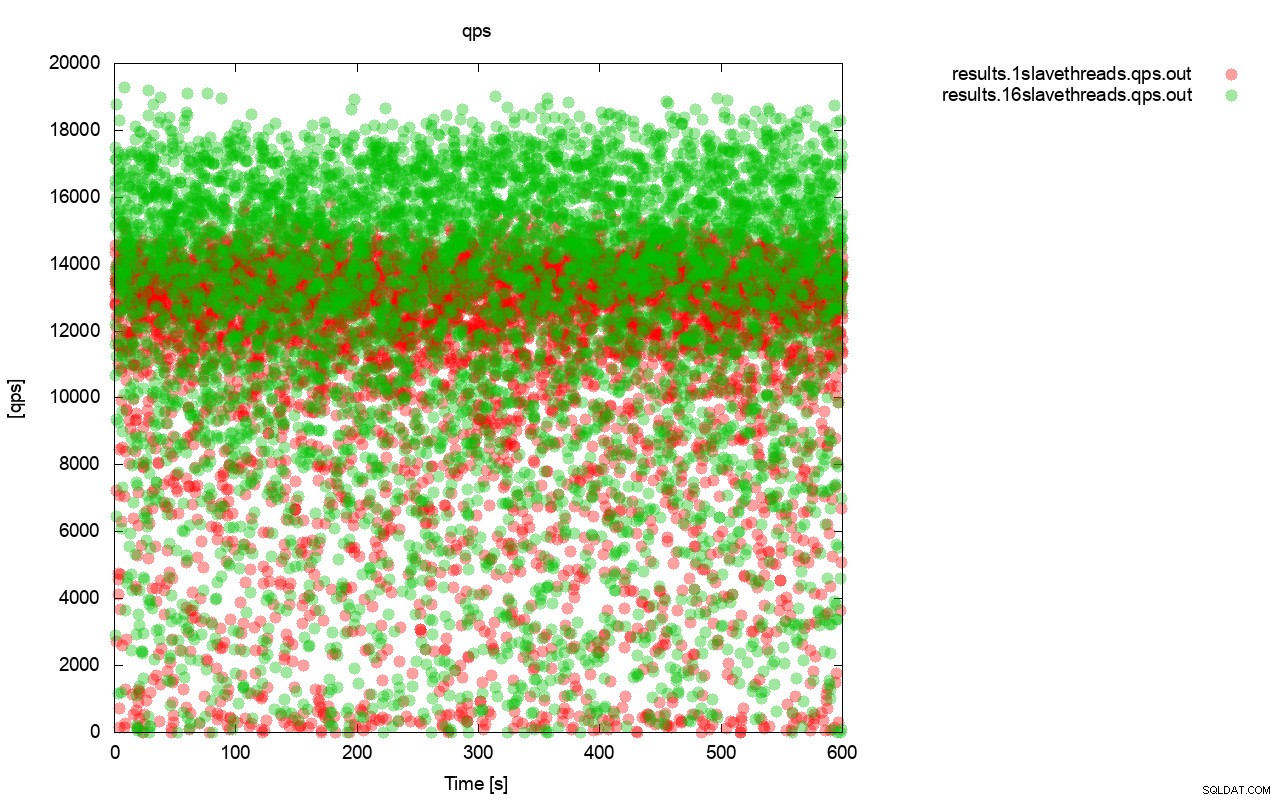
Pertama, kueri per grafik detik. Pertama-tama, Anda dapat melihat bahwa dalam kedua kasus, hasilnya ada di mana-mana. Ini sebagian besar terkait dengan kinerja penyimpanan I/O yang tidak stabil dan kontrol aliran yang muncul secara acak. Anda masih dapat melihat bahwa kinerja hasil "merah" (wsrep_slave_threads=1) cukup rendah daripada yang "hijau" ( wsrep_slave_threads=16).
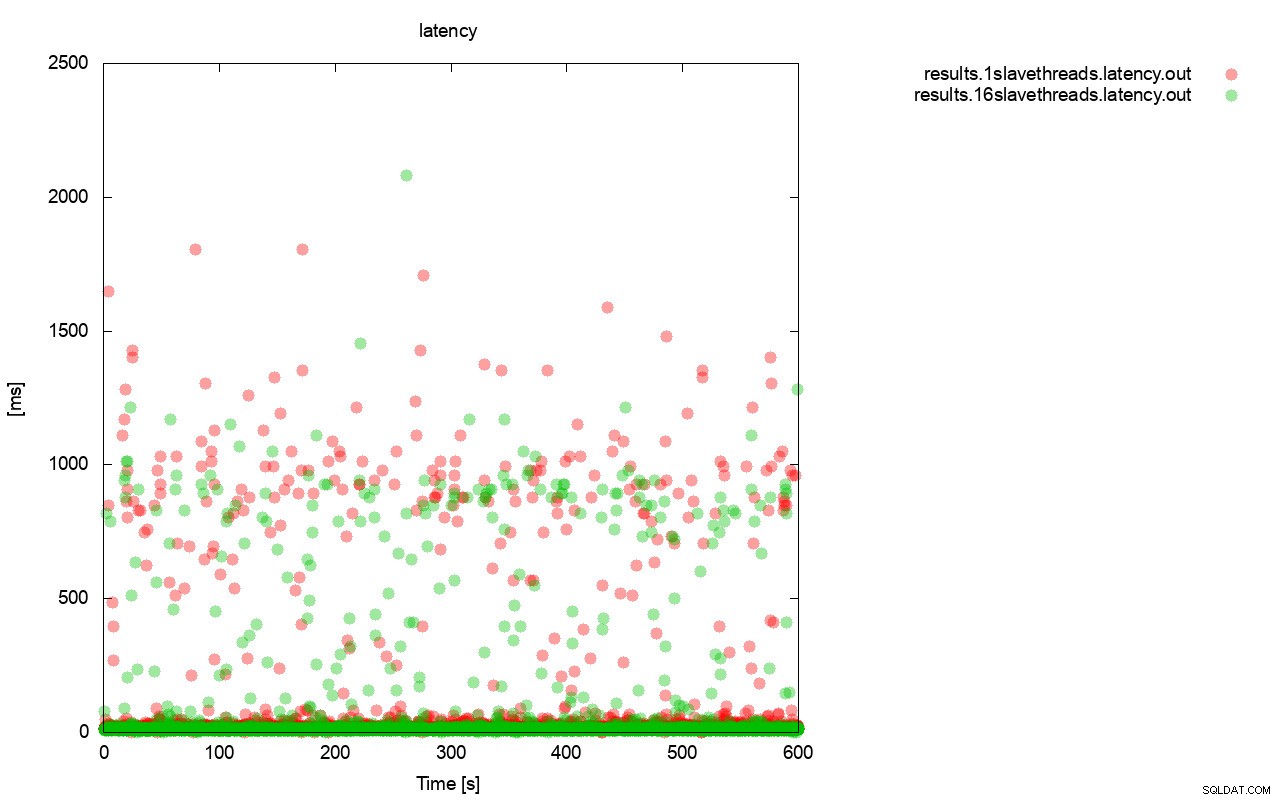
Gambaran yang cukup mirip adalah ketika kita melihat latency. Anda dapat melihat lebih banyak (dan biasanya lebih dalam) kios untuk dijalankan dengan wsrep_slave_thread=1.
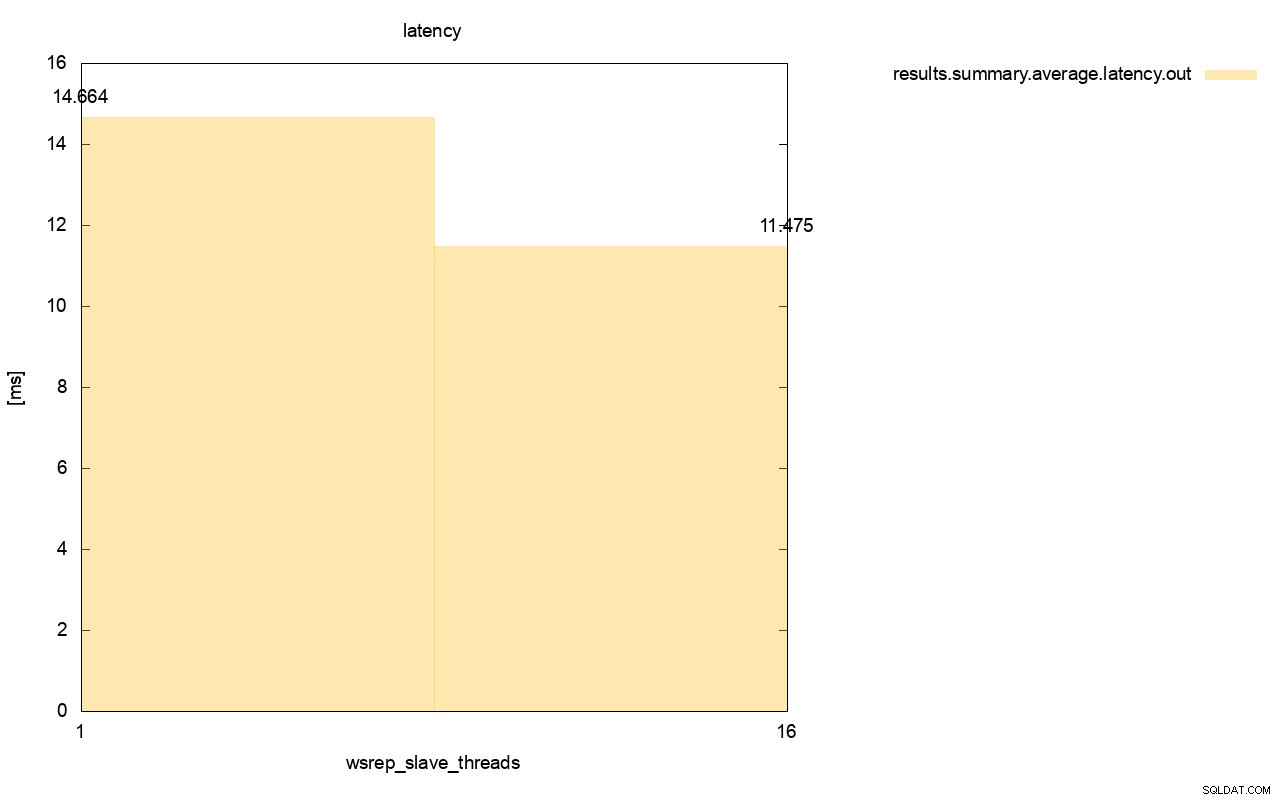
Perbedaannya bahkan lebih terlihat ketika kami menghitung latensi rata-rata di semua proses dan Anda dapat melihat bahwa latensi wsrep_slave_thread=1 adalah 27% lebih tinggi dari latensi dengan 16 utas budak, yang jelas tidak bagus karena kami ingin latensi lebih rendah , tidak lebih tinggi.
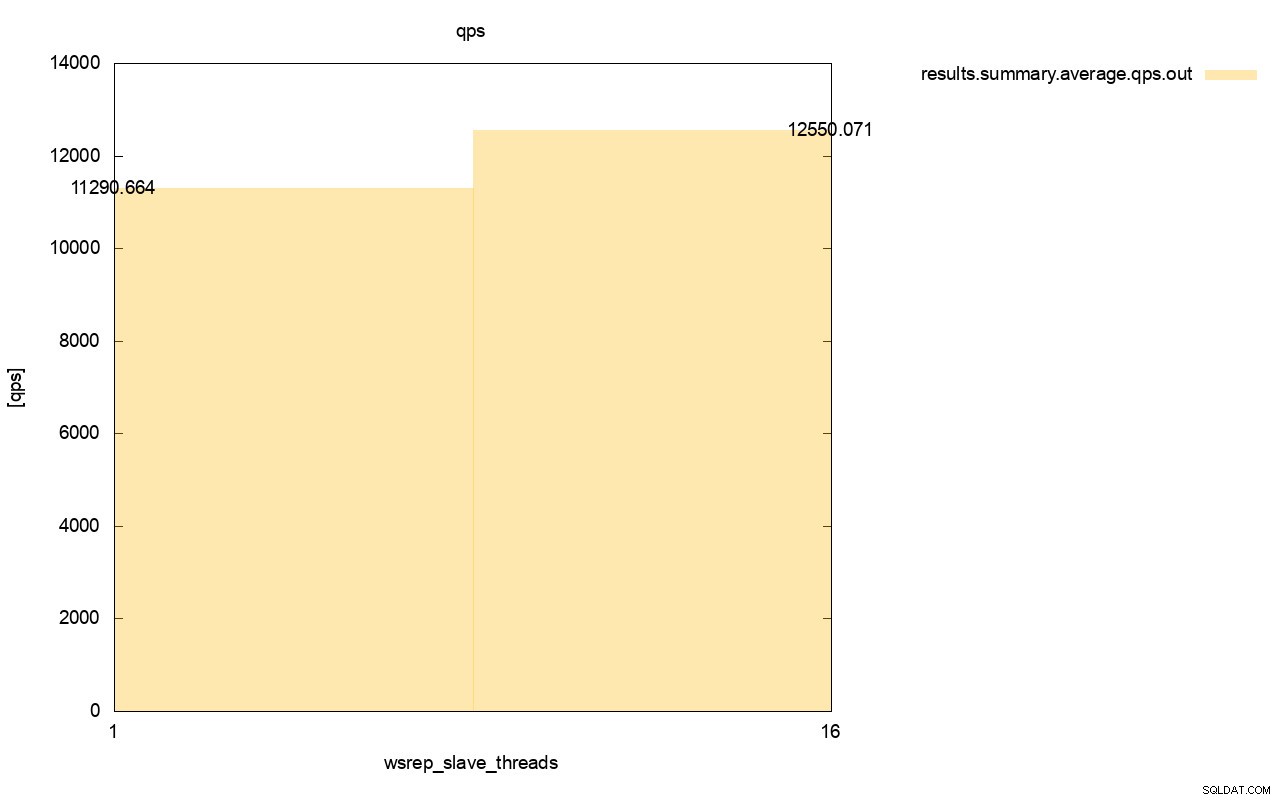
Perbedaan throughput juga terlihat, sekitar 11% peningkatan saat kami menambahkan lebih banyak wsrep_slave_threads.
Seperti yang Anda lihat, dampaknya ada di sana. Ini tidak berarti 16x (bahkan jika itu cara kami meningkatkan jumlah utas budak di Galera) tetapi ini jelas cukup menonjol sehingga kami tidak dapat mengklasifikasikannya hanya sebagai anomali statistik.
Harap diingat bahwa dalam kasus kami, kami menggunakan node yang cukup kecil. Perbedaannya akan lebih signifikan jika kita berbicara tentang instans besar yang berjalan pada volume EBS dengan ribuan IOPS yang disediakan.
Kemudian kami akan dapat menjalankan sysbench lebih agresif, dengan jumlah operasi bersamaan yang lebih tinggi. Ini akan meningkatkan paralelisasi dari writeset, meningkatkan keuntungan dari multithreading lebih jauh. Selain itu, perangkat keras yang lebih cepat berarti Galera akan dapat menggunakan 16 utas tersebut dengan cara yang lebih efisien.
Saat menjalankan tes seperti ini, Anda harus ingat bahwa Anda harus mendorong pengaturan Anda hingga hampir mencapai batasnya. Replikasi utas tunggal dapat menangani cukup banyak beban dan Anda harus menjalankan lalu lintas yang padat agar benar-benar membuatnya tidak cukup berkinerja untuk menangani tugas tersebut.
Kami berharap postingan blog ini memberi Anda lebih banyak wawasan tentang kemampuan Galera Cluster untuk menerapkan writeset secara paralel dan faktor pembatas di sekitarnya.