Dalam posting blog ini, kami akan menganalisis 6 skenario kegagalan yang berbeda dalam sistem basis data produksi, mulai dari masalah server tunggal hingga rencana failover multi-pusat data. Kami akan memandu Anda melalui prosedur pemulihan dan failover untuk skenario masing-masing. Mudah-mudahan, ini akan memberi Anda pemahaman yang baik tentang risiko yang mungkin Anda hadapi dan hal-hal yang perlu dipertimbangkan saat merancang infrastruktur Anda.
Skema Basis Data Rusak
Mari kita mulai dengan instalasi node tunggal - setup database dalam bentuk yang paling sederhana. Mudah diterapkan, dengan biaya terendah. Dalam skenario ini, Anda menjalankan beberapa aplikasi di satu server di mana setiap skema database milik aplikasi yang berbeda. Pendekatan untuk pemulihan skema tunggal akan bergantung pada beberapa faktor.
- Apakah saya punya cadangan?
- Apakah saya memiliki cadangan dan seberapa cepat saya dapat memulihkannya?
- Mesin penyimpanan seperti apa yang digunakan?
- Apakah saya memiliki cadangan yang kompatibel dengan PITR (pemulihan titik waktu)?
Kerusakan data dapat diidentifikasi dengan mysqlcheck.
mysqlcheck -uroot -p <DATABASE>Ganti DATABASE dengan nama database, dan ganti TABLE dengan nama tabel yang ingin diperiksa:
mysqlcheck -uroot -p <DATABASE> <TABLE>Mysqlcheck memeriksa database dan tabel yang ditentukan. Jika sebuah tabel lolos pemeriksaan, mysqlcheck menampilkan OK untuk tabel tersebut. Pada contoh di bawah ini, kita dapat melihat bahwa tabel gaji membutuhkan pemulihan.
employees.departments OK
employees.dept_emp OK
employees.dept_manager OK
employees.employees OK
Employees.salaries
Warning : Tablespace is missing for table 'employees/salaries'
Error : Table 'employees.salaries' doesn't exist in engine
status : Operation failed
employees.titles OKUntuk instalasi node tunggal tanpa server DR tambahan, pendekatan utama adalah memulihkan data dari cadangan. Tapi ini bukan satu-satunya hal yang perlu Anda pertimbangkan. Memiliki beberapa skema database di bawah contoh yang sama menyebabkan masalah saat Anda harus mematikan server untuk memulihkan data. Pertanyaan lain adalah apakah Anda mampu mengembalikan semua database Anda ke cadangan terakhir. Dalam kebanyakan kasus, itu tidak mungkin.
Ada beberapa pengecualian di sini. Dimungkinkan untuk memulihkan satu tabel atau database dari cadangan terakhir saat pemulihan titik waktu tidak diperlukan. Proses seperti itu lebih rumit. Jika Anda memiliki mysqldump, Anda dapat mengekstrak database Anda darinya. Jika Anda menjalankan pencadangan biner dengan xtradbackup atau mariabackup dan Anda telah mengaktifkan tabel per file, maka itu mungkin.
Berikut adalah cara memeriksa apakah Anda mengaktifkan opsi tabel per file.
mysql> SET GLOBAL innodb_file_per_table=1; Dengan mengaktifkan innodb_file_per_table, Anda dapat menyimpan tabel InnoDB dalam file tbl_name .ibd. Tidak seperti mesin penyimpanan MyISAM, dengan file tbl_name .MYD dan tbl_name .MYI terpisah untuk indeks dan data, InnoDB menyimpan data dan indeks bersama-sama dalam satu file .ibd. Untuk memeriksa mesin penyimpanan Anda, Anda perlu menjalankan:
mysql> select table_name,engine from information_schema.tables where table_name='table_name' and table_schema='database_name';atau langsung dari konsol:
[example@sqldat.com ~]# mysql -u<username> -p -D<database_name> -e "show table status\G"
Enter password:
*************************** 1. row ***************************
Name: test1
Engine: InnoDB
Version: 10
Row_format: Dynamic
Rows: 12
Avg_row_length: 1365
Data_length: 16384
Max_data_length: 0
Index_length: 0
Data_free: 0
Auto_increment: NULL
Create_time: 2018-05-24 17:54:33
Update_time: NULL
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options:
Comment: Untuk memulihkan tabel dari xtradbackup, Anda harus melalui proses ekspor. Cadangan perlu disiapkan sebelum dapat dipulihkan. Ekspor dilakukan dalam tahap persiapan. Setelah cadangan lengkap dibuat, jalankan prosedur persiapan standar dengan tanda tambahan --export :
innobackupex --apply-log --export /u01/backupIni akan membuat file ekspor tambahan yang akan Anda gunakan nanti dalam fase impor. Untuk mengimpor tabel ke server lain, pertama buat tabel baru dengan struktur yang sama dengan yang akan diimpor di server tersebut:
mysql> CREATE TABLE corrupted_table (...) ENGINE=InnoDB;buang tablespace:
mysql> ALTER TABLE mydatabase.mytable DISCARD TABLESPACE;Kemudian salin file mytable.ibd dan mytable.exp ke home database, dan impor tablespace-nya:
mysql> ALTER TABLE mydatabase.mytable IMPORT TABLESPACE;Namun untuk melakukan ini dengan cara yang lebih terkontrol, rekomendasinya adalah mengembalikan cadangan database di instance/server lain dan menyalin apa yang diperlukan kembali ke sistem utama. Untuk melakukannya, Anda perlu menjalankan instalasi instance mysql. Ini dapat dilakukan pada mesin yang sama - tetapi memerlukan lebih banyak upaya untuk mengonfigurasi sedemikian rupa sehingga kedua instance dapat berjalan pada mesin yang sama - misalnya, yang memerlukan pengaturan komunikasi yang berbeda.
Anda dapat menggabungkan pemulihan tugas dan penginstalan menggunakan ClusterControl.
ClusterControl akan memandu Anda melalui cadangan yang tersedia di tempat atau di cloud, memungkinkan Anda memilih waktu yang tepat untuk pemulihan atau posisi log yang tepat, dan menginstal instance database baru jika diperlukan.
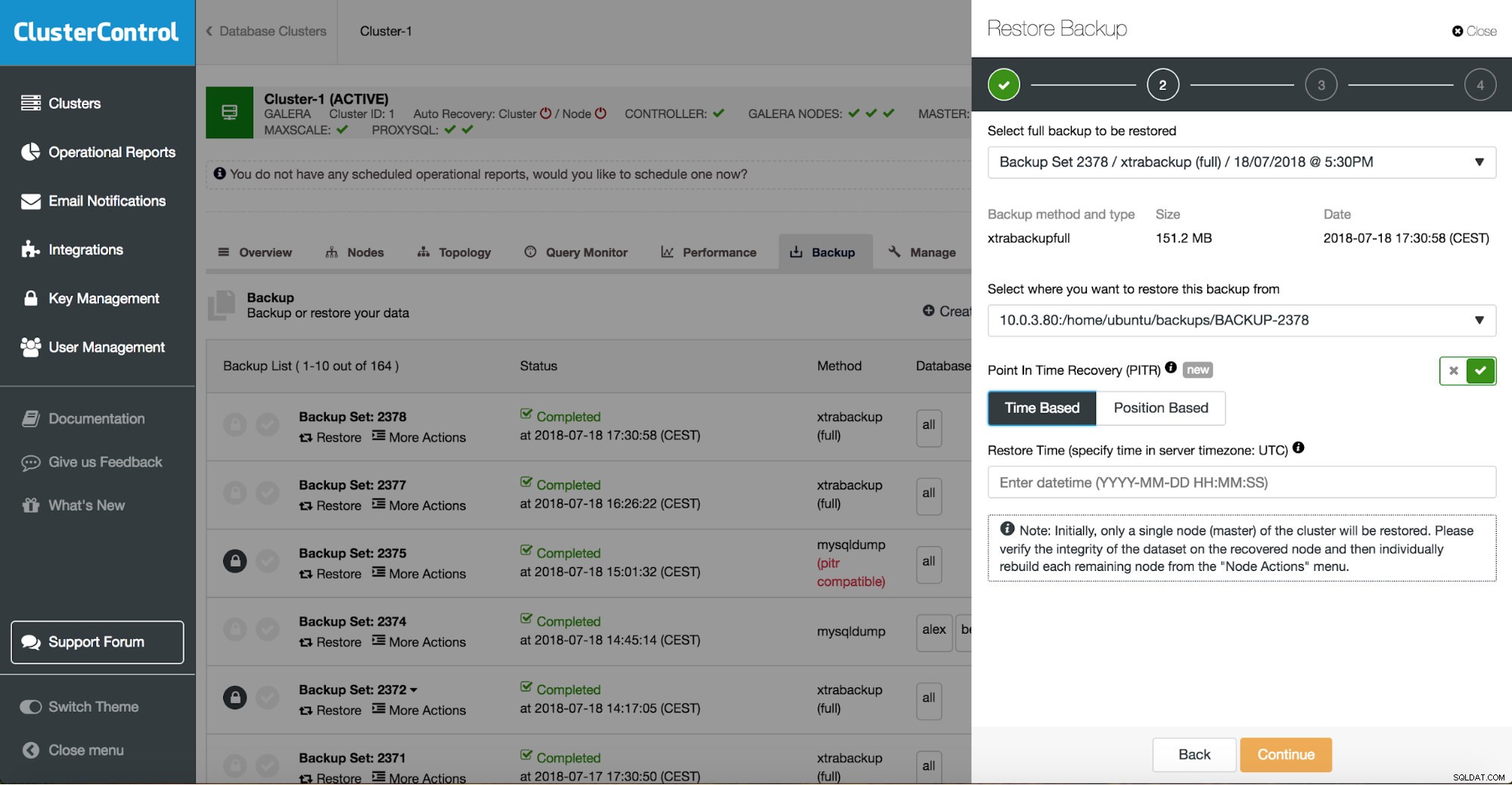 ClusterControl titik dalam pemulihan waktu
ClusterControl titik dalam pemulihan waktu 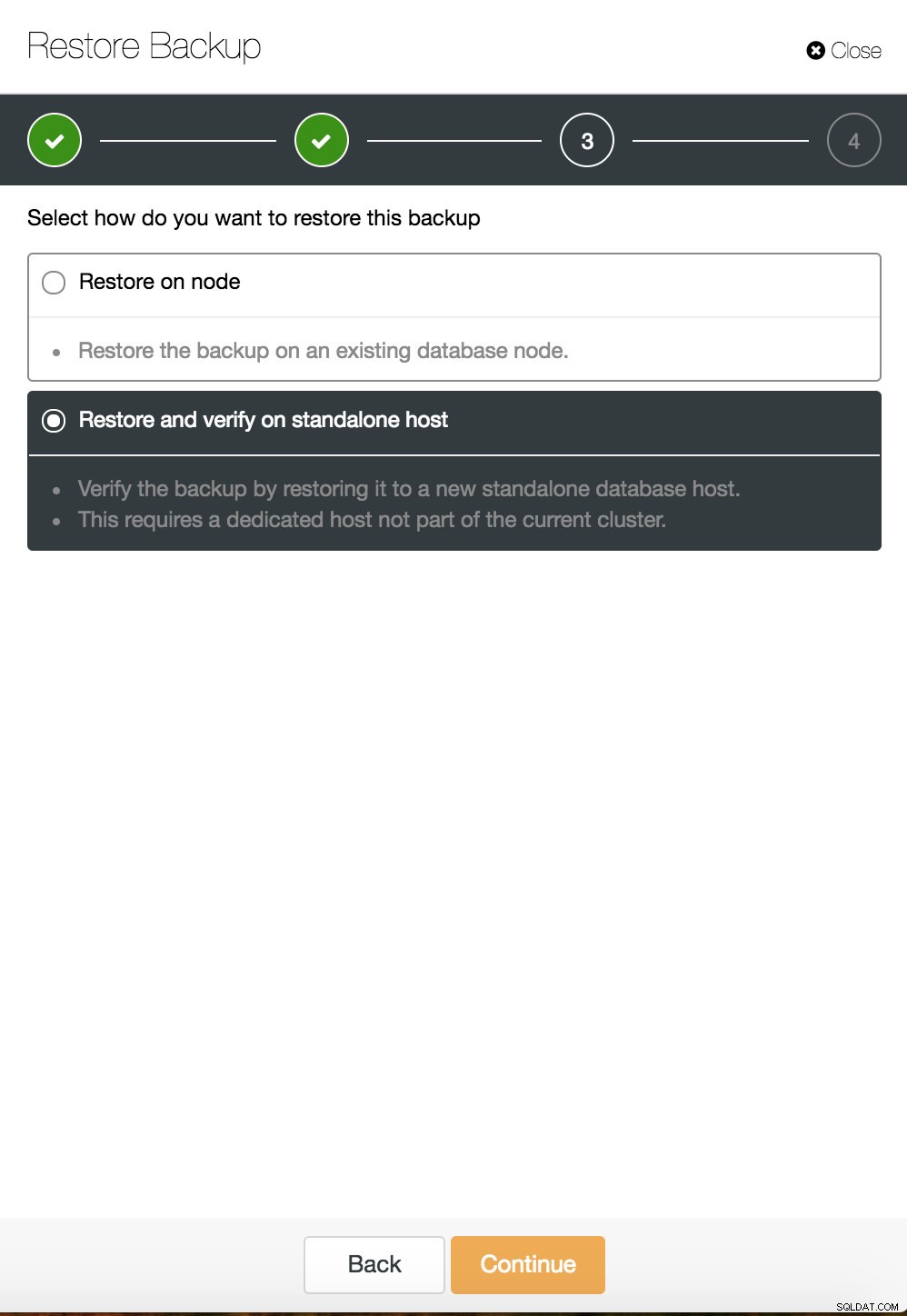 ClusterControl memulihkan dan memverifikasi pada host mandiri
ClusterControl memulihkan dan memverifikasi pada host mandiri 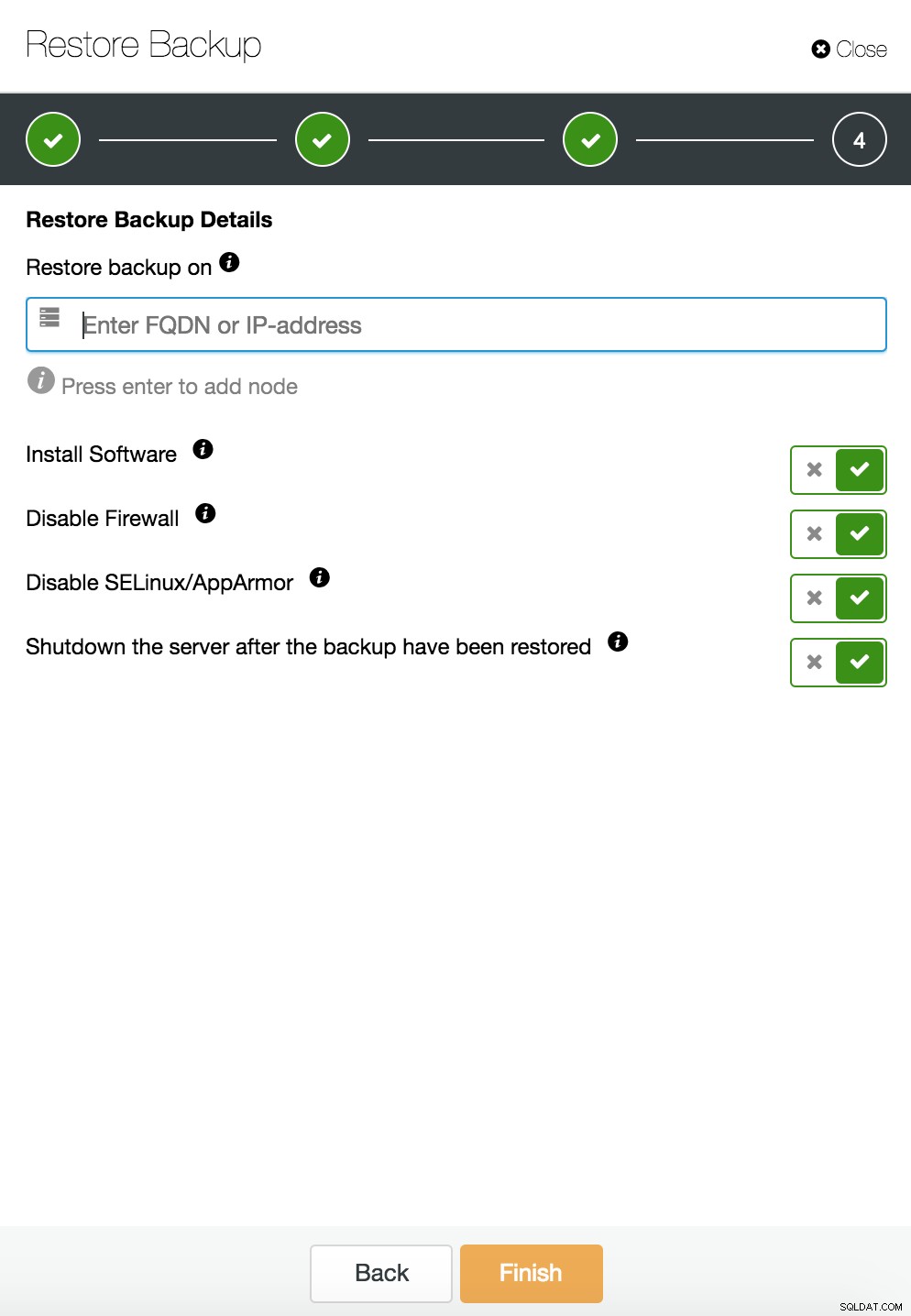 CusterControl memulihkan dan memverifikasi pada host mandiri. Opsi penginstalan.
CusterControl memulihkan dan memverifikasi pada host mandiri. Opsi penginstalan. Anda dapat menemukan informasi lebih lanjut tentang pemulihan data di blog Database MySQL Saya Rusak... Apa yang Harus Saya Lakukan Sekarang?
Instance Basis Data Rusak di Server Khusus
Cacat pada platform yang mendasarinya sering menjadi penyebab kerusakan basis data. Instance MySQL Anda bergantung pada sejumlah hal untuk menyimpan dan mengambil data - subsistem disk, pengontrol, saluran komunikasi, driver, dan firmware. Kerusakan dapat memengaruhi bagian data Anda, binari mysql, atau bahkan file cadangan yang Anda simpan di sistem. Untuk memisahkan aplikasi yang berbeda, Anda dapat menempatkannya di server khusus.
Skema aplikasi yang berbeda pada sistem yang terpisah adalah ide yang baik jika Anda mampu membelinya. Orang mungkin mengatakan bahwa ini adalah pemborosan sumber daya, tetapi ada kemungkinan dampak bisnis akan berkurang jika hanya salah satu dari mereka yang turun. Tetapi meskipun demikian, Anda perlu melindungi database Anda dari kehilangan data. Menyimpan cadangan di server yang sama bukanlah ide yang buruk selama Anda memiliki salinannya di tempat lain. Saat ini, penyimpanan cloud adalah alternatif yang sangat baik untuk backup tape.
ClusterControl memungkinkan Anda menyimpan salinan cadangan di cloud. Mendukung pengunggahan ke 3 penyedia cloud teratas - Amazon AWS, Google Cloud, dan Microsoft Azure.
Ketika Anda memiliki cadangan lengkap Anda dipulihkan, Anda mungkin ingin mengembalikannya ke titik waktu tertentu. Pemulihan point-in-time akan membuat server diperbarui ke waktu yang lebih baru daripada saat cadangan penuh diambil. Untuk melakukannya, Anda harus mengaktifkan log biner Anda. Anda dapat memeriksa log biner yang tersedia dengan:
mysql> SHOW BINARY LOGS;Dan file log saat ini dengan:
SHOW MASTER STATUS;Kemudian Anda dapat menangkap data tambahan dengan melewatkan log biner ke file sql. Operasi yang hilang dapat dijalankan kembali.
mysqlbinlog --start-position='14231131' --verbose /var/lib/mysql/binlog.000010 /var/lib/mysql/binlog.000011 /var/lib/mysql/binlog.000012 /var/lib/mysql/binlog.000013 /var/lib/mysql/binlog.000015 > binlog.outHal yang sama dapat dilakukan di ClusterControl.
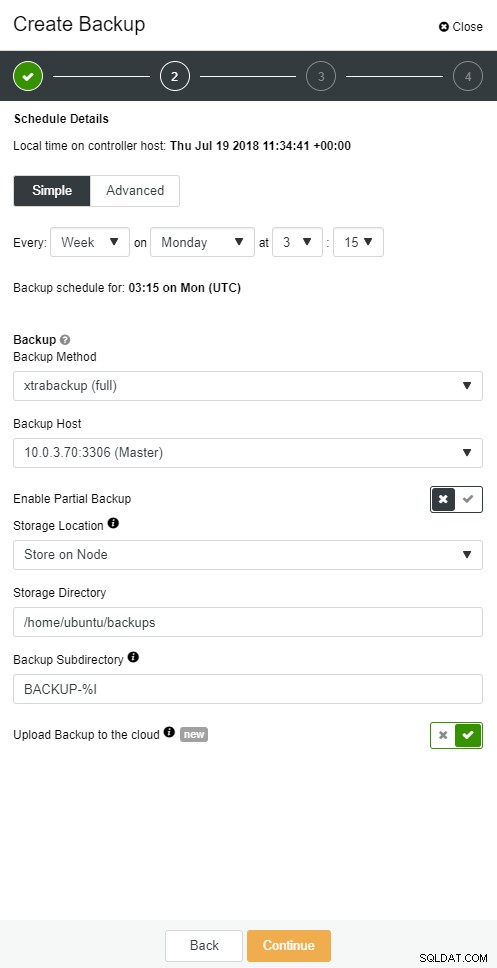 Pencadangan awan ClusterControl
Pencadangan awan ClusterControl 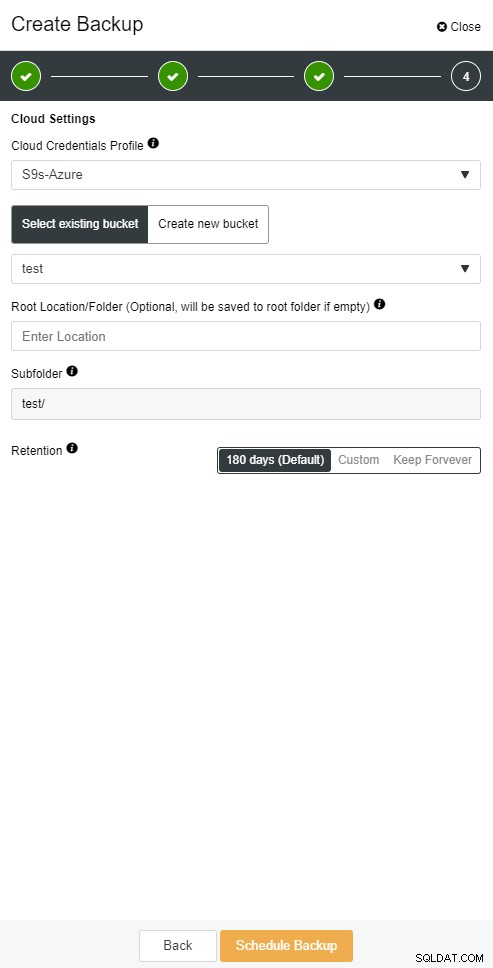 Pencadangan awan ClusterControl
Pencadangan awan ClusterControl Budak Database Turun
Oke, jadi database Anda berjalan di server khusus. Anda membuat jadwal pencadangan yang canggih dengan kombinasi pencadangan penuh dan tambahan, mengunggahnya ke cloud, dan menyimpan cadangan terbaru di disk lokal untuk pemulihan cepat. Anda memiliki kebijakan penyimpanan cadangan yang berbeda - lebih pendek untuk cadangan yang disimpan di driver disk lokal dan diperpanjang untuk cadangan cloud Anda.
Sepertinya Anda sudah siap menghadapi skenario bencana. Namun dalam hal waktu pemulihan, ini mungkin tidak memenuhi kebutuhan bisnis Anda.
Anda memerlukan fungsi failover cepat. Server yang akan aktif dan berjalan menerapkan log biner dari master tempat penulisan terjadi. Replikasi Master/Slave memulai babak baru dalam skenario failover. Ini adalah metode cepat untuk menghidupkan kembali aplikasi Anda jika master Anda down.
Tetapi ada beberapa hal yang perlu dipertimbangkan dalam skenario failover. Salah satunya adalah untuk mengatur budak replikasi tertunda, sehingga Anda dapat bereaksi terhadap perintah jari gemuk yang dipicu pada server master. Server budak dapat tertinggal dari master setidaknya dalam jangka waktu tertentu. Penundaan default adalah 0 detik. Gunakan opsi MASTER_DELAY untuk CHANGE MASTER TO untuk menyetel penundaan ke N detik:
CHANGE MASTER TO MASTER_DELAY = N;Kedua adalah mengaktifkan failover otomatis. Ada banyak solusi failover otomatis di pasaran. Anda dapat mengatur failover otomatis dengan alat baris perintah seperti MHA, MRM, mysqlfailover atau GUI Orchestrator dan ClusterControl. Jika disiapkan dengan benar, ini dapat mengurangi pemadaman Anda secara signifikan.
ClusterControl mendukung failover otomatis untuk replikasi MySQL, PostgreSQL dan MongoDB serta solusi cluster multi-master Galera dan NDB.
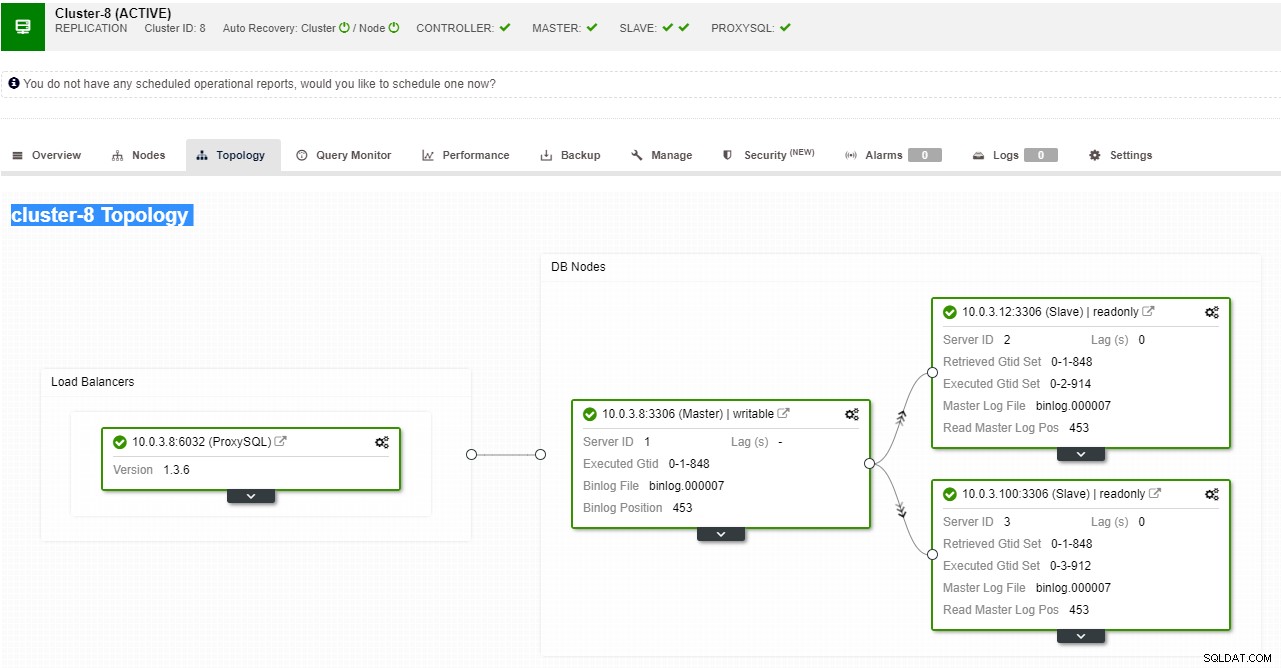 Tampilan topologi replikasi ClusterControl
Tampilan topologi replikasi ClusterControl Ketika node budak mogok dan server sangat tertinggal, Anda mungkin ingin membangun kembali server budak Anda. Proses pembangunan kembali budak mirip dengan memulihkan dari cadangan.
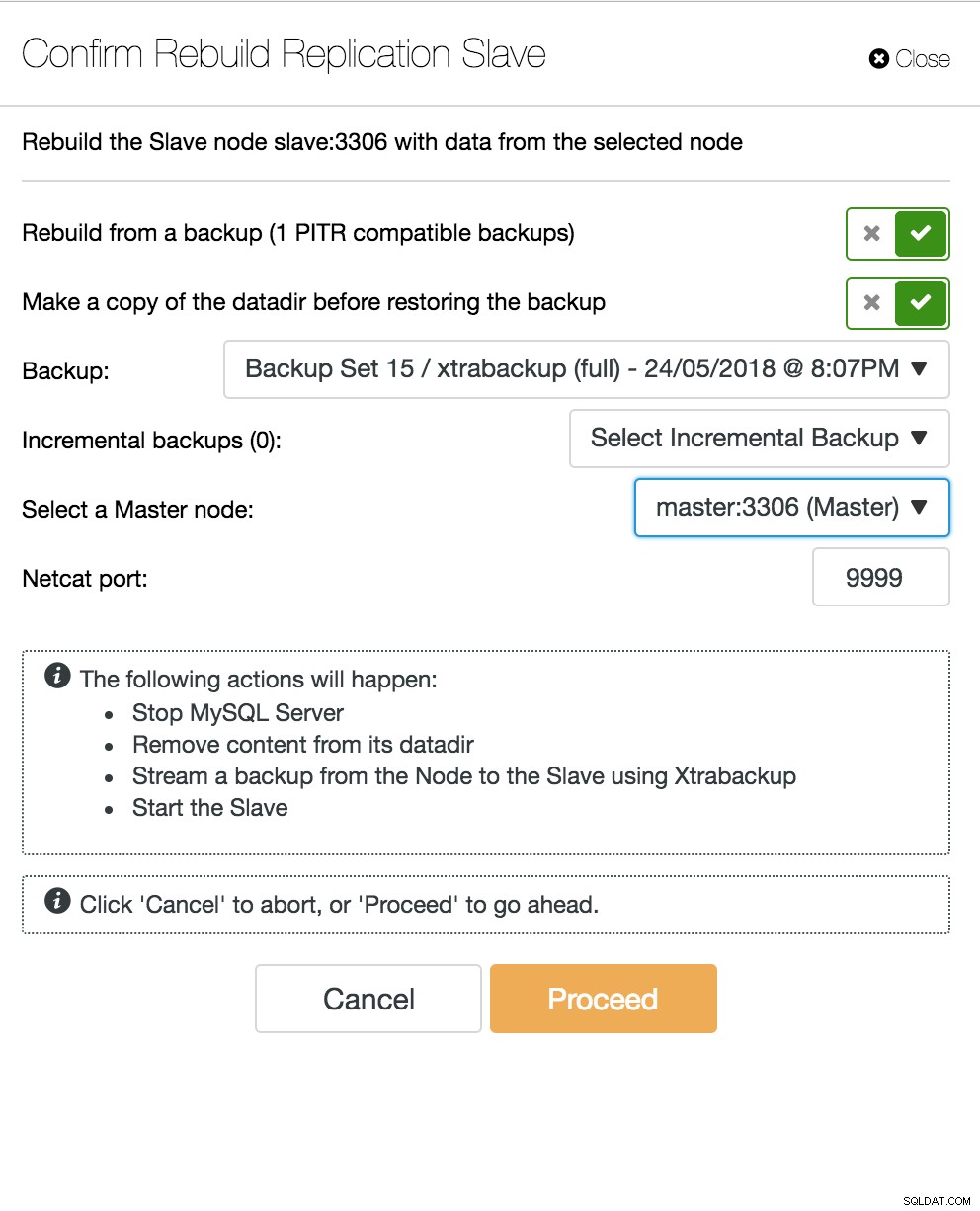 ClusterControl membangun kembali budak
ClusterControl membangun kembali budak Server Multi-Master Basis Data Mati
Sekarang ketika Anda memiliki server budak yang bertindak sebagai node DR, dan proses failover Anda diotomatisasi dan diuji dengan baik, masa pakai DBA Anda menjadi lebih nyaman. Itu benar, tetapi ada beberapa teka-teki lagi yang harus dipecahkan. Kekuatan komputasi tidak gratis, dan tim bisnis Anda mungkin meminta Anda untuk menggunakan perangkat keras dengan lebih baik, Anda mungkin ingin menggunakan server budak tidak hanya sebagai server pasif, tetapi juga untuk melayani operasi penulisan.
Anda mungkin ingin menyelidiki solusi replikasi multi-master. Galera Cluster telah menjadi pilihan utama untuk ketersediaan tinggi MySQL dan MariaDB. Dan meskipun sekarang dikenal sebagai pengganti yang kredibel untuk arsitektur master-slave MySQL tradisional, ini bukan pengganti drop-in.
Cluster Galera memiliki arsitektur apa-apa yang dibagikan. Alih-alih disk bersama, Galera menggunakan replikasi berbasis sertifikasi dengan komunikasi grup dan pemesanan transaksi untuk mencapai replikasi sinkron. Sebuah cluster database harus mampu bertahan kehilangan node, meskipun dicapai dengan cara yang berbeda. Dalam kasus Galera, aspek kritisnya adalah jumlah node. Galera membutuhkan kuorum untuk tetap beroperasi. Sebuah cluster tiga node dapat bertahan dari crash satu node. Dengan lebih banyak node di cluster, Anda dapat bertahan dari lebih banyak kegagalan.
Proses pemulihan otomatis sehingga Anda tidak perlu melakukan operasi failover apa pun. Namun praktik yang baik adalah membunuh node dan melihat seberapa cepat Anda dapat mengembalikannya. Untuk membuat operasi ini lebih efisien, Anda dapat memodifikasi ukuran cache galera. Jika ukuran cache galera tidak direncanakan dengan benar, node boot berikutnya harus mengambil cadangan penuh, bukan hanya set tulis yang hilang dalam cache.
Skenario failover sederhana seperti memulai instance. Berdasarkan data dalam cache galera, node booting akan melakukan SST (restore from full backup) atau IST (apply missing write-sets). Namun, ini sering dikaitkan dengan intervensi manusia. Jika Anda ingin mengotomatiskan seluruh proses failover, Anda dapat menggunakan fungsi pemulihan otomatis ClusterControl (tingkat node dan cluster).
 Pemulihan otomatis cluster Kontrol Cluster
Pemulihan otomatis cluster Kontrol Cluster Perkirakan ukuran cache galera:
MariaDB [(none)]> SET @start := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); do sleep(60); SET @end := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); SET @gcache := (SELECT SUBSTRING_INDEX(SUBSTRING_INDEX(@@GLOBAL.wsrep_provider_options,'gcache.size = ',-1), 'M', 1)); SELECT ROUND((@end - @start),2) AS `MB/min`, ROUND((@end - @start),2) * 60 as `MB/hour`, @gcache as `gcache Size(MB)`, ROUND(@gcache/round((@end - @start),2),2) as `Time to full(minutes)`;Untuk membuat failover lebih konsisten, Anda harus mengaktifkan gcache.recover=yes di mycnf. Opsi ini akan menghidupkan kembali galera-cache saat restart. Ini berarti node dapat bertindak sebagai DONOR dan melayani set tulis yang hilang (memfasilitasi IST, alih-alih menggunakan SST).
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 2,
members = 2/3 (joined/total),
act_id = 12810,
last_appl. = 0,
protocols = 0/7/3 (gcs/repl/appl),
group UUID = 49eca8f8-0e3a-11e8-be4a-e7e3fe48cb69
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Flow-control interval: [28, 28]
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Trying to continue unpaused monitor
2018-07-20 8:59:44 139657311033088 [Note] WSREP: New cluster view: global state: 49eca8f8-0e3a-11e8-be4a-e7e3fe48cb69:12810, view# 3: Primary, number of nodes: 3, my index: 1, protocol version 3Node SQL proxy turun
Jika Anda memiliki pengaturan IP virtual, yang harus Anda lakukan adalah mengarahkan aplikasi Anda ke alamat IP virtual dan semuanya harus benar dari segi koneksi. Tidaklah cukup untuk memiliki instans database Anda yang mencakup beberapa pusat data, Anda masih memerlukan aplikasi Anda untuk mengaksesnya. Asumsikan Anda telah mengurangi jumlah replika baca, Anda mungkin ingin menerapkan IP virtual untuk masing-masing replika baca tersebut juga karena alasan pemeliharaan atau ketersediaan. Ini mungkin menjadi kumpulan IP virtual yang rumit yang harus Anda kelola. Jika salah satu dari replika baca tersebut mengalami crash, Anda perlu menetapkan ulang IP virtual ke host yang berbeda, atau aplikasi Anda akan terhubung ke salah satu host yang sedang down atau dalam kasus terburuk, server yang tertinggal dengan data basi.
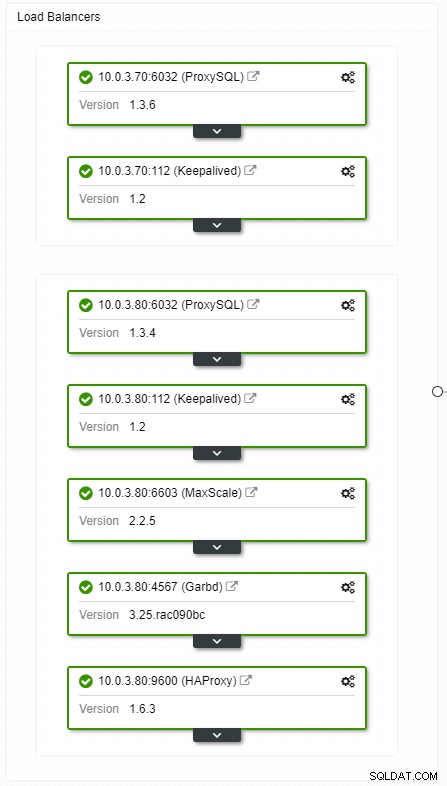 ClusterControl HA tampilan topologi penyeimbang beban
ClusterControl HA tampilan topologi penyeimbang beban Kerusakan tidak sering terjadi, tetapi lebih mungkin daripada server yang down. Jika karena alasan apa pun, seorang budak turun, sesuatu seperti ProxySQL akan mengarahkan semua lalu lintas ke master, dengan risiko kelebihan beban. Ketika budak pulih, lalu lintas akan diarahkan kembali ke sana. Biasanya, waktu henti tersebut tidak akan memakan waktu lebih dari beberapa menit, sehingga tingkat keparahan secara keseluruhan adalah sedang, meskipun kemungkinannya juga sedang.
Agar komponen penyeimbang beban Anda redundan, Anda dapat menggunakan keepalive.
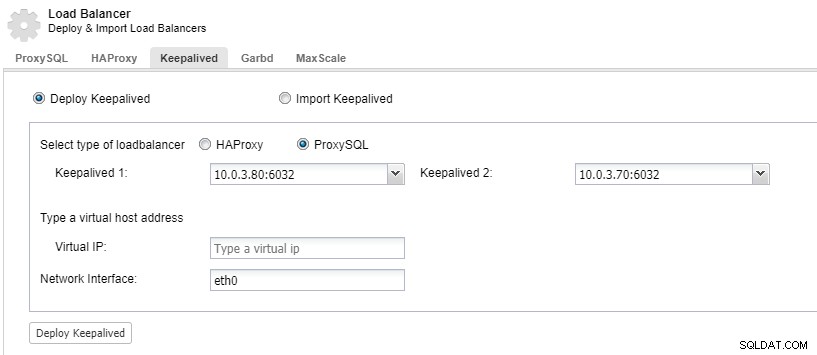 ClusterControl:Terapkan keepalive untuk penyeimbang beban ProxySQL
ClusterControl:Terapkan keepalive untuk penyeimbang beban ProxySQL Pusat Data Mati
Masalah utama dengan replikasi adalah bahwa tidak ada mekanisme mayoritas untuk mendeteksi kegagalan pusat data dan melayani master baru. Salah satu resolusinya adalah menggunakan Orchestrator/Raft. Orchestrator adalah supervisor topologi yang dapat mengontrol failover. Ketika digunakan bersama dengan Raft, Orchestrator akan menjadi sadar kuorum. Salah satu instance Orchestrator dipilih sebagai pemimpin dan menjalankan tugas pemulihan. Koneksi antara node orkestra tidak berkorelasi dengan komitmen basis data transaksional dan jarang.
Orchestrator/Raft dapat menggunakan instance tambahan yang melakukan pemantauan topologi. Dalam hal partisi jaringan, instance Orchestrator yang dipartisi tidak akan mengambil tindakan apa pun. Bagian dari cluster Orchestrator yang memiliki kuorum akan memilih master baru dan membuat perubahan topologi yang diperlukan.
ClusterControl digunakan untuk manajemen, penskalaan, dan, yang paling penting, pemulihan node - Orchestrator akan menangani failover, tetapi jika slave mogok, ClusterControl akan memastikannya akan dipulihkan. Orchestrator dan ClusterControl akan ditempatkan di zona ketersediaan yang sama, terpisah dari node MySQL, untuk memastikan aktivitas mereka tidak akan terpengaruh oleh pemisahan jaringan antara zona ketersediaan di pusat data.