Kluster Galera menerapkan konsistensi data yang kuat, di mana semua node dalam cluster digabungkan dengan erat. Meskipun segmentasi jaringan didukung, kinerja replikasi masih terikat oleh dua faktor:
-
Waktu pulang pergi (RTT) ke node terjauh dalam cluster dari node originator.
-
Ukuran writeset yang akan ditransfer dan disertifikasi untuk konflik pada node penerima.
Meskipun ada cara untuk meningkatkan kinerja Galera, dua faktor pembatas ini tidak dapat diatasi.
Untungnya, Galera Cluster dibangun di atas MySQL, yang juga dilengkapi dengan fitur replikasi bawaan (duh!). Replikasi Galera dan replikasi MySQL ada di perangkat lunak server yang sama secara independen. Teknologi ini dapat kita manfaatkan untuk bekerja sama, dimana semua replikasi dalam data center akan berada di Galera, sedangkan replikasi antar data center akan menggunakan MySQL Replication standar. Situs budak dapat bertindak sebagai situs siaga panas, siap untuk melayani data setelah aplikasi diarahkan ke situs cadangan. Kami membahas ini di blog sebelumnya tentang arsitektur MySQL untuk pemulihan bencana.
Replikasi cluster-ke-cluster diperkenalkan di ClusterControl di versi 1.7.4. Dalam posting blog ini, kami akan menunjukkan betapa mudahnya mengatur replikasi antara dua Galera Cluster (PXC 8.0). Kemudian kita akan melihat bagian yang lebih menantang:menangani kegagalan pada level node dan cluster dengan bantuan ClusterControl; operasi failover dan failback sangat penting untuk menjaga integritas data di seluruh sistem.
Penerapan Cluster
Untuk contoh kita, kita memerlukan setidaknya dua cluster dan dua situs – satu untuk yang utama dan yang lain untuk yang sekunder. Ini bekerja mirip dengan replikasi master-slave MySQL tradisional tetapi dalam skala yang lebih besar dengan tiga node database di setiap situs. Dengan ClusterControl, Anda akan mencapainya dengan menerapkan cluster utama, diikuti dengan menerapkan cluster sekunder di situs pemulihan bencana sebagai cluster replika, direplikasi oleh replikasi asinkron dua arah.
Diagram berikut mengilustrasikan arsitektur akhir kita:

Kami memiliki enam node database secara total, tiga di situs utama dan satu lagi tiga di situs pemulihan bencana. Untuk menyederhanakan representasi node, kita akan menggunakan notasi berikut:
-
Situs utama:
-
galera1-P - 192.168.11.171 (master)
-
galera2-P - 192.168.11.172
-
galera3-P - 192.168.11.173
-
-
Situs pemulihan bencana:
-
galera1-DR - 192.168.11.181 (budak)
-
galera2-DR - 192.168.11.182
-
galera3-DR - 192.168.11.183
-
Pertama, cukup gunakan cluster pertama, dan kami menyebutnya PXC-Primary. Buka ClusterControl UI → Deploy → MySQL Galera, dan masukkan semua detail yang diperlukan:
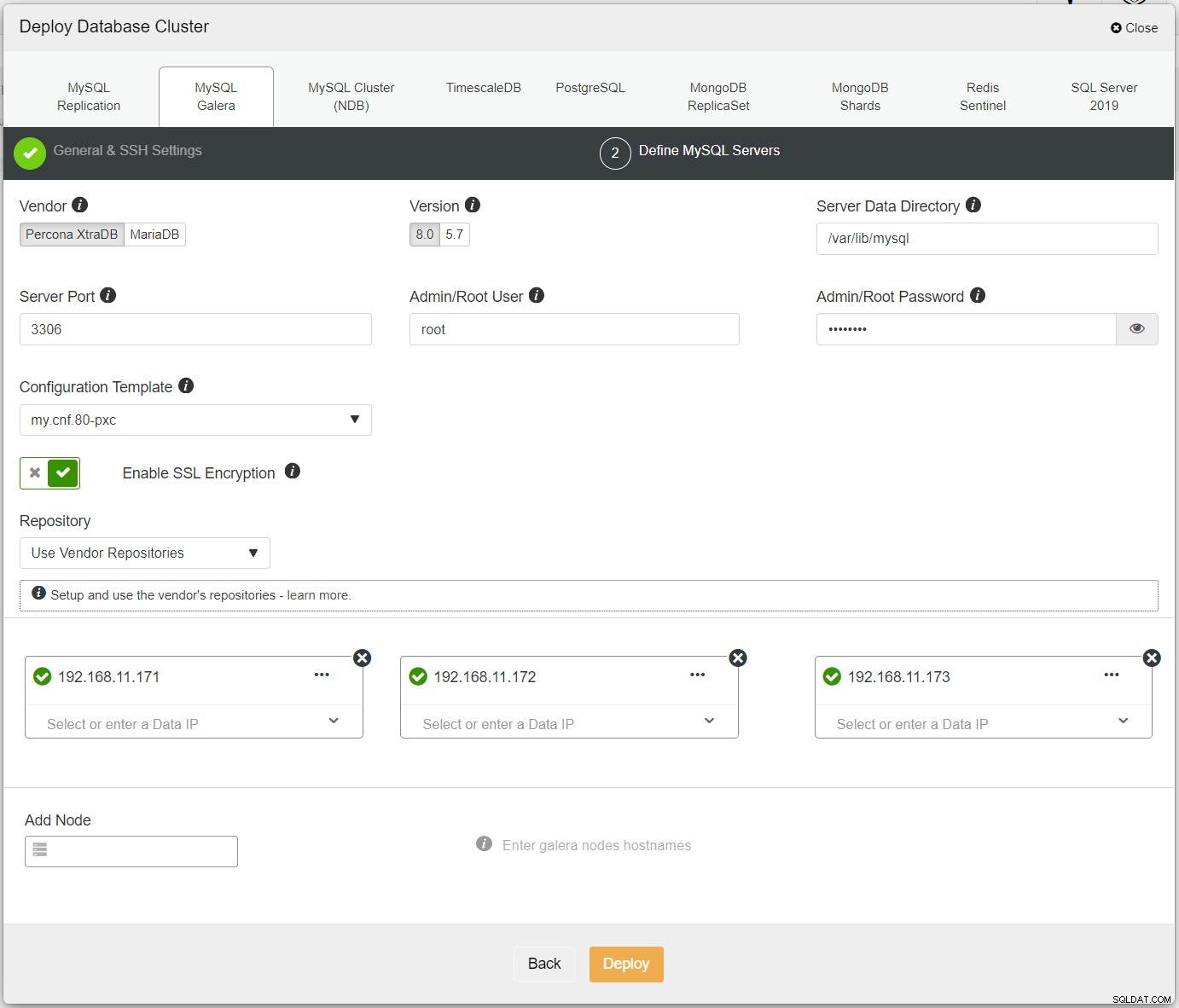
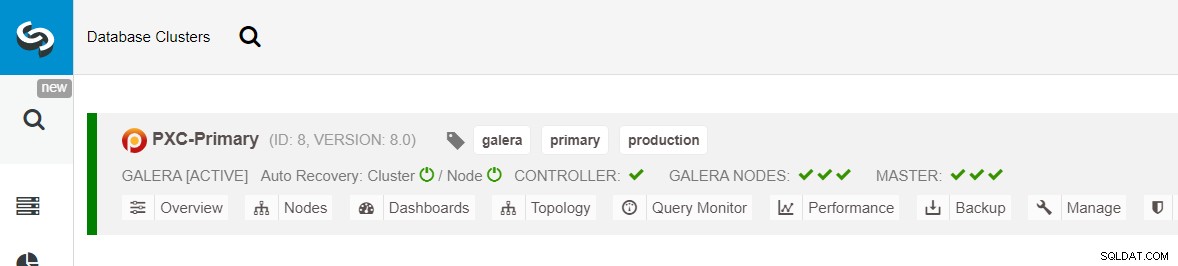
Pastikan setiap node yang ditentukan memiliki tanda centang hijau di sebelahnya, yang menunjukkan bahwa ClusterControl dapat terhubung ke host melalui SSH tanpa kata sandi. Klik Terapkan dan tunggu hingga penerapan selesai. Setelah selesai, Anda akan melihat cluster berikut terdaftar di halaman dashboard cluster:
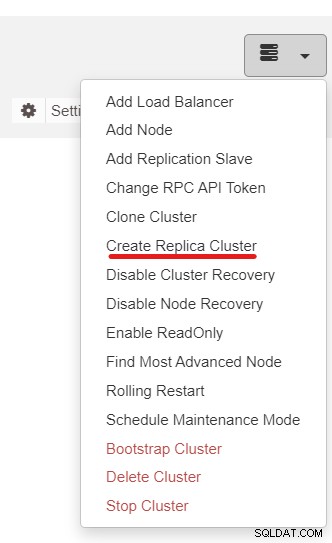
Selanjutnya, kita akan menggunakan fitur ClusterControl bernama Create Replica Cluster, dapat diakses dari tarik-turun Tindakan Klaster:
Anda akan disajikan dengan popup sidebar berikut:
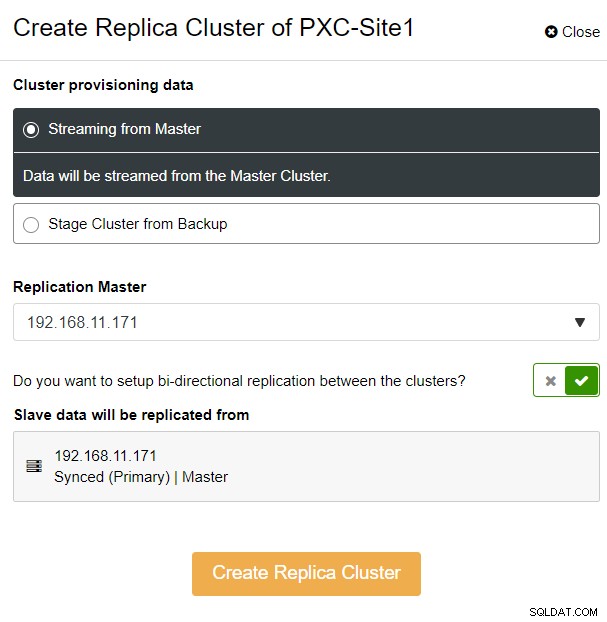
Kami memilih opsi "Streaming dari Master", di mana ClusterControl akan menggunakan master yang dipilih untuk menyinkronkan cluster replika dan mengonfigurasi replikasi. Perhatikan opsi replikasi dua arah. Jika diaktifkan, ClusterControl akan menyiapkan replikasi dua arah antara kedua situs (replikasi melingkar). Master yang dipilih akan mereplikasi dari master pertama yang ditentukan untuk cluster replika dan sebaliknya. Pengaturan ini akan meminimalkan waktu pementasan yang diperlukan saat memulihkan setelah failover atau failback. Klik "Buat Replika Cluster," di mana ClusterControl membuka wizard penerapan baru untuk cluster replika, seperti yang ditunjukkan di bawah ini:
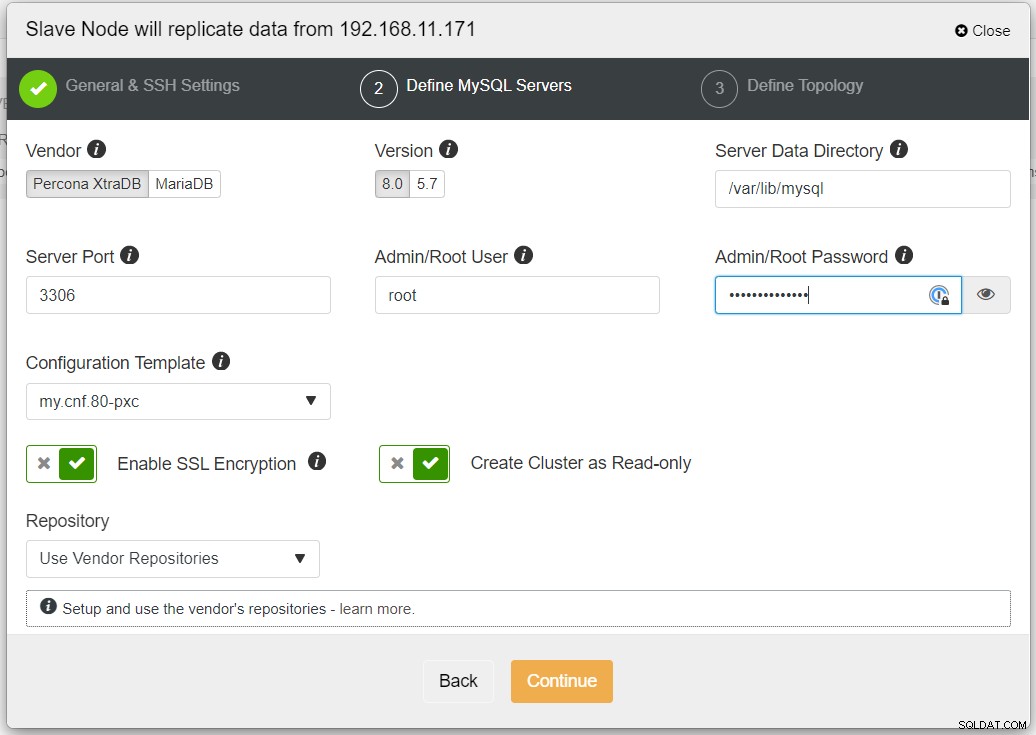
Disarankan untuk mengaktifkan enkripsi SSL jika replikasi melibatkan jaringan yang tidak tepercaya seperti WAN, jaringan non-tunnel, atau Internet. Juga, pastikan bahwa "Buat Cluster sebagai Hanya-baca" diaktifkan; ini adalah perlindungan terhadap penulisan yang tidak disengaja dan indikator yang baik untuk membedakan dengan mudah antara cluster aktif (baca-tulis) dan cluster pasif (read-only).
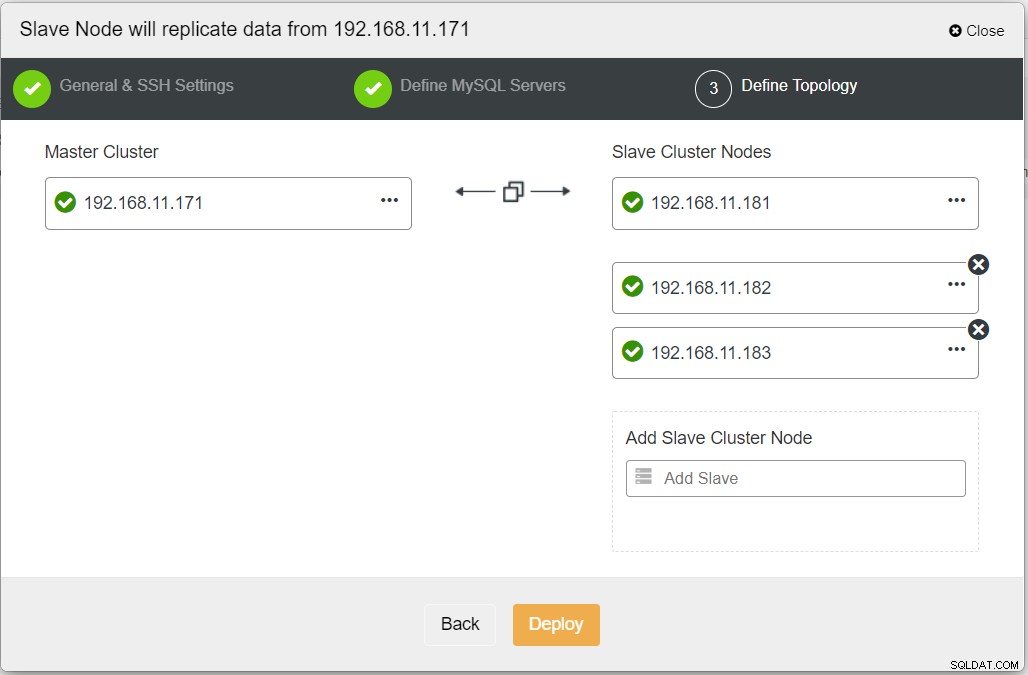
Saat mengisi semua informasi yang diperlukan, Anda harus mencapai tahap berikut untuk menentukan topologi cluster replika:
Dari dasbor ClusterControl, setelah penerapan selesai, Anda akan melihat Situs DR memiliki panah dua arah yang terhubung dengan situs Utama:
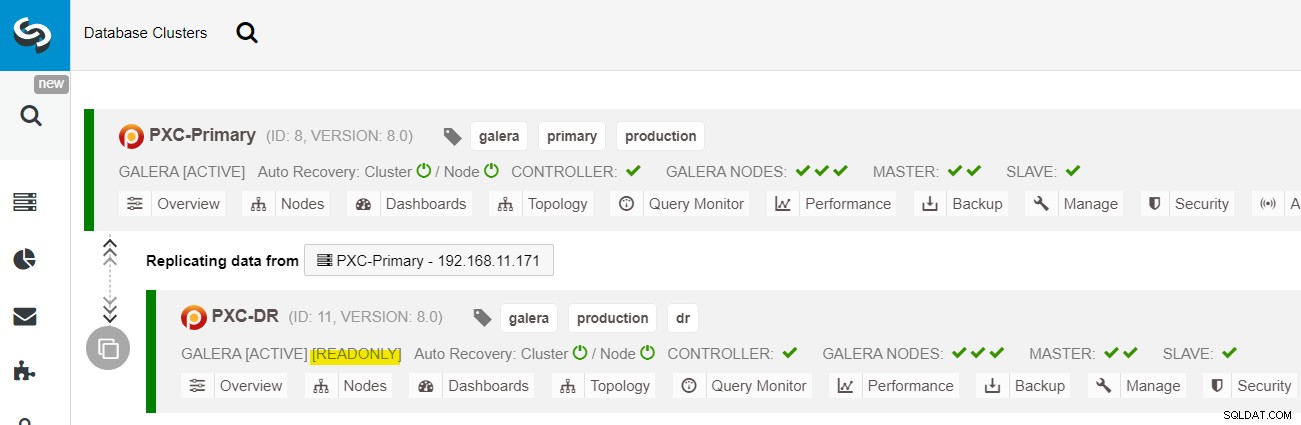
Penerapan sekarang selesai. Aplikasi harus mengirim menulis ke Situs Utama hanya karena ini adalah situs aktif, dan situs DR dikonfigurasi untuk hanya-baca (disorot dengan warna kuning). Bacaan dapat dikirim ke kedua situs, meskipun situs DR berisiko tertinggal karena sifat replikasi asinkron. Pengaturan ini akan membuat situs utama dan pemulihan bencana independen satu sama lain, terhubung secara longgar dengan replikasi asinkron. Salah satu node Galera di situs DR akan menjadi budak yang mereplikasi dari salah satu node Galera (master) di situs utama.
Kami sekarang memiliki sistem di mana kegagalan cluster di situs utama tidak akan memengaruhi situs cadangan. Dari segi kinerja, latensi WAN tidak akan memengaruhi pembaruan pada cluster aktif. Ini dikirim secara asinkron ke situs cadangan.
Sebagai catatan tambahan, Anda juga dapat memiliki instance slave khusus sebagai relai replikasi alih-alih menggunakan salah satu node Galera sebagai slave.
Prosedur Kegagalan Node Galera
Jika master saat ini (galera1-P) gagal dan node yang tersisa di Situs Utama masih aktif, slave di situs Pemulihan Bencana (galera1-DR) harus diarahkan ke master yang tersedia di Situs Utama, seperti yang ditunjukkan pada diagram berikut:
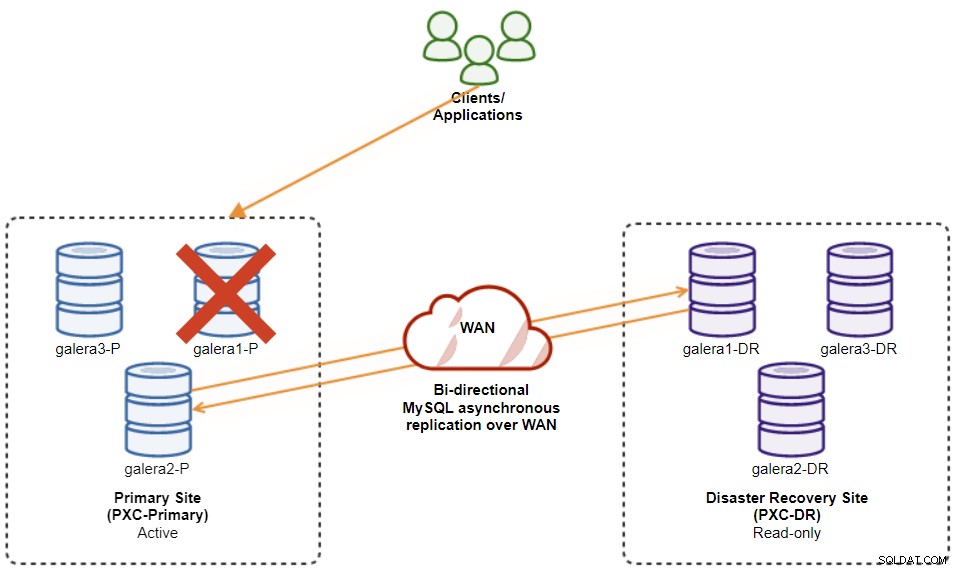
Dari daftar cluster ClusterControl, Anda dapat melihat bahwa status cluster diturunkan , dan jika Anda berguling pada ikon tanda seru, Anda dapat melihat kesalahan untuk simpul tersebut (galera1-P):
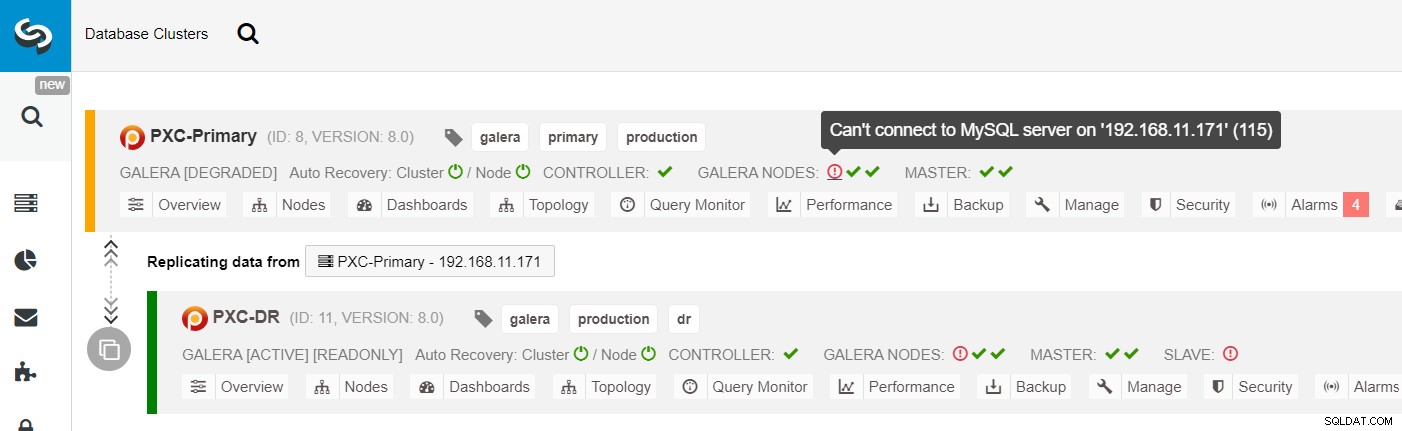
Dengan ClusterControl, Anda cukup pergi ke cluster PXC-DR → Nodes → pilih galera1-DR → Node Actions → Rebuild Replication Slave, dan Anda akan disajikan dialog konfigurasi berikut:
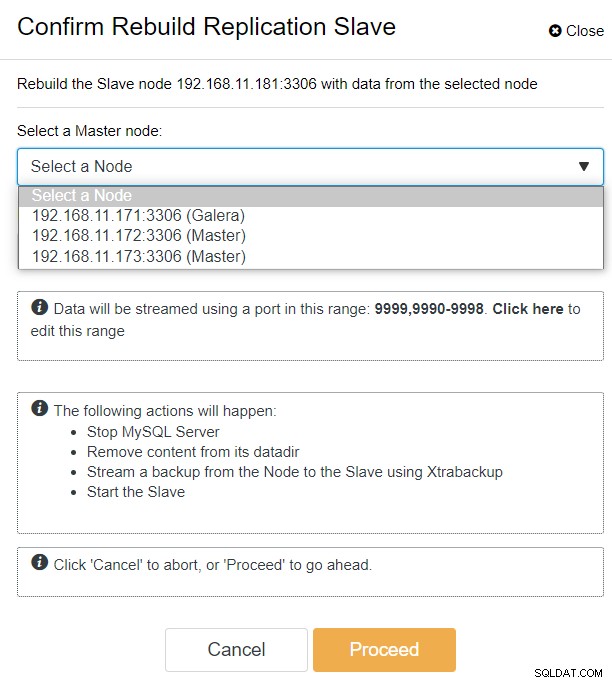
Kita dapat melihat semua node Galera di Situs Utama (192.168.11.17x ) dari daftar drop-down. Pilih node sekunder, 192.168.11.172 (galera2-P), dan klik Lanjutkan. ClusterControl kemudian akan mengonfigurasi topologi replikasi sebagaimana mestinya, menyiapkan replikasi dua arah dari galera2-P ke galera1-DR. Anda dapat mengonfirmasi hal ini dari halaman dasbor cluster (disorot dengan warna kuning):
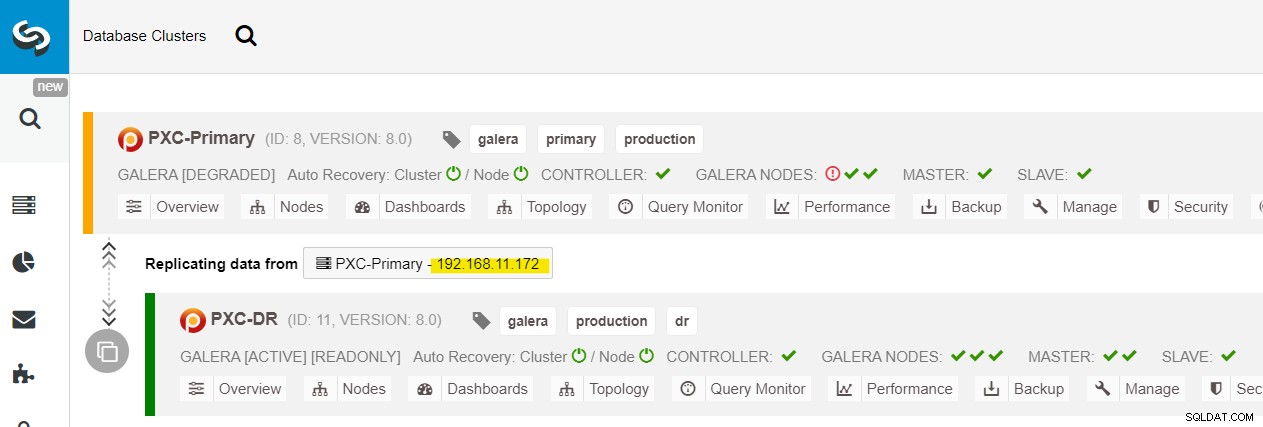
Pada titik ini, cluster utama (PXC-Primary) masih melayani sebagai cluster aktif untuk topologi ini. Seharusnya tidak memengaruhi waktu aktif layanan basis data dari kluster utama.
Prosedur Kegagalan Klaster Galera
Jika kluster utama mati, macet, atau hanya kehilangan konektivitas dari sudut pandang aplikasi, aplikasi dapat diarahkan ke situs DR hampir seketika. SysAdmin hanya perlu menonaktifkan read-only di semua node Galera di situs pemulihan bencana dengan menggunakan pernyataan berikut:
mysql> SET GLOBAL read_only = 0; -- repeat on galera1-DR, galera2-DR, galera3-DRUntuk pengguna ClusterControl, Anda dapat menggunakan ClusterControl UI → Nodes → pilih DB node → Node Actions → Disable Read-only. ClusterControl CLI juga tersedia, dengan menjalankan perintah berikut pada node ClusterControl:
$ s9s node --nodes="192.168.11.181" --cluster-id=11 --set-read-write
$ s9s node --nodes="192.168.11.182" --cluster-id=11 --set-read-write
$ s9s node --nodes="192.168.11.183" --cluster-id=11 --set-read-writeFailover ke situs DR sekarang selesai, dan aplikasi dapat mulai mengirim penulisan ke cluster PXC-DR. Dari UI ClusterControl, Anda akan melihat sesuatu seperti ini:
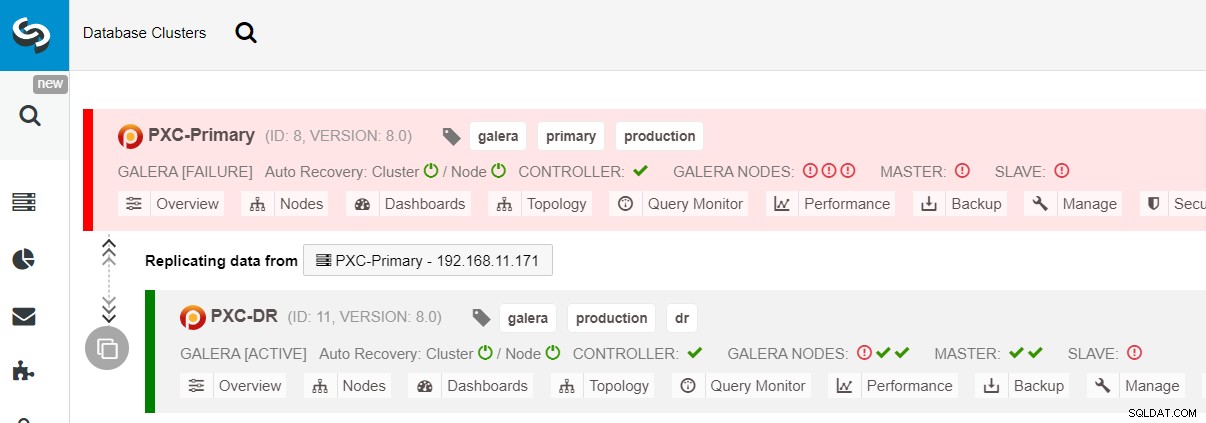
Diagram berikut menunjukkan arsitektur kami setelah aplikasi gagal ke situs DR :
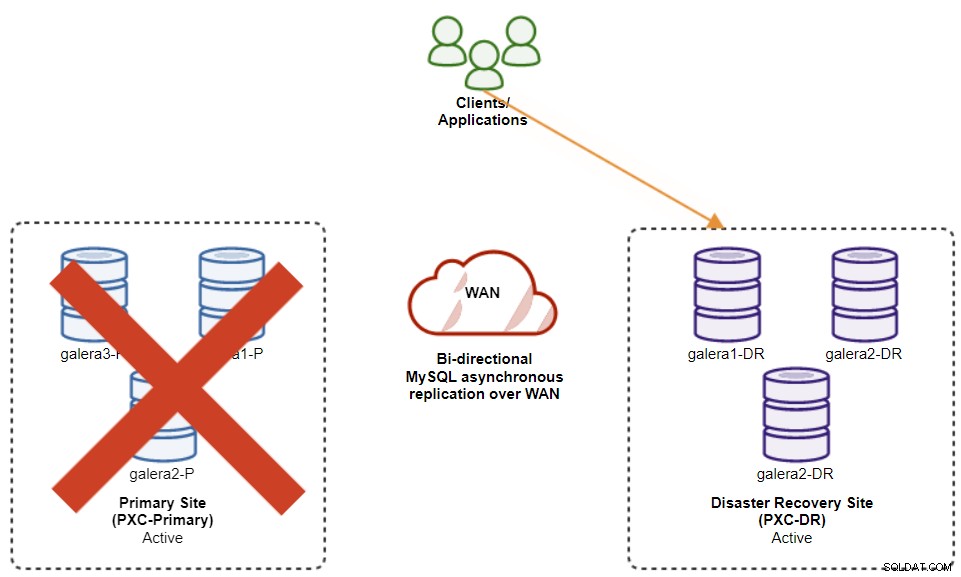
Dengan asumsi Situs Utama masih down, pada titik ini, tidak ada replikasi antar situs hingga Situs Utama muncul kembali.
Prosedur Failback Cluster Galera
Setelah situs utama muncul, penting untuk dicatat bahwa kluster utama harus disetel ke hanya-baca, jadi kita tahu bahwa kluster yang aktif adalah yang ada di situs pemulihan bencana. Dari ClusterControl, buka menu drop-down cluster dan pilih "Enable Read-only", yang akan mengaktifkan read-only pada semua node di cluster utama dan meringkas topologi saat ini seperti di bawah ini:
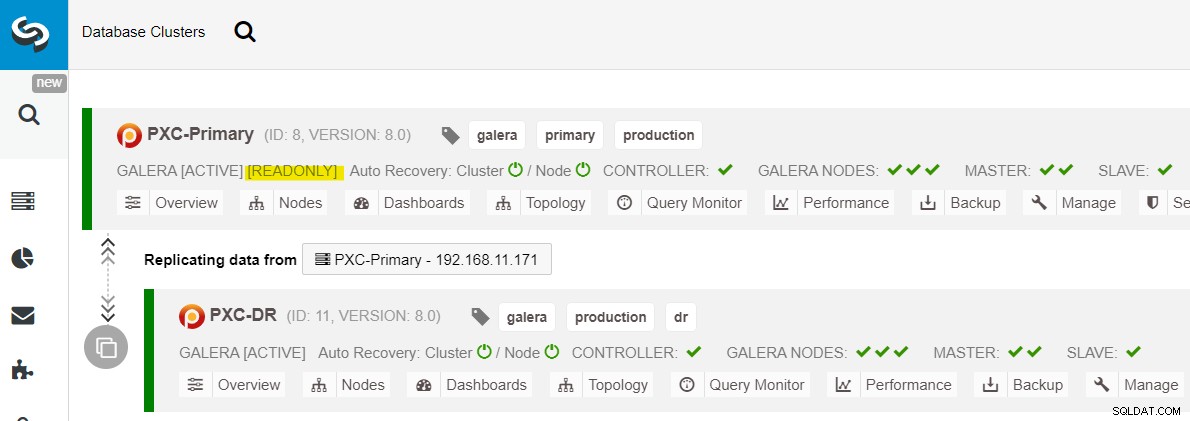
Pastikan semuanya hijau sebelum merencanakan untuk memulai prosedur failback cluster (hijau berarti semua node aktif dan disinkronkan satu sama lain). Jika ada node yang statusnya terdegradasi, misalnya node replika masih tertinggal, atau hanya beberapa node di primary cluster yang bisa dijangkau, tunggu sampai cluster pulih sepenuhnya, baik dengan menunggu prosedur pemulihan otomatis ClusterControl. untuk menyelesaikan, atau intervensi manual.
Pada titik ini, cluster aktif masih merupakan cluster DR, dan cluster utama bertindak sebagai cluster sekunder. Diagram berikut menggambarkan arsitektur saat ini:
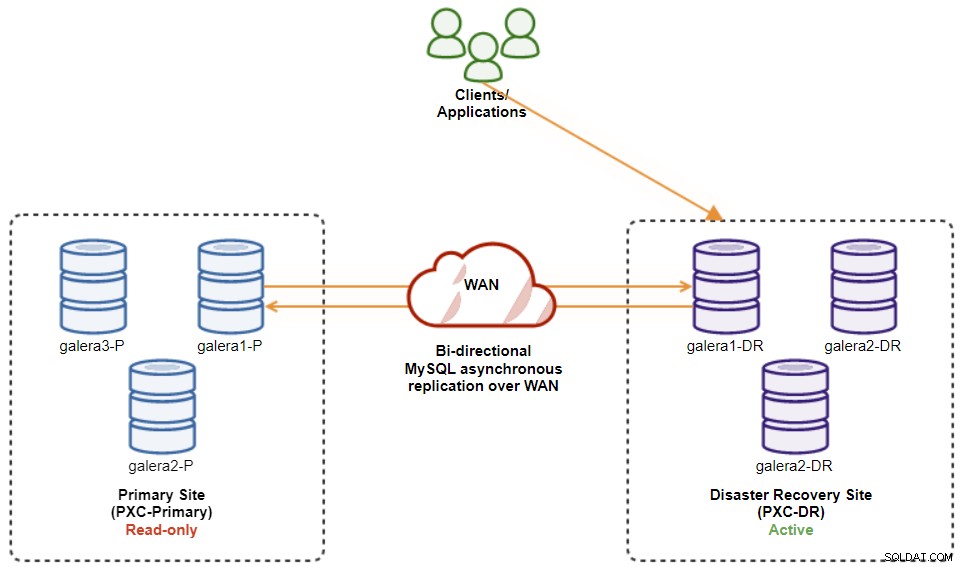
Cara teraman untuk failback ke Situs Utama adalah menyetel read-only di cluster DR, diikuti dengan menonaktifkan read-only di Situs Utama. Buka ClusterControl UI → PXC-DR (menu dropdown) → Aktifkan Read-only. Ini akan memicu tugas untuk menyetel read-only pada semua node pada cluster DR. Lalu, buka ClusterControl UI → PXC-Primary → Nodes, dan nonaktifkan read-only pada semua node database di cluster utama.
Anda juga dapat menyederhanakan prosedur di atas dengan ClusterControl CLI. Atau, jalankan perintah berikut pada host ClusterControl:
$ s9s cluster --cluster-id=11 --set-read-only # enable cluster-wide read-only
$ s9s node --nodes="192.168.11.171" --cluster-id=8 --set-read-write
$ s9s node --nodes="192.168.11.172" --cluster-id=8 --set-read-write
$ s9s node --nodes="192.168.11.173" --cluster-id=8 --set-read-writeSetelah selesai, arah replikasi telah kembali ke konfigurasi aslinya, di mana PXC-Primary adalah cluster aktif dan PXC-DR adalah cluster siaga. Diagram berikut mengilustrasikan arsitektur akhir setelah operasi failback cluster:
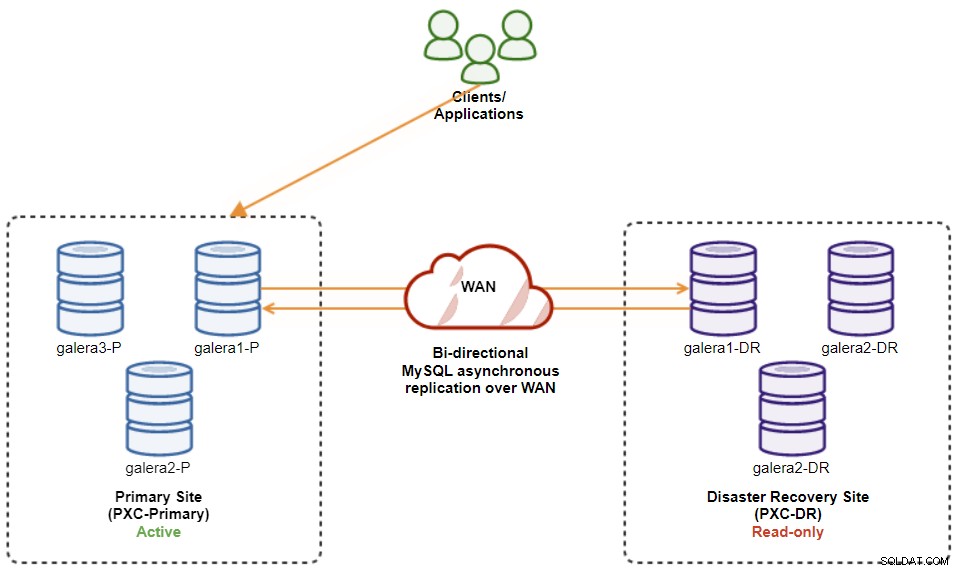
Pada titik ini, sekarang aman untuk mengarahkan ulang aplikasi untuk menulis Situs Utama.
Keuntungan Replikasi Asinkron Cluster-to-Cluster
Cluster-to-cluster dengan replikasi asinkron hadir dengan sejumlah keuntungan:
-
Minimal downtime selama operasi failover database. Pada dasarnya, Anda dapat mengarahkan ulang penulisan hampir seketika ke situs slave, hanya jika Anda dapat melindungi penulisan agar tidak mencapai situs master (karena penulisan ini tidak akan direplikasi, dan mungkin akan ditimpa saat menyinkronkan ulang dari situs DR).
-
Tidak ada dampak kinerja pada situs utama karena tidak bergantung pada situs cadangan (DR). Replikasi dari master ke slave dilakukan secara asynchronous. Situs master menghasilkan log biner, situs budak mereplikasi peristiwa dan menerapkan peristiwa di lain waktu.
-
Situs pemulihan bencana dapat digunakan untuk tujuan lain, misalnya, pencadangan basis data, pencadangan dan pelaporan log biner, atau kueri analitik berat (OLAP). Kedua situs dapat digunakan secara bersamaan, kecuali untuk jeda replikasi dan operasi read-only di sisi slave.
-
Kluster DR berpotensi berjalan pada instance yang lebih kecil di lingkungan cloud publik, selama mereka dapat mengikutinya dengan klaster primer. Anda dapat memutakhirkan instans jika diperlukan. Dalam skenario tertentu, ini dapat menghemat beberapa biaya.
-
Anda hanya memerlukan satu situs tambahan untuk Pemulihan Bencana dibandingkan dengan penyiapan replikasi multi-situs Galera yang aktif-aktif, yang membutuhkan setidaknya tiga situs aktif untuk beroperasi dengan benar.
Kekurangan Replikasi Asinkron Cluster-to-Cluster
Ada juga kekurangan pada penyiapan ini, bergantung pada apakah Anda menggunakan replikasi dua arah atau satu arah:
-
Ada kemungkinan kehilangan beberapa data selama failover jika slave berada di belakang, karena replikasi tidak sinkron. Ini dapat ditingkatkan dengan replikasi slave semi-sinkron dan multi-utas, meskipun akan ada serangkaian tantangan lain yang menunggu (overhead jaringan, celah replikasi, dll.).
-
Dalam replikasi searah, meskipun prosedur failover cukup sederhana, prosedur failback bisa rumit dan rentan terhadap manusia kesalahan. Ini membutuhkan beberapa keahlian untuk mengalihkan peran master/slave kembali ke situs utama. Disarankan untuk mendokumentasikan prosedur, melatih operasi failover/failback secara teratur, dan menggunakan alat pelaporan dan pemantauan yang akurat.
-
Ini bisa sangat mahal, karena Anda harus menyiapkan jumlah node yang sama di situs pemulihan bencana . Ini tidak hitam dan putih, karena pembenaran biaya biasanya berasal dari persyaratan bisnis Anda. Dengan beberapa perencanaan, dimungkinkan untuk memaksimalkan penggunaan sumber daya basis data di kedua situs, terlepas dari peran basis data.
Menutup
Menyiapkan replikasi asinkron untuk Cluster MySQL Galera Anda dapat menjadi proses yang relatif mudah — selama Anda memahami cara menangani kegagalan dengan benar di tingkat node dan cluster. Pada akhirnya, operasi failover dan failback sangat penting untuk memastikan integritas data.
Untuk kiat lebih lanjut tentang merancang Cluster Galera Anda dengan mempertimbangkan strategi failover dan failback, lihat posting ini tentang arsitektur MySQL untuk pemulihan bencana. Jika Anda mencari bantuan untuk mengotomatiskan operasi ini, evaluasi ClusterControl gratis selama 30 hari dan ikuti langkah-langkah dalam postingan ini.
Jangan lupa untuk mengikuti kami di Twitter atau LinkedIn dan berlangganan buletin kami untuk tetap mendapatkan berita terbaru dan praktik terbaik untuk mengelola infrastruktur basis data sumber terbuka Anda.